
推特或微博机器人的存在其实是比较危险的,他们可以制造虚假的流量、传播谣言、甚至执行一些令人汗颜的恶意操作![]() ,这里我们使用kaggle纽约大学2017年机器学习竞赛的推特分类数据来进行我们的识别实验,本实验的数据集请访问:下载Python推特机器人分类数据集。
,这里我们使用kaggle纽约大学2017年机器学习竞赛的推特分类数据来进行我们的识别实验,本实验的数据集请访问:下载Python推特机器人分类数据集。
在开始之前我们需要安装以下Python包(库),打开你的CMD(Windows系统)/Terminal(macOS系统)输入以下指令即可:
pip install numpy pip install seaborn pip install pandas pip install matplotlib pip install scikit-learn
其中numpy和pandas都是用于数据处理的,numpy是一个C编写的库,所以运算会比python内置的运算快,此外,matplotlib和seaborn主要用于Python数据可视化。scikit-learn内置了许多常用的机器学习分析模型,用起来非常简单。
1.Python加载数据
好了,废话不多说,让我们现在就开始使用panda加载数据,分别获得bot和非bot数据:
import pandas as pd
import numpy as np
import seaborn
import matplotlib
data = pd.read_csv('training_data.csv')
Bots = data[data.bot==1]
NonBots = data[data.bot==0]使用热力图识别训练集/测试集中缺失数据:
seaborn.heatmap(data.isnull(), yticklabels=False, cbar=False, cmap='viridis') # 热力图,当data中有空值时标为黄色 matplotlib.pyplot.tight_layout() matplotlib.pyplot.show()

2.Python 特征选择
什么是特征选择?其实很简单,我们在日常生活中识别西瓜和榴莲的时候是怎么识别的![]() ?比如从外观特征上:榴莲带刺、黄色的;西瓜圆润、绿色的。机器学习模型也是一样的,我们需要从类似于挑选西瓜外观特征来挑选两个类别的特征。比如说应用上我们前面的Python热力图查看数据缺失:
?比如从外观特征上:榴莲带刺、黄色的;西瓜圆润、绿色的。机器学习模型也是一样的,我们需要从类似于挑选西瓜外观特征来挑选两个类别的特征。比如说应用上我们前面的Python热力图查看数据缺失:
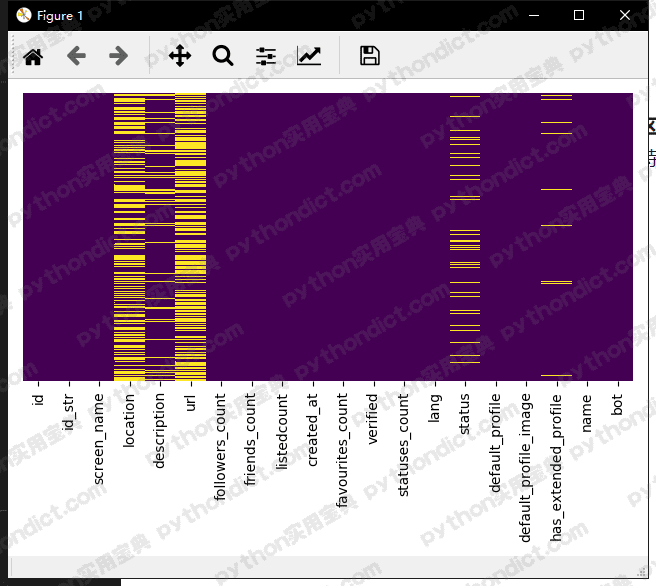
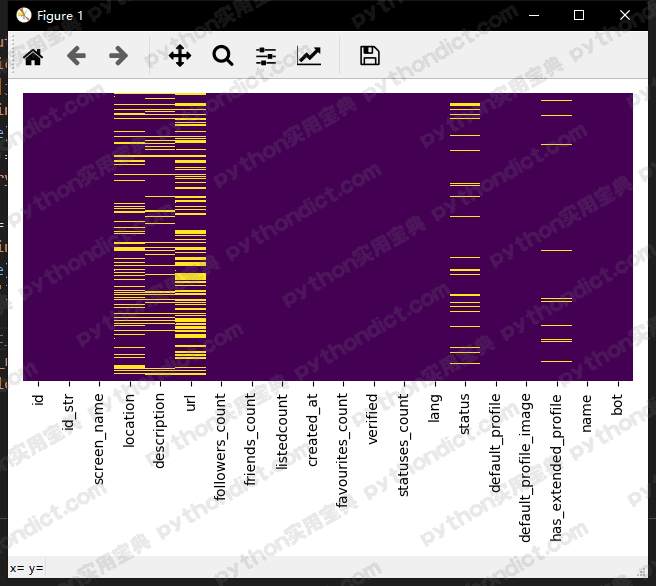
我们可以明显地看到机器人的location, urls明显缺失的部分更多。因此我们的特征可以加上这两项,由于数据量不多,我们应该绕过字符串编码,以location列为例,编码方式为:如果location缺失则为false, location存在则为True.
其他特征当然还有比如姓名、描述(description ) 这样的必输信息。当然,我们还能通过选择Twitter机器人使用的一些不好的单词将他们作为特征,如果他们的信息里包含了这些脏话,则将该机器人的该项特征设为True。下面是一个机器人使用脏话的例子。你可以添加更多的单词:
bag_of_words_bot = r'bot|b0t|cannabis|tweet me|mishear|follow me|updates every|gorilla|yes_ofc|forget' \ r'expos|kill|bbb|truthe|fake|anony|free|virus|funky|RNA|jargon'\ r'nerd|swag|jack|chick|prison|paper|pokem|xx|freak|ffd|dunia|clone|genie|bbb' \ r'ffd|onlyman|emoji|joke|troll|droop|free|every|wow|cheese|yeah|bio|magic|wizard|face'
将我们的特征编码为数字的形式:
# 该列的每个值包不包含脏话,包含则为True,不包含则为False data['screen_name_binary'] = data.screen_name.str.contains(bag_of_words_bot, case=False, na=False) data['name_binary'] = data.name.str.contains(bag_of_words_bot, case=False, na=False) data['description_binary'] = data.description.str.contains(bag_of_words_bot, case=False, na=False) data['status_binary'] = data.status.str.contains(bag_of_words_bot, case=False, na=False) # 判断该列的每个值是否有listedcount>20000的情况,有的话为False,没有的话为True data['listed_count_binary'] = (data.listedcount>20000)==False # 判断该列的每个值是否有空的情况,有空的则为False,否则为True data['location_binary'] = ~data.location.isnull() data['url_binary'] = ~data.url.isnull() # 选定我们的特征 features = ['screen_name_binary', 'name_binary', 'description_binary', 'status_binary', 'verified', 'followers_count','verified', 'friends_count', 'statuses_count', 'listed_count_binary', 'bot', 'url_binary', 'location_binary', 'default_profile', 'default_profile_image']
其中需要注意的是所有的文本我们都编码为0和1的形式(存不存在脏话)。
3.Python scikit-learn训练与测试
现在让我们来使用Python scikit-learn包里的决策树模型进行分类。
首先我们引入需要使用到的包,有三个,如下:
from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import accuracy_score from sklearn.model_selection import train_test_split
1.从 sklearn.tree 引入 DecisionTreeClassifier ,这是一个决策树的分类器模型,我们一会将使用它进行训练;
2.sklearn.metrics 引入 accuracy_score 这是用于方便计算准确率的;
3.sklearn.model_selection 的 train_test_split 是用于方便分割训练集和测试集的。
分割训练集
X = data[features].iloc[:,:-1] # 除了最后一列的BOT都是数据 y = data[features].iloc[:,-1] # BOT是分类对象,1:机器人 0:非机器人X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=101)
使用到了train_test_split()函数,test_size=0.3即30%的数据用于测试,random_state=101 是随机数种子,设置后对于每次不改变训练集的测试,测试结果都一样。
训练与测试
clf = DecisionTreeClassifier(criterion='entropy', min_samples_leaf=50, min_samples_split=10)
clf.fit(X_train, y_train)
y_pred_train = clf.predict(X_train)
y_pred_test = clf.predict(X_test)
print("Training Accuracy: %.5f" %accuracy_score(y_train, y_pred_train))
print("Test Accuracy: %.5f" %accuracy_score(y_test, y_pred_test)) 初始化了一个决策树模型clf,clf.fit即开始进行训练,clf.predict则为测试。
4.Python 模型结果
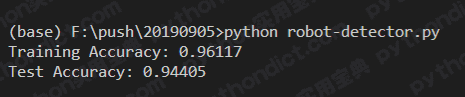
最终我得到的结果如下,测试准确率高达94.4%,这是一个相当令人满意的结果了,在当时的kaggle比赛里大约能排在27名左右。你也可以尝试其他的模型,并非只有决策树可以选择,比如说SVM、LR都可以尝试一下。

全部源代码下载请点击:Python机器学习识别微博或推特机器人(acc:94.4%)
我们的文章到此就结束啦,如果你希望我们今天的Python 教程,请持续关注我们,如果对你有帮助,麻烦在下面点一个赞/在看哦![]() 有任何问题都可以在下方留言区留言,我们都会耐心解答的!
有任何问题都可以在下方留言区留言,我们都会耐心解答的!
Python实用宝典 (pythondict.com)
不只是一个宝典
欢迎关注公众号:Python实用宝典

评论(2)
您好,点击数据集显示不可用了,如果方便的话能发我一份数据集吗,用于学习
修复了