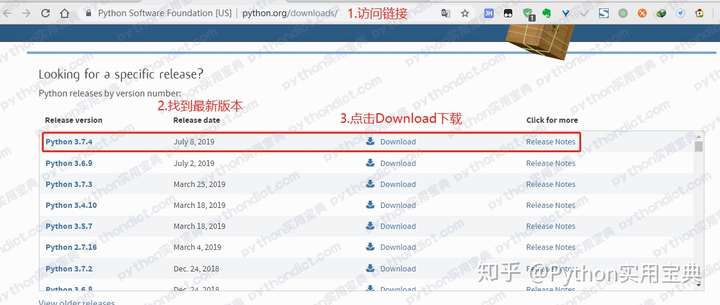
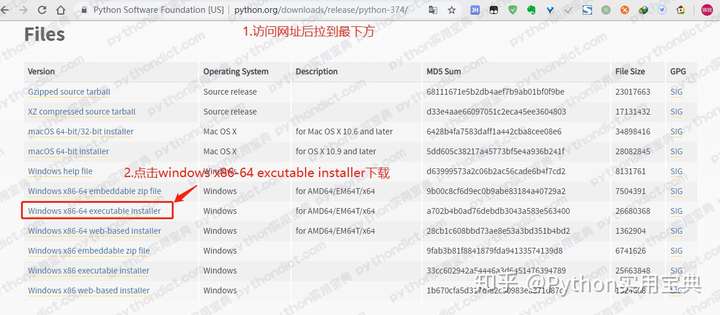
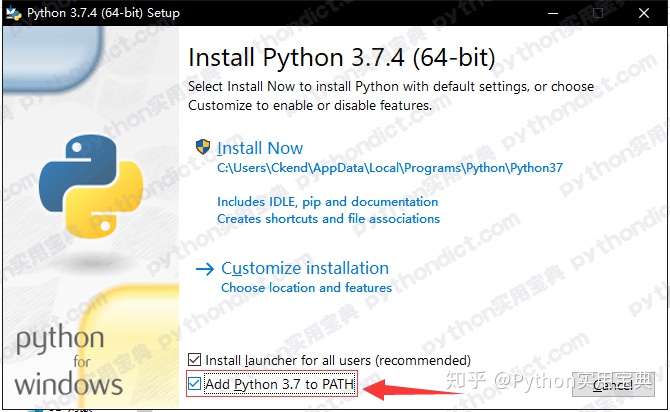
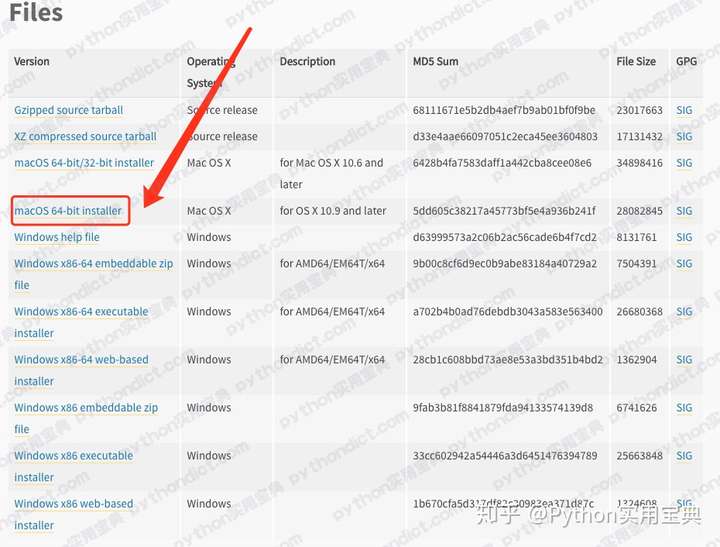
Python 的岗位本来就比较少,而且大部分都对经验要求比较高,没有什么初级岗位啊。尤其是非北上广城市,职位数量少,要求反而比一线城市更高,我个人对这些人转行不看好,欢迎指正。
答案:
这个问题,确实很有价值。
毕竟,掌握一门技能,是需要花成本的。决策之前,做个前景判断,衡量投入产出比,是应该的。
然而,一旦深入思考,你可能自己就会对学 Python 的价值,颇为疑虑。
因为大部分人看待这个问题,是在判断 Python 学过后,能否提升自己的竞争力。
国人常说的俗谚,有一句“一招鲜,吃遍天”。也就是掌握了某种供不应求的技能,于是可以坐享这种技能带来的益处与红利。
你可以暂停阅读20秒钟,在头脑里,自行匹配满足上述条件的相应技能,或是代表该技能的证书。
想好后,咱们继续。
这样的技能,确实是存在。但是,要达到“吃遍天”的效果,需要你衡量市场上的供求关系。
我们都知道,近几年市场对 Python 的需求确实很高。许多岗位招聘条件里面,都有 Python 这一项。
然而,供求关系的另一方,也就是供给,情况如何呢?
很不容乐观。
我不是说供给太少,而是太多了些。
别忘了, Python 最大的特点,就是简单易学。
因此,没有门槛,没有护城河,连上小学的孩子,课本上都要教 Python 了 。
需求再大,如果供给是这样的,价格也很难上去。
所以,如果你的打算,是学好 Python 以后,直接用它变现,那你一定要三思而后行。
这是不是说,你不该学 Python 呢?
恰恰相反,你真的应该学 Python 。
你可能会疑惑:老师,你这不是前后矛盾吗?
不是。
Python 要学,但这项技能,真的不是这么应用的。
连接
Python 无门槛,这么简单,学会了也毫不稀奇,那学它还有什么用?
用处大了。
因为它可以让你和一张巨大的协作网络连接起来。这张网络的溢出效应,对你来说益处可谓巨大。
举个例子。
机器学习听说过吧?最近很火的。
从前人们做机器学习,用的工具 叫做 Matlab 。
直到6、7年前,当 Andrew Ng 制作后来成为经典的《机器学习》课程时,用的工具 还是 Matlab 。
当然,因为当时 Matlab 很贵,所以 Andrew Ng 鼓励大家用 Octave (一种 Matlab 的开源实现版本)替代。
我学这门课程的时候,很痛苦。其中最重要的原因,就是 Matlab / Octave 的使用。
这是当时做的第 8 次作业,你看看为了做个协同过滤(Collaborative Filtering),需要多少个文件。
随便打开一个代码文件,是这样的:
结果是,大部分学员,根本就不知道,该如何完整撰写一个协同过滤算法 的程序。大家只能满足于课程的要求,即在每个文件指定的位置上,做完形填空。
因此,那时候你要是打算使用机器学习,就必须要抱着一本 Matlab 的书啃下来。因为只有明白了它怎么用,你才真正能壮起胆子,尝试从头到尾,去实践自己从 MOOC 学来的机器学习技能。
然而,短短几年之后,事情就完全变了。
2017年,Andrew Ng 的 Coursera 课程《深度学习》推出,这次,他再也不提什么 Matlab 了,从头到尾都是 Python 。
Andrew 教起来轻松,大家学习起来开心。而且更妙的是,因为 Python 简单易懂,因此全部示例代码,你可以很容易看明白,并且知道当应用于自己的实际项目时,修改哪些部分,就可以复用。
其他基于 Python 的机器学习课程,也像雨后春笋一般遍地开花。
例如在 fast.ai 的课程里,实现同样的协同过滤功能,你再也不用写那一堆 Matlab 文件和函数了。
你需要的,仅是以下这几行代码:
from fastai.collab import *
path = untar_data(URLs.ML_SAMPLE)
ratings = pd.read_csv(path/'ratings.csv')
ratings.head()
data = CollabDataBunch.from_df(ratings)
learn = collab_learner(data, n_factors=50, y_range=(0.,5.))
learn.fit_one_cycle(5, 5e-3, wd=0.1)
好了,搞定。
Python 没有门槛。但是通过掌握它,你可以用更短的时间,更高的效率学习和掌握机器学习,甚至是深度学习的技能。
注意,能以这么短短几行代码搞定问题,不是因为你学了 Python ,所以技能大涨。
那是因为这个巨大协作网络中开发框架的人,“刚巧”也是用 Python 来封装细节。你们在说同样的语言,因此你可以把他们的研究成果,“拿来”使用。
越来越多的高手都使用 Python 来编写框架、制作工具 ,因此会吸引更多人来用。
越来越多的人习惯用 Python 来完成某项功能,那么开发功能的人也被绑定在这个路径上,只能选择用 Python 来开发。
这样的一个正反馈循环,就像在滚雪球。
你可能很为那些好不容易掌握用 Matlab 做机器学习的人鸣不平,似乎他们才是会真功夫的人。而学了 Python 的人,都有作弊之嫌。
才不会。能掌握 Matlab 的人,都可以很容易学会 Python ,他们也可以立即加入这张协作网络,享受这种便利。
好玩儿的是,2017年, Matlab 开源了一本机器学习教材,供大家免费下载。
你猜群众的反馈是啥?
排在第一位的,是这样:
为什么?人家好心好意给你书,你为何不要?
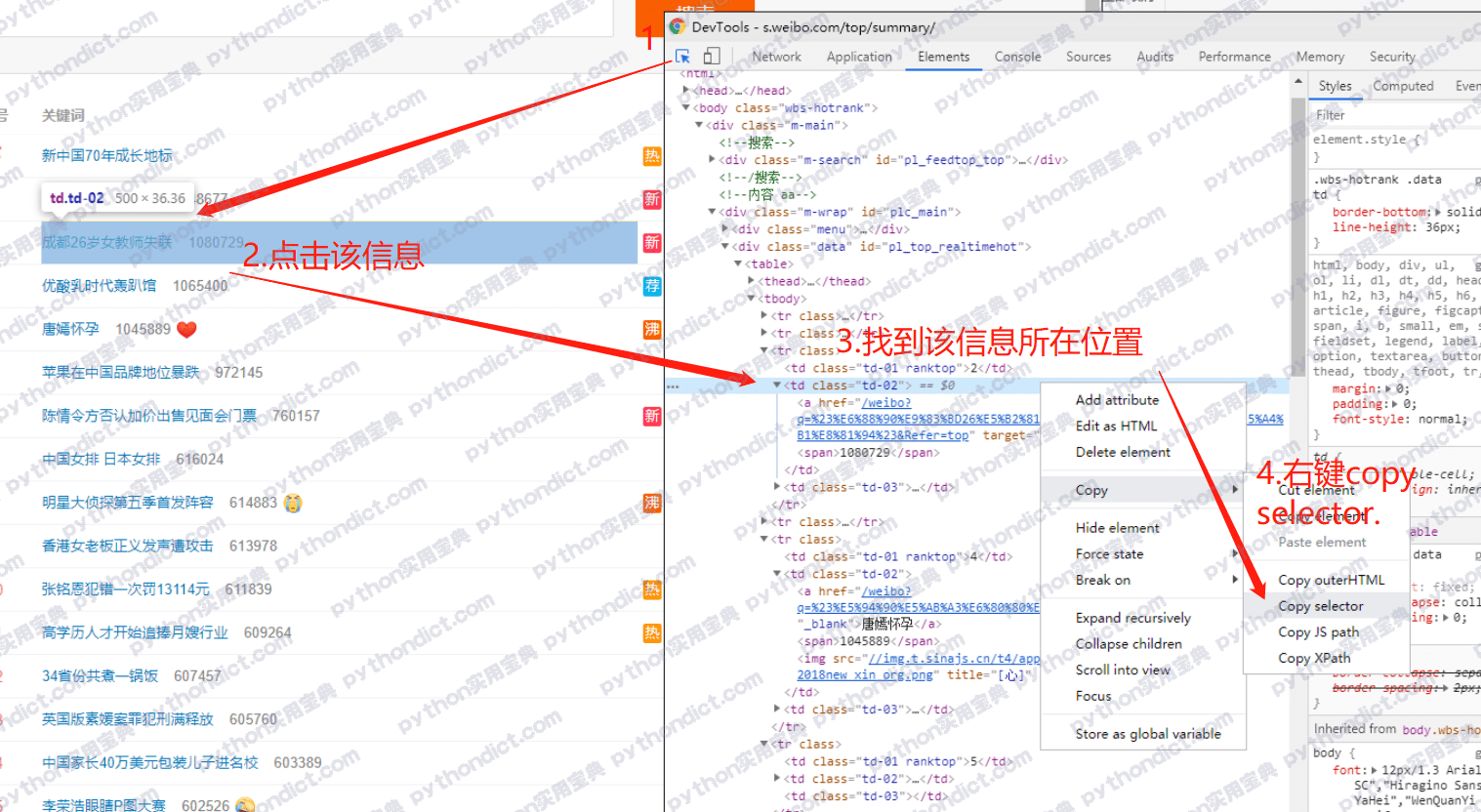
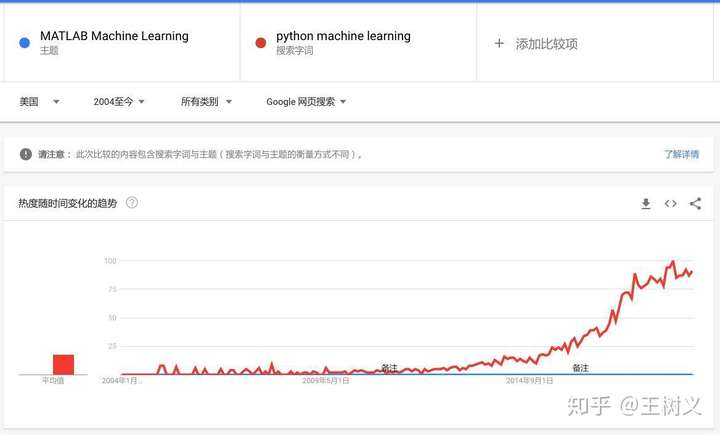
看这个曲线。
这是 Google 趋势上面,用“matlab machine learning”和“python machine learning”分别检索,得来的结果。
可以看到,如果今天你选择用 Matlab 来做机器学习,你的协作网络,和 Python 比起来,小得可以忽略不计。
这网络里面,包括为你打造工具 的高手们,为你提供教程的人,也包括你潜在的合作伙伴……
你是希望自己的网络大一些,还是小一些呢?
方法
了解了 Python 的特点,你也就大略知道,该怎么去学它了。
我见过不少初学者,深吸一口气,摆开阵仗,恨不得投入一年的时间,“系统”掌握它。
其实没必要这么如临大敌。
如果教材编写者假设,儿童都能在一个学期内学会 Python ,你一个受过高等教育的成人,学起来应该更轻松才对。
其实你看现在那些好的 MOOC 里面(主题包括但不限于数据分析、数据可视化、机器学习、深度学习……), Python 学习大概是怎么做的。
他们会说,这门课咱们要用到 Python ,所以,本课程的第3章,是 Python 的学习。
对,Python ,这门编程语言,只占了一章的篇幅。
学一章,就掌握 Python 了?
看你怎么定义“掌握”了。
要是说你对 Python 的知识全面系统获取到了,那简直是在骗人。
就像你学龄前的时候,基本上也算能用中文对话了,对吧?
但是,你知道“回”字有四种写法吗?
人家授课者的意思是,学了这些 Python 知识,在他这门课就算够用了。
后面如果出现没有涉及过的函数或者方法,给你简单说几句,就可以继续学习了。
你千万不要用背单词的方式来学 Python ,那效率会低得惨不忍睹。
说句题外话,即便你用背单词的方式来学英语,我也不推荐。
你学 Python ,就应该是快速掌握一个最小核心技能集,例如知道怎么赋值、怎么判断、怎么循环,然后会自定义一个函数,可以输入输出东西……好了,可以上路了。
因为大部分的工作中,主要就用上述这些功能。遇到不明白的,直接查文档。Python 的文档 ,只要你不嫌弃它太详细就好。
查文档搞不定的问题,也没关系,反正这门语言,世界上有数不清的人都会,论坛 上发帖问呗。这是给别人提供实现自我价值的机会。说实话,这机会不好碰到,说不定有人甚至会感谢你的提问呢。
你看,这样一来,你的技能来自于对真实问题的挑战,这样学起来,你的动力更足,学会之后你的满足感更强。而且,你的记忆,会更加深刻。
资源
学习 Python 的资源,我在《如何高效学Python? 》一文中已经为你详细做过介绍和推荐,这里就不再赘述了。
此处只介绍我最近发现的2个新资源,都是免费的。
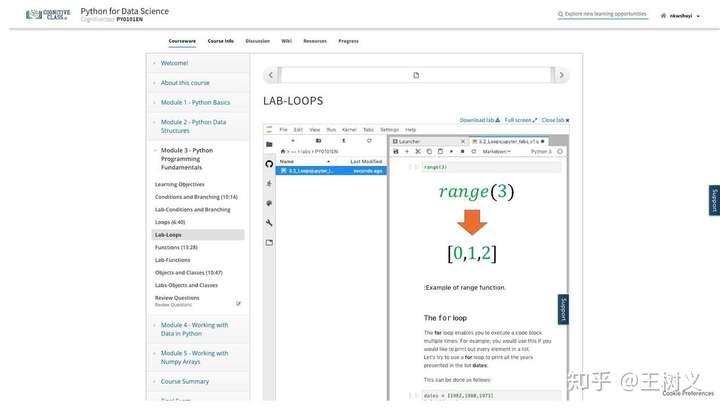
一个是 IBM 提供的系列课程。其中的 Python 基础课,叫做 Python for Data Science ,编号 PY0101EN 。网址在这里 。
除了免费、自主决定学习进度外,这门课的好处在于提供在线的 Jupyter Lab 编程环境。初学者最容易遇到的环境配置陷阱,在这里统统不存在。
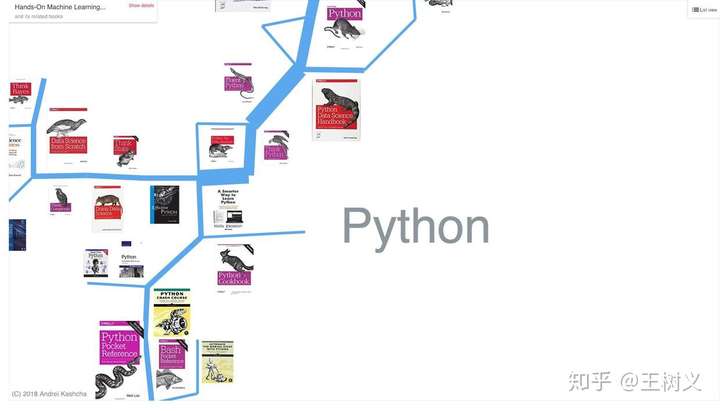
如果你更喜欢读书的方式来学习,这里 有一张交互式的数据科学教材汇总图。
你可以着重看其中的 Python 部分。
注意这张学习路线交互图是免费的。里面介绍的书,有的免费,有的收费。你可以酌情选择。
小结
通过阅读本文,希望你能掌握以下知识点:
首先,Python 本身不是什么独门绝艺,不要被人忽悠,以为学了 Python 就能……;
综上,学 Python ,确实有助于提升你的竞争力。但是再强调一遍,那竞争力,并非来自 Python 本身。
祝学习愉快!
喜欢请点赞和打赏。还可以微信 关注和置顶我的公众号“玉树芝兰”(nkwangshuyi) 。
如果你对 Python 与数据科学感兴趣,不妨阅读我的系列教程索引贴《如何高效入门数据科学? 》,里面还有更多的有趣问题及解法。
作者:gashero
举几个数字,略残酷,希望不要抹杀了大家的积极性。
中国现存程序员约185万人,2017年高等教育毕业人数795万人。截止2017年末,中国高等教育人口总数约1.85亿。
http://www.sohu.com/a/165615021_475887
http://study.ccln.gov.cn/fenke/shehuixue/shjpwz/shfcyld/381468.shtml
虽然程序员中有极少数没有接受过高等教育,但至少主流是受过高等教育的。这个数字至少意味着每年广义电子信息类毕业生总量是超过程序员历史存量的,或者说,即便是学了未来可能做程序员的专业,大部分人也没法做程序员。
好消息是相对其他专业,程序员的薪资较高,没有过多对历史身份的限制,即不管你之前学啥专业,在哪个学校毕业,只要能力符合要求,就可以成为程序员。
成为程序员的最大门槛,就是脑力,我没有用智力这个词,主要是因为希望脑力这个词也包含了长时间大强度用脑的意思,而不仅仅是灵光一现的智力。
很多人推荐大家从Python入门进入程序员,除了如上薪资高,没身份门槛外的优势外。也是希望能够帮助那些有编程天赋的人发现自己的天赋,并成为程序员。
但这种建议并不能确保你学了Python就能成为程序员,可以说绝大部分人学了以后肯定做不了程序员。
假设程序员的平均职业生命是10年,有些人会做的更长,也有很多人早早转行去创业,做销售,做产品、被辞退之类。那么每年会有18.5万职位空缺出来,加上新增职位,可以假设为每年新产生程序员职位约20万。那么新人就是要抢这大约20万个程序员职位。相对毕业人数,大约是2.5%的人可以成为程序员。
所以,做个比喻,不从悬崖上跳下去,你怎么知道你不是鹰呢?不试试Python,你怎么知道自己不适合编程呢?相对于以往死气沉沉熬资历的时代,有个机会能挑战一下自己已经很美好了。