
Excel的数据透视表非常有用,但是Pandas也有这个功能你知道吗?今天我们来对比Excel数据透视表,学习pandas pivot_table
1.Excel中做数据透视表
① 选中整个数据源;
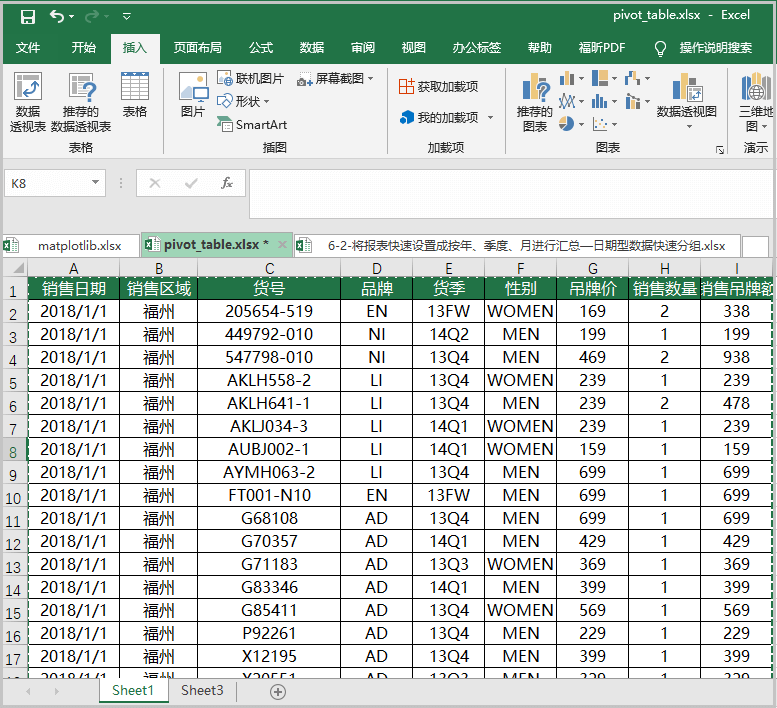
② 依次点击“插入”—“数据透视表”
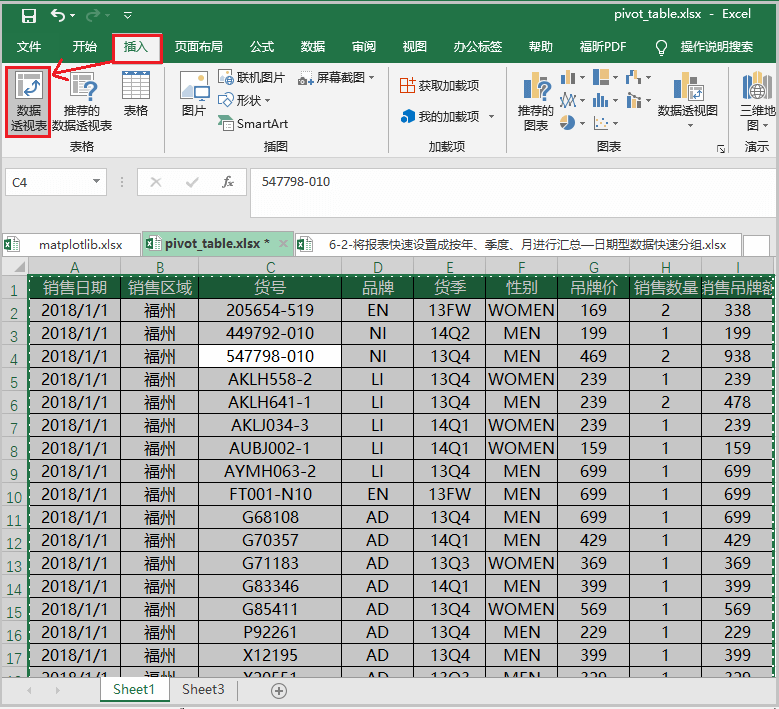
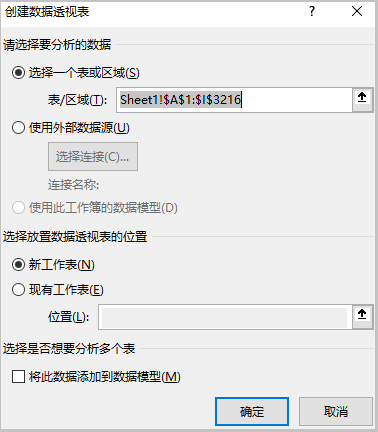
③ 选择在Excel中的哪个位置,插入数据透视表
④ 然后根据实际需求,从不同维度展示结果
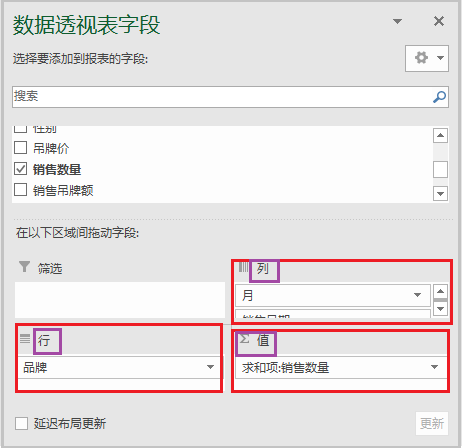
⑤ 结果如下
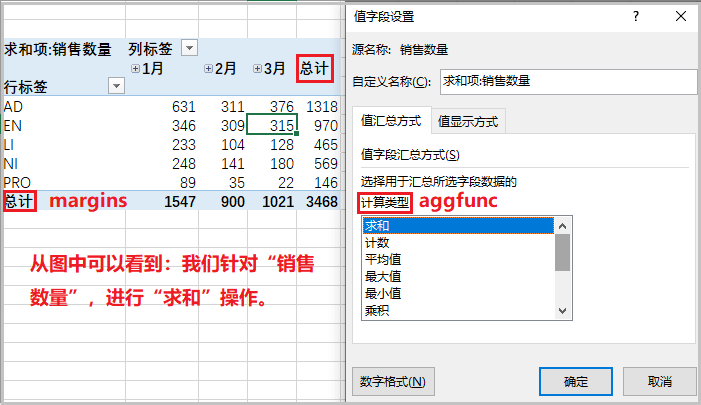
2. pandas 用 pivot_table 做数据透视表
pd.pivot_table(data,index=None,columns=None,
values=None,aggfunc='mean',
margins=False,margins_name='All',
dropna=True,fill_value=None)
2)对比excel,说明上述参数的具体含义
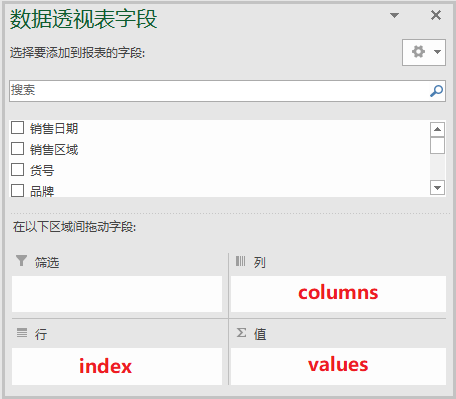
参数说明:
data 相当于Excel中的”选中数据源”;
index 相当于上述”数据透视表字段”中的行;
columns 相当于上述”数据透视表字段”中的列;
values 相当于上述”数据透视表字段”中的值;
aggfunc 相当于上述”结果”中的计算类型;
margins 相当于上述”结果”中的总计;
margins_name 相当于修改”总计”名,为其它名称;
下面几个参数,用的较少,记住干嘛的,等以后需要就百度。
dropna 表示是否删除缺失值,如果为True时,则把一整行全作为缺失值删除;
fill_value 表示将缺失值,用某个指定值填充。
3. 案例说明
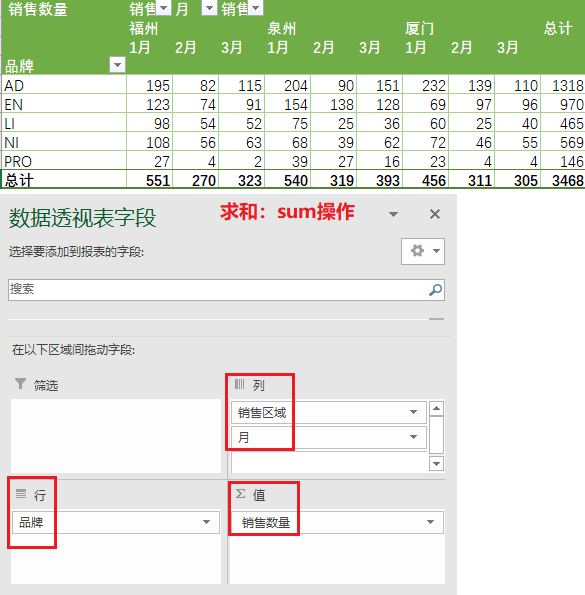
1)求出不同品牌下,每个月份的销售数量之和
① 在Excel中的操作结果如下
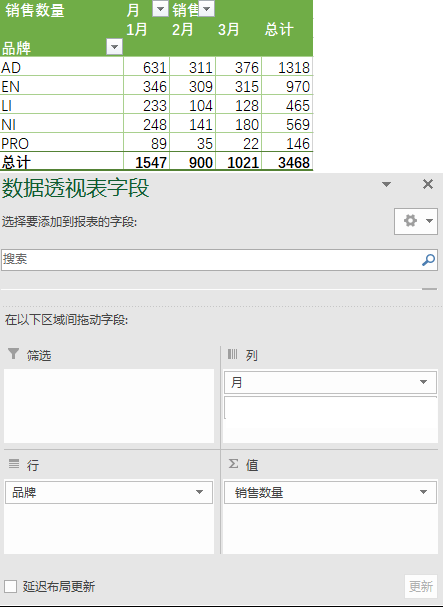
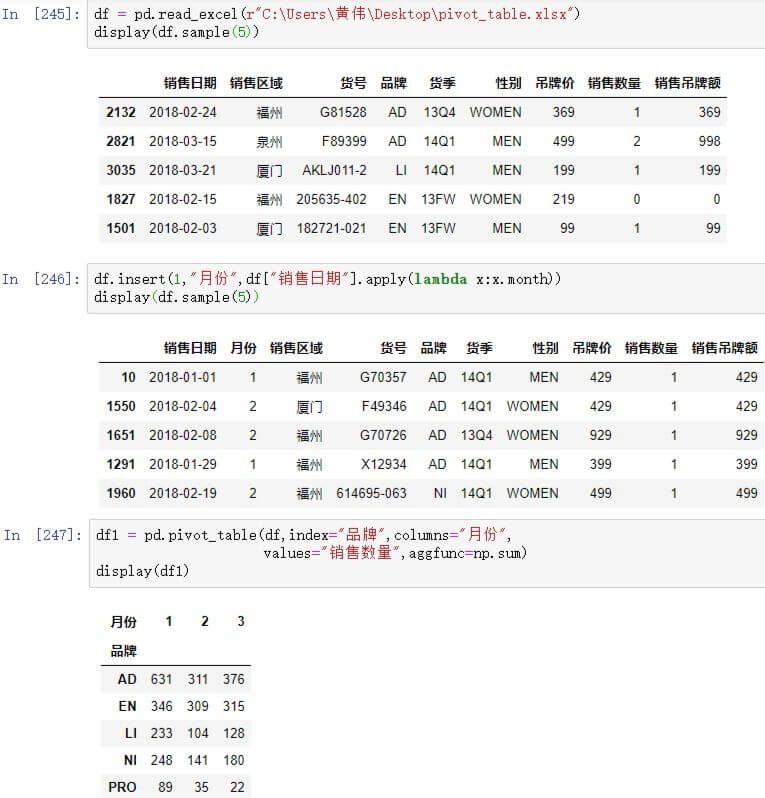
② 在pandas中的操作如下
df = pd.read_excel(r"C:\Users\黄伟\Desktop\pivot_table.xlsx")
display(df.sample(5))
df.insert(1,"月份",df["销售日期"].apply(lambda x:x.month))
display(df.sample(5))
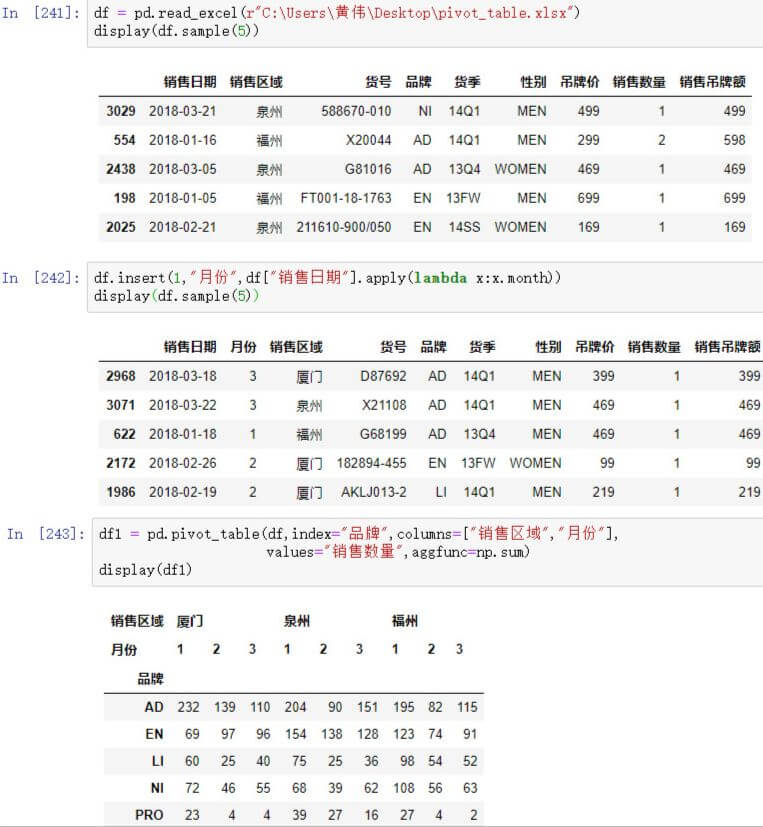
df1 = pd.pivot_table(df,index="品牌",columns="月份",
values="销售数量",aggfunc=np.sum)
display(df1)结果如下:
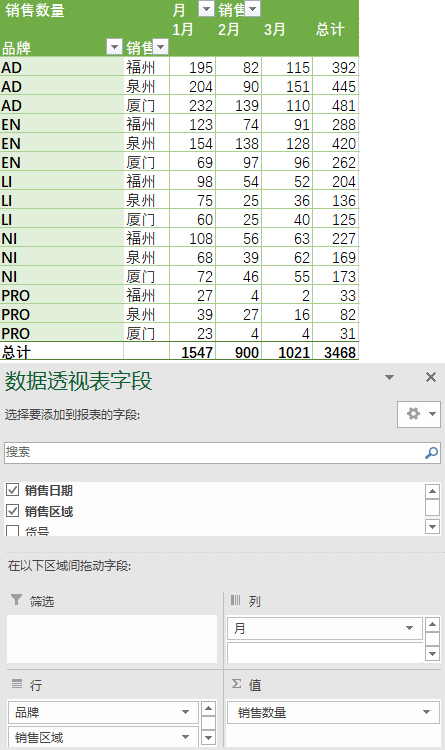
2)求出不同品牌下,每个地区、每个月份的销售数量之和
① 在Excel中的操作结果如下
② 在pandas中的操作如下
df = pd.read_excel(r"C:\Users\黄伟\Desktop\pivot_table.xlsx")
display(df.sample(5))
df.insert(1,"月份",df["销售日期"].apply(lambda x:x.month))
display(df.sample(5))
df1 = pd.pivot_table(df,index="品牌",columns=["销售区域","月份"],
values="销售数量",aggfunc=np.sum)
display(df1)
结果如下:
3)求出不同品牌不同地区下,每个月份的销售数量之和
① 在Excel中的操作结果如下
② 在pandas中的操作如下
df = pd.read_excel(r"C:\Users\黄伟\Desktop\pivot_table.xlsx")
display(df.sample(5))
df.insert(1,"月份",df["销售日期"].apply(lambda x:x.month))
display(df.sample(5))
df1 = pd.pivot_table(df,index=["品牌","销售区域"],columns="月份",
values="销售数量",aggfunc=np.sum)
display(df1)
结果如下:

4)求出不同品牌下的“销售数量之和”与“货号计数”
① 在Excel中的操作结果如下
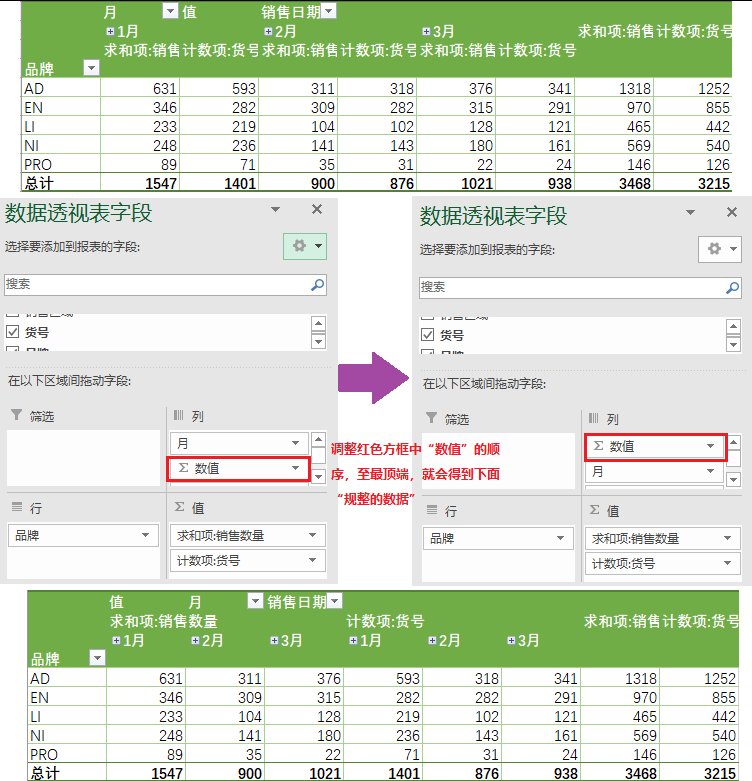
② 在pandas中的操作如下
df = pd.read_excel(r"C:\Users\黄伟\Desktop\pivot_table.xlsx")
display(df.sample(5))
df.insert(1,"月份",df["销售日期"].apply(lambda x:x.month))
display(df.sample(5))
df1 = pd.pivot_table(df,index="品牌",columns="月份",
values=["销售数量","货号"],
aggfunc={"销售数量":"sum","货号":"count"},
margins=True,margins_name="总计")
display(df1)
结果如下:

本文转自凹凸数据。
我们的文章到此就结束啦,如果你喜欢今天的Python 实战教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应红字验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
点击下方阅读原文可获得更好的阅读体验
Python实用宝典 (pythondict.com)
不只是一个宝典
欢迎关注公众号:Python实用宝典
