
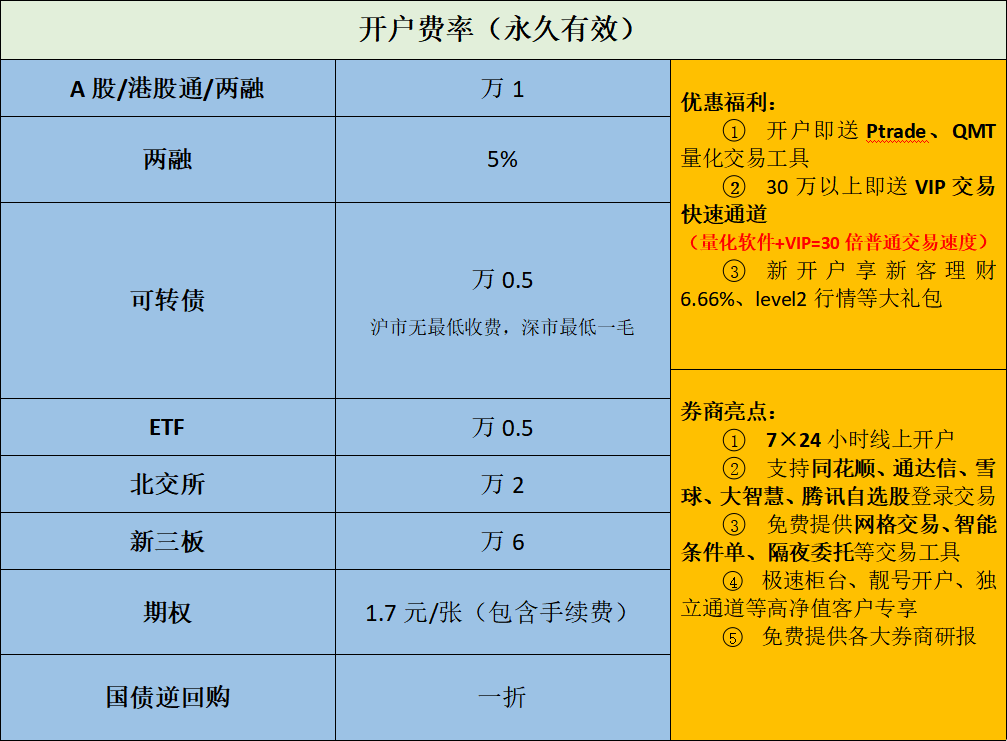
很多喜欢玩量化的同学都想要找一个靠谱且低费率能做自动化的券商。
我之前也推荐过一个渠道,但是因为他们公司内部问题,之前的那个开户渠道也遗憾下线了,今天给大家找到了一个新的渠道,费率如下:



有需要的或有任何疑问的可以直接联系我的微信: 83493903 (备注开户) 进行开通,或扫描二维码开户,有专业人士会跟进后续的开户和功能开通。
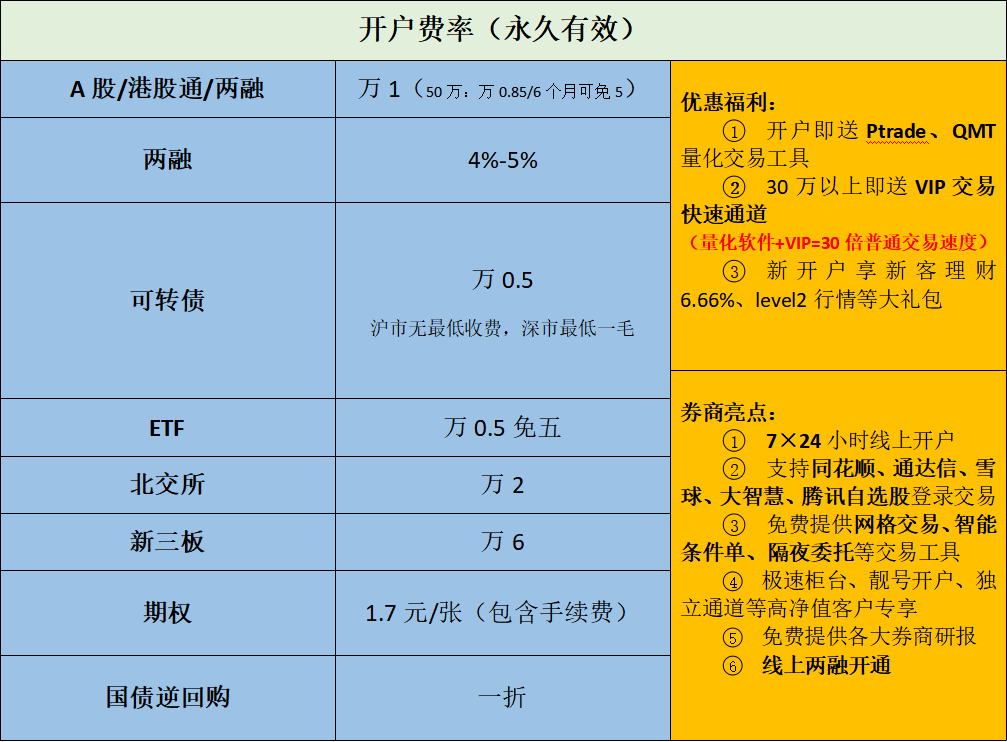
很多喜欢玩量化的同学都想要找一个靠谱且低费率能做自动化的券商。
我之前也推荐过一个渠道,但是因为他们公司内部问题,之前的那个开户渠道也遗憾下线了,今天给大家找到了一个新的渠道,费率如下:
有需要的或有任何疑问的可以直接联系我的微信: 83493903 (备注开户) 进行开通,或扫描二维码开户,有专业人士会跟进后续的开户和功能开通。
以下是二七阿尔量化的AI小机器人关于Copart公司的分析。
科帕特(Copart)是一家美国德克萨斯州达拉斯的在线车辆拍卖和再营销服务商,在北美、欧洲和中东都有业务。
[积极因素]:
[潜在问题]:
分析:基于积极的发展和潜在的担忧,我预测Copart(CPRT)的股价将在未来一周内上涨3-4%(从2023年11月17日到2023年11月24日)。公司强劲的财务表现和增长,以及高流动性,表明它是一个稳健的投资。然而,高负债水平和潜在的存货管理效率不足是可能影响公司盈利能力的潜在问题。
总体而言,公司最近的表现和未来的增长潜力表明它是一个强大的投资。然而,投资者应密切关注公司的债务水平和存货管理,以确保这些问题不会显现出来。在短期内,公司的股价预计将继续上升,受到强烈的市场情绪和公司基本面的推动。

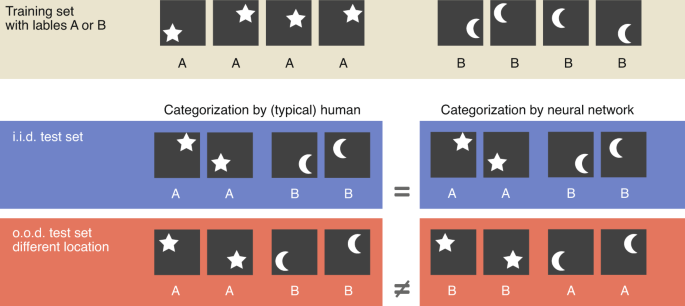
快捷学习(shortcut learning)是指神经网络在训练期间使用某些特定的捷径(shortcut)来完成任务,而这些捷径可能并没有真正理解任务的本质,而是通过记忆一些特定的输入-输出对来完成任务。这种学习方式可能会导致过拟合问题,并且对于新的输入数据可能会产生不准确的预测。
例如,在图像分类任务中,一个神经网络可能会倾向于使用一些表面特征(如颜色或形状)来判断图像属于哪个类别,而没有真正理解该类别的本质特征。这样的模型可能会在训练集上表现出色,但在测试集上的表现可能会受到影响,因为测试集中可能包含了一些不同于训练集的样本。
为了解决快捷学习问题,一些方法包括增加训练数据,使用正则化技术(如dropout),以及设计更复杂的神经网络架构等。
快捷学习通常适用于一些具有高度结构化和规则化特征的任务,例如语音识别、图像分类和机器翻译等。在这些任务中,数据的结构和规律性可以被网络用来发现一些规则和模式,以加速学习过程。此外,快捷学习在一些数据较少的任务中也可以得到较好的表现,因为模型可以从有限的数据中学习并利用一些常见的输入-输出模式来加快训练速度。
但是,快捷学习也存在一些问题,如过拟合和对新数据的泛化性能不佳等问题。因此,在应用快捷学习技术时需要谨慎选择并结合其他方法来提高模型的泛化性能和稳健性。
股市分类问题通常是一个高度复杂和非线性的问题,由于股票市场的复杂性,快捷学习可能并不适合用于该领域的任务。
股票市场的特征和趋势是难以预测和解释的,因此需要更深入和细致的分析和建模。相反,快捷学习更适合处理具有明显规则和结构的数据,例如语音、图像和自然语言处理等领域。
在股票市场的分类问题中,需要考虑各种不同的影响因素,例如市场走势、经济政策、公司业绩等等。因此,更适合使用一些复杂的深度学习方法来处理这些数据,例如循环神经网络(RNN)和卷积神经网络(CNN)。这些方法可以更好地捕捉到不同特征之间的复杂关系,并提高模型的泛化性能。
比如对于450W数据量的股市数据,由于数据量较大,可以考虑使用一些比较复杂的深度学习模型来进行建模。以下是几种可能适合的模型:
综上所述,对于450W数据量的股市数据,可以尝试使用一些复杂的深度学习模型,例如CNN、LSTM和注意力机制等,以提高预测的准确性和稳定性。但是,选择哪种模型还需要考虑具体的问题和数据特征,需要进行实验和调整来选择最适合的模型。
开始之前,你要确保Python和pip已经成功安装在电脑上,如果没有,请访问这篇文章:超详细Python安装指南 进行安装。
(可选1) 如果你用Python的目的是数据分析,可以直接安装Anaconda:Python数据分析与挖掘好帮手—Anaconda,它内置了Python和pip.
(可选2) 此外,推荐大家用VSCode编辑器来编写小型Python项目:Python 编程的最好搭档—VSCode 详细指南
Windows环境下打开Cmd(开始—运行—CMD),苹果系统环境下请打开Terminal(command+空格输入Terminal),输入命令安装依赖:
pip install pandas pip install numpy pip install scikit-learn pip install keras
获取数据
首先,你需要准备好股市秒级数据,这个文件的内容如下(可以在二七阿尔公众号后台回复秒级数据获取):
ts_code,trade_time,open,high,low,close,volume,amount 000001.SH,2021-10-08 15:00:00.0000000+08:00,3599.8,3600.0,3599.8,3600.0,0,0 000001.SH,2021-10-08 14:59:59.0000000+08:00,3599.8,3599.8,3599.7,3599.7,0,0 000001.SH,2021-10-08 14:59:58.0000000+08:00, ...
其中包含了某只股票的每秒开盘价、最高价、最低价、收盘价和成交量等信息。
然后,你需要对数据进行预处理,例如归一化、划分训练集和测试集、构造输入和输出等。这里我们假设你想用前10秒的数据来预测下一秒的涨跌情况,即二分类问题。我们可以用以下代码实现:
import pandas as pd
import numpy as np
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
# 读取数据
data = pd.read_csv("stock_data.csv")
# 归一化数据
scaler = MinMaxScaler()
data_scaled = scaler.fit_transform(data)
# 构造输入和输出
X = []
y = []
seq_len = 10 # 前10秒作为输入
for i in range(seq_len, len(data_scaled)):
X.append(data_scaled[i-seq_len:i]) # 输入是10秒的数据
y.append(1 if data_scaled[i][3] > data_scaled[i-1][3] else 0) # 输出是下一秒的涨跌情况
X = np.array(X)
y = np.array(y)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)接下来,你需要搭建一个CNN模型来对输入进行特征提取和分类。这里我们使用Keras框架来实现一个简单的CNN模型,包含两个卷积层、两个池化层和一个全连接层:
from keras.models import Sequential from keras.layers import Conv1D, MaxPooling1D, Flatten, Dense # 定义模型参数 input_shape = (seq_len, 5) # 输入形状是(10, 5),即10秒的5个特征值 num_classes = 2 # 输出类别数是2,即涨或跌 # 搭建模型结构 model = Sequential() model.add(Conv1D(filters=32, kernel_size=3, activation="relu", input_shape=input_shape)) # 第一个卷积层,使用32个3大小的卷积核,并使用relu激活函数 model.add(MaxPooling1D(pool_size=2)) # 第一个池化层,使用2大小的池化窗口,并默认使用最大池化方法 model.add(Conv1D(filters=64, kernel_size=3, activation="relu")) # 第二个卷积层,使用64个3大小的卷积核,并使用relu激活函数 model.add(MaxPooling1D(pool_size=2)) # 第二个池化层,使用2大小的池化窗口,并默认使用最大池化方法 model.add(Flatten()) # 将多维度的输出展平为一维度的向量,以便输入全连接层 model.add(Dense(units=num_classes, activation="softmax")) # 全连接层,使用softmax激活函数输出类别概率 # 编译模型并查看摘要信息 model.compile(optimizer="adam", loss="sparse_categorical_crossentropy", metrics=["accuracy"]) model.summary()
最后,你需要训练模型并评估其性能。这里我们使用20个epoch来训练模型,并在每个epoch结束后在测试集上进行评估:
# 定义训练参数
epochs = 20 # 训练轮数
batch_size = 32 # 批次大小
# 训练模型并在测试集上评估
for epoch in range(epochs):
model.fit(X_train, y_train, batch_size=batch_size) # 在训练集上训练模型
loss, acc = model.evaluate(X_test, y_test) # 在测试集上评估模型
print(f"Epoch {epoch+1}: loss={loss:.4f}, acc={acc:.4f}") # 打印损失和准确率这样,你就完成了一个Python的CNN模型分类股市秒级数据的示例。希望对你有帮助。👍
我们的文章到此就结束啦,如果你喜欢今天的 Python 教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 ( pythondict.com )
不只是一个宝典
欢迎关注公众号:Python实用宝典


当期货价格高于现货价格时,投资者可以通过期现套利策略,获得低风险、高回报的投资收益。本文将介绍期现套利的基本概念和实现方式,并提供Python代码示例。
期现套利是一种通过利用现货市场和期货市场价格之间的差异进行投资的策略。当期货价格高于现货价格时,可以通过买入现货和卖出期货的方式进行套利,从而获得利润。
开始之前,你要确保Python和pip已经成功安装在电脑上,如果没有,请访问这篇文章:超详细Python安装指南 进行安装。
(可选1) 如果你用Python的目的是数据分析,可以直接安装Anaconda:Python数据分析与挖掘好帮手—Anaconda,它内置了Python和pip.
(可选2) 此外,推荐大家用VSCode编辑器来编写小型Python项目:Python 编程的最好搭档—VSCode 详细指南
Windows环境下打开Cmd(开始—运行—CMD),苹果系统环境下请打开Terminal(command+空格输入Terminal),输入命令安装依赖:
期现套利可以通过以下步骤实现:
2.1 确定现货和期货的标的资产,并获取其价格数据。可以使用Python中的yfinance模块获取股票和期货的价格数据。
import yfinance as yf
# 获取标的现货价格
underlying_stock = yf.Ticker("AAPL")
underlying_stock_price = underlying_stock.history(period="1d")["Close"][0]
# 获取期货价格
futures_contract = "ES=F"
futures_data = yf.download(futures_contract, period="1d")
futures_price = futures_data["Close"][0]2.2 计算期货溢价或折价,并确定买卖方向。如果期货价格高于现货价格,则进行空头套利,即卖出期货合约,买入现货资产;反之,则进行多头套利,即买入期货合约,卖出现货资产。
# 计算期货溢价或折价
futures_premium = futures_price - underlying_stock_price
# 进行期现套利
if futures_premium > 0:
# 期货折价,买入期货,卖出现货
futures_quantity = 1
underlying_stock_quantity = round(futures_price / underlying_stock_price, 2)
print(f"买入 {futures_quantity} 手期货,卖出 {underlying_stock_quantity} 股现货")
else:
# 期货溢价,卖出期货,买入现货
futures_quantity = 1
underlying_stock_quantity = round(futures_price / underlying_stock_price, 2)
print(f"卖出 {futures_quantity} 手期货,买入 {underlying_stock_quantity} 股现货")期现套利是一种通过利用现货市场和期货市场价格差异进行投资的策略,需要投资者在现货和期货市场中具有一定的交易经验和分析能力。通过使用Python等程序化交易工具,投资者可以更加高效地实现期现套利策略。
股票估值是根据公司的财务数据和市场环境,计算出公司的内在价值,从而决定股票的价格。以下是一些常见的股票估值方法:
以上这些方法都有各自的优缺点,投资者可以根据自己的风险偏好、投资目标和投资策略,选择最适合自己的股票估值方法。而本文的重点,将介绍股利折现模型的原理及其计算方法。

股利折现模型是一种估值方法,用于计算一家公司的股票内在价值。该模型的基本假设是,公司未来的股利和股票价格应该是成比例的。因此,该模型基于两个关键要素:预期股利和股利的折现率。
股利折现模型的计算公式如下:
股票价格 = 每股股利 / (折现率 – 成长率)
其中,每股股利是指公司未来每股的预期股利,折现率是指投资者期望从股票投资中获得的回报率,成长率是指公司未来股利的增长率。
该模型的基本思想是,将未来的现金流折现回当前的价值,以便更准确地估算当前股票的内在价值。如果当前股票价格低于计算出的内在价值,则股票被认为是被低估的,可以被认为是购买的好时机。
股利折现模型的优点是可以考虑公司未来的盈利增长,以及投资者对股票的回报要求。但是,该模型的缺点是它基于一些假设,如股利的增长率是稳定的、折现率不变等,这些假设可能不符合实际情况。此外,该模型也无法考虑公司的负债情况、市场竞争等外部因素的影响。因此,投资者在使用股利折现模型进行估值时应该同时考虑其他因素,以得到更全面和准确的估值结果。

公司未来每股的预期股利是股利折现模型的一个重要参数,对于准确估值非常重要。以下是一些方法可以用来判断公司未来每股的预期股利:
需要注意的是,股利预测不是绝对准确的,未来的市场和经济环境都是不确定的,因此需要综合考虑多种因素,以得到更准确的股利预测。另外,不同的股利预测方法可能会得出不同的结果,投资者应该根据自己的风险偏好和投资目标,选择最适合自己的股利预测方法。
下面我们将实现一个简单的Python股利折现模型计算。
下面是一个用Python实现股利折现模型的例子,假设公司未来10年每年的股利分别为2, 2.2, 2.4, 2.6, 2.8, 3, 3.2, 3.4, 3.6和3.8元,且未来的股利增长率为5%,投资者对该股票的回报要求为10%。
def dividend_discount_model(dividends, discount_rate, growth_rate):
# 计算股利折现模型的股票价格
present_value = 0
for i in range(len(dividends)):
present_value += dividends[i] / (1 + discount_rate) ** (i + 1)
terminal_value = dividends[-1] * (1 + growth_rate) / (discount_rate - growth_rate)
stock_price = present_value + terminal_value / (1 + discount_rate) ** (len(dividends))
return stock_price
dividends = [2, 2.2, 2.4, 2.6, 2.8, 3, 3.2, 3.4, 3.6, 3.8] # 未来10年每年的股利
discount_rate = 0.1 # 投资者对该股票的回报要求为10%
growth_rate = 0.05 # 股利增长率为5%
stock_price = dividend_discount_model(dividends, discount_rate, growth_rate)
print("股票价格为:", round(stock_price, 2), "元")输出结果为:
股票价格为: 35.37 元
以上代码实现了一个简单的股利折现模型,通过输入股票未来每年的股利、投资者对该股票的回报要求和股利增长率等参数,计算出该股票的内在价值。需要注意的是,股利折现模型并不是唯一的估值方法,投资者应该综合考虑多种因素进行估值,以得到更准确的结果。
我们的文章到此就结束啦,如果你喜欢今天的 Python 教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 ( pythondict.com )
不只是一个宝典
欢迎关注公众号:Python实用宝典
很多玩股票的朋友都希望能通过计算机来自动买入卖出股票,这样的作法在美股中很常见,但在A股由于监管的问题,从前我们的做法是通过Easytrader来实现股票的自动买入和卖出,但是这种做法会让交易时延达到1秒左右,而现在,通过QMT我们能直接将这1秒的延迟直接消除。
通过QMT的交易接口,我们能实现毫秒级的交易时延,比Easytrader速度快不少。这非常重要,要知道对于交易热门的股票,差1秒,买入价差可能就差5档。
本文将教大家如何使用QMT进行基础的简单买入卖出和撤单的功能,在本文的最后会介绍仅需3万门槛且起步仅0.5元的QMT开通通道。
QMT程序可以在我们公众号后台回复 QMT 下载。
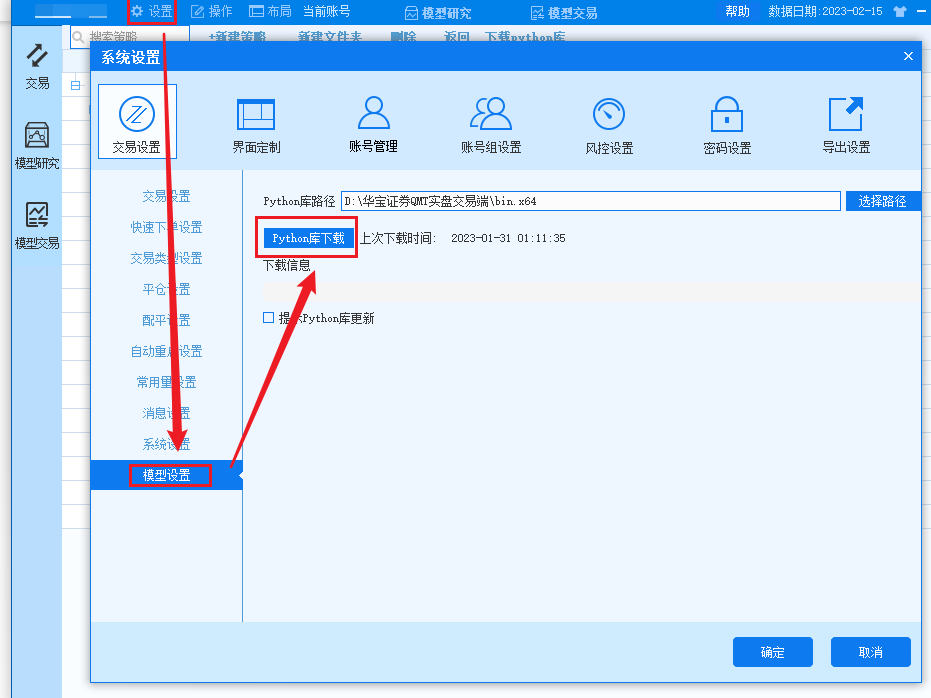
下载登陆后,请先安装Python,在设置->模型设置中,点击Python库下载即可:
然后,要实现自动交易的功能,我们必须在模型研究中,新建一个策略:
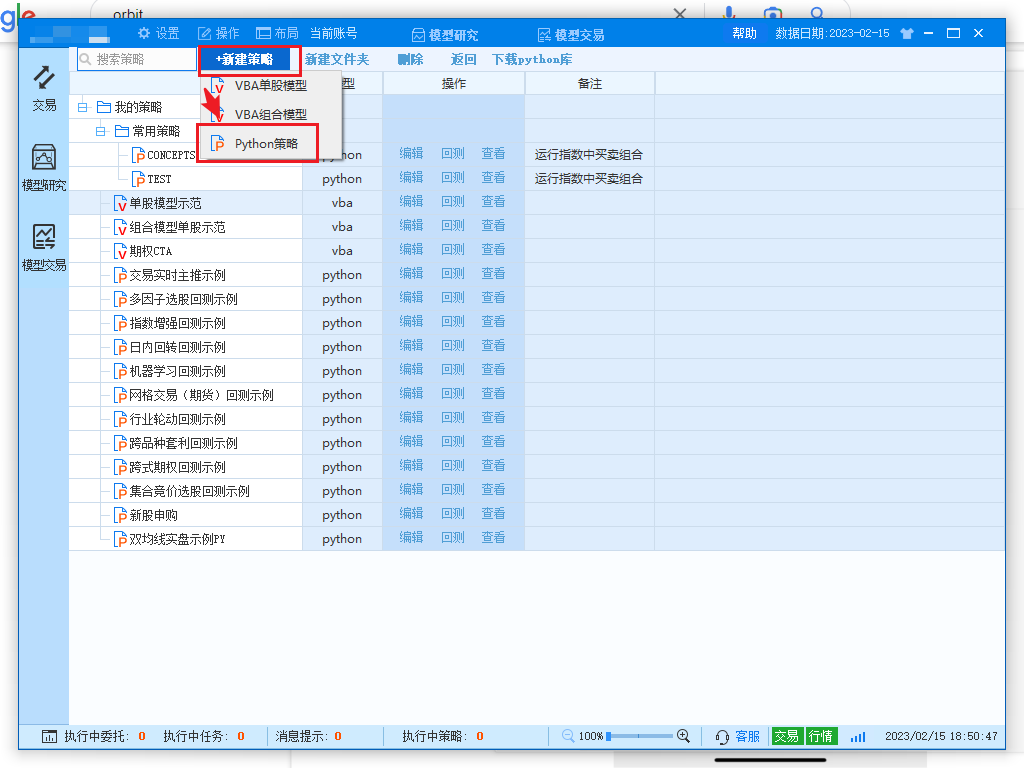
然后就会弹出一个策略的编辑器,在这里会编辑我们的买入卖出策略:
QMT的基本执行结构是:
# 公众号:二七阿尔量化
def init(ContextInfo):
ContextInfo.accID = '你的账号ID'
def handlebar(ContextInfo):
# 处理K线
pass
下面会一步一步地讲解如何基于这个基本结构制作我们的根据信号买入卖出策略。
定时器
定时器是我们实现毫秒级策略的基础。在QMT中,执行是按照K线来的,比如分钟K线,日线等K线类型,新的一根bar到来后,就进入handle_bar函数被用户处理。但是这样按K线执行的逻辑有一个严重的问题,那就是无法执行秒级、毫秒级的策略。
如果你需要执行毫秒级的策略,就需要用到定时器了:
# 公众号:二七阿尔量化
ContextInfo.run_time("buy_logic", "100nMilliSecond", "2019-10-14 13:20:00")
这行代码的意思便是从2019-10-14 13:20:00开始,每隔100毫秒执行一次 buy_logic 函数。
只需要把这行代码放在 init 函数下,便会启动定时器。
买入卖出
首先介绍如何在QMT中实现自动买入卖出。QMT的买入卖出函数都是 passorder,通过传参实现不同的操作,比如:
passorder(23, 1102, account_id, "002587", 11, 6.80, 55000, "concepts_main", 1, "", ContextInfo)
看不懂不要紧,我们先往下看。
对于股票交易,它的参数列表如下:
passorder(opType, orderType, accountid, orderCode, prType, modelprice, volume, strategyName, quickTrade, ContextInfo)
opType: 我们上述例子中 opType 为 23,意思为 股票买入,或沪港通、深港通股票买入。对于股票的交易,它只有两种选项:
23: 股票买入,或沪港通、深港通股票买入 24: 股票卖出,或沪港通、深港通股票卖出
orderType: 这个参数是能让你指定 按股买入/按金额买入/按总资产比例买入/按可用比例买入某只股票,非常好用:
1101: 单股、单账号、普通、股/手方式下单(ETF申赎只能用此参数) 1102: 单股、单账号、普通、金额(元)方式下单(只支持股票) 1113: 单股、单账号、总资产、比例[0~1]方式下单 1123: 单股、单账号、可用、比例[0~1]方式下单
account_id: 用户ID,即你的股票账户名。
orderCode: 股票代码,不要添加任何后缀。
prType: 下单选价类型,可以选择以下委托方式
0:卖5价 1:卖4价 2:卖3价 3:卖2价 4:卖1价 5:最新价 6:买1价 7:买2价(组合不支持) 8:买3价(组合不支持) 9:买4价(组合不支持) 10:买5价(组合不支持) 11:(指定价)模型价(只对单股情况支持,对组合交易不支持) 12:涨跌停价 13:挂单价 14:对手价 26:限价即时全部成交否则撤单[上交所|深交所][期权] 27:市价即成剩撤[上交所][期权] 28:市价即全成否则撤[上交所][期权] 29:市价剩转限价[上交所][期权] 42:最优五档即时成交剩余撤销申报[上交所][股票] 43:最优五档即时成交剩转限价申报[上交所][股票] 44:对手方最优价格委托[深交所][股票][期权] 45:本方最优价格委托[深交所][股票][期权] 46:即时成交剩余撤销委托[深交所][股票][期权] 47:最优五档即时成交剩余撤销委托[深交所][股票][期权] 48:全额成交或撤销委托[深交所][股票][期权]
请注意,在今天全面注册制后,正常交易存在价格笼子(挂单最多只能在当前最新价上浮动2%),所以除了在集合竞价中使用涨跌停价(12),其他情况都不要使用。
modelprice: 指定买入价格,只有当prType是模型价时price有效;其它情况无效。
volume: 决定买入的量,根据orderType值最后一位确定volume的单位:
# 当orderType最后一位为: 1:股/手 2:金额(元) 3:比例
strategyName: 策略名称,按你喜好来定即可
quickTrade: 是否立马触发下单,0 否,1 是
ContextInfo: QMT的上下文,必须传递,保持变量不变即可。
然后我们再回过头来看这行代码:
# 公众号: 二七阿尔量化 passorder(23, 1102, account_id, "002587", 11, 6.80, 55000, "concepts_main", 1, "", ContextInfo)
它的意思是,用户(参数2) 以指定金额的方式(参数1) 买入(参数0) 股票002587(参数3), 按照指定价(参数4) 6.80 元的价格(参数5), 希望可以成交 55000 元(参数6).
现在,不看我的答案的情况下,尝试理解下面这行卖出代码:
# 公众号: 二七阿尔量化 passorder(24, 1123, account_id, "002587", 12, 0, 1, "concepts_main", 1, "", ContextInfo)
答案是用户(参数2) 以可用比例的方式(参数1) 卖出(参数0) 股票002587(参数3), 按照涨跌停价(参数4) (参数5随意), 希望可以 100% (参数6) 成交。
获取仓位
仓位的获取也很简单,只需要传递account_id,第二个参数指定 “STOCK”(股票), 第三个参数指定为”POSITION”(仓位)即可:
# 公众号: 二七阿尔量化 positions = get_trade_detail_data(account_id, "STOCK", "POSITION")
获取委托
委托列表和仓位列表的获取方式都是通过get_trade_detail_data函数,只不过第三个参数改为”ORDER”
# 公众号: 二七阿尔量化 get_trade_detail_data(account_id, "STOCK", "ORDER"):
如果你希望一个线程检测是否买入某只股票、另一个线程检测是否需要撤单,还有一个线程进行卖出操作,那么你可以这么做:
# encoding:gbk
# 公众号: 二七阿尔量化
import time
import datetime
account_id = ""
def init(ContextInfo):
ContextInfo.accID = account_id
ContextInfo.max_buy = 3
ContextInfo.run_time("buy_logic", "100nMilliSecond", "2019-10-14 13:20:00", 'SZ')
ContextInfo.run_time("cancel_logic", "1000nMilliSecond", "2019-10-14 13:20:00", 'SZ')
ContextInfo.run_time("sell_logic", "300nMilliSecond", "2019-10-14 13:20:00", 'SZ')
def handlebar(ContextInfo):
pass
def buy_logic(ContextInfo):
"""
你的买入逻辑
"""
pass
def cancel_logic(ContextInfo):
"""
你的撤单逻辑
"""
pass
def sell_logic(ContextInfo):
"""
你的卖出逻辑
"""
pass
这三个run_time的意思是分别按每100毫秒执行买入逻辑、每1秒执行撤单逻辑,每300毫秒执行卖出逻辑。
只需要一个程序就能完成这三件事,用过Easytrader的同学一下就会明白这比Easytrader好用多了。
我们有一个相对完整的根据信号买入卖出的代码,在开户入金完成后,公众号后台回复:QMT代码 联系我获取代码。
填充完你的各种逻辑后,保存程序,点击模型交易
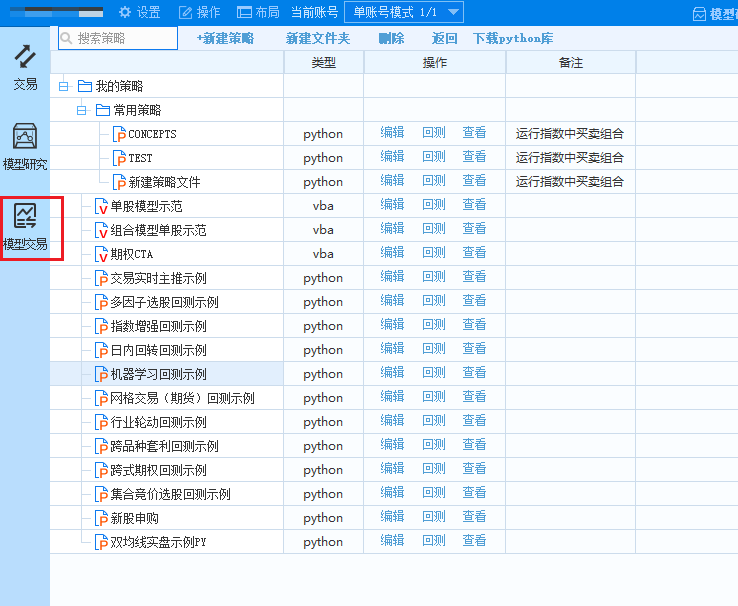
选择左上角的新建策略交易,找到你刚刚保存的策略:
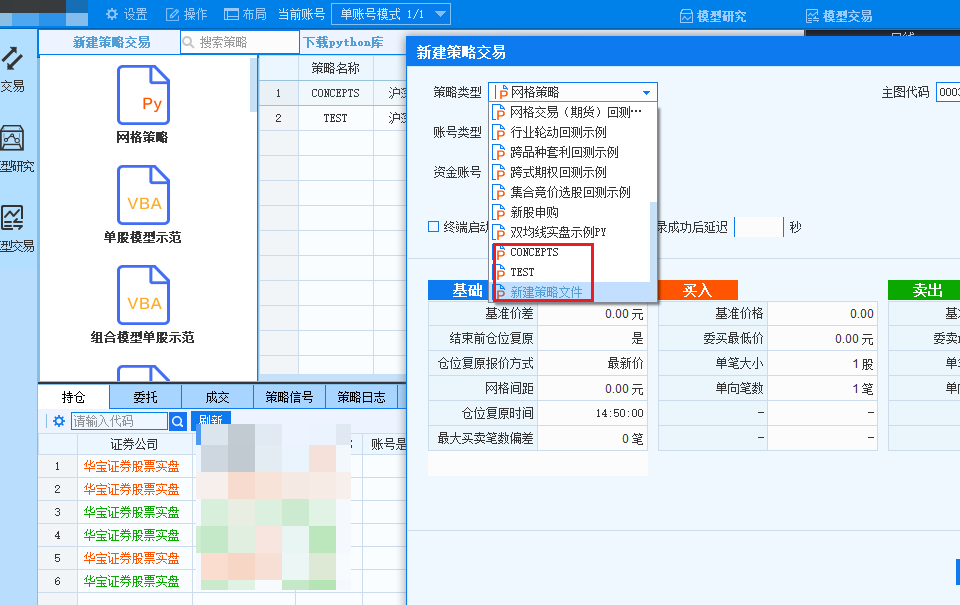
选择好账号类型和资金账号,确定后便可以准备开始运行策略,点击运行模式可以切换实盘/模拟盘。点击操作里的三角形便可以启动策略。
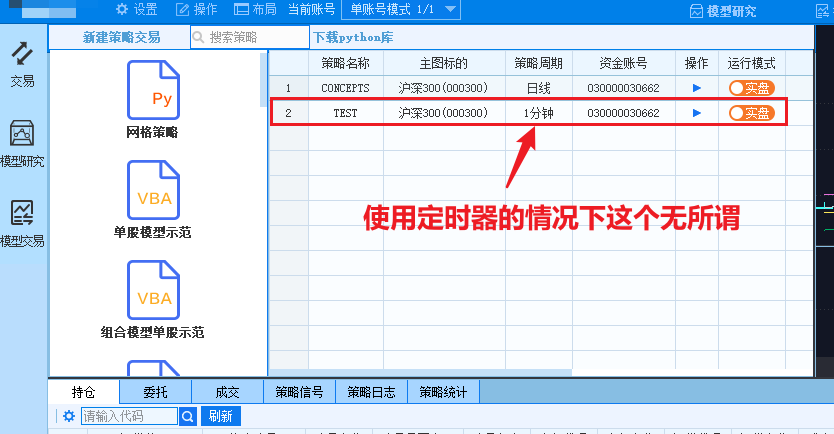
如果你是按本文定时器的方法使用QMT,你不需要在意策略周期。
本文对QMT的基本介绍结束,根据我这半个月的使用经历,我认为QMT对于我们量化交易而言是非常值得使用的,平均成交时间会比Easytrader方法快1秒左右。此外也不需要开启多个Easytrader进程去按键精灵般点点点,基本不会出现报错的情况。
我们的文章到此就结束啦,如果你喜欢今天的 Python 教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 ( pythondict.com )
不只是一个宝典
欢迎关注公众号:Python实用宝典
Bulbea 是一个基于深度学习开发的,用于股票市场预测和建模的Python库。
Bulbea 自带了不少可用于股票深度学习训练及测试的API,并且易于对数据进行扩展和延申,构建属于我们自己的数据及模型。
下面就来介绍一下这个模块。
开始之前,你要确保Python和pip已经成功安装在电脑上,如果没有,请访问这篇文章:超详细Python安装指南 进行安装。
(可选1) 如果你用Python的目的是数据分析,可以直接安装Anaconda:Python数据分析与挖掘好帮手—Anaconda,它内置了Python和pip.
(可选2) 此外,推荐大家用VSCode编辑器来编写小型Python项目:Python 编程的最好搭档—VSCode 详细指南
Windows环境下打开Cmd(开始—运行—CMD),苹果系统环境下请打开Terminal(command+空格输入Terminal),输入命令安装依赖:
git clone https://github.com/achillesrasquinha/bulbea.git && cd bulbea pip install -r requirements.txt python setup.py install
如果你无法访问Github,请在二七阿尔量化后台回复Bulbea下载项目镜像(2022-11-28).
此外,你还需要安装 Tensorflow 的CPU版本或GPU版本:
pip install tensorflow # CPU 版本 pip install tensorflow-gpu # GPU 版本 - 需要 CUDA, CuDNN
Bulbea 和普通的深度学习研究项目一样,在做训练和测试时,分为四步(加载数据,预处理,建模,测试)。
Bulbea内置了数据下载模块,让你很轻易地能够下载雅虎财经的股票数据,比如下面下载雅虎财经源的GOOGL股票数据:
>>> import bulbea as bb
>>> share = bb.Share('YAHOO', 'GOOGL')
>>> share.data
# Open High Low Close Volume \
# Date
# 2004-08-19 99.999999 104.059999 95.959998 100.339998 44659000.0
# 2004-08-20 101.010005 109.079998 100.500002 108.310002 22834300.0
# 2004-08-23 110.750003 113.479998 109.049999 109.399998 18256100.0
# 2004-08-24 111.239999 111.599998 103.570003 104.870002 15247300.0
# 2004-08-25 104.960000 108.000002 103.880003 106.000005 9188600.0
...Bulbea 同样也内置了预处理模块,让你能够轻易地分割训练集和测试集:
>>> from bulbea.learn.evaluation import split >>> Xtrain, Xtest, ytrain, ytest = split(share, 'Close', normalize = True)
Bulbea自带了RNN模型可供使用:
>>> import numpy as np >>> Xtrain = np.reshape(Xtrain, (Xtrain.shape[0], Xtrain.shape[1], 1)) >>> Xtest = np.reshape( Xtest, ( Xtest.shape[0], Xtest.shape[1], 1)) >>> from bulbea.learn.models import RNN >>> rnn = RNN([1, 100, 100, 1]) # number of neurons in each layer >>> rnn.fit(Xtrain, ytrain) # Epoch 1/10 # 1877/1877 [==============================] - 6s - loss: 0.0039 # Epoch 2/10 # 1877/1877 [==============================] - 6s - loss: 0.0019 ...
通过调用sklearn的metrics就能对数据实现测试:
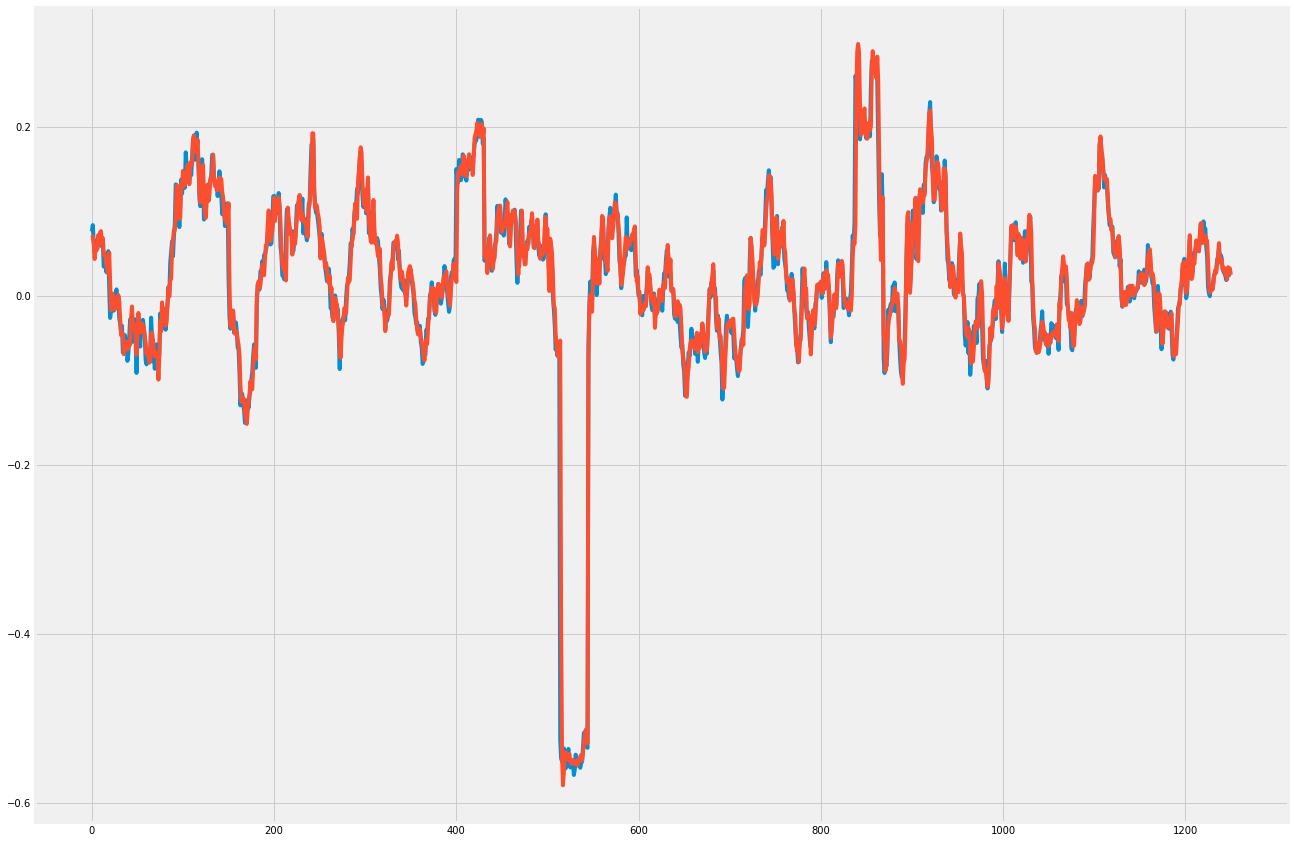
>>> from sklearn.metrics import mean_squared_error >>> p = rnn.predict(Xtest) >>> mean_squared_error(ytest, p) 0.00042927869370525931 >>> import matplotlib.pyplot as pplt >>> pplt.plot(ytest) >>> pplt.plot(p) >>> pplt.show()
Bulbea 能自动爬取相关股票在推特上的文字,并对这些文字做一个情感分析。
你只需要给Bulbea提供以下环境变量就能够进行感情色彩分析:
export BULBEA_TWITTER_API_KEY="<YOUR_TWITTER_API_KEY>" export BULBEA_TWITTER_API_SECRET="<YOUR_TWITTER_API_SECRET>" export BULBEA_TWITTER_ACCESS_TOKEN="<YOUR_TWITTER_ACCESS_TOKEN>" export BULBEA_TWITTER_ACCESS_TOKEN_SECRET="<YOUR_TWITTER_ACCESS_TOKEN_SECRET>"
测试一下:
>>> import bulbea as bb
>>> share = bb.Share('YAHOO', 'GOOGL')
>>> bb.sentiment(share)
0.07580128205128206当然,这个分析仅供参考,太粗略了。
我们的文章到此就结束啦,如果你喜欢今天的 Python 教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 ( pythondict.com )
不只是一个宝典
欢迎关注公众号:Python实用宝典
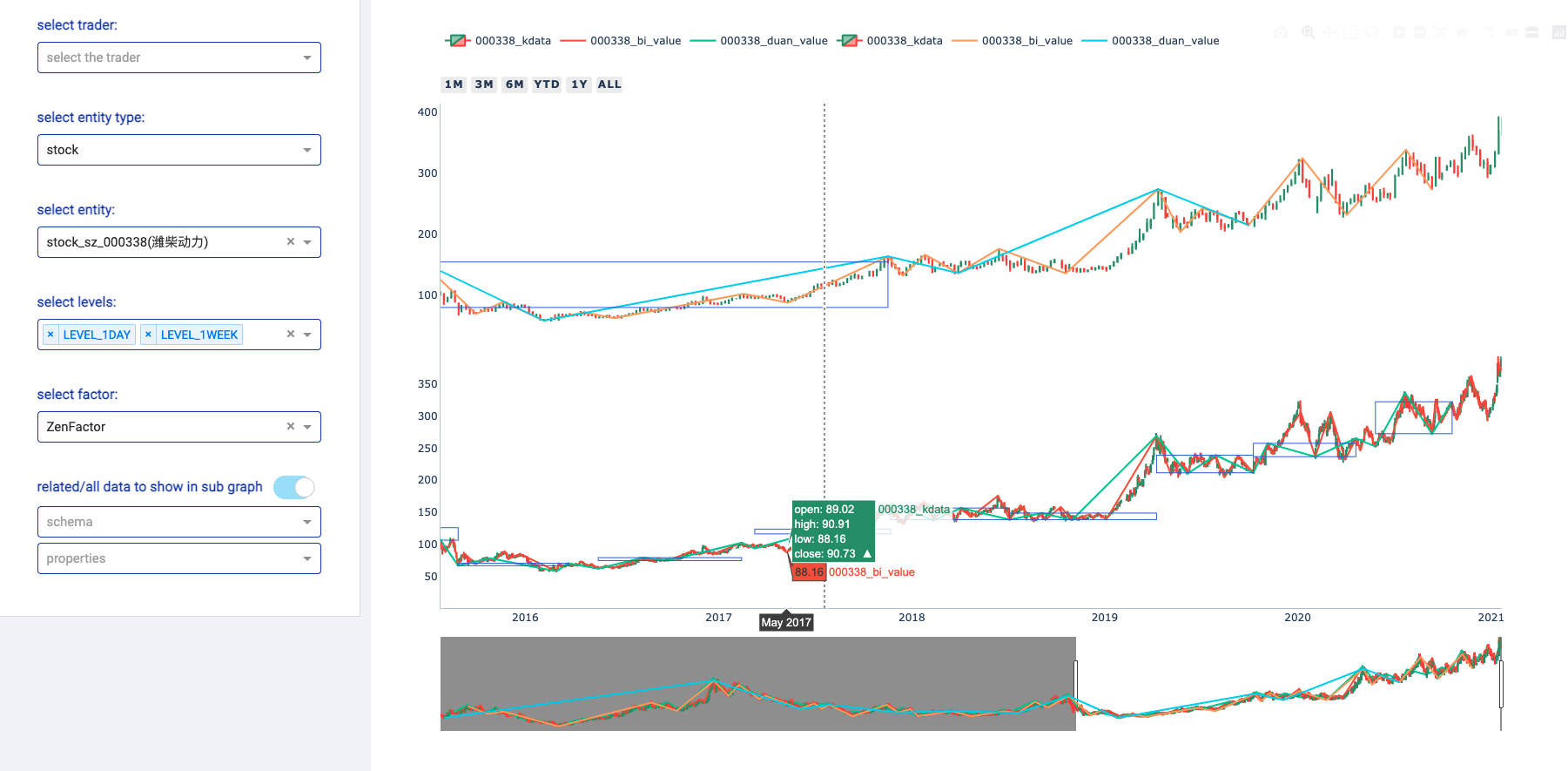
Zvt 既提供了可视化的历史数据浏览方式(web),又提供了A股历史数据的获取接口,是一个好用的股票数据下载工具。
它的使用方式非常简单,下面就教大家如何安装使用这个模块。
开始之前,你要确保Python和pip已经成功安装在电脑上,如果没有,请访问这篇文章:超详细Python安装指南 进行安装。
(可选1) 如果你用Python的目的是数据分析,可以直接安装Anaconda:Python数据分析与挖掘好帮手—Anaconda,它内置了Python和pip.
(可选2) 此外,推荐大家用VSCode编辑器来编写小型Python项目:Python 编程的最好搭档—VSCode 详细指南
Windows环境下打开Cmd(开始—运行—CMD),苹果系统环境下请打开Terminal(command+空格输入Terminal),输入命令安装依赖:
pip install -U zvt
注意,Python版本最好大于等于Python3.6.
如果你想要进入web界面,在安装完成模块后,重启终端,进入你的zvt所属Python环境,执行下面这行命令:
zvt
然后打开 http://127.0.0.1:8050/ 就能看到相关的图表:
想要通过Zvt获取A股股票的基本数据,你只需要这样:
from zvt.domain import *
Stock.record_data(provider="em")
df = Stock.query_data(provider="em", index='code')
print(df)
"""
id entity_id timestamp entity_type exchange code name list_date end_date
code
000001 stock_sz_000001 stock_sz_000001 1991-04-03 stock sz 000001 平安银行 1991-04-03 None
000002 stock_sz_000002 stock_sz_000002 1991-01-29 stock sz 000002 万 科A 1991-01-29 None
000004 stock_sz_000004 stock_sz_000004 1990-12-01 stock sz 000004 国华网安 1990-12-01 None
000005 stock_sz_000005 stock_sz_000005 1990-12-10 stock sz 000005 世纪星源 1990-12-10 None
000006 stock_sz_000006 stock_sz_000006 1992-04-27 stock sz 000006 深振业A 1992-04-27 None
... ... ... ... ... ... ... ... ... ...
605507 stock_sh_605507 stock_sh_605507 2021-08-02 stock sh 605507 国邦医药 2021-08-02 None
605577 stock_sh_605577 stock_sh_605577 2021-08-24 stock sh 605577 龙版传媒 2021-08-24 None
605580 stock_sh_605580 stock_sh_605580 2021-08-19 stock sh 605580 恒盛能源 2021-08-19 None
605588 stock_sh_605588 stock_sh_605588 2021-08-12 stock sh 605588 冠石科技 2021-08-12 None
605589 stock_sh_605589 stock_sh_605589 2021-08-10 stock sh 605589 圣泉集团 2021-08-10 None
[4136 rows x 9 columns]
"""注意, provider = “em” 指的是 东方财富(eastmoney).
历史数据获取:
from zvt.domain import *
Stock1dHfqKdata.record_data(code='000338', provider='em')
df = Stock1dHfqKdata.query_data(code='000338', provider='em')
print(df)
"""
id entity_id timestamp provider code name level open close high low volume turnover change_pct turnover_rate
0 stock_sz_000338_2007-04-30 stock_sz_000338 2007-04-30 None 000338 潍柴动力 1d 70.00 64.93 71.00 62.88 207375.0 1.365189e+09 2.1720 0.1182
1 stock_sz_000338_2007-05-08 stock_sz_000338 2007-05-08 None 000338 潍柴动力 1d 66.60 64.00 68.00 62.88 86299.0 5.563198e+08 -0.0143 0.0492
2 stock_sz_000338_2007-05-09 stock_sz_000338 2007-05-09 None 000338 潍柴动力 1d 63.32 62.00 63.88 59.60 93823.0 5.782065e+08 -0.0313 0.0535
3 stock_sz_000338_2007-05-10 stock_sz_000338 2007-05-10 None 000338 潍柴动力 1d 61.50 62.49 64.48 61.01 47720.0 2.999226e+08 0.0079 0.0272
4 stock_sz_000338_2007-05-11 stock_sz_000338 2007-05-11 None 000338 潍柴动力 1d 61.90 60.65 61.90 59.70 39273.0 2.373126e+08 -0.0294 0.0224
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
3426 stock_sz_000338_2021-08-27 stock_sz_000338 2021-08-27 None 000338 潍柴动力 1d 331.97 345.95 345.95 329.82 1688497.0 3.370241e+09 0.0540 0.0398
3427 stock_sz_000338_2021-08-30 stock_sz_000338 2021-08-30 None 000338 潍柴动力 1d 345.95 342.72 346.10 337.96 1187601.0 2.377957e+09 -0.0093 0.0280
3428 stock_sz_000338_2021-08-31 stock_sz_000338 2021-08-31 None 000338 潍柴动力 1d 344.41 342.41 351.02 336.73 1143985.0 2.295195e+09 -0.0009 0.0270
3429 stock_sz_000338_2021-09-01 stock_sz_000338 2021-09-01 None 000338 潍柴动力 1d 341.03 336.42 341.03 328.28 1218697.0 2.383841e+09 -0.0175 0.0287
3430 stock_sz_000338_2021-09-02 stock_sz_000338 2021-09-02 None 000338 潍柴动力 1d 336.88 339.03 340.88 329.67 1023545.0 2.012006e+09 0.0078 0.0241
[3431 rows x 15 columns]
"""财务数据获取:
from zvt.domain import *
FinanceFactor.record_data(code='000338')
FinanceFactor.query_data(code='000338',columns=FinanceFactor.important_cols(),index='timestamp')
"""
basic_eps total_op_income net_profit op_income_growth_yoy net_profit_growth_yoy roe rota gross_profit_margin net_margin timestamp
timestamp
2002-12-31 NaN 1.962000e+07 2.471000e+06 NaN NaN NaN NaN 0.2068 0.1259 2002-12-31
2003-12-31 1.27 3.574000e+09 2.739000e+08 181.2022 109.8778 0.7729 0.1783 0.2551 0.0766 2003-12-31
2004-12-31 1.75 6.188000e+09 5.369000e+08 0.7313 0.9598 0.3245 0.1474 0.2489 0.0868 2004-12-31
2005-12-31 0.93 5.283000e+09 3.065000e+08 -0.1463 -0.4291 0.1327 0.0603 0.2252 0.0583 2005-12-31
2006-03-31 0.33 1.859000e+09 1.079000e+08 NaN NaN NaN NaN NaN 0.0598 2006-03-31
... ... ... ... ... ... ... ... ... ... ...
2020-08-28 0.59 9.449000e+10 4.680000e+09 0.0400 -0.1148 0.0983 0.0229 0.1958 0.0603 2020-08-28
2020-10-31 0.90 1.474000e+11 7.106000e+09 0.1632 0.0067 0.1502 0.0347 0.1949 0.0590 2020-10-31
2021-03-31 1.16 1.975000e+11 9.207000e+09 0.1327 0.0112 0.1919 0.0444 0.1931 0.0571 2021-03-31
2021-04-30 0.42 6.547000e+10 3.344000e+09 0.6788 0.6197 0.0622 0.0158 0.1916 0.0667 2021-04-30
2021-08-31 0.80 1.264000e+11 6.432000e+09 0.3375 0.3742 0.1125 0.0287 0.1884 0.0653 2021-08-31
[66 rows x 10 columns]
"""资产负债表、利润表、现金流表:
from zvt.domain import * BalanceSheet.record_data(code='000338') IncomeStatement.record_data(code='000338') CashFlowStatement.record_data(code='000338')
更多数据请看
from zvt.domain import * print(zvt_context.schemas) """ [zvt.domain.dividend_financing.DividendFinancing, zvt.domain.dividend_financing.DividendDetail, zvt.domain.dividend_financing.SpoDetail...] """
基于query_data的filters参数,你还能实现筛选,比如2018年年报中roe>8%、营收增速>8%的前20只股票:
from zvt.domain import *
df = FinanceFactor.query_data(filters=[FinanceFactor.roe>0.08,FinanceFactor.report_period=='year',FinanceFactor.op_income_growth_yoy>0.08],start_timestamp='2019-01-01',order=FinanceFactor.roe.desc(),limit=20,columns=["code"]+FinanceFactor.important_cols(),index='code')
print(df)
"""
code basic_eps total_op_income net_profit op_income_growth_yoy net_profit_growth_yoy roe rota gross_profit_margin net_margin timestamp
code
000048 000048 2.7350 4.919000e+09 1.101000e+09 0.4311 1.5168 0.7035 0.1988 0.5243 0.2355 2020-04-30
000912 000912 0.3500 4.405000e+09 3.516000e+08 0.1796 1.2363 4.7847 0.0539 0.2175 0.0795 2019-03-20
002207 002207 0.2200 3.021000e+08 5.189000e+07 0.1600 1.1526 1.1175 0.1182 0.1565 0.1718 2020-04-27
002234 002234 5.3300 3.276000e+09 1.610000e+09 0.8023 3.2295 0.8361 0.5469 0.5968 0.4913 2020-04-21
002458 002458 3.7900 3.584000e+09 2.176000e+09 1.4326 4.9973 0.8318 0.6754 0.6537 0.6080 2020-02-20
... ... ... ... ... ... ... ... ... ... ... ...
600701 600701 -3.6858 7.830000e+08 -3.814000e+09 1.3579 -0.0325 1.9498 -0.7012 0.4173 -4.9293 2020-04-29
600747 600747 -1.5600 3.467000e+08 -2.290000e+09 2.1489 -0.4633 3.1922 -1.5886 0.0378 -6.6093 2020-06-30
600793 600793 1.6568 1.293000e+09 1.745000e+08 0.1164 0.8868 0.7490 0.0486 0.1622 0.1350 2019-04-30
600870 600870 0.0087 3.096000e+07 4.554000e+06 0.7773 1.3702 0.7458 0.0724 0.2688 0.1675 2019-03-30
688169 688169 15.6600 4.205000e+09 7.829000e+08 0.3781 1.5452 0.7172 0.4832 0.3612 0.1862 2020-04-28
[20 rows x 11 columns]
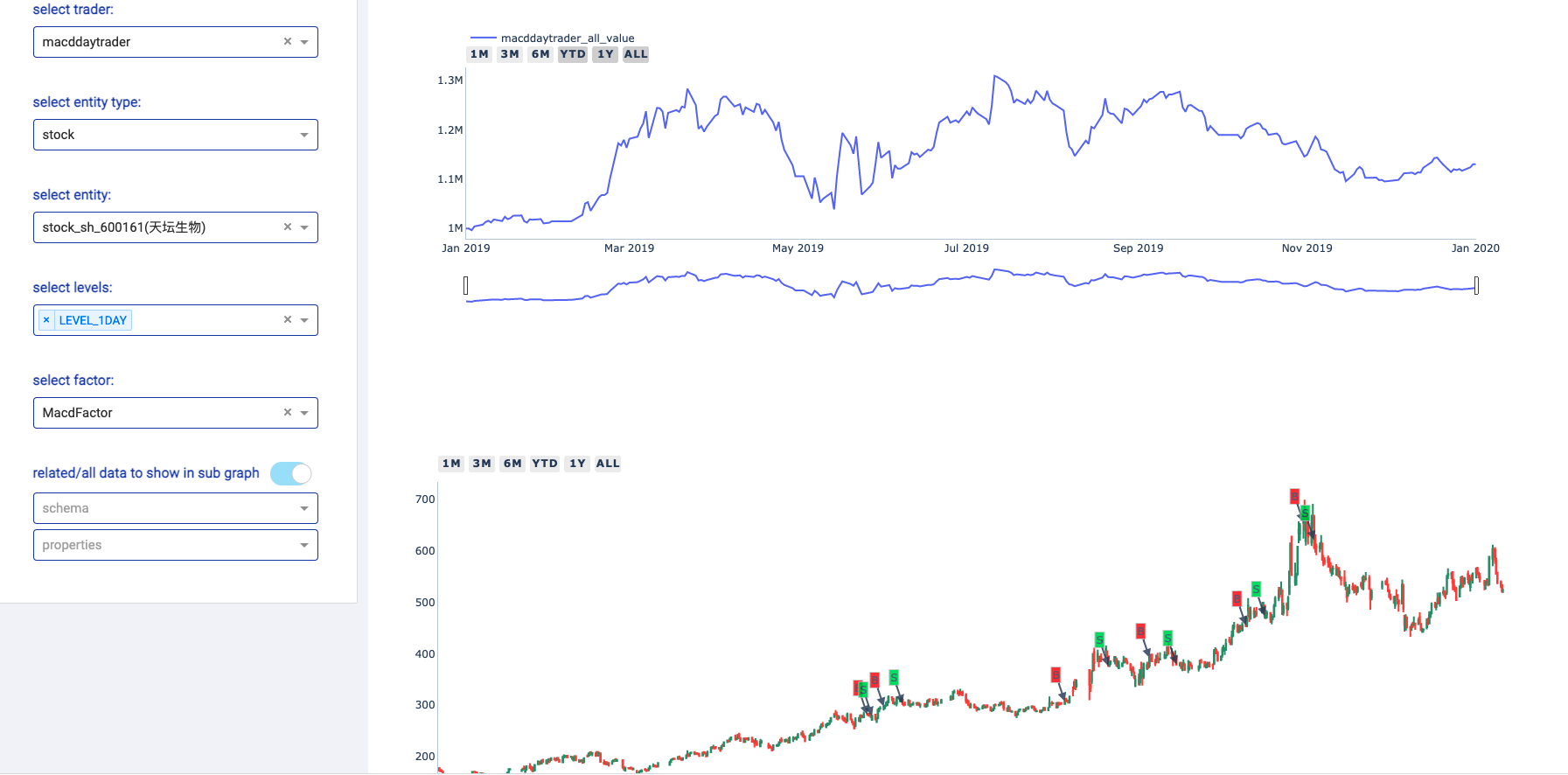
"""Zvt还能编写策略,然后能在页面上查看你策略产生的买入信号和卖出信号:
# -*- coding: utf-8 -*-
import pandas as pd
from zvt.api import get_recent_report_date
from zvt.contract import ActorType, AdjustType
from zvt.domain import StockActorSummary, Stock1dKdata
from zvt.trader import StockTrader
from zvt.utils import pd_is_not_null, is_same_date, to_pd_timestamp
class FollowIITrader(StockTrader):
finish_date = None
def on_time(self, timestamp: pd.Timestamp):
recent_report_date = to_pd_timestamp(get_recent_report_date(timestamp))
if self.finish_date and is_same_date(recent_report_date, self.finish_date):
return
filters = [StockActorSummary.actor_type == ActorType.raised_fund.value,
StockActorSummary.report_date == recent_report_date]
if self.entity_ids:
filters = filters + [StockActorSummary.entity_id.in_(self.entity_ids)]
df = StockActorSummary.query_data(filters=filters)
if pd_is_not_null(df):
self.logger.info(f'{df}')
self.finish_date = recent_report_date
long_df = df[df['change_ratio'] > 0.05]
short_df = df[df['change_ratio'] < -0.5]
try:
self.trade_the_targets(due_timestamp=timestamp, happen_timestamp=timestamp,
long_selected=set(long_df['entity_id'].to_list()),
short_selected=set(short_df['entity_id'].to_list()))
except Exception as e:
self.logger.error(e)
if __name__ == '__main__':
entity_id = 'stock_sh_600519'
Stock1dKdata.record_data(entity_id=entity_id, provider='em')
StockActorSummary.record_data(entity_id=entity_id, provider='em')
FollowIITrader(start_timestamp='2002-01-01', end_timestamp='2021-01-01', entity_ids=[entity_id],
provider='em', adjust_type=AdjustType.qfq, profit_threshold=None).run()它将能输出如下所示的信号图:
更多的功能请见 Zvt 官方文档:zvt.readthedocs.io/en/latest/
我们的文章到此就结束啦,如果你喜欢今天的 Python 教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 ( pythondict.com )
不只是一个宝典
欢迎关注公众号:Python实用宝典
上一篇文章:《Eiten 一个构建美股投资组合的好帮手》中,我们讲解了Eiten这一个开源工具包,以及如何使用它来构建美股的投资组合。
所谓的投资组合优化,就是决定你的股票池的权重分配比例,这一步是在选股完毕之后进行的。关于选股,你可以阅读我们之前的文章:量化投资单因子回测神器 — Alphalens。
本篇文章我们将介绍如何使用Eiten做A股的投资组合优化,文中的股票都是随机选取的,请勿参考。
开始之前,你要确保Python和pip已经成功安装在电脑上,如果没有,请访问这篇文章:超详细Python安装指南 进行安装。
(可选1) 如果你用Python的目的是数据分析,可以直接安装Anaconda:Python数据分析与挖掘好帮手—Anaconda,它内置了Python和pip.
(可选2) 此外,推荐大家用VSCode编辑器来编写小型Python项目:Python 编程的最好搭档—VSCode 详细指南
Windows环境下打开Cmd(开始—运行—CMD),苹果系统环境下请打开Terminal(command+空格输入Terminal),输入命令安装依赖:
git clone https://github.com/tradytics/eiten.git cd eiten pip install -r requirements.txt pip install yfinance --upgrade --no-cache-dir
如你无法下载github上的内容,请到 https://pythondict.com/下载/eiten-源代码/ 上下载。
目录结构如下:
| 路径 | 描述 |
|---|---|
| eiten | 主目录 |
| └ figures | 仓库用到的图表(无需关注) |
| └ stocks | 你的用于创建投资组合的股票列表 |
| └ strategies | python编写的策略代码 |
| backtester.py | 回测模块 |
| data_loader.py | 数据加载工具 |
| portfolio_manager.py | 生成投资组合的代码 |
| simulator.py | 使用历史回报生成投资组合的模拟器 |
| strategy_manager.py | 策略管理器 |
把你想要构建投资组合的候选股票列表写入 stocks/stocks.txt 中。A股的股票代码形式如下:
上海市场,股票代码后缀加 .SS, 如: 600519.SS 及 688111.SS
深圳市场,股票代码后缀加 .SZ 如: 000858.SZ 及 300498.SZ
比如我在 stocks/stocks.txt 中放入以下10只股票进行投资组合优化:
600519.SS 601318.SS 600036.SS 000858.SZ 601012.SS 000333.SZ 600276.SS 002415.SZ 601166.SS 601888.SS
在终端输入以下命令运行,试试效果:
python portfolio_manager.py --is_test 1 --future_bars 20 --data_granularity_minutes 3600 --history_to_use 250 --apply_noise_filtering 1 --only_long 1 --eigen_portfolio_number 3 --stocks_file_path stocks/stocks.txt
参数说明:
is_test: 该值决定了程序是否要保留一些数据用于未来的测试。当这个值为True时,future_bars的值应该大于5。
future_bars: 构建投资组合时将排除的最近n条K线。这也被称为样本外的数据。
data_granularity_minutes: 你想什么频率的数据来建立你的投资组合。对于长期投资组合,你应该使用每日数据,但对于短期策略,你可以使用分钟的数据(60、30、15、5、1)。3600代表每天。
history_to_use: 是使用特定数量的数据还是使用我们从雅虎财经下载的所有数据。对于分钟级别的数据,我们只下载了一个月的历史数据。对于日线,我们下载了5年的历史数据。如果你想使用所有可用的数据,该值应该是 all,但如果你想使用较小的数据量,你可以将其设置为一个整数,例如100,这将只使用最后100条k线来建立投资组合。在本文例子中,我们只用250条K线,因为雅虎财经上沪深300指数只保存了1年半。
apply_noise_filtering: 它使用随机矩阵理论来过滤掉随机性的协方差矩阵,从而产生更好的投资组合。值为1将启用它。
market_index: 你想用哪个指数来作为你的投资组合的基准值, 这里我使用了沪深300指数(000300.SS)。
only_long: 是否只做多。
eigen_portfolio_number: 针对Eigen策略,数字越小,风险和回报都会降低。可阅读这篇文章了解更多: eigen-portfolios.
stocks_file_path: 你想用来建立投资组合的股票列表。
首先你会在终端中看到输出的所有策略给每只股票分配的权重:
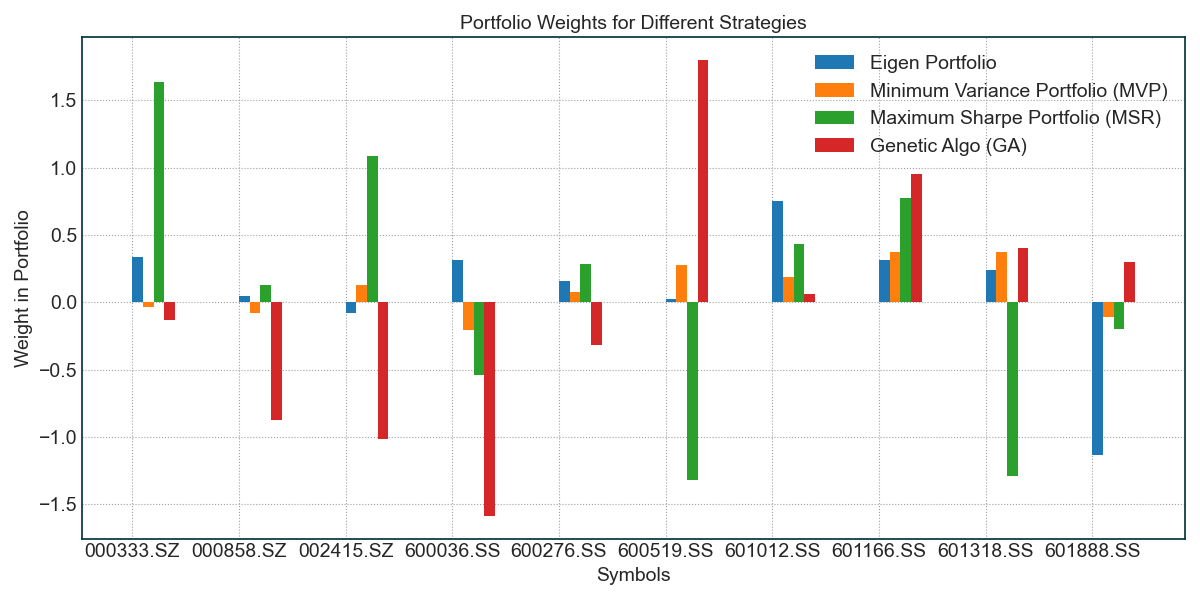
*% Printing portfolio weights... -------- Weights for Eigen Portfolio -------- Symbol: 000333.SZ, Weight: 0.3399 Symbol: 000858.SZ, Weight: 0.0496 Symbol: 002415.SZ, Weight: -0.0787 Symbol: 600036.SS, Weight: 0.3179 Symbol: 600276.SS, Weight: 0.1612 Symbol: 600519.SS, Weight: 0.0292 Symbol: 601012.SS, Weight: 0.7539 Symbol: 601166.SS, Weight: 0.3149 Symbol: 601318.SS, Weight: 0.2433 Symbol: 601888.SS, Weight: -1.1312 -------- Weights for Minimum Variance Portfolio (MVP) -------- Symbol: 000333.SZ, Weight: -0.0335 Symbol: 000858.SZ, Weight: -0.0812 Symbol: 002415.SZ, Weight: 0.1281 Symbol: 600036.SS, Weight: -0.2021 Symbol: 600276.SS, Weight: 0.0767 Symbol: 600519.SS, Weight: 0.2759 Symbol: 601012.SS, Weight: 0.1913 Symbol: 601166.SS, Weight: 0.3773 Symbol: 601318.SS, Weight: 0.3735 Symbol: 601888.SS, Weight: -0.1058 -------- Weights for Maximum Sharpe Portfolio (MSR) -------- Symbol: 000333.SZ, Weight: 1.6382 Symbol: 000858.SZ, Weight: 0.1264 Symbol: 002415.SZ, Weight: 1.0846 Symbol: 600036.SS, Weight: -0.5394 Symbol: 600276.SS, Weight: 0.2878 Symbol: 600519.SS, Weight: -1.3160 Symbol: 601012.SS, Weight: 0.4310 Symbol: 601166.SS, Weight: 0.7743 Symbol: 601318.SS, Weight: -1.2865 Symbol: 601888.SS, Weight: -0.2004 -------- Weights for Genetic Algo (GA) -------- Symbol: 000333.SZ, Weight: -0.1276 Symbol: 000858.SZ, Weight: -0.8724 Symbol: 002415.SZ, Weight: -1.0129 Symbol: 600036.SS, Weight: -1.5845 Symbol: 600276.SS, Weight: -0.3169 Symbol: 600519.SS, Weight: 1.7996 Symbol: 601012.SS, Weight: 0.0641 Symbol: 601166.SS, Weight: 0.9515 Symbol: 601318.SS, Weight: 0.4069 Symbol: 601888.SS, Weight: 0.2969
第二张图,你能看到每个策略的回测效果,可以看到,这10只股票的组合,使用GA策略的效果会比沪深300好一点:
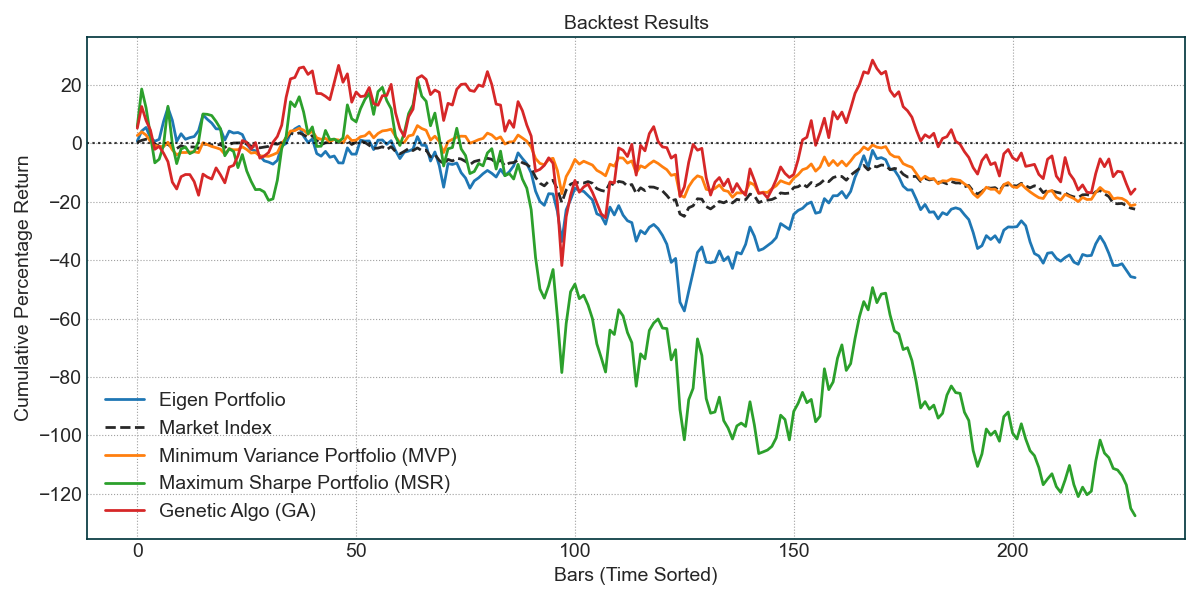
@公众号: 二七阿尔量化
第三张图,我们设定了最后20个交易日用于测试,这是测试结果,由于近期市场处于下跌趋势,这10只股票也产生了剧烈波动,效果一般。

第四张图是对未来的一个预估,没有太大参考性。

可以看到输出的报告中包含了4种策略:
Eigen Portfolios 特征投资组合 (蓝色)
这些投资组合通常与市场相关性较低,会产生相对的高回报和阿尔法。然而,由于它们与市场相关性不高,它们也可能带来很大的风险。数字越小,风险和回报都会降低。
Minimum Variance Portfolio (MVP) 最小方差投资组合 (橙色)
MVP 试图最小化投资组合的收益方差。这些投资组合的风险和回报最低。
Maximum Sharpe Ratio Portfolio (MSR) 最大夏普比率投资组合 (绿色)
MSR 试图最大化投资组合的夏普比率。它在优化过程中使用过去的回报,这意味着如果过去的回报与未来的回报不同,那么未来的结果可能会有所不同。
Genetic Algorithm (GA) based Portfolio 基于遗传算法 (GA) 的投资组合 (红色)
这是 Eiten 模块内实现的基于 GA 的投资组合。通常能提供比其他策略更强大的投资组合。
我们的文章到此就结束啦,如果你喜欢今天的 Python 教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 ( pythondict.com )
不只是一个宝典
欢迎关注公众号:Python实用宝典


























