
在日常 PC 端的爬虫过程工作中,Chrome 浏览器是我们常用的一款工具。
鉴于 Chrome 浏览器的强大,Chrome 网上应用商店很多强大的插件可以帮助我们快速高效地进行数据爬虫。
今天推荐的 6 款 Chrome 插件,可以大大提升我们的爬虫效率。
EditThisCookie

EditThisCookie 是一个 Cookie 管理器,可以很方便的添加,删除,编辑,搜索,锁定和屏蔽 Cookies。
可以将登录后的 Cookies 先保存到本地,借助 cookielib 库,直接爬取登录后的数据。
避免了抓包和模拟登录,帮助我们快速地进行爬虫。
Web Scraper
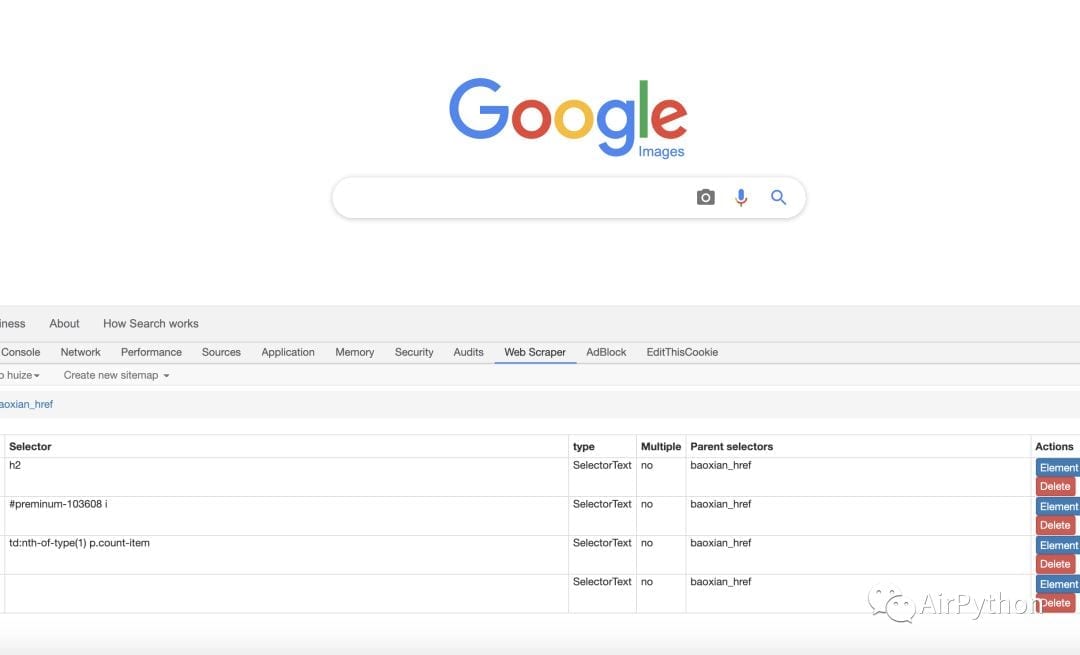
Web Scraper 是一款免费的、适用于任何人,包含没有任何编程基础的爬虫工具。
操作简单,只需要鼠标点击和简单的配置,就能快速的爬取 Web 端的数据。
它支持复杂的网站结构,数据支持文本、连接、数据块、下拉加载数据块等各种数据类型。
此外,还能将爬取的数据导出到 CSV 文件中。
Xpath Helper

Xpath Helper 是一种结构化网页元素选择器,支持列表和单节点数据获取,
它可以快速地定位网页元素。
对比 Beautiful Soup,由于 Xpath 网页元素查找性能更有优势;Xpath 相比正则表达式编写起来更方便。
编写 Xpath 之后会实时显示匹配的数目和对应的位置,方便我们判断语句是否编写正确。
Toggle JavaScript

Toggle JavaScript 插件可以用来检测当前网页哪些元素是通过 AJAX 动态加载的。
使用它可以快速在容许加载 JS 、禁止加载 JS 两种模式中切换。
User-Agent Switcher for Chrome

User-Agent Switcher for Chrome 插件可以很方便的修改浏览器的 User-Agent。
可以模拟不同的浏览器、客户端,包含 Android、IOS 去模拟请求。
对于一些特殊网站,切换 User-Agent 可以更方便地进行数据爬取。
JSON-handle
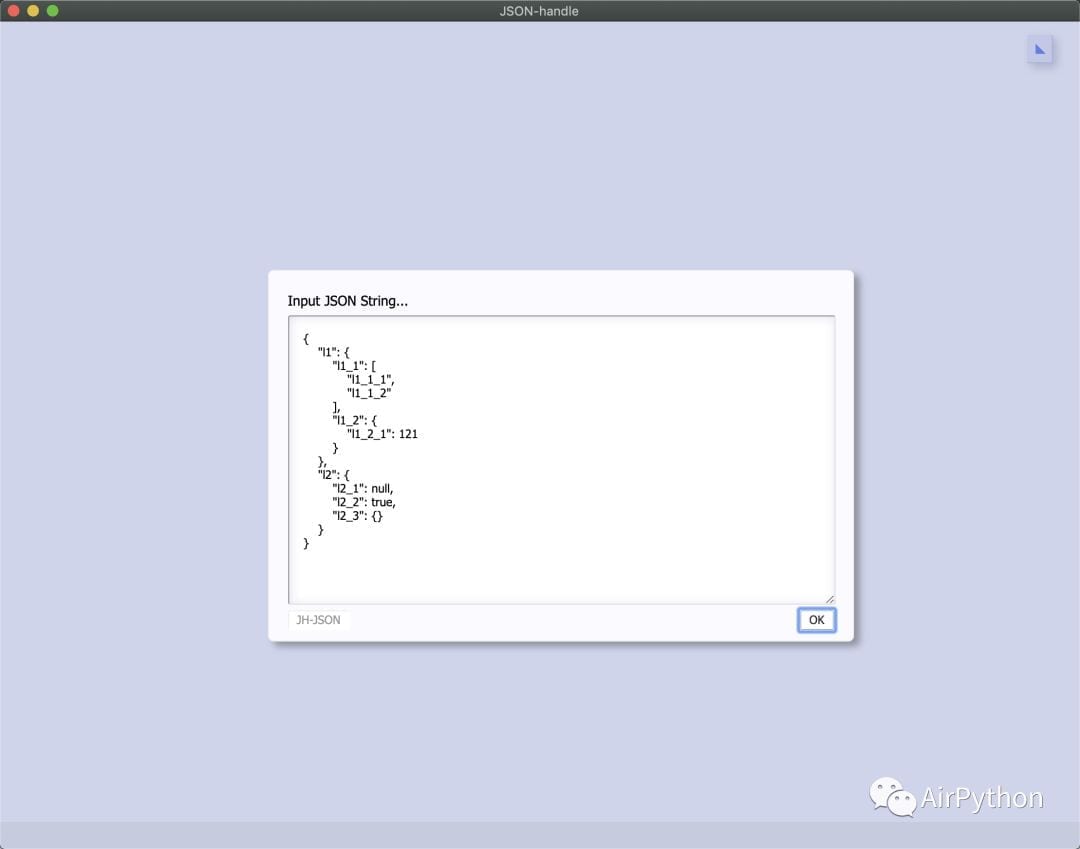
JSON-handle 是一款功能强大的JSON数据解析Chrome插件。它以简单清晰的树形图样式展现 JSON 文档,并可实时编辑。针对数据量大的场景,可以做局部选取分析。
我们的文章到此就结束啦,如果你希望我们今天的Python 教程,请持续关注我们。有任何问题请在下方留言,我们会耐心解答的!
Python实用宝典 (pythondict.com)
不只是一个宝典
欢迎关注公众号:Python实用宝典

评论(0)