


AutoGrad 是一个老少皆宜的 Python 梯度计算模块。
对于初高中生而言,它可以用来轻易计算一条曲线在任意一个点上的斜率。
对于大学生、机器学习爱好者而言,你只需要传递给它Numpy这样的标准数据库下编写的损失函数,它就可以自动计算损失函数的导数(梯度)。
我们将从普通斜率计算开始,介绍到如何只使用它来实现一个逻辑回归模型。
1.准备
开始之前,你要确保Python和pip已经成功安装在电脑上,如果没有,请访问这篇文章:超详细Python安装指南 进行安装。
(可选1) 如果你用Python的目的是数据分析,可以直接安装Anaconda:Python数据分析与挖掘好帮手—Anaconda,它内置了Python和pip.
(可选2) 此外,推荐大家用VSCode编辑器来编写小型Python项目:Python 编程的最好搭档—VSCode 详细指南
Windows环境下打开Cmd(开始—运行—CMD),苹果系统环境下请打开Terminal(command+空格输入Terminal),输入命令安装依赖:
pip install autograd
2.AutoGrad 计算斜率
对于初高中生同学而言,它可以用来轻松计算斜率,比如我编写一个斜率为0.5的直线函数:
# 公众号 Python实用宝典
import autograd.numpy as np
from autograd import grad
def oneline(x):
y = x/2
return y
grad_oneline = grad(oneline)
print(grad_oneline(3.0))
运行代码,传入任意X值,你就能得到在该X值下的斜率:
(base) G:\push\20220724>python 1.py 0.5
由于这是一条直线,因此无论你传什么值,都只会得到0.5的结果。
那么让我们再试试一个tanh函数:
# 公众号 Python实用宝典
import autograd.numpy as np
from autograd import grad
def tanh(x):
y = np.exp(-2.0 * x)
return (1.0 - y) / (1.0 + y)
grad_tanh = grad(tanh)
print(grad_tanh(1.0))此时你会获得 1.0 这个 x 在tanh上的曲线的斜率:
(base) G:\push\20220724>python 1.py 0.419974341614026
我们还可以绘制出tanh的斜率的变化的曲线:
# 公众号 Python实用宝典
import autograd.numpy as np
from autograd import grad
def tanh(x):
y = np.exp(-2.0 * x)
return (1.0 - y) / (1.0 + y)
grad_tanh = grad(tanh)
print(grad_tanh(1.0))
import matplotlib.pyplot as plt
from autograd import elementwise_grad as egrad
x = np.linspace(-7, 7, 200)
plt.plot(x, tanh(x), x, egrad(tanh)(x))
plt.show()
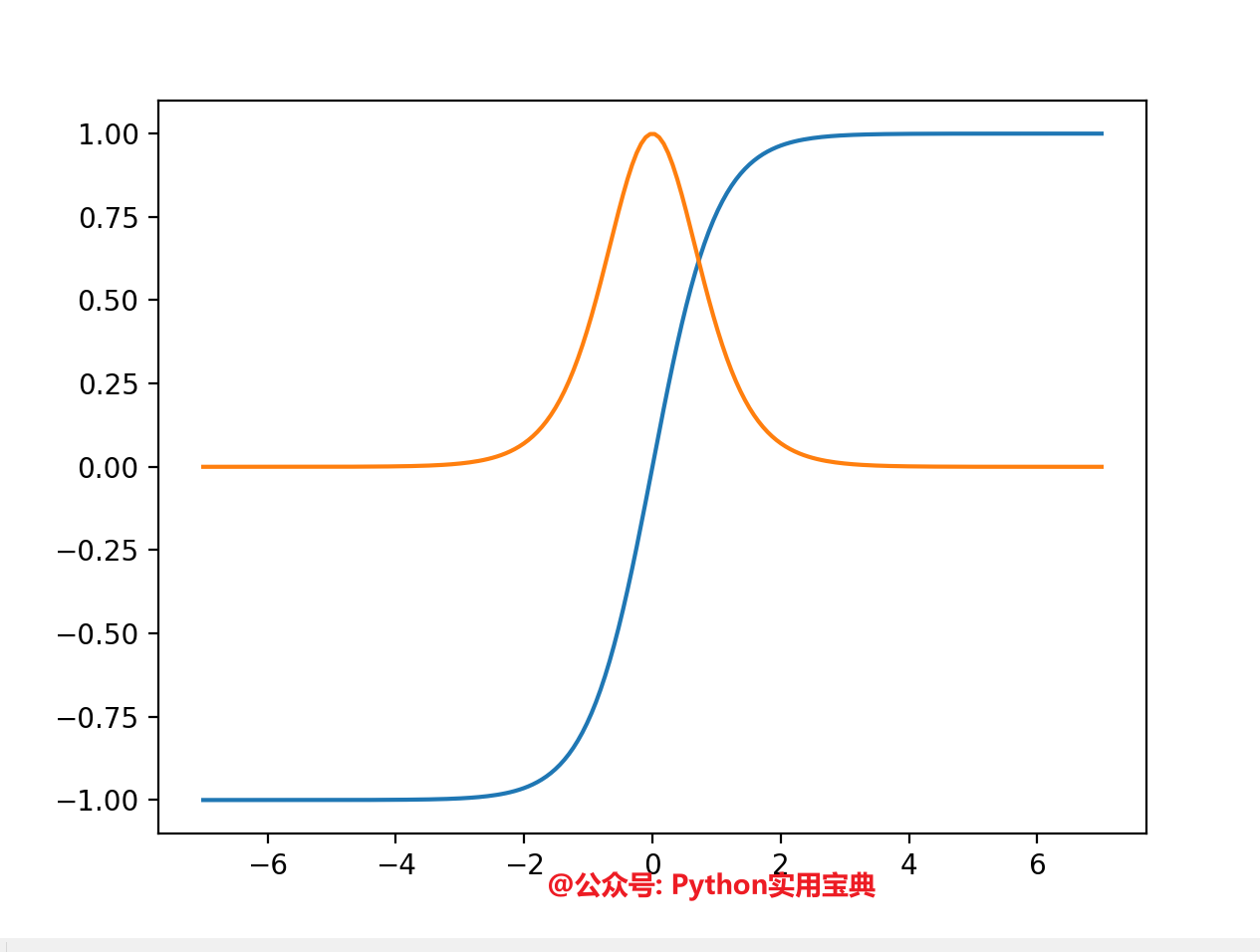
图中蓝色的线是tanh,橙色的线是tanh的斜率,你可以非常清晰明了地看到tanh的斜率的变化。非常便于学习和理解斜率概念。
3.实现一个逻辑回归模型
有了Autograd,我们甚至不需要借用scikit-learn就能实现一个回归模型:
逻辑回归的底层分类就是基于一个sigmoid函数:
import autograd.numpy as np
from autograd import grad
# Build a toy dataset.
inputs = np.array([[0.52, 1.12, 0.77],
[0.88, -1.08, 0.15],
[0.52, 0.06, -1.30],
[0.74, -2.49, 1.39]])
targets = np.array([True, True, False, True])
def sigmoid(x):
return 0.5 * (np.tanh(x / 2.) + 1)
def logistic_predictions(weights, inputs):
# Outputs probability of a label being true according to logistic model.
return sigmoid(np.dot(inputs, weights))从下面的损失函数可以看到,预测结果的好坏取决于weights的好坏,因此我们的问题转化为怎么优化这个 weights 变量:
def training_loss(weights):
# Training loss is the negative log-likelihood of the training labels.
preds = logistic_predictions(weights, inputs)
label_probabilities = preds * targets + (1 - preds) * (1 - targets)
return -np.sum(np.log(label_probabilities))知道了优化目标后,又有Autograd这个工具,我们的问题便迎刃而解了,我们只需要让weights往损失函数不断下降的方向移动即可:
# Define a function that returns gradients of training loss using Autograd.
training_gradient_fun = grad(training_loss)
# Optimize weights using gradient descent.
weights = np.array([0.0, 0.0, 0.0])
print("Initial loss:", training_loss(weights))
for i in range(100):
weights -= training_gradient_fun(weights) * 0.01
print("Trained loss:", training_loss(weights))运行结果如下:
(base) G:\push\20220724>python regress.py Initial loss: 2.772588722239781 Trained loss: 1.067270675787016
由此可见损失函数以及下降方式的重要性,损失函数不正确,你可能无法优化模型。损失下降幅度太单一或者太快,你可能会错过损失的最低点。
总而言之,AutoGrad是一个你用来优化模型的一个好工具,它可以给你提供更加直观的损失走势,进而让你有更多优化想象力。有兴趣的朋友还可以看官方的更多示例代码:
我们的文章到此就结束啦,如果你喜欢今天的 Python 教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 ( pythondict.com )
不只是一个宝典
欢迎关注公众号:Python实用宝典

