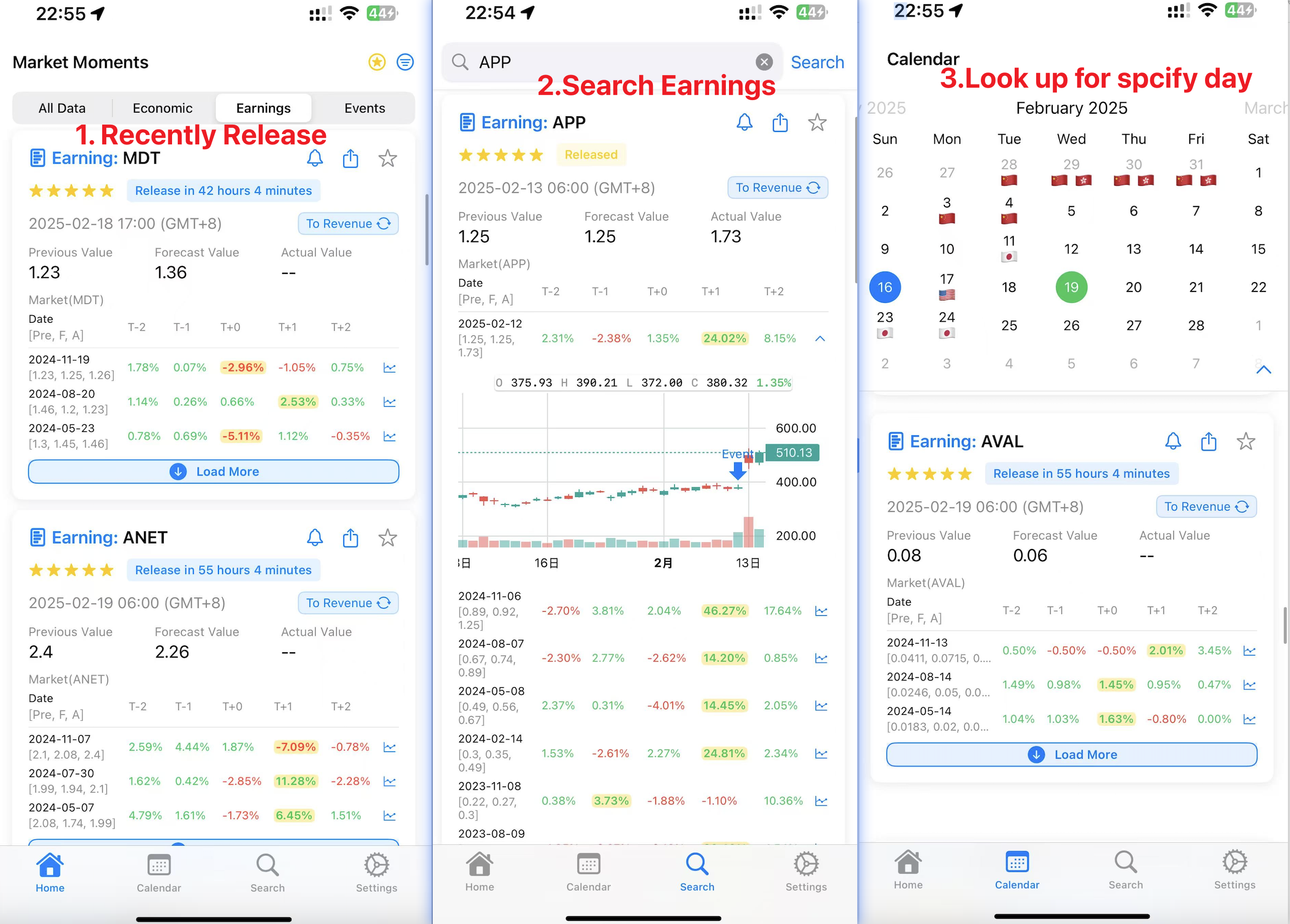
下面是 Market Moments APP 显示的下周重要经济事件和财报,供你参考:





下面是 Market Moments APP 显示的下周重要经济事件和财报,供你参考:
我为了更好地发现每次事件或股票财报发布时的波动率,开发了这款 APP: Market moments
使用它你能够:
通过 Market Moments,你可以:
这款 APP 的设计初衷是帮助投资者更好地把握市场波动机会,降低期权交易风险。

After earnings releases, stock price volatility can be extreme – 5% movements are normal, 10% swings are common, and some even exceed 20%.
This leads many to try ‘betting on earnings.’ However, this approach requires correctly predicting market direction after earnings, which is notoriously difficult to systematize.
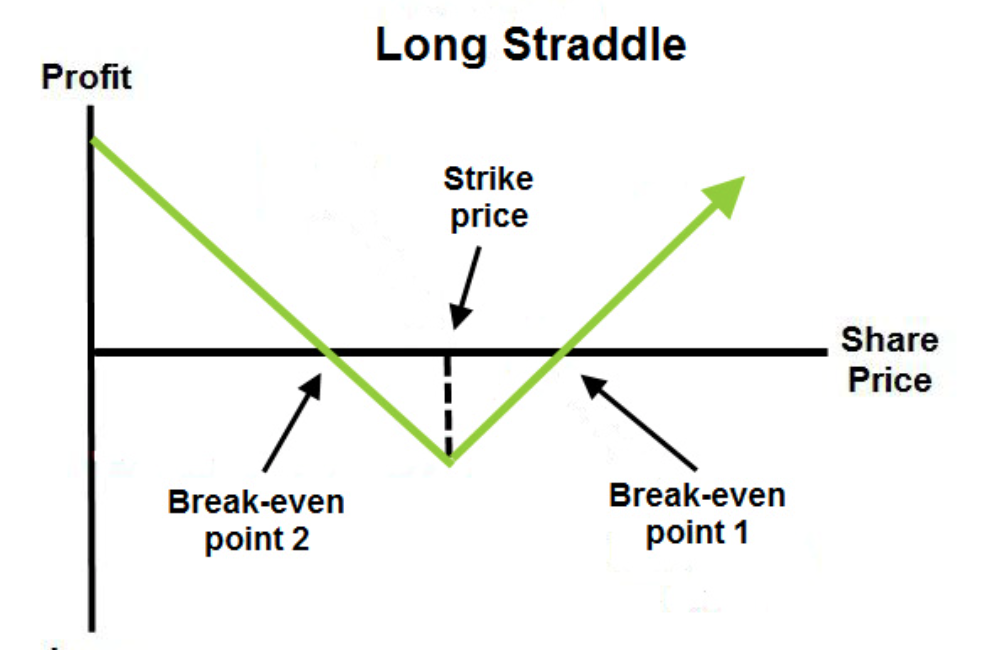
Today, I’ll introduce a strategy that doesn’t require directional prediction but instead profits from volatility – the Straddle strategy.
The principle of a Straddle is simple: simultaneously buying both call and put options with the same strike price and expiration date.
However, timing the purchase and selecting the right expiration date for the Straddle requires careful consideration.
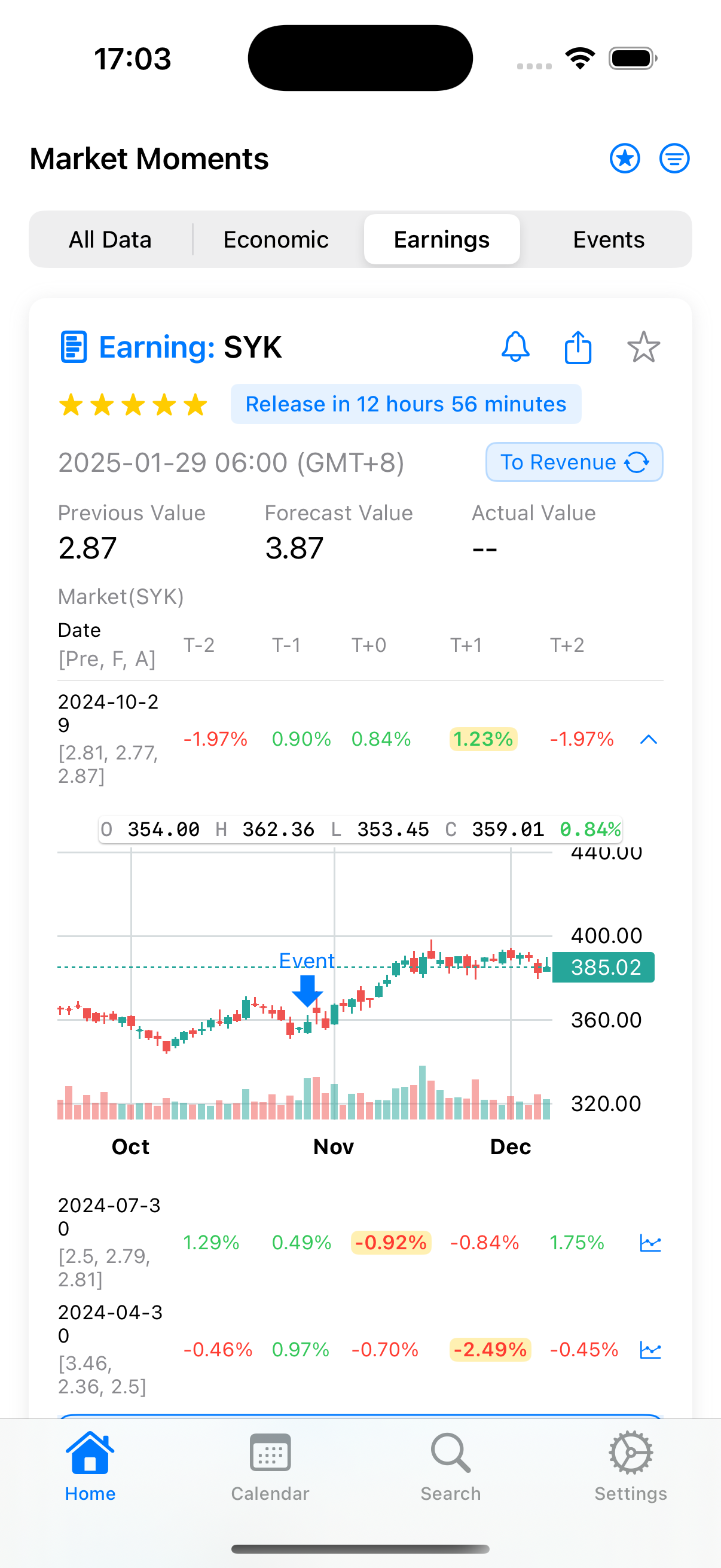
Let’s take a simple example from NFLX’s earnings on January 21st. According to the APP: Market Moments data, NFLX’s historical average post-earnings movement is around 8%:
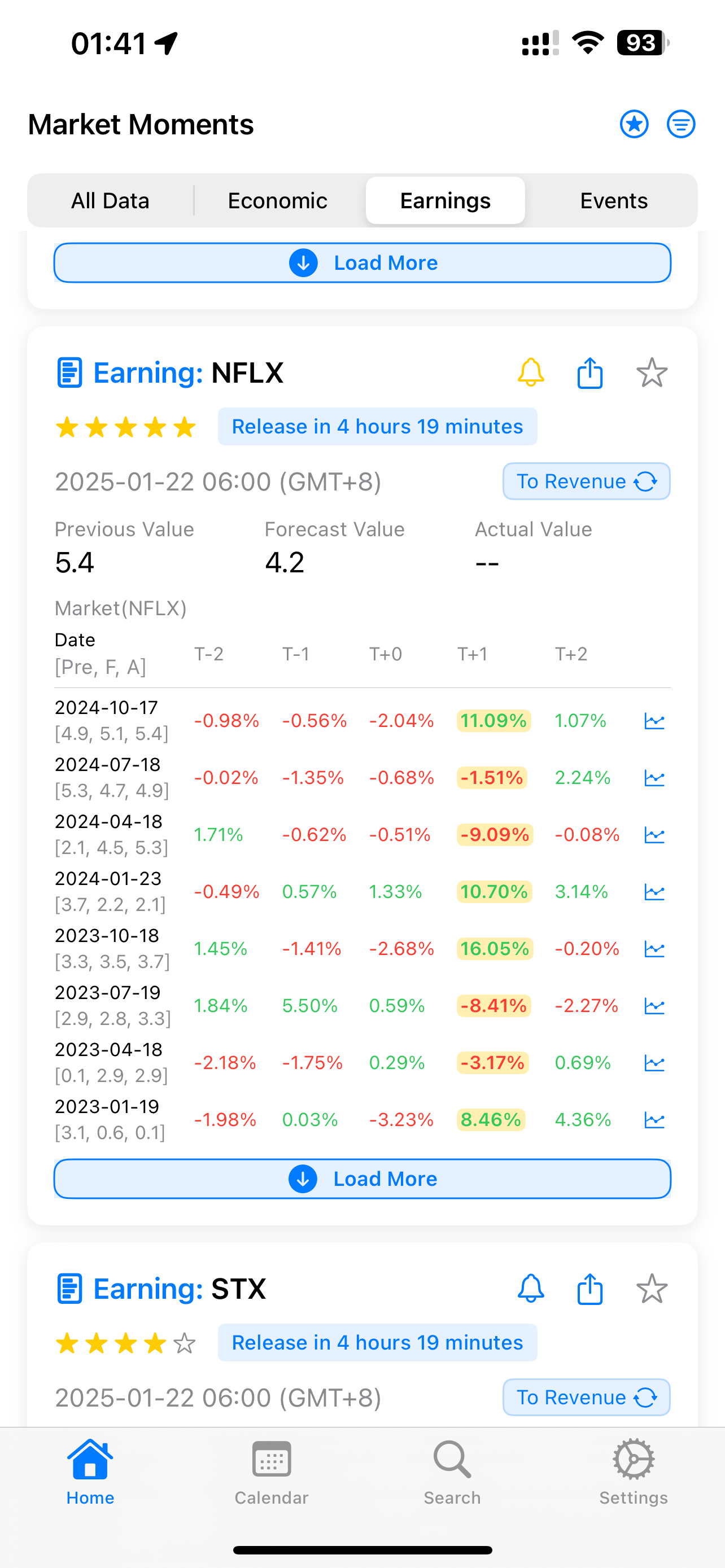
At that time, purchasing one Straddle required a minimum movement of 7.x% to be profitable. Based on historical data, this had a high probability of success. My purchase cost was approximately $6,478.
Eventually, NFLX exceeded earnings expectations and opened up over 12%. If you sold within the first hour of trading, you could profit over $3,000, representing about a 47% return.
However, if NFLX hadn’t exceeded expectations and opened with less than a 7% move, you would have suffered losses due to the sharp decline in implied volatility. With only a 5% move at open, you would have lost around $1,200.
Therefore, analyzing historical volatility is crucial. However, buying Straddles with longer expiration dates provides more margin for error. Take Tesla’s recent earnings as an example:
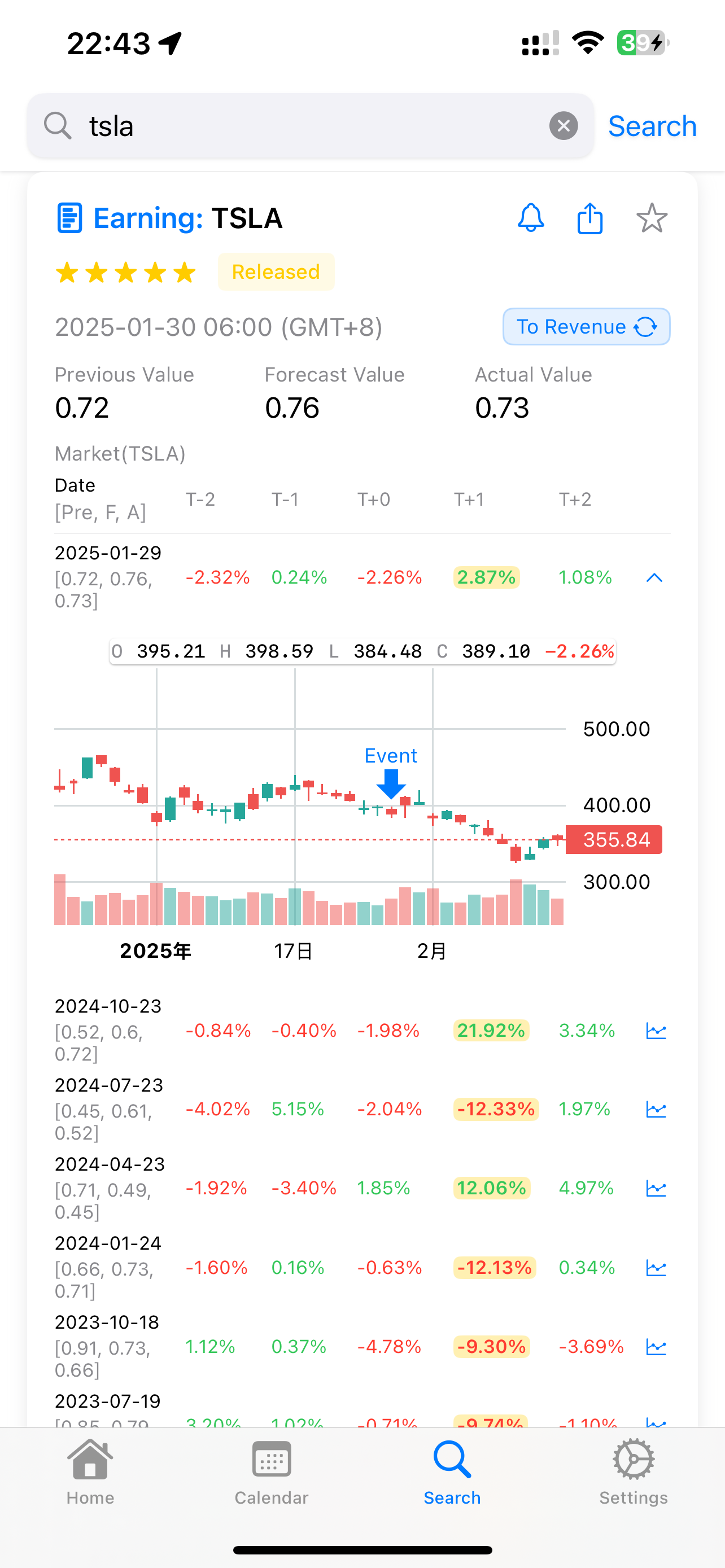
According to APP: Market Moments search results, Tesla’s most recent earnings volatility was unusually low at just 2.x%. If you had bought a same-week expiring Straddle, with a cost basis of 10.x%, you would have suffered significant losses due to implied volatility collapse.
However, if you had chosen a late February expiring Straddle, given Tesla’s subsequent market performance dropping to $325, assuming your Straddle strike price was $389, the decline of 325/389-1 = 16.45% would have still resulted in a profit.
Two key factors for buying Straddles are:
You can scan the QR code below to download:

你可扫描下方二维码下载:
2025 新年快乐!在这个充满希望的新年里,愿大家都能心想事成,学业进步,健康快乐!
随着新年的到来,Market Moments 也迎来重磅更新!

随着2025年1月20日(美国东部时间周一晚上10:30)特朗普正式宣誓就职,全球投资者的目光都聚焦在这位即将重返白宫的总统身上。
在这个关键时刻,回顾历史数据或许能为我们提供一些有价值的投资启示。
让我们先看看2017年特朗普首次就职后的美国市场表现:
在特朗普上一任期的首个240个交易日,纳斯达克100指数(QQQ)交出了一份亮眼的成绩单,累计上涨30%:

与此同时,亚洲市场在同期也呈现出显著增长:
– 港股(恒生指数)表现尤为抢眼,240个交易日内大涨35.98%

– A股(上证指数)也录得9.2%的可观涨幅:

有意思的是,在奥巴马最后一任期和拜登在任期的首年表现中,恒生指数和上证指数均录得负收益。

然而,最令人瞩目的莫过于加密货币市场,比特币在这240个交易日内实现了惊人的300%涨幅,这其实侧面反应了特朗普对加密货币乃至整个 Web3 的态度是支持的。
另一个引人深思的数据是:自2005年以来,每位新任美国总统上任后的首年240个交易日,QQQ的涨幅都保持在10%以上。这一历史规律是否会在2025年再次应验?让我们拭目以待吧。
想了解更多历史市场数据和深度分析,欢迎下载Market Moments APP,让数据助力您的投资决策。APP 完全免费,另外,财报季即将到来,后续还会推出财报专项,敬请期待。
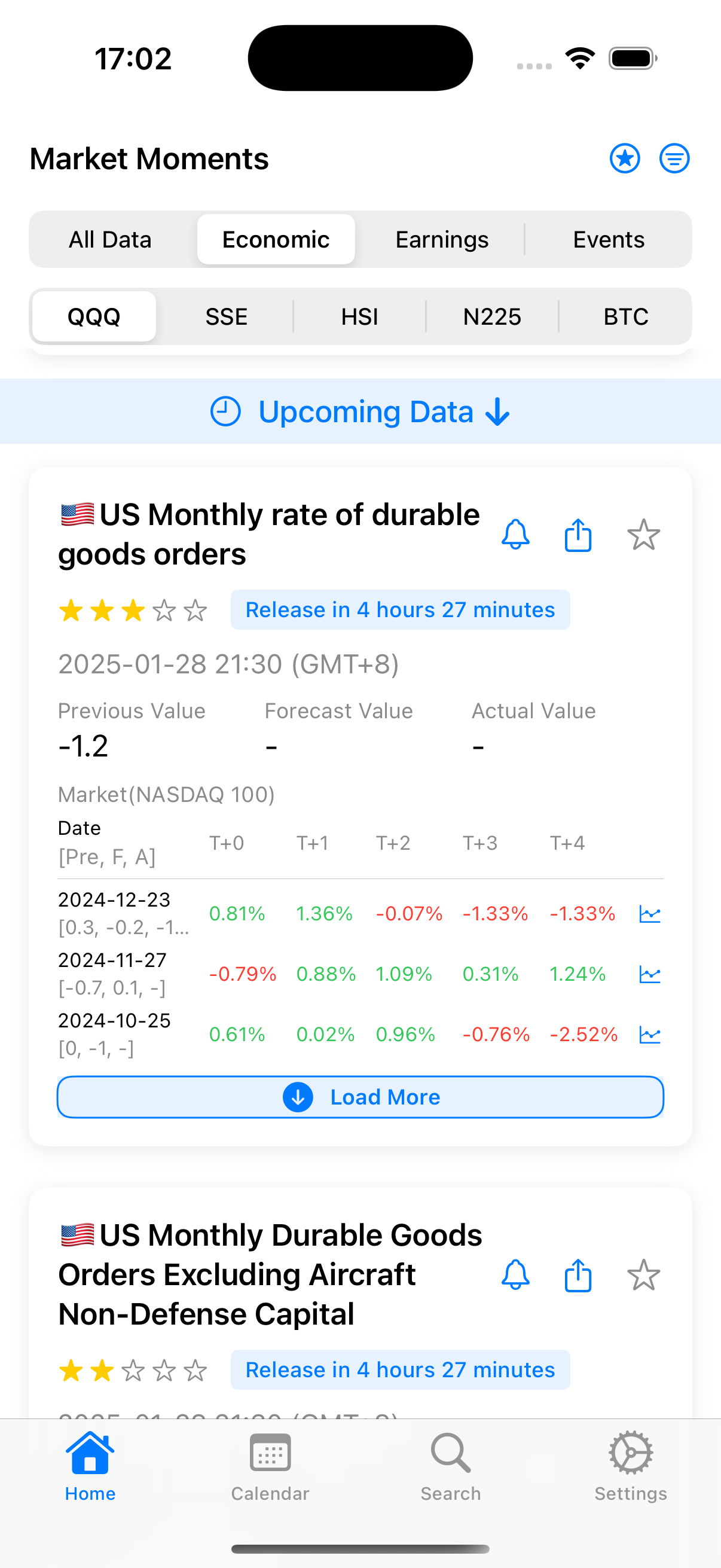
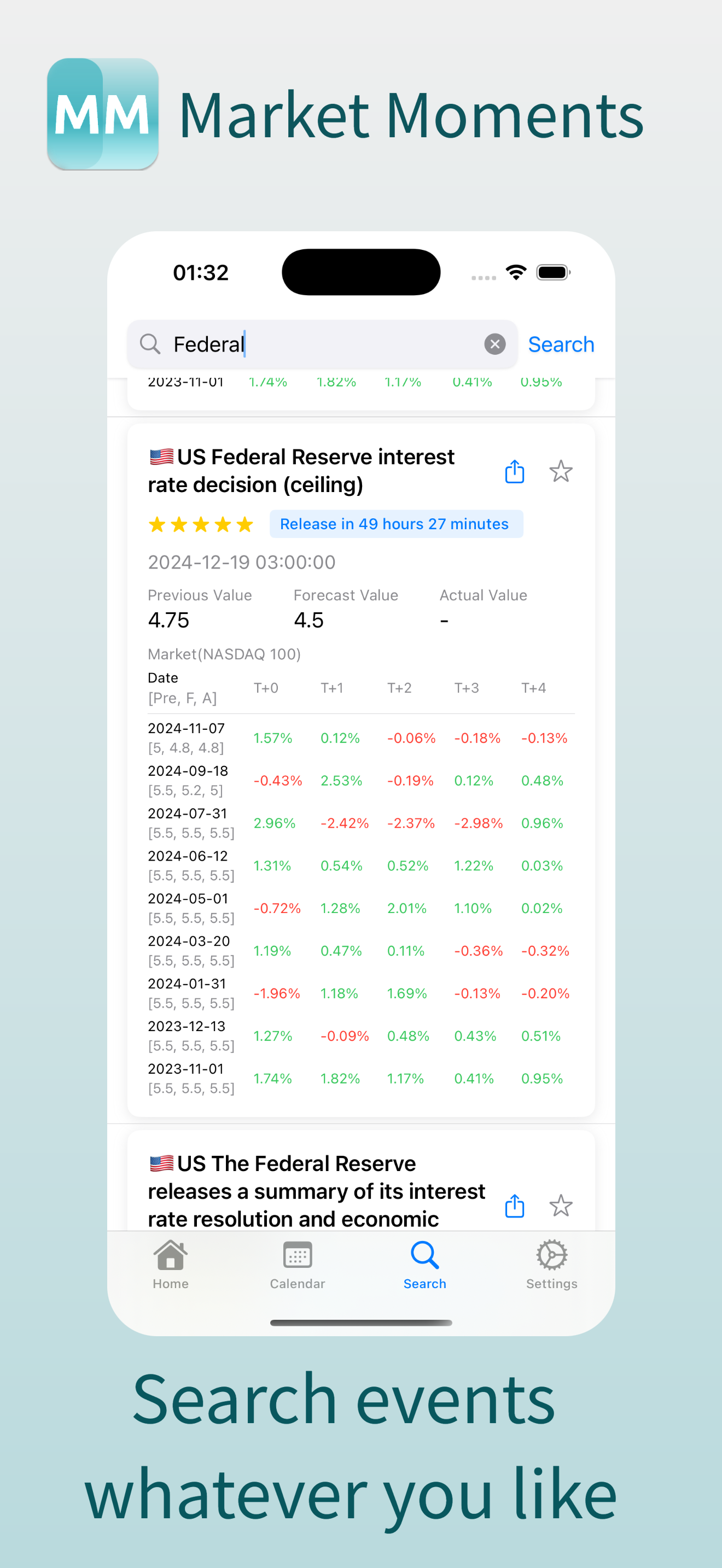
每隔一段时间,总有几个重要的经济数据会影响市场。美联储利率决定、非农、CPI、GDP、PMI…这些数字的起伏,往往牵动着全球市场的神经。
现在市面上的经济数据APP 大多都存在一个问题:没有直观体现经济数据发布后这些数据对世界各地的金融市场产生的影响。
这就是我开发 Market Moments 的初衷。它是一个简单但实用的经济数据工具:
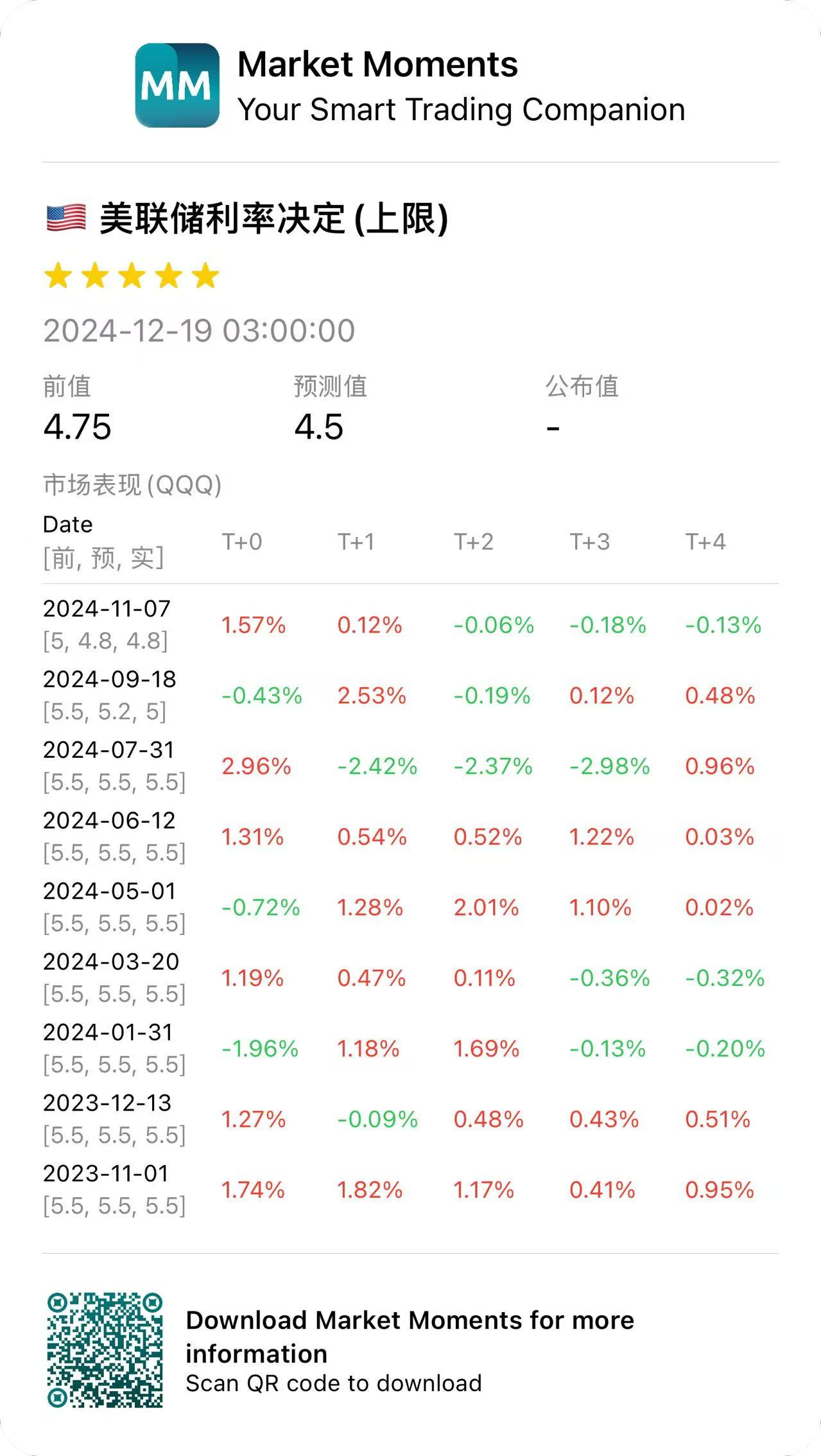
它就像一个随身的经济日历,帮你:
1. 追踪重要经济数据对不同市场的影响
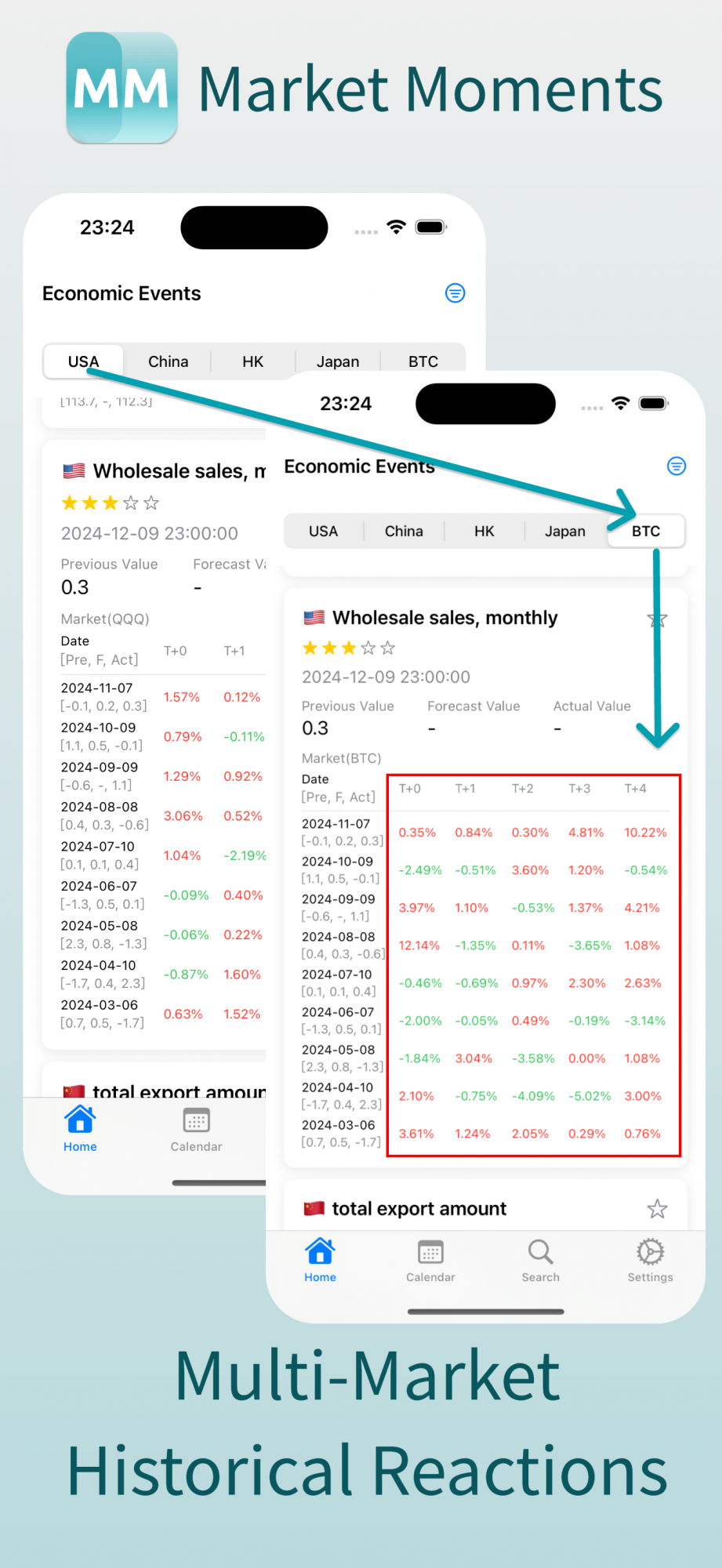
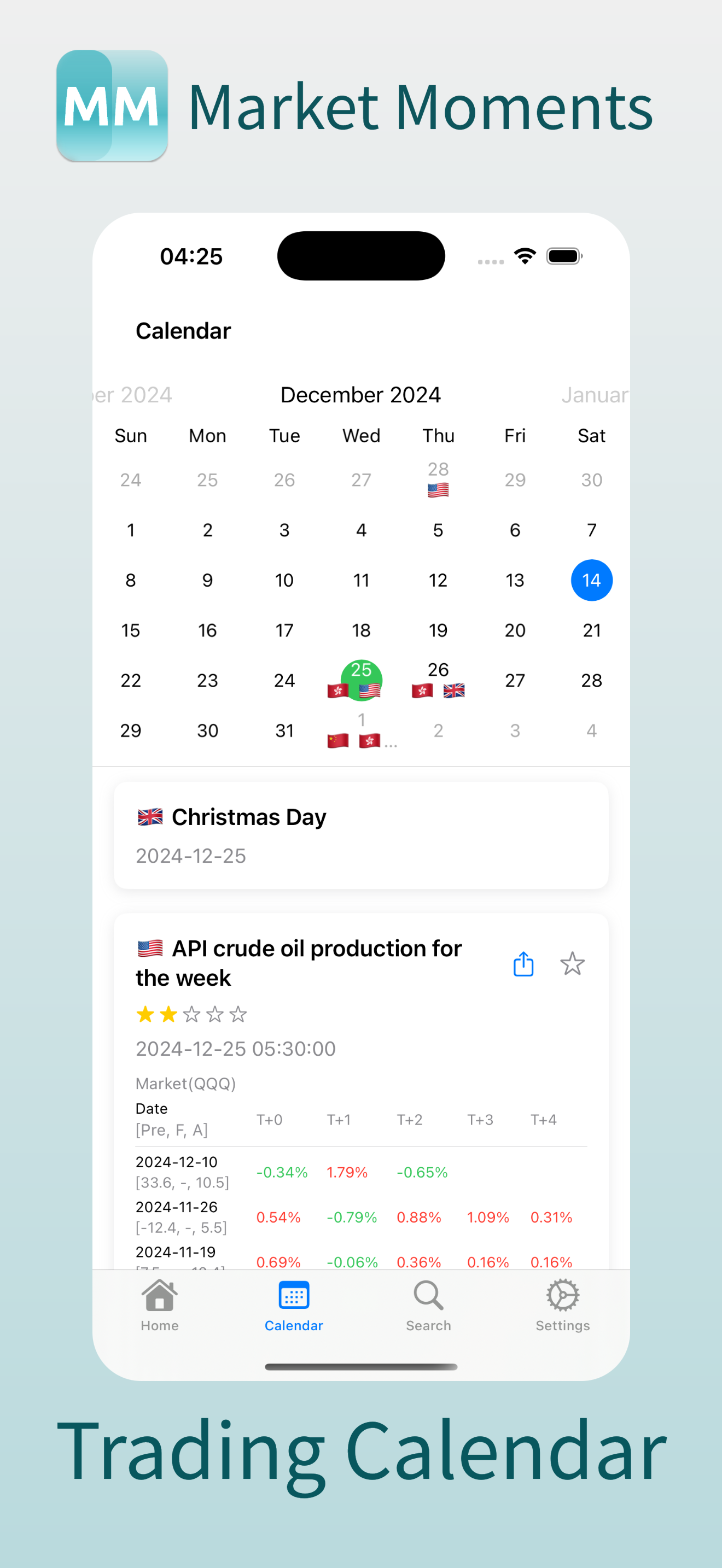
2. 交易日历,哪一天发布了什么经济事件,会发布什么经济事件,有什么节假日,在这个 APP 上一清二楚:
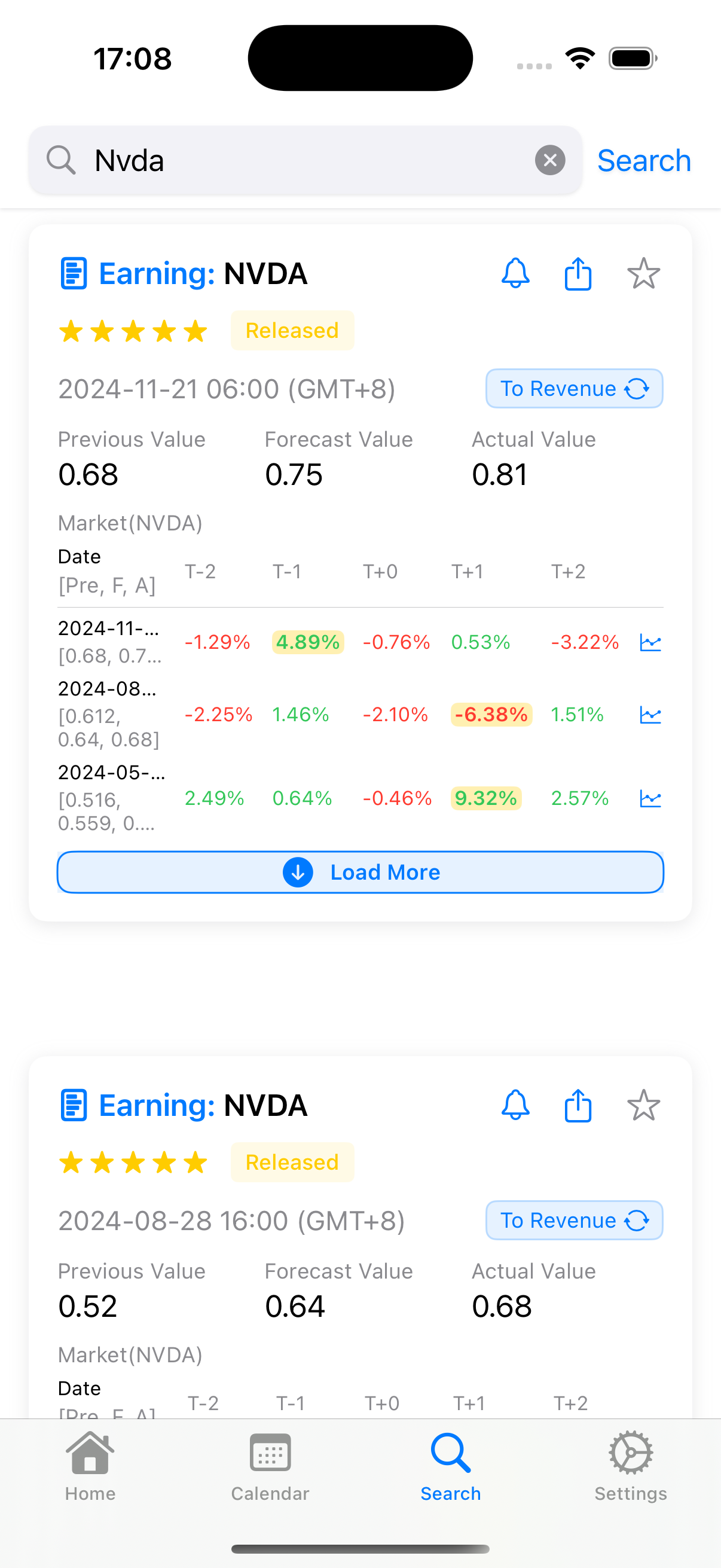
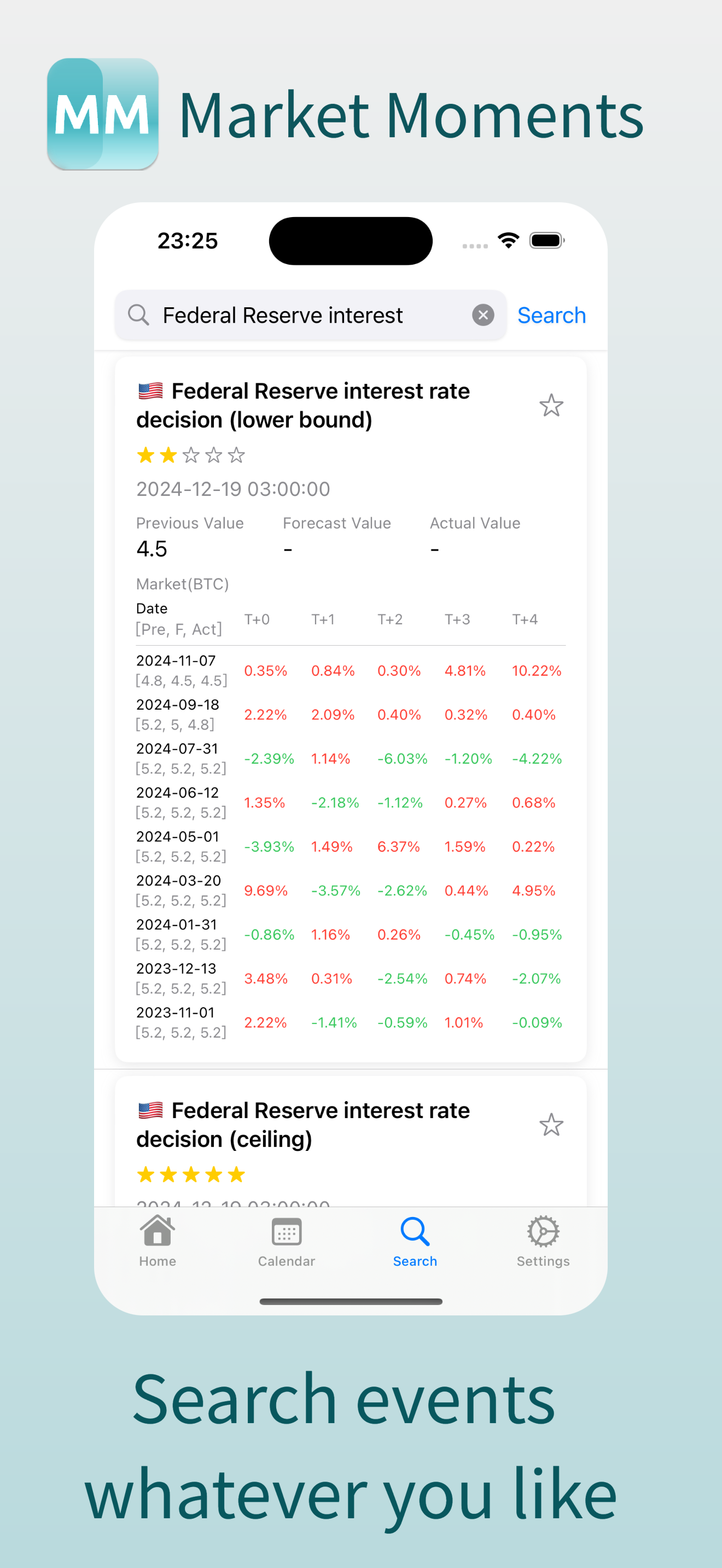
3. 搜索,你可以搜索历史上发生过的经济事件以及其对市场的影响
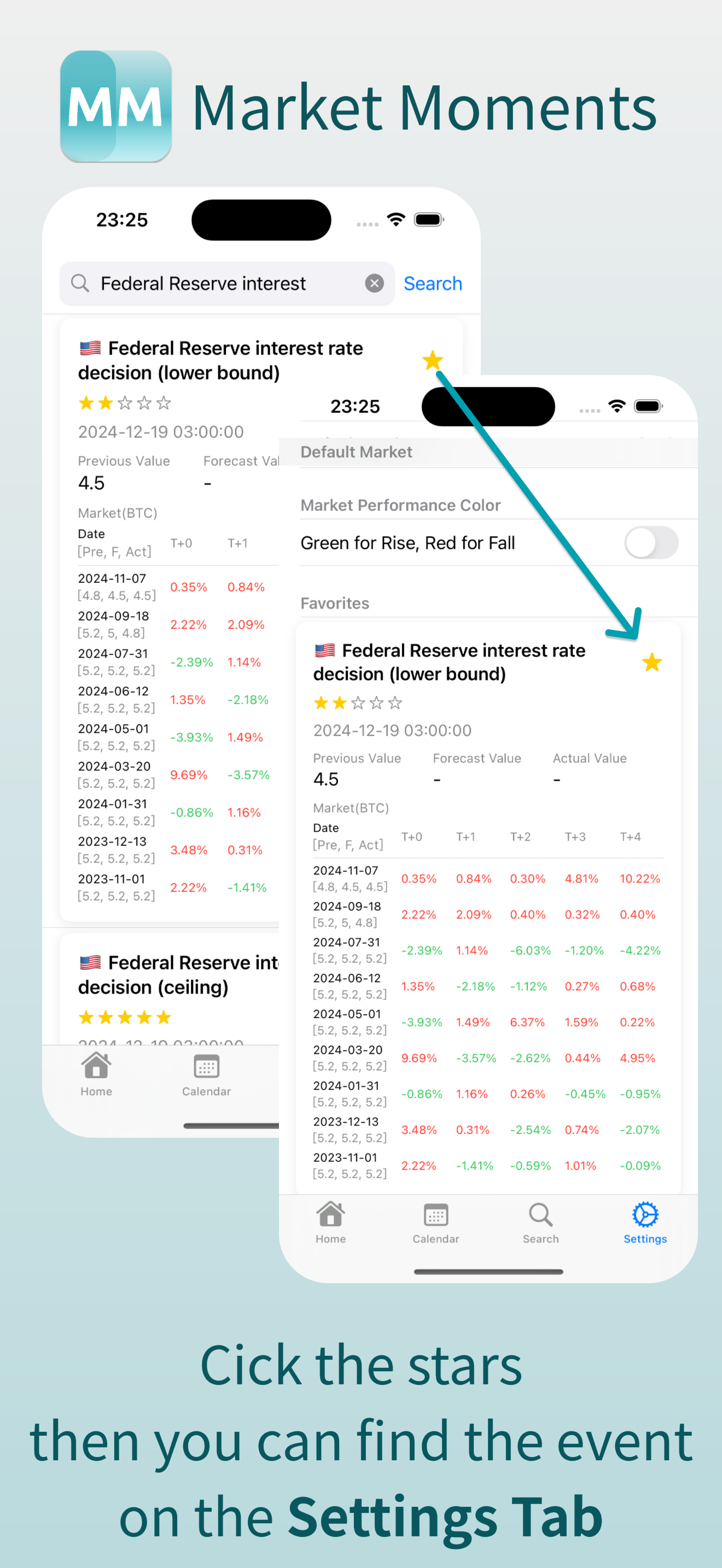
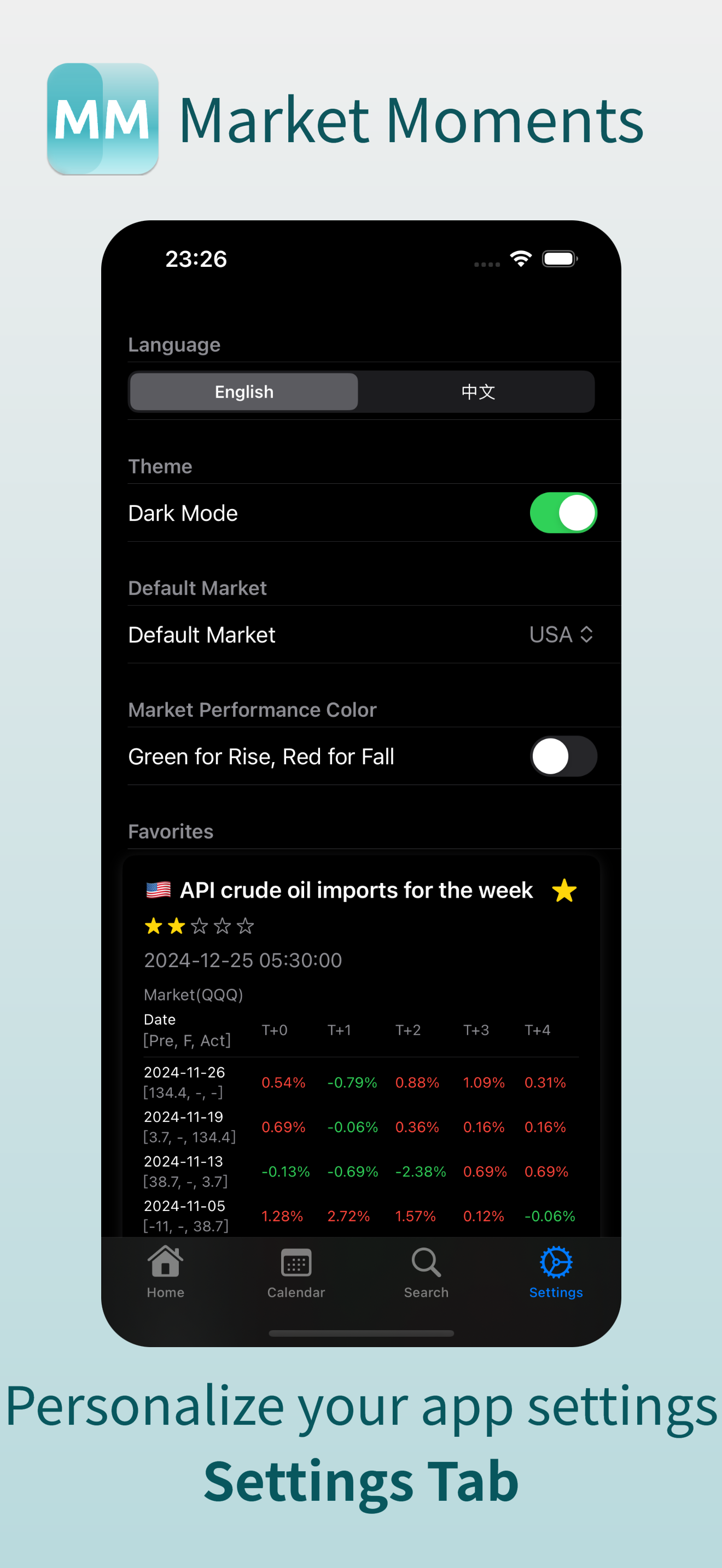
4. 收藏和自定义设置:点击右上角的小星星,你就可以收藏某个事件,避免重复查找。另外,在设置页面中,你还可以选择红涨绿跌/中英文/黑色模式等配置。
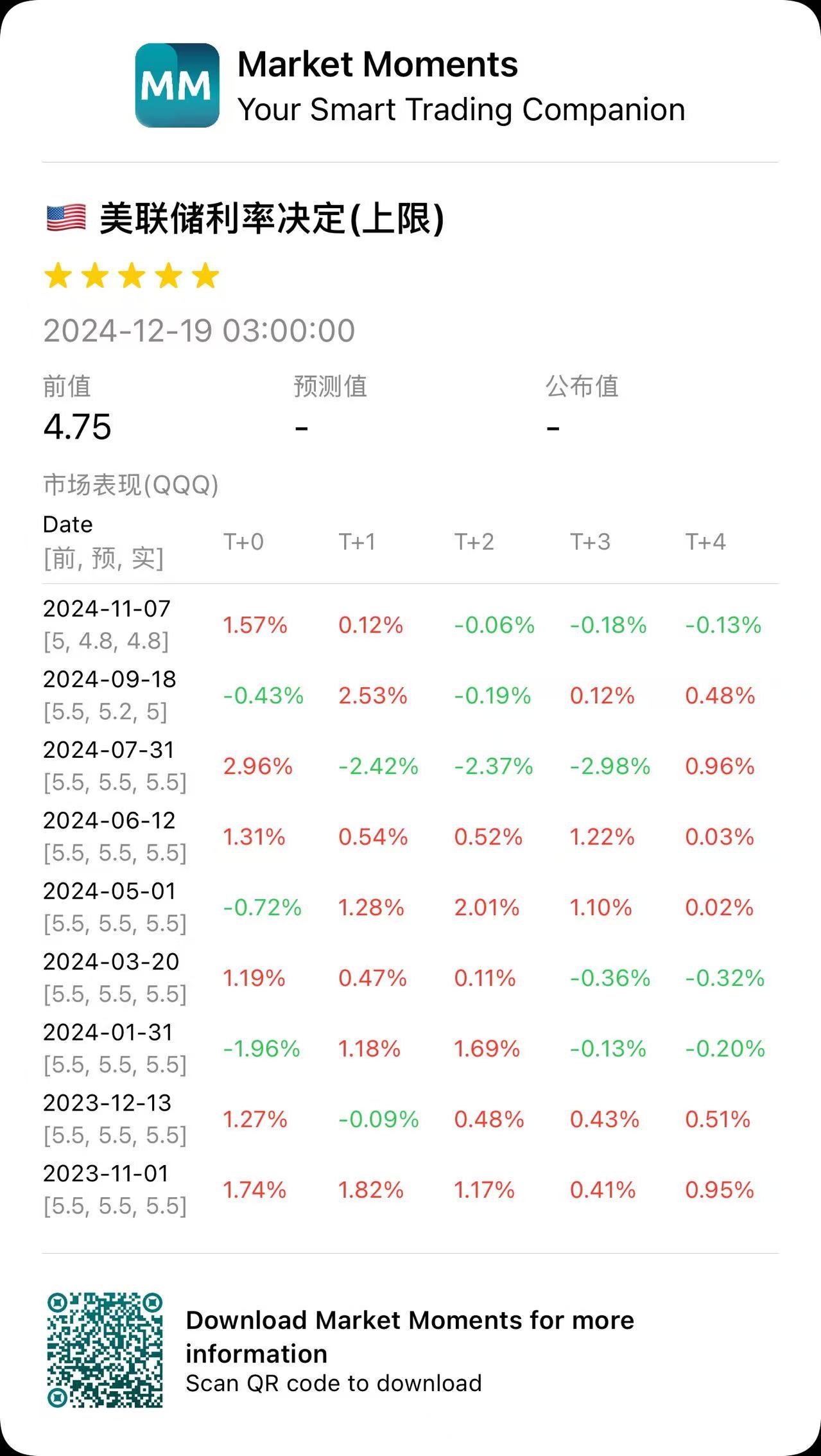
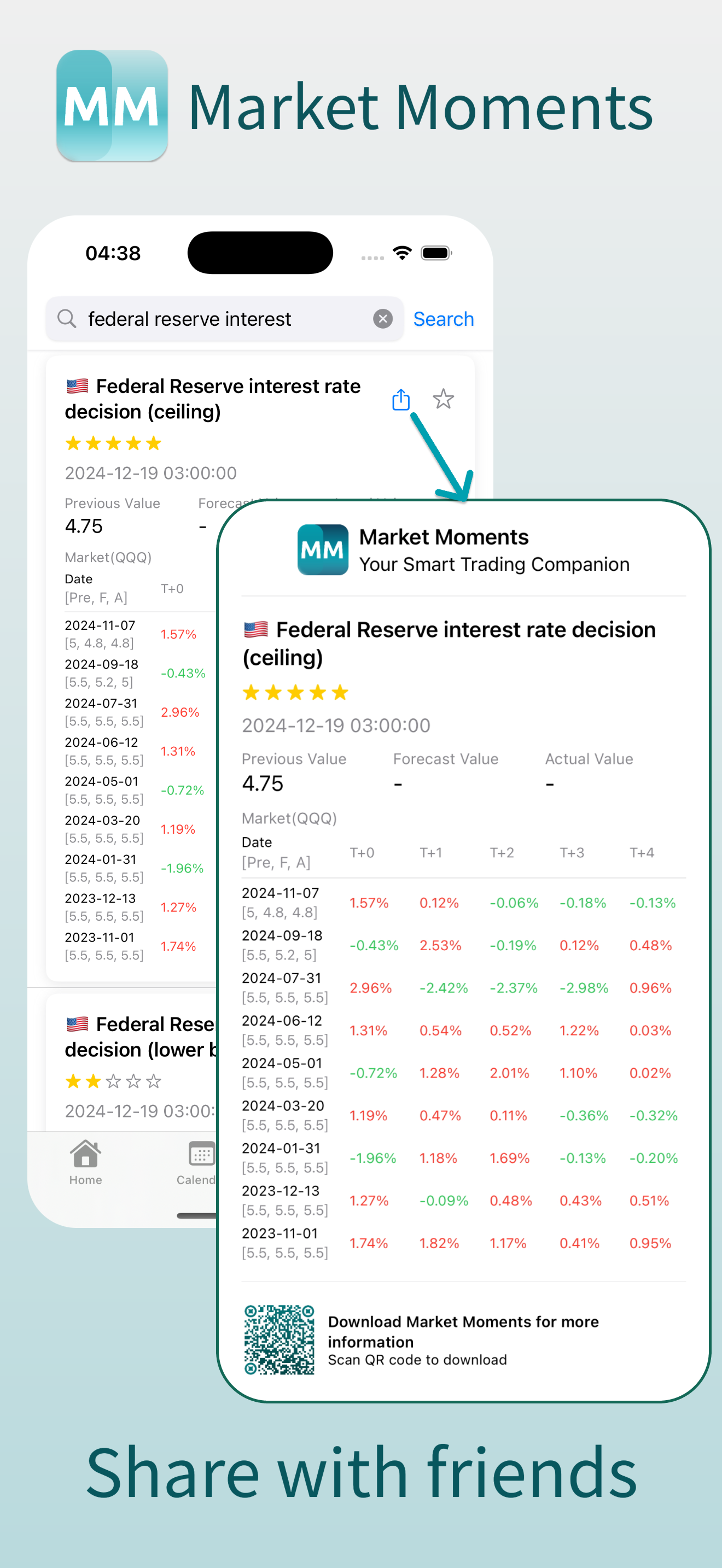
5.分享功能最后,你还可以通过分享按钮,将事件分享给你朋友:
不追求花哨的功能,只为满足最基础的需求 – 知道该看什么,什么时候看。
如果你也需要这样一个工具,欢迎在 App Store 搜索【Market Moments】。

鼎鼎大名的 Bert 算法相信大部分同学都听说过,它是Google推出的NLP领域“王炸级”预训练模型,其在NLP任务中刷新了多项记录,并取得state of the art的成绩。
但是有很多深度学习的新手发现BERT模型并不好搭建,上手难度很高,普通人可能要研究几天才能勉强搭建出一个模型。
没关系,今天我们介绍的这个模块,能让你在3分钟内基于BERT算法搭建一个问答搜索引擎。它就是 bert-as-service 项目。这个开源项目,能够让你基于多GPU机器快速搭建BERT服务(支持微调模型),并且能够让多个客户端并发使用。
开始之前,你要确保Python和pip已经成功安装在电脑上,如果没有,请访问这篇文章:超详细Python安装指南 进行安装。
(可选1) 如果你用Python的目的是数据分析,可以直接安装Anaconda:Python数据分析与挖掘好帮手—Anaconda,它内置了Python和pip.
(可选2) 此外,推荐大家用VSCode编辑器来编写小型Python项目:Python 编程的最好搭档—VSCode 详细指南
Windows环境下打开Cmd(开始—运行—CMD),苹果系统环境下请打开Terminal(command+空格输入Terminal),输入命令安装依赖:
pip install bert-serving-server # 服务端 pip install bert-serving-client # 客户端
请注意,服务端的版本要求:Python >= 3.5,Tensorflow >= 1.10 。
此外还要下载预训练好的BERT模型,在 https://github.com/hanxiao/bert-as-service#install 上可以下载,如果你无法访问该网站,也可以在 bert-serving 模型及源代码 此处下载。
也可在Python实用宝典后台回复 bert-as-service 下载这些预训练好的模型。
下载完成后,将 zip 文件解压到某个文件夹中,例如 /tmp/uncased_L-24_H-1024_A-16/.
安装完成后,输入以下命令启动BERT服务:
bert-serving-start -model_dir /tmp/uncased_L-24_H-1024_A-16/ -num_worker=4
-num_worker=4 代表这将启动一个有四个worker的服务,意味着它最多可以处理四个并发请求。超过4个其他并发请求将在负载均衡器中排队等待处理。
下面显示了正确启动时服务器的样子:
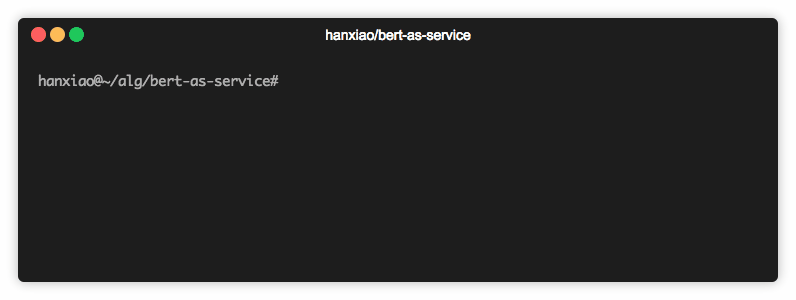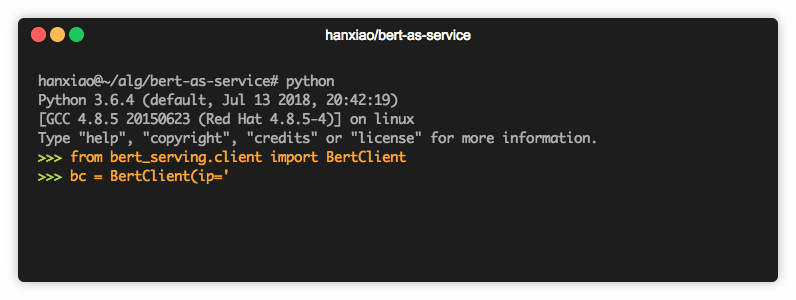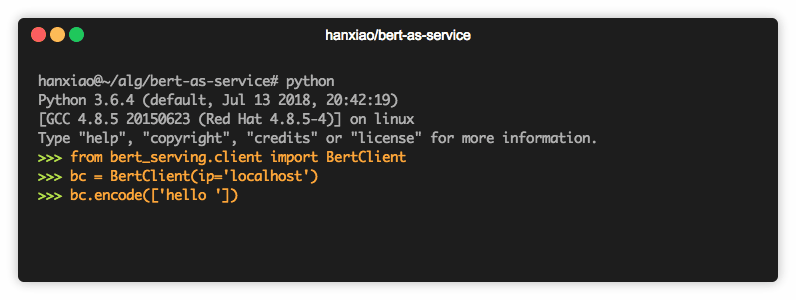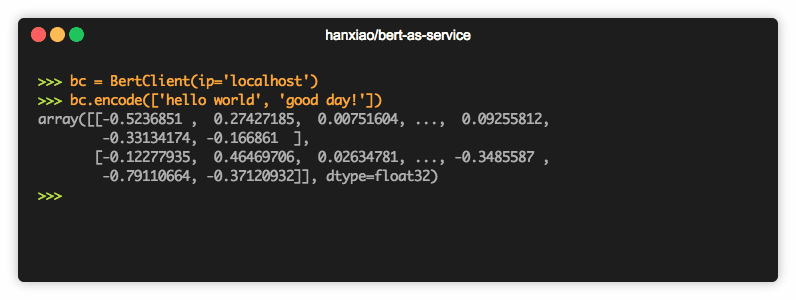
现在你可以简单地对句子进行编码,如下所示:
from bert_serving.client import BertClient bc = BertClient() bc.encode(['First do it', 'then do it right', 'then do it better'])
作为 BERT 的一个特性,你可以通过将它们与 |||(前后有空格)连接来获得一对句子的编码,例如
bc.encode(['First do it ||| then do it right'])

远程使用 BERT 服务
你还可以在一台 (GPU) 机器上启动服务并从另一台 (CPU) 机器上调用它,如下所示:
# on another CPU machine from bert_serving.client import BertClient bc = BertClient(ip='xx.xx.xx.xx') # ip address of the GPU machine bc.encode(['First do it', 'then do it right', 'then do it better'])
我们将通过 bert-as-service 从FAQ 列表中找到与用户输入的问题最相似的问题,并返回相应的答案。
FAQ列表你也可以在 Python实用宝典后台回复 bert-as-service 下载。
首先,加载所有问题,并显示统计数据:
prefix_q = '##### **Q:** '
with open('README.md') as fp:
questions = [v.replace(prefix_q, '').strip() for v in fp if v.strip() and v.startswith(prefix_q)]
print('%d questions loaded, avg. len of %d' % (len(questions), np.mean([len(d.split()) for d in questions])))
# 33 questions loaded, avg. len of 9
一共有33个问题被加载,平均长度是9.
然后使用预训练好的模型:uncased_L-12_H-768_A-12 启动一个Bert服务:
bert-serving-start -num_worker=1 -model_dir=/data/cips/data/lab/data/model/uncased_L-12_H-768_A-12
接下来,将我们的问题编码为向量:
bc = BertClient(port=4000, port_out=4001) doc_vecs = bc.encode(questions)
最后,我们准备好接收用户的查询,并对现有问题执行简单的“模糊”搜索。
为此,每次有新查询到来时,我们将其编码为向量并计算其点积 doc_vecs;然后对结果进行降序排序,返回前N个类似的问题:
while True:
query = input('your question: ')
query_vec = bc.encode([query])[0]
# compute normalized dot product as score
score = np.sum(query_vec * doc_vecs, axis=1) / np.linalg.norm(doc_vecs, axis=1)
topk_idx = np.argsort(score)[::-1][:topk]
for idx in topk_idx:
print('> %s\t%s' % (score[idx], questions[idx]))
完成!现在运行代码并输入你的查询,看看这个搜索引擎如何处理模糊匹配:
完整代码如下,一共23行代码(在后台回复关键词也能下载):
import numpy as np
from bert_serving.client import BertClient
from termcolor import colored
prefix_q = '##### **Q:** '
topk = 5
with open('README.md') as fp:
questions = [v.replace(prefix_q, '').strip() for v in fp if v.strip() and v.startswith(prefix_q)]
print('%d questions loaded, avg. len of %d' % (len(questions), np.mean([len(d.split()) for d in questions])))
with BertClient(port=4000, port_out=4001) as bc:
doc_vecs = bc.encode(questions)
while True:
query = input(colored('your question: ', 'green'))
query_vec = bc.encode([query])[0]
# compute normalized dot product as score
score = np.sum(query_vec * doc_vecs, axis=1) / np.linalg.norm(doc_vecs, axis=1)
topk_idx = np.argsort(score)[::-1][:topk]
print('top %d questions similar to "%s"' % (topk, colored(query, 'green')))
for idx in topk_idx:
print('> %s\t%s' % (colored('%.1f' % score[idx], 'cyan'), colored(questions[idx], 'yellow')))
够简单吧?当然,这是一个基于预训练的Bert模型制造的一个简单QA搜索模型。
你还可以微调模型,让这个模型整体表现地更完美,你可以将自己的数据放到某个目录下,然后执行 run_classifier.py 对模型进行微调,比如这个例子:
https://github.com/google-research/bert#sentence-and-sentence-pair-classification-tasks
它还有许多别的用法,我们这里就不一一介绍了,大家可以前往官方文档学习:
https://github.com/hanxiao/bert-as-service
我们的文章到此就结束啦,如果你喜欢今天的 Python 教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 ( pythondict.com )
不只是一个宝典
欢迎关注公众号:Python实用宝典

很多喜欢玩量化的同学都想要找一个靠谱且低费率能做自动化的券商。
我之前也推荐过一个渠道,但是因为他们公司内部问题,之前的那个开户渠道也遗憾下线了,今天给大家找到了一个新的渠道,费率如下:


有需要的或有任何疑问的可以直接联系我的微信: 83493903 (备注开户) 进行开通,或扫描二维码开户,有专业人士会跟进后续的开户和功能开通。
以下是二七阿尔量化的AI小机器人关于Copart公司的分析。
科帕特(Copart)是一家美国德克萨斯州达拉斯的在线车辆拍卖和再营销服务商,在北美、欧洲和中东都有业务。
[积极因素]:
[潜在问题]:
分析:基于积极的发展和潜在的担忧,我预测Copart(CPRT)的股价将在未来一周内上涨3-4%(从2023年11月17日到2023年11月24日)。公司强劲的财务表现和增长,以及高流动性,表明它是一个稳健的投资。然而,高负债水平和潜在的存货管理效率不足是可能影响公司盈利能力的潜在问题。
总体而言,公司最近的表现和未来的增长潜力表明它是一个强大的投资。然而,投资者应密切关注公司的债务水平和存货管理,以确保这些问题不会显现出来。在短期内,公司的股价预计将继续上升,受到强烈的市场情绪和公司基本面的推动。