
《机器学习100天》学习计划由 Avik-Jain/100-Days-Of-ML-Code 推出,现在一共有54天的教程,已经积攒了近30k的Star.
中文版的《机器学习100天》由 MLEveryday/100-Days-Of-ML-Code 提供,感谢作者和若干贡献者们的付出!
这个项目的内容非常详细,不仅有相关内容的图解,作者还提供了源代码给大家进行学习,相当适合新手。
不过我们Python实用宝典推出的这个100天学习计划并不完全跟着原作者的思路来走,我们会锦上添花,适当提供一些提示,比如安装依赖,模块说明和运行结果等。
建议想要学习机器学习的同学一定要跟着本教程走下去。
下面就让我们开始第一天的学习,数据预处理的步骤如下:

第0步:安装依赖 #
开始之前,你要确保Python和pip已经成功安装在电脑上,如果没有,请访问这篇文章:超详细Python安装指南 进行安装。
如果你用Python的目的是数据分析,可以直接安装Anaconda:Python数据分析与挖掘好帮手—Anaconda,它内置了Python和pip.
此外,推荐大家用VSCode编辑器:Python 编程的最好搭档—VSCode 详细指南
Windows环境下打开Cmd(开始—运行—CMD),苹果系统环境下请打开Terminal(command+空格输入Terminal),输入命令安装依赖:
pip install numpy pip install pandas pip install scikit-learn
第1步:导入库 #
导入我们刚刚安装的几个依赖:
import numpy as np import pandas as pd
第2步:导入数据集 #
这一步将通过pandas导入我们的数据集,请注意数据集文件要在运行python的当前目录下:
dataset = pd.read_csv('Data.csv')//读取csv文件
X = dataset.iloc[ : , :-1].values//.iloc[行,列]
Y = dataset.iloc[ : , 3].values // : 全部行 or 列;[a]第a行 or 列
// [a,b,c]第 a,b,c 行 or 列
print("Step 2: Importing dataset")
print("X")
print(X)
print("Y")
print(Y)今天的数据集和源代码你可以在Python实用宝典公众号回复 机器学习1 下载。或者在 https://pythondict.com/download/100-days-of-ml-code/ 下载本系列全部代码和数据。
第3步:处理丢失数据 #
使用sklearn的内置方法Imputer,可以将丢失的数据用特定的方法补全。
这里我们使用整列的平均值来替换:
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(missing_values=np.nan,strategy='mean')
imputer = imputer.fit(X[:,1:3])
X[:,1:3] = imputer.fit_transform(X[:,1:3])
print("---------------------")
print("Step 3: Handling the missing data")
print("step2")
print("X")
print(X)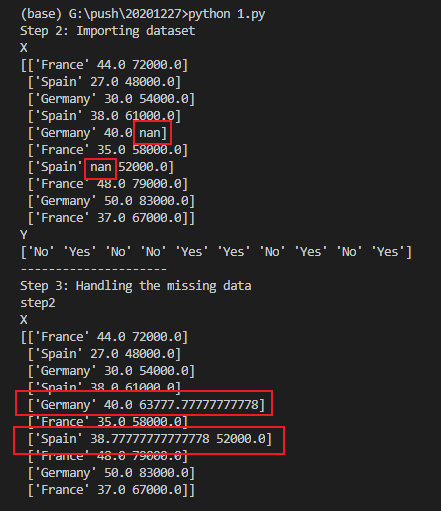
第4步:解析分类数据 #
从第3步的输出结果中我们可以看到分类数据Y中有很多”Yes”/”No”之类的字符标签,X中有很多国家的字符名称比如”France” , “Spain”,这些字符对于计算机而言,并不符合计算要求。
因此为了让机器方便进行数学计算,我们需要将其解析成数字:
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from sklearn.compose import ColumnTransformer
labelencoder_X = LabelEncoder()
X[ : , 0] = labelencoder_X.fit_transform(X[ : , 0])
# 创建虚拟变量
onehotencoder = ColumnTransformer([('encoder', OneHotEncoder(), [0])], remainder='passthrough')
X = onehotencoder.fit_transform(X)
labelencoder_Y = LabelEncoder()
Y = labelencoder_Y.fit_transform(Y)
print("---------------------")
print("Step 4: Encoding categorical data")
print("X")
print(X)
print("Y")
print(Y)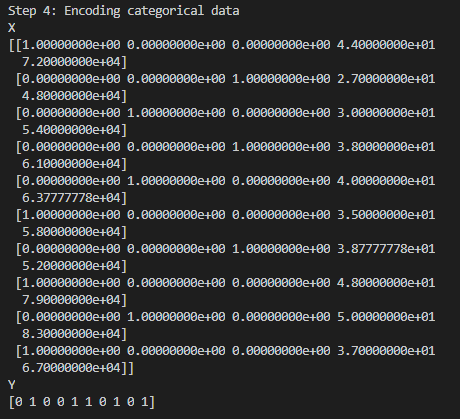
第5步:拆分数据集为训练集合和测试集合 #
我们知道,为了让机器学习到分类的特征,我们需要先“训练”机器,这时候就需要训练集。训练结束后需要测试刚训练得到的模型的效果,因此又需要测试集。
为了实现这个目的,将刚获得的数据集进行拆分,其中20%为测试集,80%为训练集。使用sklearn的train_test_split可以很容易做到:
from sklearn.cross_validation import train_test_split X_train, X_test, Y_train, Y_test = train_test_split( X , Y , test_size = 0.2, random_state = 0)
第6步:特征缩放 #
如第4步的结果显示,数据集中存在一些值比如[4000, 6000, 10000, 100], 这样会导致一个问题:大部分模型使用欧式距离进行计算:

因此越大的值,权重越大,但是在我们正常的应用范围中,不论这个值多大,它的权重都应该是相同的,这时候就需要引入StandardScaler进行数据标准化了:
from sklearn.preprocessing import StandardScaler sc_X = StandardScaler() X_train = sc_X.fit_transform(X_train) X_test = sc_X.transform(X_test)
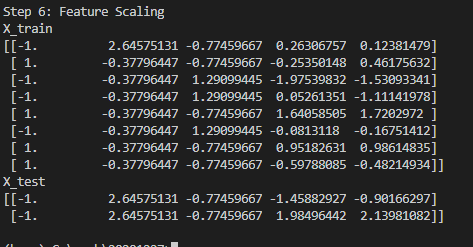
将数据特征标准化后,每个数据的权重都是相同的,这样进行计算的时候才是最准确的。
做完数据标准化这一步后,就可以进行模型的训练了,不过不用着急,请大家把今天的这些内容都敲一遍,学习透彻后,我们再进入下一天的学习。
我们的文章到此就结束啦,如果你喜欢今天的 Python 教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 ( pythondict.com )
不只是一个宝典
欢迎关注公众号:Python实用宝典





评论(6)
最新版
from sklearn.impute import SimpleImputer
imputer=SimpleImputer(missing_values=np.nan,strategy=’mean’)
imputer=imputer.fit(X[:,1:3])
X[:,1:3]=imputer.fit_transform(X[:,1:3])
最新版报错:
onehotencoder = OneHotEncoder(categorical_features = [0])
已更新
建议更新,或者在项目前面标注版本,有些都已经变了 ,例如:训练集 from sklearn.model_selection import train_test_split
感谢提醒,应该是用了旧的版本,我更新一下
from sklearn.model_selection import train_test_split
应该没问题