



在人工智能领域中,有一项非常关键的技术,那就是图像分割。
图像分割是指将图像中具有特殊意义的不同区域划分开来, 这些区域互不相交,每个区域满足灰度、纹理、彩色等特征的某种相似性准则。

比如上图识别视盘。视盘是视网膜中的关键解剖学结构,其形状、面积和深度等参数是衡量眼底健康状况的重要指标,准确定位和分割视盘区域是眼底图像分析和处理的关键步骤。
在人工智能的辅助下,只需要数秒,即可初步判断被检者是否存在眼底疾病,这将有助缓解专业眼科医生不足的瓶颈,开启眼底疾病的基层筛查新模式。而图像分割就是实现这项功能的基础,可见其重要性。
下面就给大家讲讲如何基于 PaddlePaddle 平台,训练并测试一个视盘图像分割的基本模型。
1.Python 准备
为了实现这个实验,Python 是必不可少的,如果你还没有安装 Python,建议阅读我们的这篇文章:超详细Python安装指南。
在安装前,确认自己需要的 PaddlePaddle 版本,比如 GPU版 或 CPU版,GPU 在计算上具有绝对优势,但是如果你没有一块强力的显卡,建议选择CPU版本。
(GPU版) 如果你想使用GPU版,请确认本机安装了 CUDA 计算平台及 cuDNN,它们的下载地址分别是:
https://developer.nvidia.com/cuda-downloads
https://developer.nvidia.com/cudnn-download-survey
具体 CUDA 和 cuDNN 对应的版本要求如下:
- CUDA 工具包10.1/10.2配合cuDNN v7.6+
- CUDA 工具包11.2配合cuDNN v8.1.1
CUDA安装流程很简单,下载exe程序,一路往下走。cuDNN安装流程复杂一些,你需要转移压缩包解压后的部分文件到CUDA中,具体可见这篇cuDNN的官方安装指引:
https://docs.nvidia.com/deeplearning/cudnn/install-guide/index.html
(CPU版)CPU版安装过程比较简单,直接按照下面 PaddlePaddle 的安装指引输入命令即可。
(通用)选择完你想要安装的版本,并做好基础工作后,接下来就是安装 PaddlePaddle 的具体步骤,打开安装指引流程页面:
https://www.paddlepaddle.org.cn/install/quick

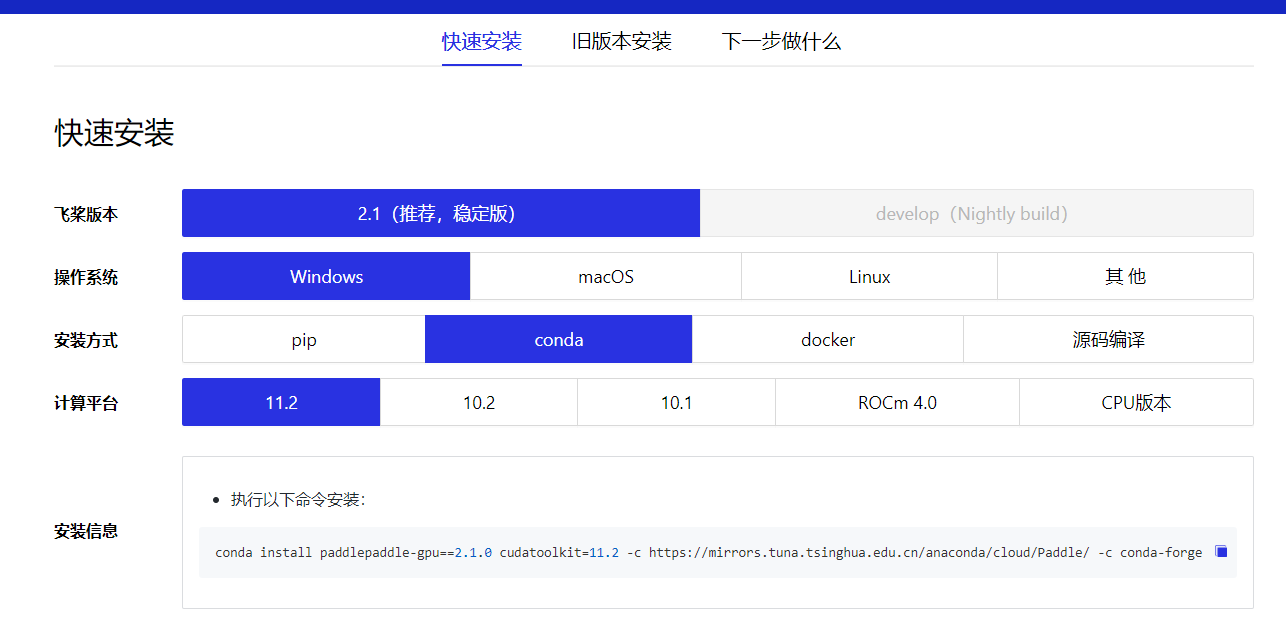
根据你自己的情况选择这些选项,最后一个选项计算平台指的是 GPU 加速工具包或CPU,如果你不想用GPU,请选CPU版;想用GPU版的同学请按刚刚下载的CUDA版本进行选择。
选择完毕后下方会出现安装信息,输入安装信息里的命令即可安装成功,不得不说,PaddlePaddle 这些方面做的还是比较贴心的。
在页面下方还有具体的从头到尾的安装步骤,对 Python 基本的虚拟环境安装流程不了解的同学可以看着这些步骤进行安装。

2.初尝paddleseg图像分割
安装完 paddle 后,为了能够实现图像分割功能,我们还需要安装 paddleseg:
pip install paddleseg
并克隆 paddleseg的代码库(如果克隆不了,请在Python实用宝典公众号后台回复:图像分割 下载):
git clone https://github.com/PaddlePaddle/PaddleSeg.git
克隆完成,进入代码库文件夹:
cd PaddleSeg
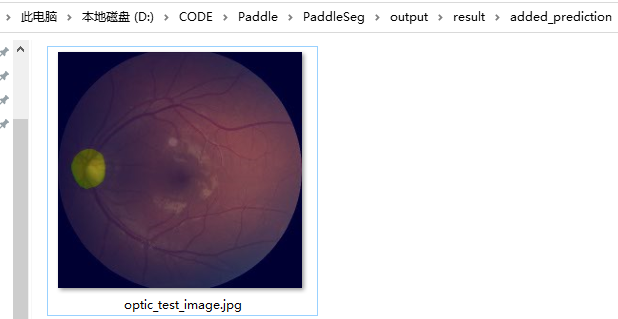
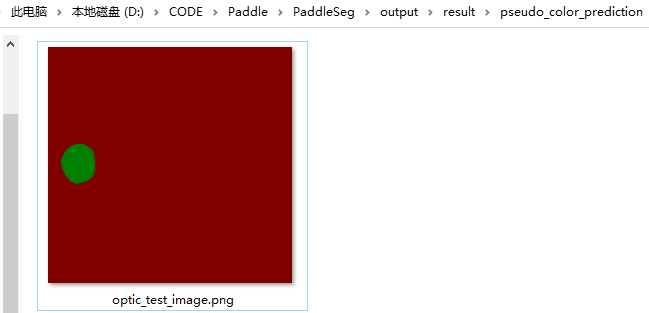
执行下面命令,并在 PaddleSeg/output 文件夹中出现预测结果,则证明安装成功。
python predict.py \
--config configs/quick_start/bisenet_optic_disc_512x512_1k.yml \
--model_path https://bj.bcebos.com/paddleseg/dygraph/optic_disc/bisenet_optic_disc_512x512_1k/model.pdparams\
--image_path docs/images/optic_test_image.jpg \
--save_dir output/result预测结果如下:


3.训练模型
前面只是利用了 PaddlePaddle 提前训练好的数据进行预测,下面我们要尝试自己训练一个模型。
为了训练模型,我们需要获得眼底训练集。事实上,在前面 初尝 Paddleseg 中,我们便获得了一份眼底训练集,其路径是 PaddleSeg\data\optic_disc_seg.
如果你没有进行 初尝 Paddleseg 这一节,也想要获取训练集数据的话,在Python实用宝典公众号后台回复:图像分割 下载。下载后解压数据集,得到一个optic_disc_seg文件夹,将其放到 PaddleSeg 代码库的 data 文件夹下。
配置化训练
PaddleSeg 提供了配置化驱动进行模型训练。他们在配置文件中详细列出了每一个可以优化的选项,用户只要修改这个配置文件就可以对模型进行定制。
所有的配置文件在PaddleSeg/configs文件夹下面:

每一个文件夹代表一个模型,里面包含这个模型的所有配置文件。
在PaddleSeg的配置文件给出的学习率中,除了”bisenet_optic_disc_512x512_1k.yml”中为单卡学习率外,其余配置文件中均为4卡的学习率,因此如果你是单卡训练,则学习率设置应变成原来的1/4。
为了简化学习难度,我们继续以”bisenet_optic_disc_512x512_1k.yml”文件为例,修改部分参数进行训练,下面是这个配置的全部说明:
batch_size: 4 #设定batch_size的值即为迭代一次送入网络的图片数量,一般显卡显存越大,batch_size的值可以越大
iters: 1000 #模型迭代的次数
train_dataset: #训练数据设置
type: OpticDiscSeg #选择数据集格式
dataset_root: data/optic_disc_seg #选择数据集路径
num_classes: 2 #指定目标的类别个数(背景也算为一类)
transforms: #数据预处理/增强的方式
- type: Resize #送入网络之前需要进行resize
target_size: [512, 512] #将原图resize成512*512在送入网络
- type: RandomHorizontalFlip #采用水平反转的方式进行数据增强
- type: Normalize #图像进行归一化
mode: train
val_dataset: #验证数据设置
type: OpticDiscSeg #选择数据集格式
dataset_root: data/optic_disc_seg #选择数据集路径
num_classes: 2 #指定目标的类别个数(背景也算为一类)
transforms: #数据预处理/增强的方式
- type: Resize #将原图resize成512*512在送入网络
target_size: [512, 512] #将原图resize成512*512在送入网络
- type: Normalize #图像进行归一化
mode: val
optimizer: #设定优化器的类型
type: sgd #采用SGD(Stochastic Gradient Descent)随机梯度下降方法为优化器
momentum: 0.9 #动量
weight_decay: 4.0e-5 #权值衰减,使用的目的是防止过拟合
learning_rate: #设定学习率
value: 0.01 #初始学习率
decay:
type: poly #采用poly作为学习率衰减方式。
power: 0.9 #衰减率
end_lr: 0 #最终学习率
loss: #设定损失函数的类型
types:
- type: CrossEntropyLoss #损失函数类型
coef: [1, 1, 1, 1, 1]
#BiseNetV2有4个辅助loss,加上主loss共五个,1表示权重 all_loss = coef_1 * loss_1 + .... + coef_n * loss_n
model: #模型说明
type: BiSeNetV2 #设定模型类别
pretrained: Null #设定模型的预训练模型你可以尝试调整部分参数进行训练,看看你自己训练的模型效果和官方给出的模型的效果的差别。
开始训练
(GPU版)在正式开启训练前,我们需要将CUDA设置为目前有1张可用的显卡:
set CUDA_VISIBLE_DEVICES=0 # windows # export CUDA_VISIBLE_DEVICES=0 # linux
输入训练命令开始训练:
python train.py \
--config configs/quick_start/bisenet_optic_disc_512x512_1k.yml \
--do_eval \
--use_vdl \
--save_interval 500 \
--save_dir output训练参数解释
| 参数名 | 用途 | 是否必选项 | 默认值 |
|---|---|---|---|
| iters | 训练迭代次数 | 否 | 配置文件中指定值 |
| batch_size | 单卡batch size | 否 | 配置文件中指定值 |
| learning_rate | 初始学习率 | 否 | 配置文件中指定值 |
| config | 配置文件 | 是 | – |
| save_dir | 模型和visualdl日志文件的保存根路径 | 否 | output |
| num_workers | 用于异步读取数据的进程数量, 大于等于1时开启子进程读取数据 | 否 | 0 |
| use_vdl | 是否开启visualdl记录训练数据 | 否 | 否 |
| save_interval_iters | 模型保存的间隔步数 | 否 | 1000 |
| do_eval | 是否在保存模型时启动评估, 启动时将会根据mIoU保存最佳模型至best_model | 否 | 否 |
| log_iters | 打印日志的间隔步数 | 否 | 10 |
| resume_model | 恢复训练模型路径,如:output/iter_1000 | 否 | None |
| keep_checkpoint_max | 最新模型保存个数 | 否 | 5 |
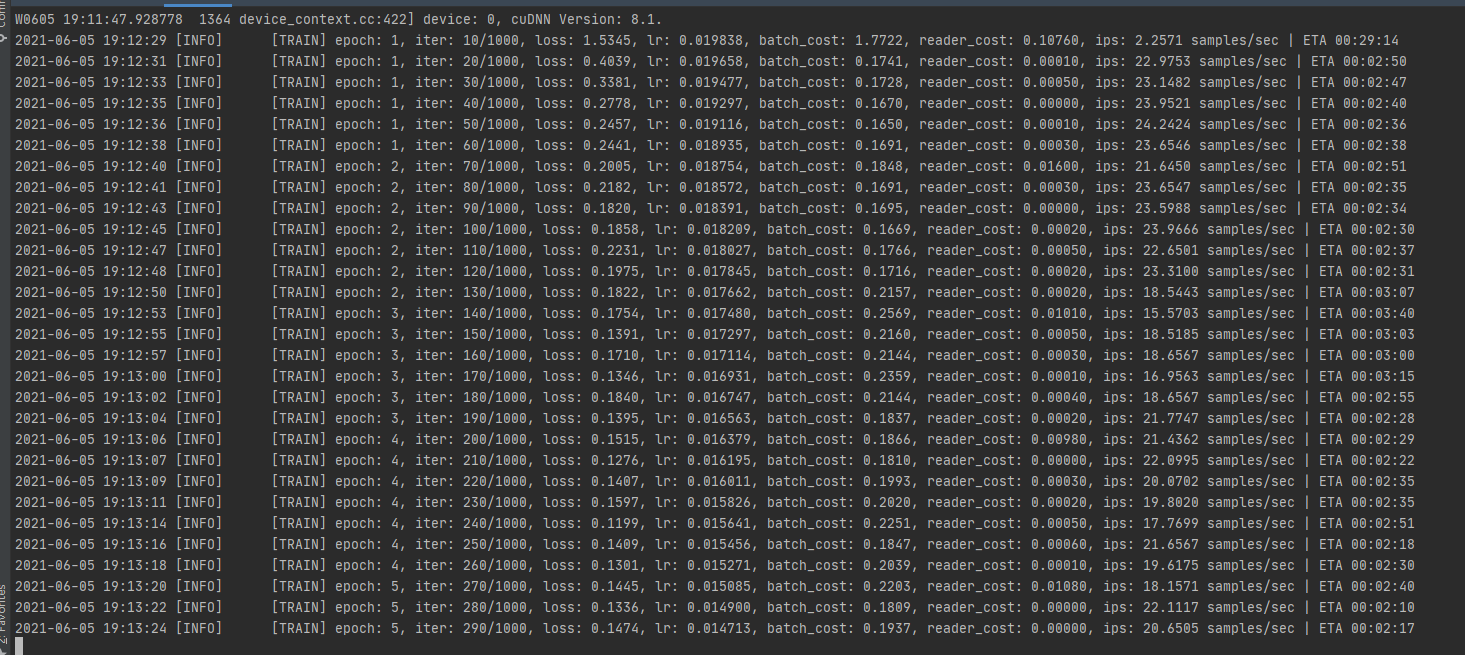
见到如下的界面,说明你已经开始训练了:

4.训练过程可视化
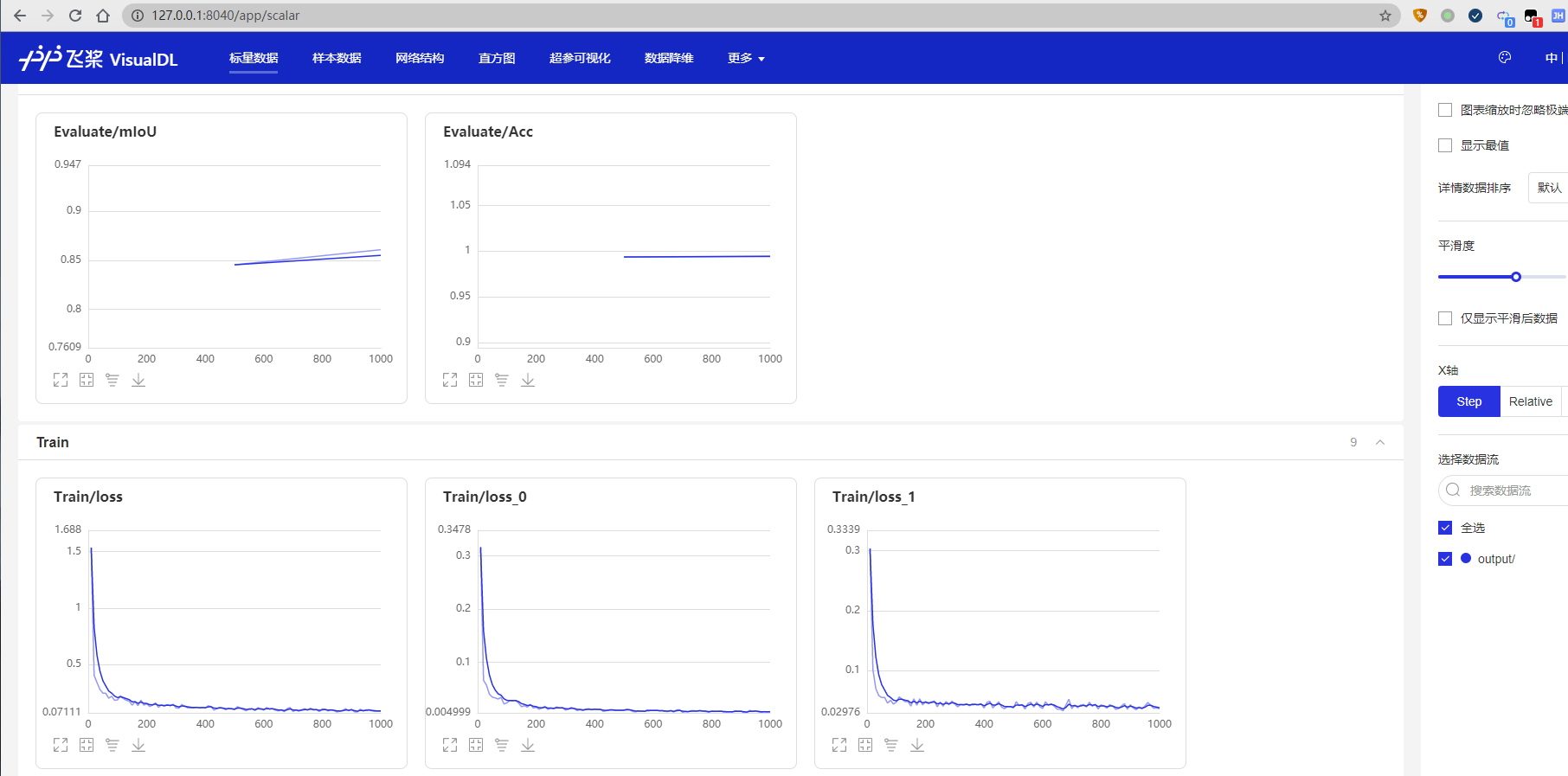
PaddlePaddle 还提供了可视化分析工具:VisualDL,让我们的网络训练过程更加直观。
当打开use_vdl开关后,PaddleSeg会将训练过程中的数据写入VisualDL文件,可实时查看训练过程中的日志。记录的数据包括:
- loss变化趋势
- 学习率变化趋势
- 训练时间
- 数据读取时间
- mean IoU变化趋势(当打开了do_eval开关后生效)
- mean pixel Accuracy变化趋势(当打开了do_eval开关后生效)
使用如下命令启动VisualDL查看日志
# 下述命令会在127.0.0.1上启动一个服务,支持通过前端web页面查看,可以通过--host这个参数指定实际ip地址 visualdl --logdir output/
在浏览器输入提示的网址,效果如下:


如图所示,打开 http://127.0.0.1:8040/ 页面,效果如下:

5.模型测试评估
训练完成后,用户可以使用评估脚本val.py来评估模型效果。
假设训练过程中迭代次数(iters)为1000,保存模型的间隔为500,即每迭代1000次数据集保存2次训练模型。
因此一共会产生2个定期保存的模型,加上保存的最佳模型best_model,一共有3个模型,可以通过model_path指定期望评估的模型文件。
python val.py \
--config configs/quick_start/bisenet_optic_disc_512x512_1k.yml \
--model_path output/iter_1000/model.pdparams在图像分割领域中,评估模型质量主要是通过三个指标进行判断,准确率(acc)、平均交并比(Mean Intersection over Union,简称mIoU)、Kappa系数。
- 准确率:指类别预测正确的像素占总像素的比例,准确率越高模型质量越好。
- 平均交并比:对每个类别数据集单独进行推理计算,计算出的预测区域和实际区域交集除以预测区域和实际区域的并集,然后将所有类别得到的结果取平均。在本例中,正常情况下模型在验证集上的mIoU指标值会达到0.80以上,显示信息示例如下所示,第2行的mIoU=0.8609即为mIoU。
- Kappa系数:一个用于一致性检验的指标,可以用于衡量分类的效果。Kappa系数越高模型质量越好。
随着评估脚本的运行,最终打印的评估日志如下。
76/76 [==============================] - 6s 84ms/step - batch_cost: 0.0835 - reader cost: 0.0029 2021-06-05 19:38:53 [INFO] [EVAL] #Images: 76 mIoU: 0.8609 Acc: 0.9945 Kappa: 0.8393 2021-06-05 19:38:53 [INFO] [EVAL] Class IoU: [0.9945 0.7273] 2021-06-05 19:38:53 [INFO] [EVAL] Class Acc: [0.9961 0.8975]
可以看到,我改了参数后的训练效果还是不错的。
6.效果可视化
除了分析模型的IOU、ACC和Kappa指标之外,我们还可以查阅一些具体样本的切割样本效果,从Bad Case启发进一步优化的思路。
predict.py脚本是专门用来可视化预测案例的,命令格式如下所示
python predict.py \
--config configs/quick_start/bisenet_optic_disc_512x512_1k.yml \
--model_path output/iter_1000/model.pdparams \
--image_path data/optic_disc_seg/JPEGImages/H0003.jpg \
--save_dir output/result运行完成后,打开 output/result 文件夹。我们选择1张图片进行查看,效果如下。

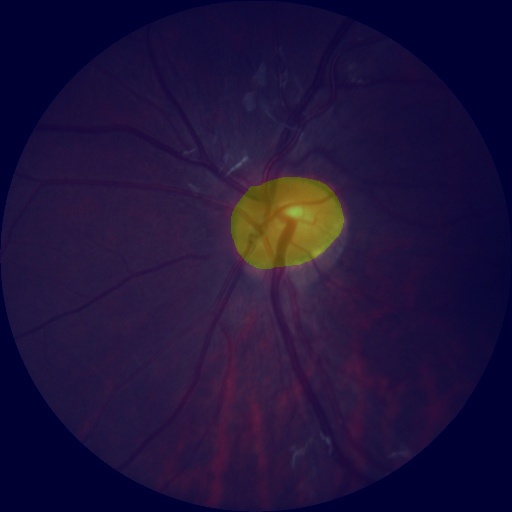
我们可以直观的看到模型的切割效果和原始标记之间的差别,从而产生一些优化的思路,比如是否切割的边界可以做规则化的处理等。
大家也可以尝试自己标注一个数据集进行图像分割,你只要按照 PaddleSeg\data\optic_disc_seg 里面那样组织图片结构,就可以复用这些训练、评估的过程。
本文部分内容摘自: PaddleSeg官方文档
我们的文章到此就结束啦,如果你喜欢今天的 Python 教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 ( pythondict.com )
不只是一个宝典
欢迎关注公众号:Python实用宝典

