
很多同学都对自然语言处理感兴趣,但是却不知道应该从哪里下手。Python实用宝典曾写过一篇文章(《短文本分类识别自杀倾向》),教你从构建数据集到训练数据,再到测试数据,整个流程确实需要耐心的人才能成功走通。
不过现在有了paddlehub,我们可以先省略掉构建数据集和训练数据这两个步骤,直接拿模型过来文本分类。
一旦简单版的分类成功了,你就会有动力继续前进,继续学习如何训练属于自己的模型。
今天我们用paddlehub中比较简单的情感倾向分析模型 senta_lstm 来对文本做一个简单的积极和消极的分类。
1.准备
为了实现这个实验,Python是必不可少的,如果你还没有安装Python,建议阅读我们的这篇文章哦:超详细Python安装指南。
然后,我们需要安装百度的paddlepaddle, 进入他们的官方网站就有详细的指引:
https://www.paddlepaddle.org.cn/install/quick
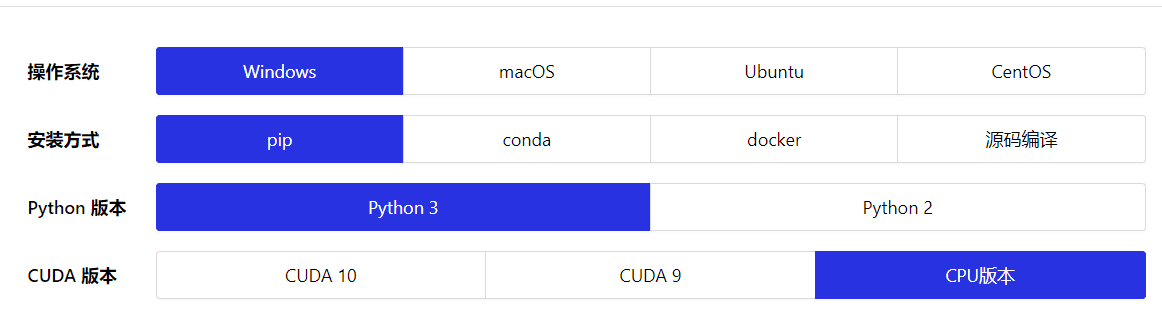
根据你自己的情况选择这些选项,最后一个CUDA版本,由于本实验不需要训练数据,也不需要太大的计算量,所以直接选择CPU版本即可。选择完毕,下方会出现安装指引,不得不说,Paddlepaddle这些方面做的还是比较贴心的(就是名字起的不好)。

不过虽然它里面写了这么多,大部分人用一句话安装,打开CMD(Win+R)或者Terminal(Command+空格搜索)输入以下命令即可安装:
pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
还需要安装paddlehub,这点别忘了:
pip install -i https://mirror.baidu.com/pypi/simple paddlehub
2.编写代码
整个步骤分为三步:
1.加载模型
2.指定待分类文本
3.情感分类
import paddlehub as hub
# 加载模型
senta = hub.Module(name="senta_lstm")
# 待分类文本
test_text = [
"你长得真好看",
"《黑色四叶草》是部不错的番"
]
# 情感分类
results = senta.sentiment_classify(data={"text": test_text})
# 得到结果
for result in results:
print(result)将这份代码保存为 code.py, (如果你懒得打一遍,可以再公众号后台回复 识别文本情感 获得代码)在CMD或Terminal中进入该文件文件夹运行以下命令执行脚本: python code.py
就能得到以下结果:
{‘text’: ‘你长得真好看’, ‘sentiment_label’: 1, ‘sentiment_key’: ‘positive’, ‘positive_probs’: 0.9866, ‘negative_probs’: 0.0134}
{‘text’: ‘《黑色四叶草》是部不错的番’, ‘sentiment_label’: 1, ‘sentiment_key’: ‘positive’, ‘positive_probs’: 0.9401, ‘negative_probs’: 0.0599}
其中:
1.sentiment_key 代表分类结果,postive是 积极 ,negative是 消极 。
2.sentiment_label 是分类结果标签,1代表 积极 ,0代表 消极 。
3. positive_probs 是积极分类的置信度,0.9866即模型判断98.66%的可能性是正面。
4. negative_probs 与 positive_probs 相对,是消极分类的置信度。
3.结果分析
这么看,你会发现其实在有明显的积极消极词汇面前,这个模型的分类效果还是不错的。那在特殊的例子面前效果又如何呢?我们去微博随便取一条试一下,比如银教授的段子:
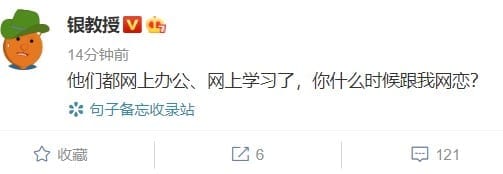
分类结果:
{‘text’: ‘他们都网上办公、网上学习了,你什么时候跟我网恋?’, ‘sentiment_label’: 0, ‘sentiment_key’: ‘negative’, ‘positive_probs’: 0.0507, ‘negative_probs’: 0.9493}
竟然意外的分对了。虽然是句段子,但是明显有对方不跟自己网恋的消极态度。再试试有潜在含义的句子:
{‘text’: ‘不想说什么了,听首歌吧。’, ‘sentiment_label’: 0, ‘sentiment_key’: ‘negative’, ‘positive_probs’: 0.0321, ‘negative_probs’: 0.9679}
{‘text’: ‘我忘了世界还有一种人火星人,你从那来的吧。’, ‘sentiment_label’: 1, ‘sentiment_key’: ‘positive’, ‘positive_probs’: 0.7261, ‘negative_probs’: 0.2739}
这里第一句分对了,第二句没分对。确实,第二句太隐晦了,机器可能分不出来。不过,置信度并不高,如果真的需要应用这个模型,可以通过置信度过滤掉一些分类。
总的而言,这个模型效果还是不错的,在网上那么多情感分类开源的模型中,百度的这个应该可以打80分左右。
而且,它支持你自己做一些微调(Fine-tune),也就是能够使用自定义的训练集调整模型到你需要的样子,详见github:
https://github.com/PaddlePaddle/models/tree/develop/PaddleNLP/sentiment_classification
我们的文章到此就结束啦,如果你希望我们今天的Python 教程,请持续关注我们,如果对你有帮助,麻烦在下面点一个赞/在看哦![]() 有任何问题都可以在下方留言区留言,我们都会耐心解答的!
有任何问题都可以在下方留言区留言,我们都会耐心解答的!
Python实用宝典 (pythondict.com)
不只是一个宝典
欢迎关注公众号:Python实用宝典

评论(3)
使用后模型效果确实不错~
请问如何将结果输出到csv文档或者excel中呢?
for循环分类结果,将你需要的数据写入到csv或excel中,可以参见这个
https://pythondict.com/python-data-analyze/python-tablib-export-data/ 文章,
也可以自己查阅资料完成。