

Python推特机器人分类(2017 Kaggle NYU) 准确率94%源代码下载
[download_code]
这是一个python机器学习比赛的源代码。
来自于kaggle的NYU Tandon Spring 2017 Machine Learning Competition: Twitter Bot classification赛事,原网站访问此处。
准确率:
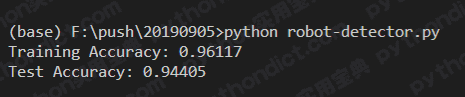

若参加比赛可排27名:

Python推特机器人分类(2017 Kaggle NYU) 准确率94%源代码下载
[download_code]
这是一个python机器学习比赛的源代码。
来自于kaggle的NYU Tandon Spring 2017 Machine Learning Competition: Twitter Bot classification赛事,原网站访问此处。
准确率:
若参加比赛可排27名:
[download_code]
译者注:
本项目face_recognition是一个强大、简单、易上手的人脸识别开源项目,并且配备了完整的开发文档和应用案例,特别是兼容树莓派系统。
为了便于中国开发者研究学习人脸识别、贡献代码,我将本项目README文件翻译成中文。
向本项目的所有贡献者致敬。
英译汉:同济大学开源软件协会 子豪兄Tommy
Translator’s note:
face_recognition is a powerful, simple and easy-to-use face recognition open source project with complete development documents and application cases, especially it is compatible with Raspberry Pi.
In order to facilitate Chinese software developers to learn, make progress in face recognition development and source code contributions, I translated README file into simplified Chinese.
Salute to all contributors to this project.
Translator: Tommy in Tongji Univerisity Opensource Association 子豪兄Tommy
本项目是世界上最简洁的人脸识别库,你可以使用Python和命令行工具提取、识别、操作人脸。
本项目的人脸识别是基于业内领先的C++开源库 dlib中的深度学习模型,用Labeled Faces in the Wild人脸数据集进行测试,有高达99.38%的准确率。但对小孩和亚洲人脸的识别准确率尚待提升。
Labeled Faces in the Wild是美国麻省大学安姆斯特分校(University of Massachusetts Amherst)制作的人脸数据集,该数据集包含了从网络收集的13,000多张面部图像。
本项目提供了简易的face_recognition命令行工具,你可以用它处理整个文件夹里的图片。
定位图片中的所有人脸:

import face_recognition
image = face_recognition.load_image_file("your_file.jpg")
face_locations = face_recognition.face_locations(image)
识别人脸关键点,包括眼睛、鼻子、嘴和下巴。

import face_recognition
image = face_recognition.load_image_file("your_file.jpg")
face_landmarks_list = face_recognition.face_landmarks(image)
识别人脸关键点在很多领域都有用处,但同样你也可以把这个功能玩坏,比如本项目的 digital make-up自动化妆案例(就像美图秀秀一样)。


import face_recognition
known_image = face_recognition.load_image_file("biden.jpg")
unknown_image = face_recognition.load_image_file("unknown.jpg")
biden_encoding = face_recognition.face_encodings(known_image)[0]
unknown_encoding = face_recognition.face_encodings(unknown_image)[0]
results = face_recognition.compare_faces([biden_encoding], unknown_encoding)
你也可以配合其它的Python库(比如opencv)实现实时人脸检测:

看这个案例 实时人脸检测 。
First, make sure you have dlib already installed with Python bindings:
第一步,安装dlib和相关Python依赖:
Then, install this module from pypi using pip3 (or pip2 for Python 2):
pip3 install face_recognition
如果你遇到了幺蛾子,可以用Ubuntu虚拟机安装本项目,看下面这个教程。 如何使用Adam Geitgey大神提供的Ubuntu虚拟机镜像文件安装配置虚拟机,本项目已经包含在镜像中.
修改你的pip镜像源为清华镜像,然后使用pip install face_recognition,可以自动帮你安装各种依赖,包括dlib。只是在安装dlib的时候可能会出问题,因为dlib需要编译,出现的问题一般是gcc或者g++版本的问题,所以在pip install face_recognition之前,可以通过在命令行键入
export CC=/usr/local/bin/gcc
export CXX=/usr/local/bin/g++
来指定你gcc和g++对应的位置,(这两句话会临时修改当前终端的环境变量/usr/local/bin/gcc对应你自己gcc或者g++所在目录)。
虽然本项目官方并不支持Windows,但一些大神们摸索出了在Windows上运行本项目的方法:
当你安装好了本项目,你可以使用两种命令行工具:
face_recognition – 在单张图片或一个图片文件夹中认出是谁的脸。face_detection – 在单张图片或一个图片文件夹中定位人脸位置。face_recognition 命令行工具face_recognition命令行工具可以在单张图片或一个图片文件夹中认出是谁的脸。
首先,你得有一个你已经知道名字的人脸图片文件夹,一个人一张图,图片的文件名即为对应的人的名字:

然后,你需要第二个图片文件夹,文件夹里面是你希望识别的图片:

然后,你在命令行中切换到这两个文件夹所在路径,然后使用face_recognition命令行,传入这两个图片文件夹,然后就会输出未知图片中人的名字:
$ face_recognition ./pictures_of_people_i_know/ ./unknown_pictures/
/unknown_pictures/unknown.jpg,Barack Obama
/face_recognition_test/unknown_pictures/unknown.jpg,unknown_person
输出结果的每一行对应着图片中的一张脸,图片名字和对应人脸识别结果用逗号分开。
如果结果输出了unknown_person,那么代表这张脸没有对应上已知人脸图片文件夹中的任何一个人。
face_detection 命令行工具face_detection命令行工具可以在单张图片或一个图片文件夹中定位人脸位置(输出像素点坐标)。
在命令行中使用face_detection,传入一个图片文件夹或单张图片文件来进行人脸位置检测:
$ face_detection ./folder_with_pictures/
examples/image1.jpg,65,215,169,112
examples/image2.jpg,62,394,211,244
examples/image2.jpg,95,941,244,792
输出结果的每一行都对应图片中的一张脸,输出坐标代表着这张脸的上、右、下、左像素点坐标。
如果一张脸识别出不止一个结果,那么这意味着他和其他人长的太像了(本项目对于小孩和亚洲人的人脸识别准确率有待提升)。你可以把容错率调低一些,使识别结果更加严格。
通过传入参数 --tolerance 来实现这个功能,默认的容错率是0.6,容错率越低,识别越严格准确。
$ face_recognition --tolerance 0.54 ./pictures_of_people_i_know/ ./unknown_pictures/
/unknown_pictures/unknown.jpg,Barack Obama
/face_recognition_test/unknown_pictures/unknown.jpg,unknown_person
如果你想看人脸匹配的具体数值,可以传入参数 --show-distance true:
$ face_recognition --show-distance true ./pictures_of_people_i_know/ ./unknown_pictures/
/unknown_pictures/unknown.jpg,Barack Obama,0.378542298956785
/face_recognition_test/unknown_pictures/unknown.jpg,unknown_person,None
如果你并不在乎图片的文件名,只想知道文件夹中的图片里有谁,可以用这个管道命令:
$ face_recognition ./pictures_of_people_i_know/ ./unknown_pictures/ | cut -d ',' -f2
Barack Obama
unknown_person
如果你的CPU是多核的,你可以通过并行运算加速人脸识别。例如,如果你的CPU有四个核心,那么你可以通过并行运算提升大概四倍的运算速度。
如果你使用Python3.4或更新的版本,可以传入 --cpus <number_of_cpu_cores_to_use> 参数:
$ face_recognition --cpus 4 ./pictures_of_people_i_know/ ./unknown_pictures/
你可以传入 --cpus -1参数来调用cpu的所有核心。
子豪兄批注:树莓派3B有4个CPU核心,传入多核参数可以显著提升图片识别的速度(亲测)。
face_recognition在Python中,你可以导入face_recognition模块,调用我们提供的丰富的API接口,用几行代码就可以轻松玩转各种人脸识别功能!
API 接口文档: https://face-recognition.readthedocs.io
import face_recognition
image = face_recognition.load_image_file("my_picture.jpg")
face_locations = face_recognition.face_locations(image)
# face_locations is now an array listing the co-ordinates of each face!
你也可以使用深度学习模型达到更加精准的人脸定位。
注意:这种方法需要GPU加速(通过英伟达显卡的CUDA库驱动),你在编译安装dlib的时候也需要开启CUDA支持。
import face_recognition
image = face_recognition.load_image_file("my_picture.jpg")
face_locations = face_recognition.face_locations(image, model="cnn")
# face_locations is now an array listing the co-ordinates of each face!
如果你有很多图片需要识别,同时又有GPU,那么你可以参考这个例子:案例:使用卷积神经网络深度学习模型批量识别图片中的人脸.
import face_recognition
image = face_recognition.load_image_file("my_picture.jpg")
face_landmarks_list = face_recognition.face_landmarks(image)
# face_landmarks_list is now an array with the locations of each facial feature in each face.
# face_landmarks_list[0]['left_eye'] would be the location and outline of the first person's left eye.
看这个案例 案例:提取奥巴马和拜登的面部关键点
import face_recognition
picture_of_me = face_recognition.load_image_file("me.jpg")
my_face_encoding = face_recognition.face_encodings(picture_of_me)[0]
# my_face_encoding now contains a universal 'encoding' of my facial features that can be compared to any other picture of a face!
unknown_picture = face_recognition.load_image_file("unknown.jpg")
unknown_face_encoding = face_recognition.face_encodings(unknown_picture)[0]
# Now we can see the two face encodings are of the same person with `compare_faces`!
results = face_recognition.compare_faces([my_face_encoding], unknown_face_encoding)
if results[0] == True:
print("It's a picture of me!")
else:
print("It's not a picture of me!")
看这个案例 案例:是奥巴马还是拜登?
所有案例都在这个链接中 也就是examples文件夹.
face_recognition的文章和教程如果你想更深入了解人脸识别这个黑箱的原理 读这篇文章。
子豪兄批注:一定要看这篇文章,讲的既有趣又有料。
本项目是基于C++库dlib的,所以把本项目部署在Heroku或者AWS的云端服务器上是很明智的。
为了简化这个过程,有一个Dockerfile案例,教你怎么把face_recognition开发的app封装成Docker 容器文件,你可以把它部署在所以支持Docker镜像文件的云服务上。
如果出了问题,请在Github提交Issue之前查看 常见错误 。
dlib库,提供了响应的人脸关键点检测和人脸编码相关的模型,你可以查看 blog post这个网页获取更多有关ResNet的信息。[download_code]
此代码基于pytorch。它已经在Ubuntu 14.04 LTS上进行了测试。
依赖关系:
CUDA后端:
下载VGG-19:
sh models/download_models.sh
编译cuda_utils.cu(makefile为您的机器调整PREFIX以及NVCC_PREFIX):
make clean && make
使用提供的脚本生成所有(examples/)结果,只需在Matlab或Octave运行
run('gen_laplacian/gen_laplacian.m')
然后在Python中:
python gen_all.py
最终输出在examples/final_results/。
examples/:examples/input/in<id>.png,examples/style/tar<id>.png和examples/segmentation/in<id>.png,examples/segmentation/tar<id>.png;gen_laplacian/gen_laplacian.mMatlab 计算消光拉普拉斯矩阵。输出矩阵将具有以下文件名形式:gen_laplacian/Input_Laplacian_3x3_1e-7_CSR<id>.mat;注意:请确保内容图像分辨率与Matlab中的Matting Laplacian计算和Torch中的样式传输一致,否则结果将不正确。
th neuralstyle_seg.lua -content_image <input> -style_image <style> -content_seg <inputMask> -style_seg <styleMask> -index <id> -serial <intermediate_folder>
th deepmatting_seg.lua -content_image <input> -style_image <style> -content_seg <inputMask> -style_seg <styleMask> -index <id> -init_image <intermediate_folder/out<id>_t_1000.png> -serial <final_folder> -f_radius 15 -f_edge 0.01
可以传递-backend cudnn和-cudnn_autotune两者Lua脚本(步骤3和4),以潜在地提高速度和内存使用情况。libcudnn.so必须在你的LD_LIBRARY_PATH。这需要cudnn.torch。
注意:在论文中,我们使用从DilatedNet修改的自动场景分割算法生成所有比较结果。手动分割可以实现更多样化的任务,因此我们提供了掩模examples/segmentation/。
我们使用的蒙版颜色(您可以ExtractMask在两个*.lua文件中添加更多颜色):
| 颜色变量 | RGB值 | 十六进制值 |
|---|---|---|
blue |
0 0 255 |
0000ff |
green |
0 255 0 |
00ff00 |
black |
0 0 0 |
000000 |
white |
255 255 255 |
ffffff |
red |
255 0 0 |
ff0000 |
yellow |
255 255 0 |
ffff00 |
grey |
128 128 128 |
808080 |
lightblue |
0 255 255 |
00ffff |
purple |
255 0 255 |
ff00ff |
以下是算法的一些结果(从左到右分别是输入,样式和输出):












[download_code]
这是一个python机器学习项目。
FastText模型是一个用于文本分类的库。[Github拥有11786 星星 ]。
感谢Facebook的研究。
此外还有一篇应用项目,Muse:
基于FastText的多语种无监督或监督词嵌入项目。Github上有695颗星星。















