
CNTK
| 聊天 | Windows生成状态 | Linux构建状态 |
|---|---|---|
 |
Microsoft认知工具包(https://cntk.ai)是一个统一的深度学习工具包,它通过有向图将神经网络描述为一系列计算步骤。在这个有向图中,叶节点表示输入值或网络参数,而其他节点表示对其输入的矩阵运算。CNTK允许用户轻松地实现和组合流行的模型类型,例如前馈DNN、卷积网络(CNN)和递归网络(RNNs/LSTM)。它通过跨多个GPU和服务器的自动区分和并行化实现随机梯度下降(SGD,误差反向传播)学习。自2015年4月以来,CNTK一直在开源许可证下提供。我们希望社区能够利用CNTK的优势,通过开放源码工作代码的交流,更快地分享想法
安装
- Setup CNTK
- Windows(Python-only/Script-driven/Manual)
- Linux(Python-only/Script-driven/Manual/Docker)
- CNTK backend for Keras
- Setup CNTK development environment
- Windows(Script-driven/Manual)
- Linux(Manual)
安装夜间软件包
如果您更喜欢使用MASTER的最新CNTK位,请使用CNTK夜间软件包之一:
学习CNTK
您可以通过以下资源了解更多关于使用和贡献CNTK的信息:
- General documentation
- Python API documentation
- Evaluation documentation (C++, C#/.NET, Python, Java)
- Manual
- Tutorials
- Examples
- Pretrained models
- Blog
- Presentations
- License
更多信息
免责声明
亲爱的社区:
随着我们对ONNX和ONNX Runtime的持续贡献,我们已经使AI框架生态系统内的互操作变得更容易,并为传统ML模型和深度神经网络访问高性能的跨平台推理功能。在过去的几年里,我们有幸开发了这样的关键开源机器学习项目,包括Microsoft Cognitive Toolkit,它使其用户能够利用整个行业在大规模深度学习方面的进步
今天的2.7版本将是CNTK的最后一个主要版本。我们可能会有一些后续的小版本来修复错误,但这些版本将根据具体情况进行评估。此版本之后没有开发新功能的计划
CNTK 2.7版本完全支持ONNX 1.4.1,我们鼓励那些寻求将其CNTK模型运行化的用户利用ONNX和ONNX Runtime。展望未来,用户可以通过众多支持ONNX的框架继续利用不断发展的ONNX创新。例如,用户可以从PyTorch本机导出ONNX模型,或使用TensorFlow-ONNX转换器将TensorFlow模型转换为ONNX
我们非常感谢自CNTK最初开放源码发布以来多年来我们从贡献者和用户那里得到的所有支持。CNTK使微软团队和外部用户都能够在各种深度学习应用程序中执行复杂而大规模的工作负载,例如该框架的创始人微软语音研究人员在语音识别方面取得的历史性突破
随着ONNX越来越多地被用于为Bing和Office等微软产品提供服务的模型,我们致力于将研究创新与生产的严格要求相结合,以推动生态系统向前发展
最重要的是,我们的目标是使跨软件和硬件堆栈的深度学习创新尽可能开放和可访问。我们将努力将CNTK的现有优势和最新的最新研究成果应用到其他开源项目中,以真正扩大此类技术的应用范围。
怀着感激之情,
–CNTK团队
Microsoft开放源代码行为准则
本项目采用了Microsoft Open Source Code of Conduct有关更多信息,请参阅Code of Conduct FAQ或联系方式opencode@microsoft.com如有任何其他问题或评论
新闻
您可以在以下网站上找到更多新闻the official project feed
2019-03-29CNTK 2.7.0
此版本的亮点
- 已迁移到适用于Windows和Linux的CUDA 10
- 在ONNX导出中支持高级RNN环路
- 以ONNX格式导出大于2 GB的型号
- 在大脑脚本训练动作中支持FP16
支持CUDA 10的CNTK
CNTK现在支持CUDA 10。这需要更新到Visual Studio 2017 v15.9 for Windows的构建环境
要在Windows上设置生成和运行时环境,请执行以下操作:
- 安装Visual Studio 2017注意:对于CUDA 10及更高版本,不再需要安装和运行特定的VC Tools版本14.11
- 安装Nvidia CUDA 10
- 从PowerShell运行:DevInstall.ps1
- 启动Visual Studio 2017并打开CNTK.sln
要使用docker在Linux上设置构建和运行时环境,请使用Dockerfiles构建Unbuntu 16.04坞站映像here对于其他Linux系统,请参考Dockerfile来设置CNTK的依赖库
在ONNX导出中支持高级RNN环路
带有递归循环的CNTK模型可以通过扫描操作导出到ONNX模型
以ONNX格式导出大于2 GB的型号
要以ONNX格式导出大于2 GB的模型,可使用cntk.Function API:Save(Self,FileName,Format=ModelFormat.CNTKv2,USE_EXTERNAL_FILES_TO_STORE_PARAMETERS=FALSE),并将‘Format’设置为ModelFormat.ONNX,将Use_External_Files_to_Store_Parameters设置为True。在这种情况下,模型参数保存在外部文件中。使用onnxrun进行模型评估时,导出的模型应与外部参数文件一起使用
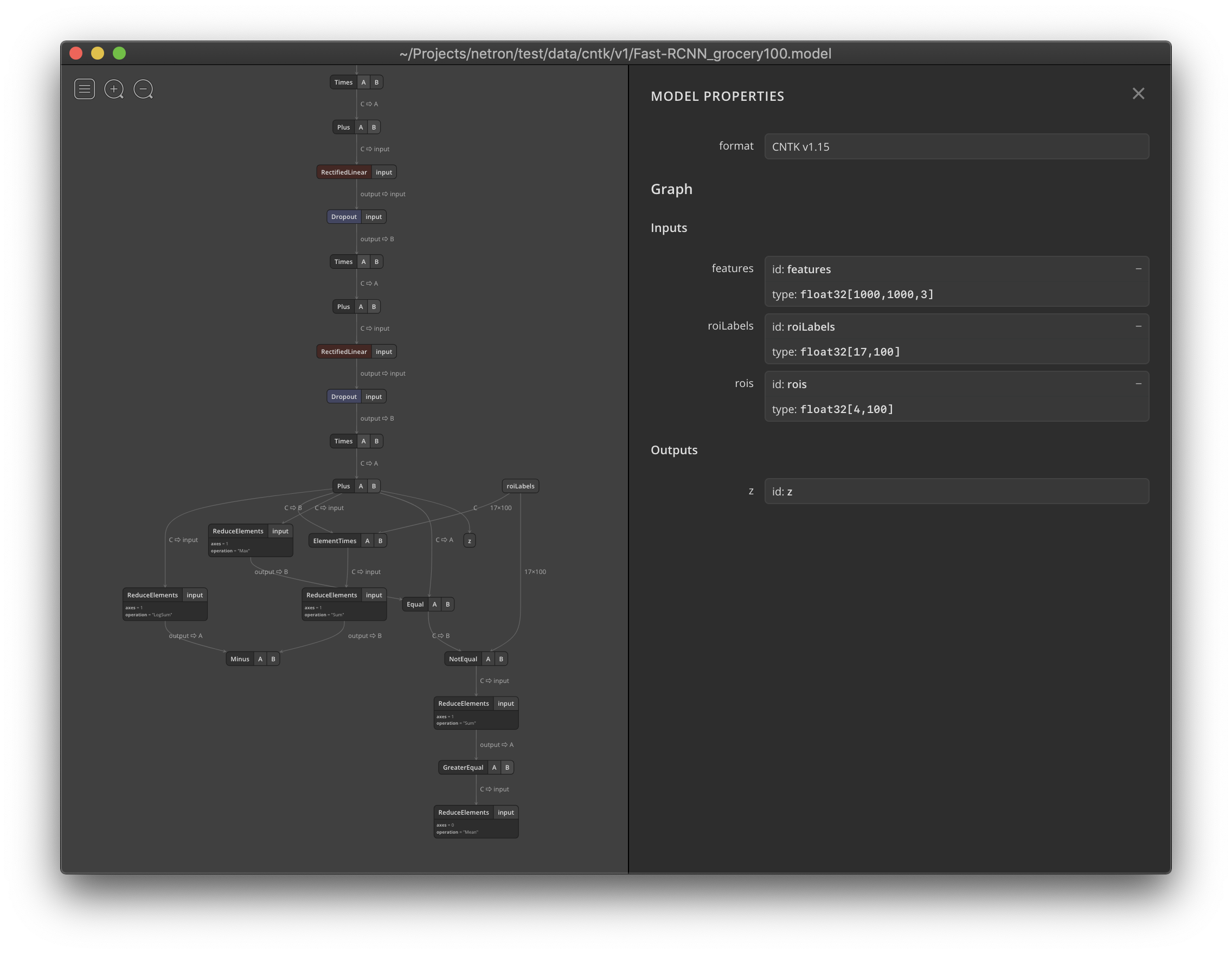
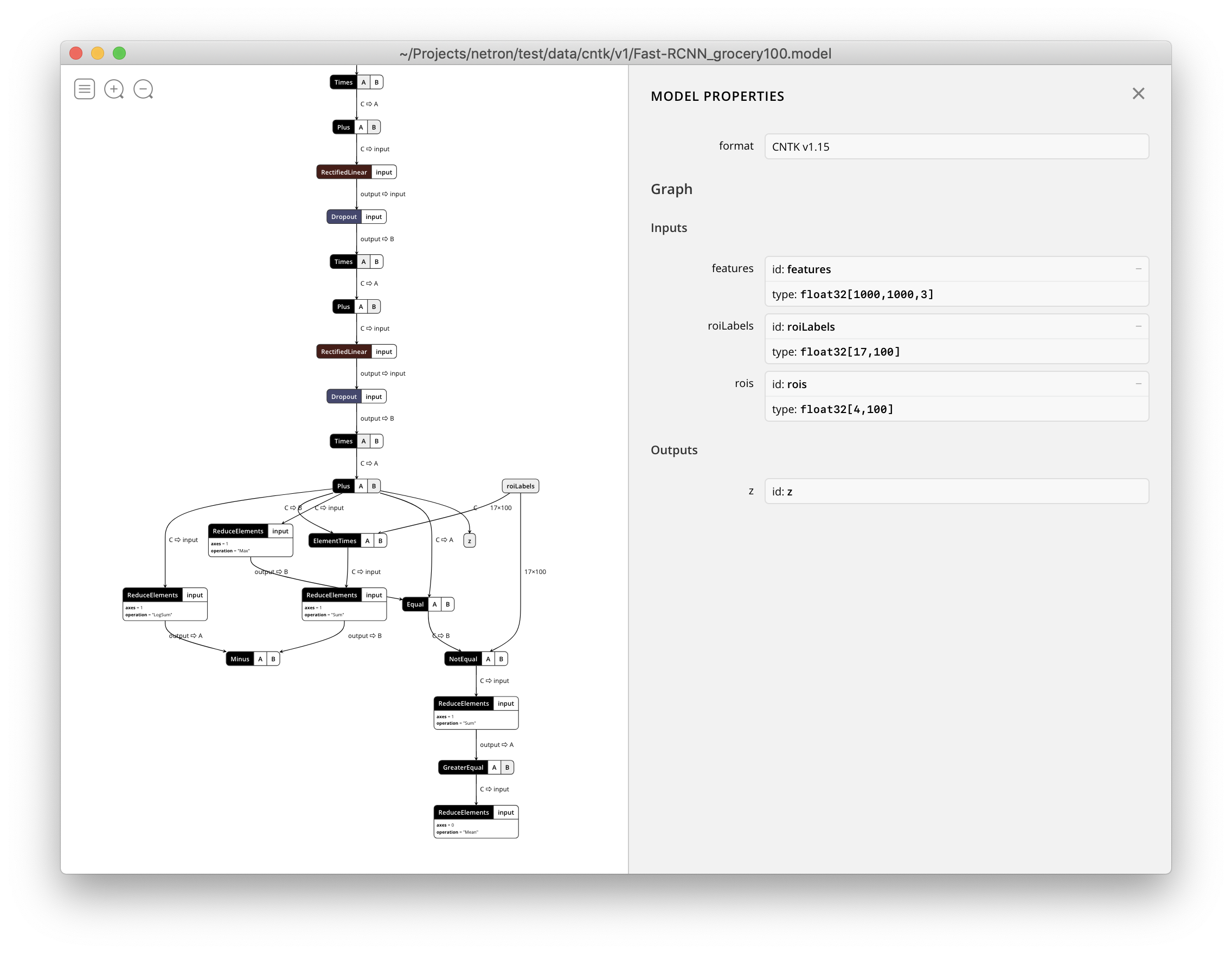
2018/11/26
Netron现在支持可视化CNTK v1和CNTK v2.model文件
项目变更日志
2018-09-17CNTK 2.6.0
高效群卷积
对CNTK中的分组卷积实现进行了更新。更新后的实现不再创建分组卷积的子图(使用切片和拼接),而是直接使用cuDNN7和MKL2017API。这在性能和型号大小方面都改善了体验
例如,对于具有以下属性的单个组卷积OP:
- 输入张量(C,H,W)=(32,128,128)
- 输出通道数=32(通道倍增为1)
- 组=32(深度卷积)
- 内核大小=(5,5)
此单个节点的比较编号如下:
| 第一个标题 | GPU EXEC。时间(单位为毫秒,平均运行1000次) | CPU EXEC。时间(单位为毫秒,平均运行1000次) | 模型大小(KB,CNTK格式) |
|---|---|---|---|
| 旧实施 | 9.349 | 41.921 | 38 |
| 新实施 | 6.581 | 9.963 | 5个 |
| 加速/节约近似值 | 30%近似 | 65-75%近似 | 87% |
顺序卷积
更新了CNTK中序列卷积的实现。更新后的实现创建单独的顺序卷积层。与规则卷积层不同,该操作还在动态轴(序列)上进行卷积,并将过滤_Shape[0]应用于该轴。更新后的实现支持更广泛的情况,例如序列轴的跨度>1
例如,对一批单通道黑白图像进行顺序卷积。这些图像的高度相同,固定为640,但每个图像的宽度都是可变的。然后,宽度由顺序轴表示。启用填充,宽度和高度的步长均为2
深度到空间和空间到深度
有一个突破性的变化,那就是深度到空间和空间到深度操作员。这些已经更新,以符合ONNX规范,特别是深度维度在空间维度中作为块放置的排列方式,反之亦然。请参考这两个操作的更新文档示例以查看更改
谭恩美和阿坦
添加了对三角运算的支持Tan和Atan
ELU
添加了对以下各项的支持alphaELU操作中的属性
卷积
更新的自动填充算法Convolution在不影响最终卷积输出值的情况下,在CPU上尽最大努力产生对称填充。此更新增加了MKL API可以覆盖的案例范围,并提高了性能,例如ResNet50
默认参数顺序
有一个突破性的变化,那就是论据属性。默认行为已更新,以Python顺序而不是C++顺序返回参数。这样,它将以与输入到操作中相同的顺序返回参数。如果您仍然希望以C++顺序获取参数,只需覆盖全局选项即可。此更改应仅影响以下操作:Times、TransposeTimes和Gemm(内部)
错误修复
- 已更新卷积图层的文档,以包括组参数和膨胀参数
- 添加了改进的分组卷积输入验证
- 已更新
LogSoftMax要使用更稳定的数值实现,请执行以下操作 - 修复了聚集OP的错误渐变值
- 添加了对python克隆替换中的“None”节点的验证
- 添加了卷积中填充通道轴的验证
- 添加了CNTK本机默认lotusIR记录器,以修复加载某些ONNX型号时出现的“尝试使用DefaultLogger”错误
- 添加了ONNX TypeStrToProtoMap的正确初始化
- 更新了python doctest,以处理较新版本号(Version>=1.14)的不同打印格式
- 当内核中心位于填充的输入单元上时,固定池(CPU)可生成正确的输出值
ONNX
更新
- 更新了CNTK的ONNX导入/导出以使用ONNX 1.2规范
- 对如何在导出和导入中处理批次和序列轴进行了重大更新。因此,可以准确地处理复杂场景和边缘情况
- 更新了CNTK的ONNX
BatchNormalizationOP导出/导入到最新规范 - 将模型域添加到ONNX模型导出
- 改进了ONNX型号导入和导出期间的错误报告
- 已更新
DepthToSpace和SpaceToDepth操作以匹配ONNX关于如何将深度维度放置为挡路维度的排列规范 - 添加了对导出的支持
alpha中的属性ELUONNX操作 - 大修是为了
Convolution和Pooling导出。与以前不同的是,这些操作不会导出显式Pad在任何情况下都可操作 - 大修是为了
ConvolutionTranspose导出和导入。属性,如output_shape,output_padding,以及pads完全支持 - 添加了对CNTK的支持
StopGradient作为一个禁区 - 添加了对TOPK操作的ONNX支持
- 添加了对序列操作的ONNX支持:Sequence.Slice、Sequence.first、Sequence.last、Sequence.duce_sum、Sequence.Reduce_max、Sequence.softmax。对于这些操作,不需要扩展ONNX规范。CNTK ONNX Exporter仅为这些序列操作构建计算等效图
- 添加了对Softmax操作的完全支持
- 使CNTK广播运营与ONNX规范兼容
- 在CNTK ONNX导出器中处理TO_BATCH、TO_SEQUENCE、UNPACK_BATCH、Sequence.Unpack工序
- 用于导出ONNX测试用例以供其他工具箱运行和验证的ONNX测试
- 固定的
Hardmax/Softmax/LogSoftmax导入/导出 - 添加了对以下各项的支持
SelectOP导出 - 添加了对多个三角运算的导入/导出支持
- 更新了对ONNX的CNTK支持
MatMul操作 - 更新了对ONNX的CNTK支持
Gemm操作 - 更新了CNTK的ONNX
MeanVarianceNormalizationOP导出/导入到最新规范 - 更新了CNTK的ONNX
LayerNormalizationOP导出/导入到最新规范 - 更新了CNTK的ONNX
PReluOP导出/导入到最新规范 - 更新了CNTK的ONNX
GatherOP导出/导入到最新规范 - 更新了CNTK的ONNX
ImageScalerOP导出/导入到最新规范 - 更新了CNTK的ONNX
Reduce操作导出/导入到最新规范 - 更新了CNTK的ONNX
FlattenOP导出/导入到最新规范 - 添加了对ONNX的CNTK支持
Unsqueeze操作
错误或次要修复:
- 更新了LRN OP以匹配ONNX 1.2规范,其中
size属性具有直径的语义,而不是半径的语义。添加了LRN内核大小大于通道大小时的验证 - 已更新
Min/Max导入实现以处理各种输入 - 修复了在现有ONNX模型文件上重新保存时可能出现的文件损坏
网络支持
Cntk.Core.Managed库已正式转换为.Net标准,并在Windows和Linux上支持.Net Core和.Net Framework应用程序。从这个版本开始,.NET开发人员应该能够使用新的.Net SDK样式项目文件(包管理格式设置为PackageReference)恢复CNTK Nuget包
下面的C#代码现在可以在Windows和Linux上运行:
例如,只需在.Net Core应用程序的.csproj文件中添加ItemGroup子句就足够了:>netcoreapp2.1>x64>
错误或次要修复:
- 修复了Linux上C#string和char到本机wstring和wchar UTF转换的问题
- 修复了代码库中的多字节和宽字符转换
- 修复了针对.Net标准打包的Nuget包机制
- 修复了C#API中值类中的内存泄漏问题,其中在对象销毁时不调用Dispose
杂项
2018-04-16CNTK 2.5.1
使用捆绑包中包含的第三方库(Python轮包)重新打包CNTK 2.5
2018-03-15CNTK 2.5
将探查器详细信息输出格式更改为chrome://tracing
启用逐节点计时。工作示例here
- 启用探查器时,按节点计时会在探查器详细信息中创建项目
- Python中的用法:
中的Profiler详细信息视图示例chrome://tracing

使用MKL提高CPU推理性能
- 加速用于Float32的英特尔CPU推理中的一些常见张量运算,特别是对于完全连接的网络
- 可以通过以下方式打开/关闭
cntk.cntk_py.enable_cpueval_optimization()/cntk.cntk_py.disable_cpueval_optimization()
1BitSGD并入CNTK
1BitSGD源代码现已随CNTK许可证(MIT许可证)一起在以下位置提供Source/1BitSGD/1bitsgd生成目标已合并到现有GPU目标中
新的损耗函数:分层Softmax
- 感谢@耀诚记的贡献!
具有多个学习者的分布式培训
- Trader现在接受多参数学习者进行分布式培训。通过这种改变,不同的学习者可以在单个培训会话中学习不同的网络参数。这也促进了Gans的分布式培训。有关更多信息,请参阅Basic_GAN_Distributed.py以及cntk.learners.distributed_multi_learner_test.py
操作员
- 已添加
MeanVarianceNormalization操作员
错误修复
- 修复了教程201b中的收敛问题
- 固定的合用/解合,以支持序列的自由维度
- 修复了中的崩溃
CNTKBinaryFormat跨越扫描边界时的反序列化程序 - 修正了RNN阶跃函数在标量广播中的形状推断错误
- 修复了在以下情况下的构建错误
mpi=no - 通过提高打包阈值和暴露V2中的旋钮来提高分布式训练聚合速度
- 修复了MKL布局中的内存泄漏
- 修复了中的错误
cntk.convertAPI Inmisc.converter.py,这样可以防止将复杂的网络
ONNX
- 更新
- CNTK导出的ONNX型号现在
ONNX.checker合规 - 添加了对CNTK的ONNX支持
OptimizedRNNStack操作员(仅限LSTM) - 添加了对LSTM和GRU运算符的支持
- 添加了对实验性ONNX操作的支持
MeanVarianceNormalization - 添加了对实验性ONNX操作的支持
Identity - 添加了对导出CNTK的支持
LayerNormalization使用ONNX的图层MeanVarianceNormalization操作
- CNTK导出的ONNX型号现在
- 错误或次要修复:
- 轴属性在CNTK的ONNX中是可选的
Concat操作员 - 修复标量ONNX广播中的错误
- 修复ONNX ConvTranspose运算符中的错误
- 修复向后兼容性错误
LeakyReLu(参数“alpha”恢复为双精度类型)
- 轴属性在CNTK的ONNX中是可选的
杂项
- 添加了新的接口
find_by_uid()在……下面cntk.logging.graph
2018-02-28CNTK支持夜间构建
如果您更喜欢使用MASTER提供的最新CNTK位,请使用CNTK夜间软件包之一
或者,您也可以单击相应的构建标记以登录到夜间构建页面
2018-01-31CNTK 2.4
亮点:
- 已移至CUDA9、cuDNN 7和Visual Studio 2017
- 删除了Python 3.4支持
- 添加了Volta GPU和FP16支持
- 更好的ONNX支持
- CPU性能改进
- 更多运营
运营部
top_k操作:在正向传递中,它计算沿指定轴的顶部(最大)k值和相应的索引。在后向传递中,梯度分散到顶部k个元素(不在顶部k中的元素获得零梯度)gather操作现在支持轴参数squeeze和expand_dims轻松移除和添加单一轴的操作zeros_like和ones_like运营部。在许多情况下,您可以仅仅依靠CNTK正确地广播一个简单的0或1,但有时您需要实际的张量depth_to_space:将输入张量中的元素从深度维度重新排列到空间块中。此操作的典型用法是实现某些图像超分辨率模型的亚像素卷积space_to_depth:将输入张量中的元素从空间维度重新排列到深度维度。它在很大程度上与DepthToSpace相反sum操作:创建计算输入张量的元素求和的新函数实例softsign操作:创建计算输入张量的元素软符号的新函数实例asinh操作:创建一个新的函数实例,该实例计算输入张量的逐个元素的asinhlog_softmax操作:创建计算输入张量的logsoftmax规格化值的新函数实例hard_sigmoid操作:创建计算输入张量的hard_sigmoid归一化值的新函数实例element_and,element_not,element_or,element_xor基于元素的逻辑运算reduce_l1操作:沿提供的轴计算输入张量元素的L1范数reduce_l2操作:沿提供的轴计算输入张量元素的L2范数reduce_sum_square操作:沿提供的轴计算输入张量元素的平方和image_scaler操作:通过缩放图像的各个值来更改图像
ONNX
- CNTK中对ONNX支持进行了多项改进
- 更新
- 更新的ONNX
Reshape要处理的操作InferredDimension - 添加
producer_name和producer_versionONNX模型的字段 - 在两个都不是的情况下处理案件
auto_pad也不是pads属性在ONNX中指定Conv操作
- 更新的ONNX
- 错误修复
- 修复了ONNX中的错误
PoolingOP序列化 - 修复错误以创建ONNX
InputVariable只有一个批次轴 - 对ONNX实施的错误修复和更新
Transpose操作以匹配更新的规范 - 对ONNX实施的错误修复和更新
Conv,ConvTranspose,以及Pooling操作以匹配更新的规范
- 修复了ONNX中的错误
操作员
- 群卷积
- 修复了组卷积中的错误。CNTK的输出
ConvolutionOP将针对>1的组进行更改。预计在下一版本中将对组卷积进行更优化的实施 - 更好的分组卷积错误报告
Convolution图层
- 修复了组卷积中的错误。CNTK的输出
卤化物二元卷积
- CNTK版本现在可以使用可选Halide要构建的库
Cntk.BinaryConvolution.so/dll库,该库可以与netopt模块。该库包含优化的二进制卷积操作符,其性能优于基于Python的二进制卷积操作符。要在内部版本中启用Halide,请下载Halide release并将其设置为HALIDE_PATH开始构建之前的环境变量。在Linux中,您可以使用./configure --with-halide[=directory]来启用它。有关如何使用此功能的详细信息,请参阅How_to_use_network_optimization
有关更多信息,请参阅Release Notes从CNTK Releases page