

JsonPath是一种简单的方法来提取给定JSON文档的部分内容。 JsonPath有许多编程语言,如Javascript,Python和PHP,Java。JsonPath提供的json解析非常强大,它提供了类似正则表达式的语法,基本上可以满足所有你想要获得的json内容。
本文介绍了Json相关的基础知识,引入XML和Jsonpath的对比,说明Jsonpath出现的必要性,并在文末附上了 Jsonpath 实战教程。
1.关于JSON
JSON是一个标记符序列。这套标记符包括:构造字符、字符串、数字和三个字面值。
构造字符
JSON包括六个构造字符,分别是:左方括号、右方括号、左大括号、右大括号、冒号与逗号。
JSON值
JSON值可以是对象、数组、数字、字符串或者三个字面值(false、true、null),并且字面值必须是小写英文字母。
对象
对象是由花括号括起来,逗号分割的成员构成,成员是字符串键和上面所说的JSON值构成,例如:
{"name":"jack","age":18,"address":{"country"}}
数组
数组是由方括号括起来的一组数值构成,例如:
[1,2,32,3,6,5,5]
字符串与数字想必就不用我过多叙述吧。
下面我就举例一些合法的JSON格式的数据:
{"a":1,"b":[1.2.3]}
[1,2,"3",{"a":4}]
3.14
"json_data"
2.为什么要使用JSON
JSON是一种轻量级的数据交互格式,它使得人们很容易的进行阅读和编写。同时也方便机器进行解析和生成。适用于进行数据交互的场景,比如网站前台与后台之间的数据交互。
JSON的使用方法
json.loads()
把JSON格式字符串解码转成Python对象,从JSON到Python类型转换表如下:
| JSON | Python |
|---|---|
| object | dict |
| array | list |
| string | str |
| number(int) | int |
| number(real) | float |
| true | True |
| false | False |
| null | None |
将数组转成列表对象
import json
strList = "[1,2,3,3,4]"
print(json.loads(strList))
print(type(json.loads(strList)))
试着运行上面的代码,你会发现已经成功的将strList转换为列表对象。
将对象转换成字典
import json
strDict = '{"city":"上海","name":"jack","age":18}'
print(json.loads(strDict))
print(type(json.loads(strDict)))
试着运行上面的代码,你会发现已经成功的将object转换为dict类型的数据。
json.dumps()
其实这个方法也很好理解,就是将Python类型的对象转换为json字符串。从Python类型向JSON类型转换的对照表如下:
| python | JSON |
|---|---|
| dict | object |
| list, tuple | array |
| str | string |
| int, float | number |
| True | true |
| False | false |
| None | null |
将Python列表对象转换为JSON字符串
import json
list_str = [1,2,3,6,5]
print(json.dumps(list_str))
print(type(json.dumps(list_str)))
试着运行上面的代码,你会发现成功的将列表类型转换成了字符串类型。
将Python元组对象转换为JSON字符串
import json
tuple_str = (1,2,3,6,5)
print(json.dumps(tuple_str))
print(type(json.dumps(tuple_str)))
试着运行上面的代码,你会发现成功的将元组类型的数据转换成了字符串。
将Python字典对象转换为JSON字符串
import json
dict_str = {"name": "小明", "age":18, "city": "中国深圳"}
print(json.dumps(dict_str))
print(type(json.dumps(dict_str)))
输出结果:
{"name": "\u5c0f\u660e", "age": 18, "city": "\u4e2d\u56fd\u6df1\u5733"}
<class 'str'>
看到上面的输出结果也许你会有点疑惑,其实不需要疑惑,这是ASCII编码方式造成的,因为**json.dumps()**做序列化操作时默认使用的就是ASCII编码,因此我们可以这样写:
import json
dict_str = {"name": "小明", "age":18, "city": "中国深圳"}
print(json.dumps(dict_str, ensure_ascii=False))
print(type(json.dumps(dict_str)))
输出结果:
{"name": "小明", "age": 18, "city": "中国深圳"}
<class 'str'>
因为ensure_ascii的默认值是True,因此我们可以添加参数ensure_ascii将它的默认值改成False,这样编码方式就会更改为utf-8了。
json.load()
该方法的主要作用是将文件中JSON形式的字符串转换为Python类型。
具体代码示例如下:
import json
str_list = json.load(open('position.json', encoding='utf-8'))
print(str_dict)
print(type(str_dict))
运行上面的代码,你会发现成功的将字符串类型的JSON数据转换为了dict类型。
代码中的文件position.json我也会分享给大家。
json.dump()
将Python内置类型序列化为JSON对象后写入文件。具体代码示例如下所示:
import json
list_str = [{'city':'深圳'}, {'name': '小明'},{'age':18}]
dict_str = {'city':'深圳','name':'小明','age':18}
json.dump(list_str, open('listStr.json', 'w'), ensure_ascii=False)
json.dump(list_str, open('dictStr.json', 'w'), ensure_ascii=False)
3.jsonpath
XML的优点是提供了大量的工具来分析、转换和有选择地从XML文档中提取数据。Xpath是这些功能强大的工具之一。
对于JSON数据来说,也出现了jsonpath这样的工具来解决这些问题:
数据可以通过交互方式从客户端上的JSON结构提取,不需要特殊的脚本。 客户端请求的JSON数据可以减少到服务器的上的相关部分,从而大幅度减少服务器响应的带宽使用。
jsonpath表达式始终引用JSON结构的方式与Xpath表达式与XML文档使用的方式相同。
jsonpath的安装方法
pip install jsonpath
jsonpath与Xpath
下面表格是jsonpath语法与Xpath的完整概述和比较。
| Xpath | jsonpath | 概述 |
|---|---|---|
| / | $ | 根节点 |
| . | @ | 当前节点 |
| / | .or[] | 取子节点 |
| * | * | 匹配所有节点 |
| [] | [] | 迭代器标识(如数组下标,根据内容选值) |
| // | … | 不管在任何位置,选取符合条件的节点 |
| n/a | [,] | 支持迭代器中多选 |
| n/a | ?() | 支持过滤操作 |
| n/a | () | 支持表达式计算 |
下面我们就通过几个示例来学习jsonxpath的使用方法。
我们先来看下面这段json数据
{ "store": {
"book": [
{ "category": "reference",
"author": "Nigel Rees",
"title": "Sayings of the Century",
"price": 8.95
},
{ "category": "fiction",
"author": "Evelyn Waugh",
"title": "Sword of Honour",
"price": 12.99
},
{ "category": "fiction",
"author": "Herman Melville",
"title": "Moby Dick",
"isbn": "0-553-21311-3",
"price": 8.99
},
{ "category": "fiction",
"author": "J. R. R. Tolkien",
"title": "The Lord of the Rings",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"color": "red",
"price": 19.95
}
}
}
获取符合条件的节点
假如我需要获取到作者的名称该怎么样写呢?
如果通过Python的字典方法来获取是非常麻烦的,所以在这里我们可以选择使用jsonpath.。
具体代码示例如下所示:
import jsonpath
author = jsonpath.jsonpath(data_json, '$.store.book[*].author')
print(author)
运行上面的代码你会发现,成功的获取到了所有的作者名称,并保存在列表中。
或者还可以这样写:
import jsonpath
author = jsonpath.jsonpath(data_json, '$..author')
print(author)
使用指定索引
还是使用上面的json数据,假如我现在需要获取第三本书的价格。
third_book_price = jsonpath.jsonpath(data_json, '$.store.book[2].price')
print(third_book_price)
运行上面的代码,你会发现成功的获取到了第三本书的价格。
使用过滤器
isbn_book = jsonpath.jsonpath(data_json, '$..book[?(@.isbn)]')
print(isbn_book)
print(type(isbn_book))
通过运行上面的代码,你会发现,成功的将含有isbn编号的书籍过滤出来了。
同样的道理,根据上面的例子,我们也可以将价格小于10元的书过滤出来。
book = jsonpath.jsonpath(data_json, '$..book[?(@.price<10)]')
print(book)
print(type(book))
通过运行上面的代码,你会发现这里已经成功的将价格小于10元的书提取出来了。
jsonpath其实是非常适合用来获取json格式的数据的一款工具,最重要的是这款工具轻量简单容使用。关于jsonpath的介绍到这里就结束了,下面我们就进入实战演练吧!
4.Jsonpath 实战教程
前言
每年的6月份都是高校学生的毕业季,作为计算机专业的你来说,如果刚刚毕业就可以进入大厂,想必是一个非常不错的选择。因此,今天我带来的项目就是爬取腾讯招聘的网站,获取职位名称、职位类别、工作地点、工作国家、职位的更新时间、职位描述。
爬取内容一共有329页,在前329页的职位都是在这个月发布的,还是比较新,对大家来说更有参考的价值。
网页链接:https://careers.tencent.com/search.html
准备
工欲善其事,必现利其器。首先我们要准备好几个库:pandas、requests、jsonpath
如果没有安装,请参考下面的安装过程:
pip install requests
pip install pandas
pip install jsonpath
需求分析与功能实现
获取所有的职位信息
对网页进行分析的时候,我发现想从网页上直接获取信息是是做不到的,该网页的响应信息如下所示:
<!DOCTYPE html><html><head><meta charset=utf-8><meta http-equiv=X-UA-Compatible content="IE=edge"><meta name=viewport content="initial-scale=1,maximum-scale=1,user-scalable=no"><meta name=keywords content=""><meta name=description content=""><meta name=apple-mobile-web-app-capable content=no><meta name=format-detection content="telephone=no"><title>搜索 | 腾讯招聘</title><link rel=stylesheet href=https://cdn.multilingualres.hr.tencent.com/tencentcareer/static/css/main.css><link rel=stylesheet href=https://cdn.multilingualres.hr.tencent.com/tencentcareer/static/css/jquery-ui.min.css></head><body><div id=app></div><script type=text/javascript src=https://cdn.multilingualres.hr.tencent.com/careersmlr/HeadFoot_zh-cn.js></script><script type=text/javascript src=https://cdn.multilingualres.hr.tencent.com/careersmlr/HostMsg_zh-cn.js></script><script type=text/javascript src=https://cdn.multilingualres.hr.tencent.com/careersmlr/Search_zh-cn.js></script><script type=text/javascript src=https://cdn.multilingualres.hr.tencent.com/tencentcareer/static/js/vendor/config.js></script><script type=text/javascript src=https://cdn.multilingualres.hr.tencent.com/tencentcareer/static/js/vendor/jquery.min.js></script><script type=text/javascript src=https://cdn.multilingualres.hr.tencent.com/tencentcareer/static/js/vendor/jquery.ellipsis.js></script><script type=text/javascript src=https://cdn.multilingualres.hr.tencent.com/tencentcareer/static/js/vendor/report.js></script><script type=text/javascript src=https://cdn.multilingualres.hr.tencent.com/tencentcareer/static/js/vendor/qrcode.min.js></script><script type=text/javascript src=https://cdn.multilingualres.hr.tencent.com/tencentcareer/static/js/manifest.build.js></script><script type=text/javascript src=https://cdn.multilingualres.hr.tencent.com/tencentcareer/static/js/vendor.build.js></script><script type=text/javascript src=https://cdn.multilingualres.hr.tencent.com/tencentcareer/static/js/p_zh-cn_search.build.js></script></body><script type=text/javascript src=https://cdn.multilingualres.hr.tencent.com/tencentcareer/static/js/vendor/common.js></script></html>
因此我判断,这个是动态Ajax加载的数据,因此就要去网页控制器上查找职位数据是否存在。
经过一番查找,果然发现是动态加载的数据,信息如下所示:
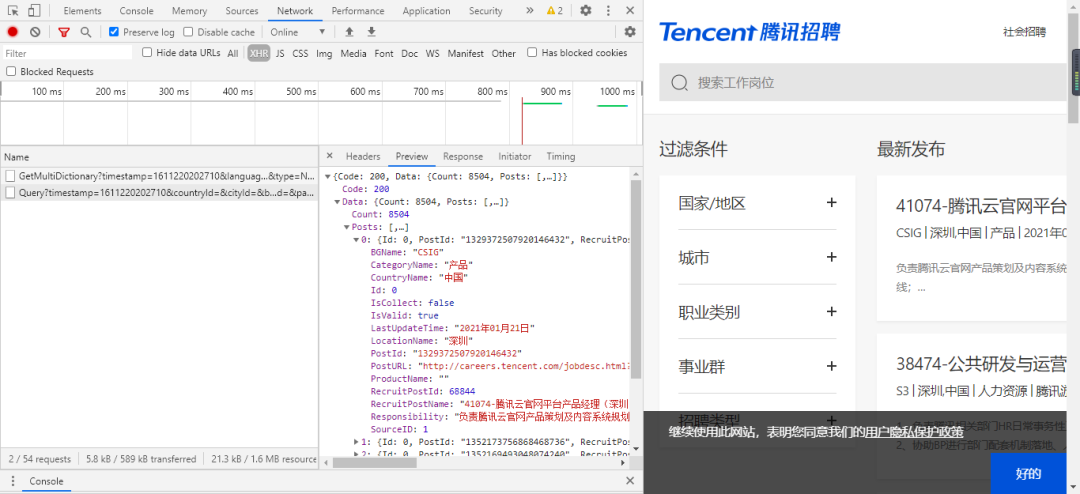
格式化之后的数据如下所示:
{
"Code":200,
"Data":{
"Count":8500,
"Posts":[
{
"Id":0,
"PostId":"1346716678288842752",
"RecruitPostId":71330,
"RecruitPostName":"41071-腾讯会议项目经理(西安)(CSIG全资子公司)",
"CountryName":"中国",
"LocationName":"西安",
"BGName":"CSIG",
"ProductName":"腾讯云",
"CategoryName":"产品",
"Responsibility":"1、负责研发项目及研发效能的计划制定、进度驱动和跟踪、风险识别以及应对,确保项目按计划完成;
2、负责组织项目各项评审会议及项目例会,制定并推广项目流程规范,确保项目有序进行;
3、负责与项目外部合作伙伴进行沟通,制定流程规范双方合作,并推动合作事宜;
4、及时发现并跟踪解决项目问题,有效管理项目风险。
",
"LastUpdateTime":"2021年01月21日",
"PostURL":"http://careers.tencent.com/jobdesc.html?postId=1346716678288842752",
"SourceID":1,
"IsCollect":false,
"IsValid":true
},
{
"Id":0,
"PostId":"1346716729744564224",
"RecruitPostId":71331,
"RecruitPostName":"41071-腾讯会议产品策划(平台方向)(CSIG全资子公司)",
"CountryName":"中国",
"LocationName":"西安",
"BGName":"CSIG",
"ProductName":"腾讯云",
"CategoryName":"产品",
"Responsibility":"1、负责腾讯会议企业管理平台的产品策划工作,包括企业运营平台、运维、会控平台和工具的产品设计和迭代优化;
2、协调和推动研发团队完成产品开发、需求落地,并能在需求上线后进行持续数据分析和反馈跟进,不断提升产品竞争力;
3、根据行业场景抽象用户需求,沉淀面向不同类型客户的云端管控平台解决方案;
",
"LastUpdateTime":"2021年01月21日",
"PostURL":"http://careers.tencent.com/jobdesc.html?postId=1346716729744564224",
"SourceID":1,
"IsCollect":false,
"IsValid":true
},
{
"Id":0,
"PostId":"1346062593894129664",
"RecruitPostId":71199,
"RecruitPostName":"41071-腾讯会议产品策划(CSIG全资子公司)",
"CountryName":"中国",
"LocationName":"西安",
"BGName":"CSIG",
"ProductName":"腾讯云",
"CategoryName":"产品",
"Responsibility":"负责腾讯会议的产品策划工作:
1、研究海外用户办公习惯及SaaS市场动态,调研海外相关SaaS产品并输出产品调研结论,综合市场情况和用户需求输出高质量的产品需求或解决方案;
2、负责腾讯会议各产品线的英文版的功能同步和产品设计工作,把关产品功能同步和国际版需求改造等;
3、协调和推动研发团队完成产品开发、需求落地,并能在需求上线后进行持续数据分析和反馈跟进,不断提升产品竞争力; ",
"LastUpdateTime":"2021年01月21日",
"PostURL":"http://careers.tencent.com/jobdesc.html?postId=1346062593894129664",
"SourceID":1,
"IsCollect":false,
"IsValid":true
},
{
"Id":0,
"PostId":"1352161575309418496",
"RecruitPostId":72134,
"RecruitPostName":"CSIG16-推荐算法高级工程师",
"CountryName":"中国",
"LocationName":"北京",
"BGName":"CSIG",
"ProductName":"",
"CategoryName":"技术",
"Responsibility":"1. 参与地图场景下推荐算法优化,持续提升转化效果和用户体验;
2. 负责地图场景下推荐引擎架构设计和开发工作;
3. 跟进业界推荐领域最新进展,并推动其在地图场景下落地。",
"LastUpdateTime":"2021年01月21日",
"PostURL":"http://careers.tencent.com/jobdesc.html?postId=0",
"SourceID":1,
"IsCollect":false,
"IsValid":true
},
{
"Id":0,
"PostId":"1352158432852975616",
"RecruitPostId":72133,
"RecruitPostName":"41071-腾讯云SDK 终端研发工程师(CSIG全资子公司)",
"CountryName":"中国",
"LocationName":"西安",
"BGName":"CSIG",
"ProductName":"",
"CategoryName":"技术",
"Responsibility":"1. 负责腾讯云 GME SDK(游戏多媒体引擎)的开发和优化工作,并配套开发相应的场景解决方案业务流程,以满足不同场景和不同行业的客户需求;
2. 全流程参与客户需求咨询、需求评估、方案设计、方案编码实施及交付工作;
3. 负责优化腾讯云GME产品易用性,并跟踪客户的接入成本、完善服务体系,解决客户使用产品服务和解决方案过程中的技术问题,不断完善问题处理机制和流程。",
"LastUpdateTime":"2021年01月21日",
"PostURL":"http://careers.tencent.com/jobdesc.html?postId=0",
"SourceID":1,
"IsCollect":false,
"IsValid":true
},
{
"Id":0,
"PostId":"1352155053116366848",
"RecruitPostId":72131,
"RecruitPostName":"40931-智慧交通数据平台前端开发工程师(北京)",
"CountryName":"中国",
"LocationName":"北京",
"BGName":"CSIG",
"ProductName":"",
"CategoryName":"技术",
"Responsibility":"负责腾讯智慧交通领域的平台前端开发工作;
负责规划与制定前端整体发展计划与基础建设;
负责完成前端基础架构设计与组件抽象。",
"LastUpdateTime":"2021年01月21日",
"PostURL":"http://careers.tencent.com/jobdesc.html?postId=0",
"SourceID":1,
"IsCollect":false,
"IsValid":true
},
{
"Id":0,
"PostId":"1306860769169645568",
"RecruitPostId":66367,
"RecruitPostName":"35566-HRBP(腾讯全资子公司)",
"CountryName":"中国",
"LocationName":"武汉",
"BGName":"CSIG",
"ProductName":"",
"CategoryName":"人力资源",
"Responsibility":"负责区域研发公司的HR政策、制度、体系与重点项目在部门内部的落地与推动执行;
深入了解所负责领域业务与人员发展状况,评估并明确组织与人才发展对HR的需求;
驱动平台资源提供HR解决方案,并整合内部资源推动执行;提升管理干部的人力资源管理能力,关注关键人才融入与培养,确保持续的沟通与反馈;
协助管理层进行人才管理、团队发展、组织氛围建设等,确保公司文化在所属业务领域的落地;
负责所对接部门的人才招聘工作;
",
"LastUpdateTime":"2021年01月21日",
"PostURL":"http://careers.tencent.com/jobdesc.html?postId=1306860769169645568",
"SourceID":1,
"IsCollect":false,
"IsValid":true
},
{
"Id":0,
"PostId":"1351353005709991936",
"RecruitPostId":71981,
"RecruitPostName":"35566-招聘经理(腾讯云全资子公司)",
"CountryName":"中国",
"LocationName":"武汉",
"BGName":"CSIG",
"ProductName":"",
"CategoryName":"人力资源",
"Responsibility":"1、负责CSIG区域研发公司相关部门的社会招聘及校园招聘工作,制定有效的招聘策略并推动落地执行,保障人才开源、甄选和吸引;
2、负责相关部门人力资源市场分析,有效管理并优化招聘渠道;
3、参与招聘体系化建设,甄选相关优化项目,有效管理及优化招聘渠道。",
"LastUpdateTime":"2021年01月21日",
"PostURL":"http://careers.tencent.com/jobdesc.html?postId=1351353005709991936",
"SourceID":1,
"IsCollect":false,
"IsValid":true
},
{
"Id":0,
"PostId":"1351838518279675904",
"RecruitPostId":72081,
"RecruitPostName":"35566-雇主品牌经理(腾讯云全资子公司)",
"CountryName":"中国",
"LocationName":"武汉",
"BGName":"CSIG",
"ProductName":"",
"CategoryName":"人力资源",
"Responsibility":"1、负责腾讯云区域研发公司雇主品牌的规划和建设工作,结合业务招聘需求,制定有效的品牌方案;
2、负责讯云区域研发公司的公众号、媒体账号的内容策划、撰写,协调相关资源完成高质量内容输出;
3、负责招聘创意项目的策划和项目统筹,借助各种平台渠道,完成创意内容的传播触达,提升人选对腾讯云区域研发公司的认知和意向度;",
"LastUpdateTime":"2021年01月21日",
"PostURL":"http://careers.tencent.com/jobdesc.html?postId=1351838518279675904",
"SourceID":1,
"IsCollect":false,
"IsValid":true
},
{
"Id":0,
"PostId":"1199244591342030848",
"RecruitPostId":55432,
"RecruitPostName":"22989-数据库解决方案架构师(北京/上海/深圳)",
"CountryName":"中国",
"LocationName":"上海",
"BGName":"CSIG",
"ProductName":"",
"CategoryName":"产品",
"Responsibility":"支持客户的应用架构设计,了解客户的业务逻辑和应用架构,给出合理的产品方案建议;
支持客户的数据库方案设计,从运维、成本、流程等角度主导云数据库产品落地;
梳理客户的核心诉求,提炼为普适性的产品能力,推动研发团队提升产品体验;
根据客户的行业属性,定制行业场景的解决方案,提升云数据库的影响力;",
"LastUpdateTime":"2021年01月21日",
"PostURL":"http://careers.tencent.com/jobdesc.html?postId=1199244591342030848",
"SourceID":1,
"IsCollect":false,
"IsValid":true
}
]
}
}
经过对比发现上面的json数据与网页信息是完全相同的。
看到json数据你有没有一丝的惊喜,终于到了可以大显身手的时候了。
你会发现,上面每一个节点的参数都是独立的,不会存在重复,那我们可以这样写:
def get_info(data):
recruit_post_name = jsonpath.jsonpath(data, '$..RecruitPostName')
category_name = jsonpath.jsonpath(data, '$..CategoryName')
country_name= jsonpath.jsonpath(data, '$..CountryName')
location_name = jsonpath.jsonpath(data, '$.Data.Posts..LocationName')
responsibility = jsonpath.jsonpath(data, '$..Responsibility')
responsibility = [i.replace('\n', '').replace('\r', '') for i in responsibility]
last_update_time = jsonpath.jsonpath(data, '$..LastUpdateTime')
运行上面的代码,你会发现成功的获取到了每一组数据。
关于翻页
打开网页之后你会发现腾讯的职位信息一共有850页,但是前面的json数据仅仅只有第一页的数据怎么办呢?
不用担心,直接点击第二页看看网络数据有什么变化。
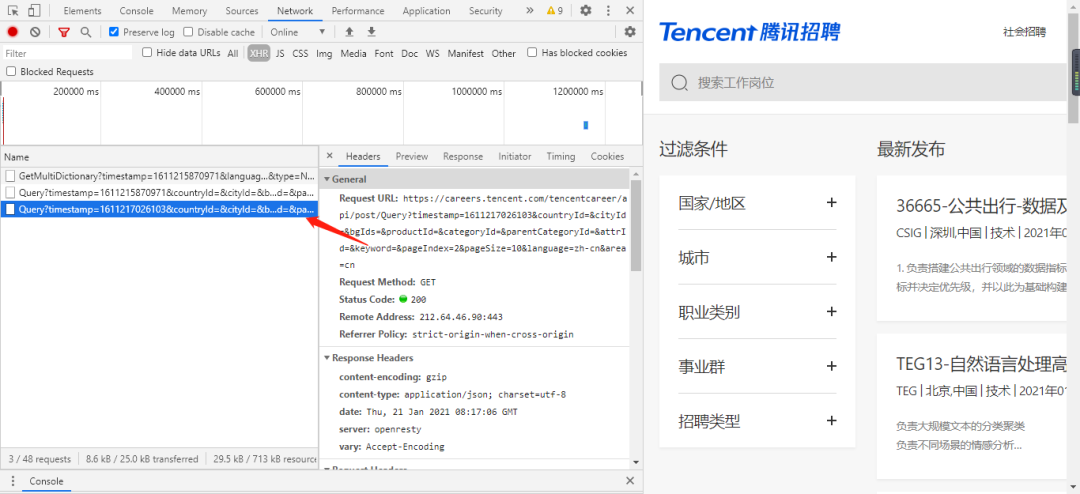
如上图所示,当点击第二页的时候,又加载出来了一个数据,点击进去之后你就会发现,这个数据刚好就是第二页的职位信息。
那接下来就是发现规律的时候了,第一页与第二页保存JSON数据的URL如下所示:
# 第一页
https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1611215870971&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex=1&pageSize=10&language=zh-cn&area=cn
# 第二页
https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1611217026103&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex=2&pageSize=10&language=zh-cn&area=cn
经过测试发现,可以将URL地址进行简化,简化后的URL如下所示:
# 第一页
https://careers.tencent.com/tencentcareer/api/post/Query?pageIndex=1&pageSize=10
# 第二页
https://careers.tencent.com/tencentcareer/api/post/Query?pageIndex=1&pageSize=10
数据保存
将爬取下来的数据保存至csv文件,核心代码如下所示:
df = pd.DataFrame({
'country_name': country_name,
'location_name': location_name,
'recruit_post_name':recruit_post_name,
'category_name': category_name,
'responsibility':responsibility,
'last_update_time':last_update_time
})
if __name__ == '__main__':
tengxun = TengXun()
df = pd.DataFrame(columns=['country_name', 'location_name', 'category_name','recruit_post_name', 'responsibility', 'last_update_time'])
for page in range(1, 330):
print(f'正在获取第{page}页')
url = tengxun.get_url(page)
data = tengxun.get_json(url)
time.sleep(0.03)
df1 = get_info(data)
df = pd.concat([df, df1])
df = df.reset_index(drop=True)
# pprint.pprint(data)
df.to_csv('../data/腾讯招聘.csv', encoding='utf-8-sig')
最后结果

我们的文章到此就结束啦,如果你喜欢今天的Python 实战教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应红字验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
点击下方阅读原文可获得更好的阅读体验
Python实用宝典 (pythondict.com)
不只是一个宝典
欢迎关注公众号:Python实用宝典
