
微博数据是非常有价值的数据,这些数据可以用作我们进行一些系统开发时的数据源, 比如前段时间发过的:Python 短文本识别个体是否有自杀倾向,在此文中,我们使用微博绝望树洞的数据,利用SVM做了一个简单的自杀倾向识别模型。
当然,微博数据的应用还不仅如此,如果你大胆详细,大胆猜测,将会有许多可以利用这些数据进行研究的机会。不过, 技术是把双刃剑,有好有坏,我不希望各位拿着这个爬虫去做一些违反道德、法律的事情,应用于好的事务,才是技术诞生的初衷。
本文讲的是以用户为单位的爬虫,如果你希望能够定制自己需要的爬虫,请看这篇教程:Python 爬取微博树洞详细教程
1.准备
其实免登录的原理很简单,就是通过手机版的微博绕过其登录验证,大家可以用手机网页打开这个网址,你会发现其实大部分微博在你不登录的情况下都是可见的:
https://m.weibo.cn/u/2075686772
可见即可爬。因此,我们只需要调用这个微博数据的json接口即可获取到数据。不过我们不要一上来就直接撸代码,要善于利用Python开源社区的特点,上网上找相关的现成的成熟轮子,而不是自己动手做一个半成熟版,这样能节省许多时间。
经过一番搜索,我找到了这个免Cookie版的微博爬虫,dataabc开发的:
https://github.com/dataabc/weibo-crawler
其代码思路与我想的差不多,只需要调用json的数据接口即可获取数据:

下载该开源项目,可以上该网页直接Download, 也可以使用git:
git clone https://github.com/dataabc/weibo-crawler.git
如果你两个都不会,没关系,Python实用宝典后台回复 微博采集工具 即可下载。
2.配置采集参数
在开始采集数据前,你需要确保电脑上已经安装了Python,如果没有,请访问这篇文章:超详细Python安装指南 进行安装。
安装完Python后,Windows环境下打开Cmd(开始—运行—CMD),苹果系统环境下请打开Terminal(command+空格输入Terminal).
进入我们刚下载好的文件夹,输入以下命令安装所需要的模块:
pip install -r requirements.txt
看到许多个 Successfully installed xxx 则说明安装成功。
2.1 找到你需要爬的用户ID
点开你希望爬取的用户主页,然后查看此时的url,你会发现有一串数字在链接中,这个就是我们要用到的userID, 复制即可。
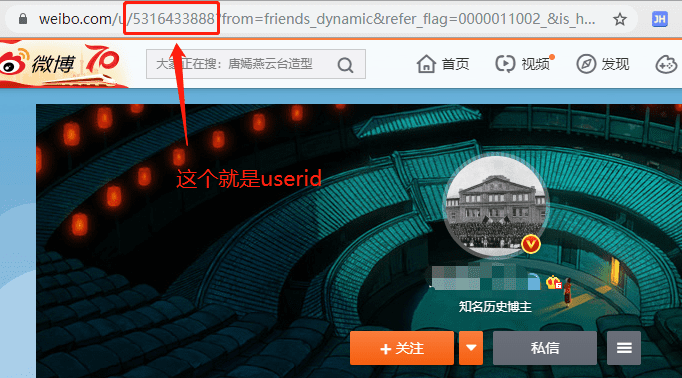
如果不是一串数字,可以点开任一条微博评论的页面,这时候上面的链接一定会有串数字,如果还是没有,就上手机版的微博页面找,这种时候就需要耐心和多尝试了。
2.2 修改config.json
获得用户的userID后,需要将ID写入到config.json的user_id_list数组中,如图所示:

其他参数如:
filter:控制爬取范围,值为1代表爬取全部原创微博,值为0代表爬取全部微博(原创+转发)
since_date: 爬取该日期之后的时间
write_mode: 写入的文件格式
下面的分别是:是否下载原创微博图片、是否下载转发微博图片、是否下载原创视频、是否下载转发的视频,如果为1则是,为0则为否。再往后如果你需要写入数据库,还可以配置MySQL或MongoDB的连接参数。
3.开始采集
配置好了以后,采集就很简单了,你只需要用CMD或Terminal进入该文件夹,输入:
python weibo.py
即可进行数据采集。采集结束后,如果你设定的是保存为csv文件,则会在当前文件夹下的weibo文件夹里产生一个名为该微博用户名的数字.csv文件,如:
weibo\阿森纳足球俱乐部\2075686772.csv
这个文件里就是你想要的数据。
该开源模块设计的功能其实非常完善,你看看下面这个列表就知道了。

真的太贴心辣,必须得感谢这位开源作者,如果你喜欢的话,记得上去他的仓库给他点个star哦!
我们的文章到此就结束啦,如果你希望我们今天的Python 教程,请持续关注我们,如果对你有帮助,麻烦在下面点一个赞/在看哦![]() 有任何问题都可以在下方留言区留言,我们都会耐心解答的!
有任何问题都可以在下方留言区留言,我们都会耐心解答的!
Python实用宝典 (pythondict.com)
不只是一个宝典
欢迎关注公众号:Python实用宝典

评论(2)
如果要设置爬取微博的截至日期请问该这么办呢?
可以自行修改代码设置end_date