

工作时我们经常会遇到需要临时保存结果变量的场景,尤其是一些数据处理、模型开发的场景,加载处理速度是个很漫长的过程,于是经常会把这些变量储存起来。
而储存变量最常见、最普遍的方法是用pickle,保存为pkl文件。但是如果从写入和读取的性能角度考虑,pkl可能真的不是最优选。
Pickle有其独特的好处,大部分变量不需要进行处理,都能直接存到pkl文件里,但这样的方便其实是牺牲了部分性能取得的。与之相比,numpy的.npy格式就比pickle性能上快不少。
当然,我们需要有证据支撑这个观点。所以今天我们就来做个实验,分别在Python2和Python3中对比 numpy 和 pickle 两种存储格式(.npy, .pkl) 对数据的存储和读取的性能对比。
部分内容参考分析自: https://applenob.github.io/python/save/
1. Python2中, npy与pkl的性能对比
首先初始化数据:
import numpy as np
import time
import cPickle as pkl
import os
all_batches = []
for i in range(20):
a1 = np.random.normal(size=[25600, 40])
label = np.random.normal(size=[25600, 1])
all_batch = np.concatenate([a1, label], 1)
all_batches.append(all_batch)
all_batches = np.array(all_batches)
print(all_batches.shape)
# (20, 25600, 41)然后测试使用pickle保存和读取时间的耗时,以及整个文件的大小:
s_t1 = time.time()
pkl_name = "a.pkl"
with open(pkl_name, "wb") as f:
pkl.dump(all_batches, f)
pkl_in_time = time.time() - s_t1
print("pkl dump costs {} sec".format(pkl_in_time))
s_t2 = time.time()
with open(pkl_name, "rb") as f:
new_a = pkl.load(f)
pkl_out_time = time.time() - s_t2
print("pkl load costs {} sec".format(pkl_out_time))
pkl_size = os.path.getsize(pkl_name)
print("pkl file size: {} byte, {} mb".format(pkl_size, float(pkl_size)/(1024*1024)))结果如下:

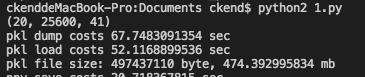
pkl dump costs 67.7483091354 sec
pkl load costs 52.1168899536 sec
pkl file size: 497437110 byte, 474.392995834 mb
然后再试一下npy的写入和读取:
s_t3 = time.time()
npy_name = "a.npy"
with open(npy_name, "wb") as f:
np.save(f, arr=all_batches)
npy_in_time = time.time() - s_t3
print("npy save costs {} sec".format(npy_in_time))
s_t4 = time.time()
with open(npy_name, "rb") as f:
new_a = np.load(f)
npy_out_time = time.time() - s_t4
print("npy load costs {} sec".format(npy_out_time))
npy_size = os.path.getsize(npy_name)
print("npy file size: {} byte, {} mb".format(npy_size, float(npy_size) / (1024 * 1024)))结果如下:


npy save costs 20.718367815 sec
npy load costs 0.62314915657 sec
npy file size: 167936128 byte, 160.15637207 mb
结果发现,npy性能明显优于pkl格式。
通过多次测试发现,在Python2中,npy格式的性能优势全面碾压pkl,工程允许的情况下,在Python2中,我们应该在这二者中毫不犹豫地选择npy.
2.Python3中, npy与pkl的性能对比
Python2已经是过去式,重点还要看Python3.
在Python3中,与Python2的代码唯一一句不一样的是pickle的引入:
# Python2: import cPickle as pkl # Python3: import pickle as pkl
其他代码基本一样,替换代码后,重新运行程序,让我们看看在Python3上,npy格式和pkl格式性能上的区别:
首先是pkl格式的表现:
ckenddeMacBook-Pro:Documents ckend$ python 1.py (20, 25600, 41) pkl dump costs 24.32167887687683 sec pkl load costs 4.480823040008545 sec pkl file size: 167936163 byte, 160.15640544891357 mb
然后是npy格式的表现:
npy save costs 22.471696853637695 sec npy load costs 0.3791017532348633 sec npy file size: 167936080 byte, 160.1563262939453 mb
可以看到在Python3中pkl格式和npy格式的存储大小是基本相同的,在存储耗时上也相差无几。但是在读取数据的时候,npy相对于pkl还是有一定的优势的。
因此,如果你的程序非常注重读取效率,那么我觉得npy格式会比pkl格式更适合你。
我们的文章到此就结束啦,如果你喜欢今天的 Python 教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 ( pythondict.com )
不只是一个宝典
欢迎关注公众号:Python实用宝典

