

在泰坦尼克号上你能活下来吗?Python告诉你!
泰坦尼克号是英国的一艘客轮,在1912年4月的一个清晨,其从南安普顿出发,在行驶至目的地纽约的途中与冰山相撞后沉没,船上估计共有2224名乘客和船员,死亡1500多人,成为现代历史上最严重的和平时期海上灾难。
今天,我们将在著名的泰坦尼克号数据集上创建机器学习模型,这个数据集提供了有关泰坦尼克号上乘客的数据,比如经济状况、性别、年龄等等,让我们组合这些特征,构建一个根据参数预测某些人是否能够在当时那种情况下存活的机器学习模型,甚至可以用来测测自己存活的概率。

1.准备
开始之前,你要确保Python和pip已经成功安装在电脑上噢,如果没有,请访问这篇文章:超详细Python安装指南 进行安装。
Windows环境下打开Cmd(开始—运行—CMD),苹果系统环境下请打开Terminal(command+空格输入Terminal),准备开始输入命令安装依赖。
当然,我更推荐大家用VSCode编辑器,把本文代码Copy下来,在编辑器下方的终端装依赖模块,多舒服的一件事啊:Python 编程的最好搭档—VSCode 详细指南。
输入以下命令安装我们所需要的依赖模块:
pip install numpy pip install pandas pip install seaborn pip install matplotlib pip install scikit-learn
看到 Successfully installed xxx 则说明安装成功。啊,别忘了,还要下载数据集,你可以上kaggle官网进行下载,也可以在Python实用宝典公众号后台回复:泰坦尼克号 获得本文完整数据和代码。
2.分析基本数据
在开始使用机器学习进行分析前,我们需要先做一些常规的数据分析,比如缺失值检测、特征数量、基本关联分析等。
2.1 缺失值
首先是缺失值检测,这样的数据集不可能没有缺失值,我们在开始机器学习分析之前就应该把缺失的数据情况分析清楚。
这时候就要善用工具了:7行代码巧用Python热力图可视化表格缺失数据,丰富的知识积累在这个时候就能派上用场。生成热力图:

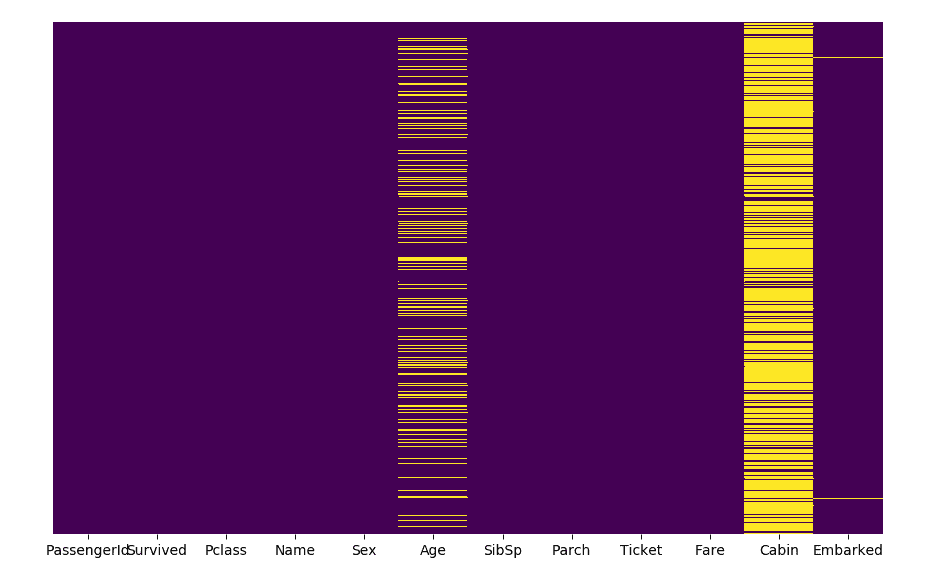
可见,cabin和Age的缺失值最多,这两列数据到了不得已的情况的话需要删除掉。还有Embarked有几个缺失值,这种情况好处理,我们用填充的方法就可以解决。热力图代码:


2.2 找到特征变量
这一小节,我们重点要找出哪些变量能使得乘客的存活率更高,比如年龄和性别、上船的位置、等等。
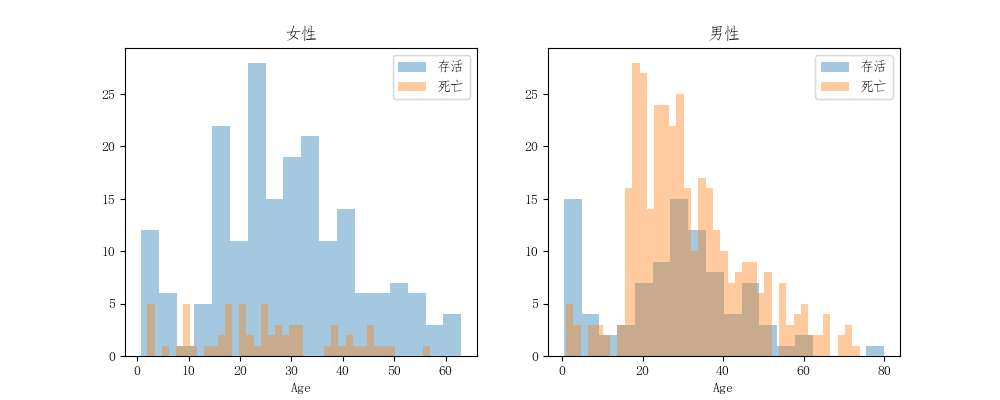
首先从年龄、性别上进行分析,根据训练集绘制如下的分析图:
我们可以看到,男性的死亡率其实更高,大体体现了让女性和儿童先逃亡的原则。对于5到18岁的男性而言,存活下来的几率似乎非常低,不过这可能是因为船上这个年龄段的人数少导致的。
再往下看,客舱等级和上船地点是否会对生存率造成影响?请看下图,Embarked是上船港口,pclass是客舱等级,数字1为头等舱。

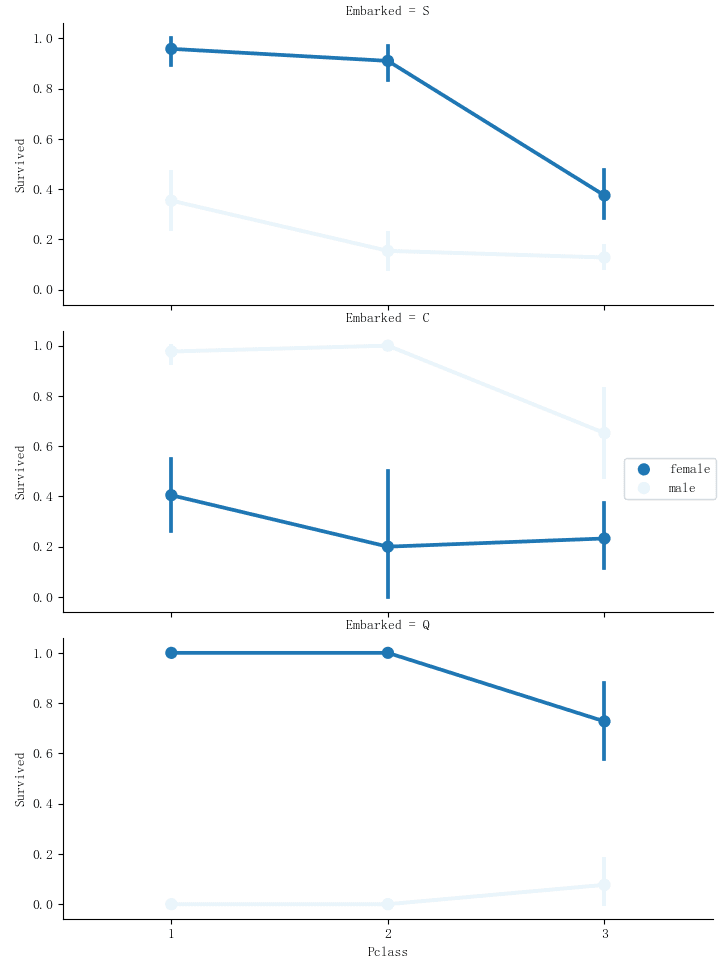
可以看到,头等舱乘客的存活率高于其他舱的乘客,而且,C港口上岸的人男性存活概率大于女性,这不得不让人怀疑C港口乘客的品德了。
还有一点,亲戚越多是不是越可能存活呢?
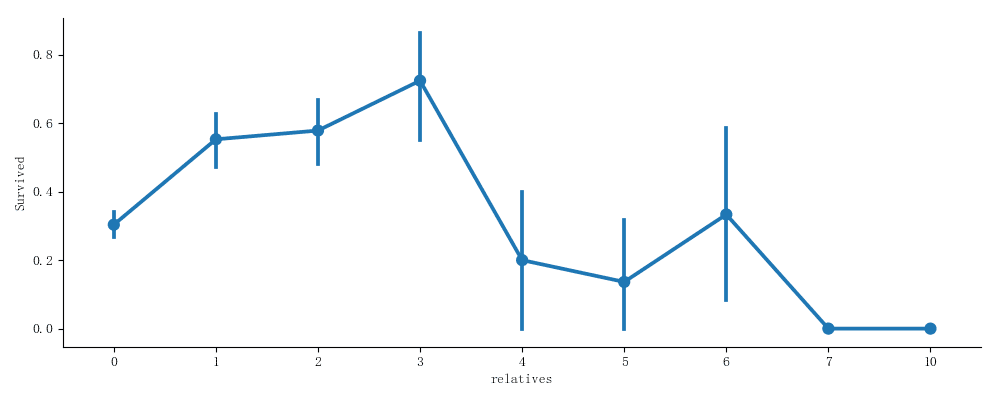
可以看到,亲戚数量在1到3的人最有可能存活,不过,大于3之后的存活率可就不太好看了。
这部分可视化的代码如下:

3.机器学习预测
首先我们得根据刚刚的数据分析进行数据预处理,去除掉对我们模型没有帮助的数据【 乘客ID 】。
此外,【cabin】 实在是缺太多了,我们在这里也把它们都去掉。
【name 】 维度,名字要数字化才能分析,为了简化步骤,这里也去除掉。
还要去掉的一个是【Ticket】,都是唯一值,对我们而言没有意义,去除掉。
3.1 补全缺失数据
当然还得补完整我们的缺失值。根据年龄的平均值和标准差求得年龄的随机数,填充缺失的年龄数据。登船点均用S地来替代。


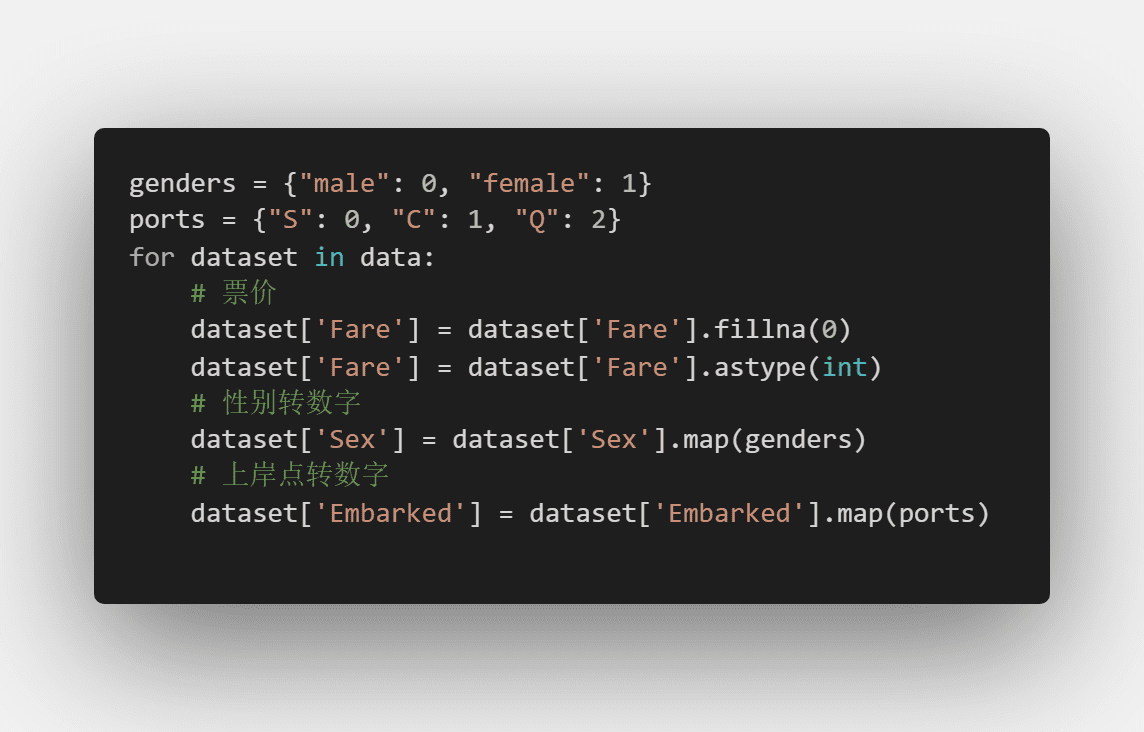
3.2 数字化数据
这里我们一共需要数字化三个维度:
1.票价,从浮点型转整形
2.性别转数字
3.上岸点转数字
不得不说,pandas是真的方便。Map就完事了。

3.3 单值转段值
由于年龄是一个一个的数字,在数据量不够大的情况,这样一个一个的数字没太大意义,我们要按照年龄段进行划分,票价也是如此,我们一起转化了:


3.4 创建模型
终于到了关键点了,然而这里是整个第三节最简单的部分,因为sklearn模块已经帮我们包装好了所有需要做的东西,我们需要做的仅仅是调用模块、传入数据训练、测试。
我们使用随机森林模型(说实话如果没有sklearn,这个模型能写到我头秃),关于随机森林的介绍可以看这一篇文章,其实就是解决了决策树的过拟合问题,这篇文章讲得通俗易懂:
https://blog.csdn.net/mao_xiao_feng/article/details/52728164
训练和测试的代码如下:


准确率如下:
>> python 1.p 0.9034792368125701
准确率有90%,这是挺高的准确率了,让我们把自己的情况带入进去,看看能不能存活,最终数据格式是这样的,你只需要把自己的情况带入,然后往测试数据追加属于你的一行即可:

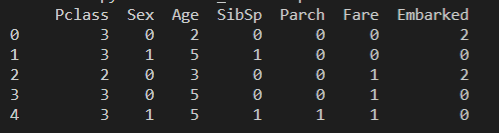
比如我应该会坐二等舱(其实是三等舱,但是想想我都坐泰坦尼克号了为什么不坐二等舱?);Sex为 1 (男性),Age在范围 3 中(老了啊);SibSp是在船兄弟姐妹配偶的数量,Parch是在船父母、儿女数量,由于我可能是一个人出游,这里我们都设为 0,然后票价Fare应该是 2,Embarked随意选0.


>> python 1.py 1
天啊,我竟然能活下来,不容易 (滑稽,不知道是不是换了个舱的缘故) 。大家也试试看吧。完整代码太长了,在这里就不放出来了,大家可在Python实用宝典公众号后台回复 泰坦尼克号 获取。
本文参考自 https://towardsdatascience.com/predicting-the-survival-of-titanic-passengers-30870ccc7e8
我们的文章到此就结束啦,如果你喜欢我们今天的Python 教程,请持续关注我们,如果对你有帮助,麻烦在下面点一个赞/在看哦![]()

Python实用宝典 (pythondict.com)
不只是一个宝典
欢迎关注公众号:Python实用宝典

