

当某个股票保持下跌的时候,你可以肯定该股票一定有什么地方不对,要么是它的市场,要么是它的公司。——利弗莫尔
因此结合自己最近的研究,提出了这个比较新颖的想法:利用股票市场找到已有或潜在食品安全问题的企业。
为什么会有这个想法呢?我们知道食品安全事故发生的时间点和媒体报道的时间点之间实际上是有一个间隔的,然而相关利益人士、内部人士却能提前知道事件的发生。
比如说,2012年11月19日,酒鬼酒被国家质检总局爆出塑化剂超标247%,但是在19号之前,酒鬼酒的收盘价却神奇地从2012年11月2日的55元回落到2012年11月16号的46元。然而国家质检总局的消息是在2012年11月19号才发布的。
而且这样的下跌,明显违背该股票当时上涨的趋势,在10月底时,它的股价已突破周K的压力线,却很不自然地下跌了?而且还违背了许多技术指标,如1号、14号、16号,KDJ和BOLL指标明显提示上涨,在股市这种情绪化的市场中,有人却不为所动,仍然售出大量股票导致其不正常下跌。

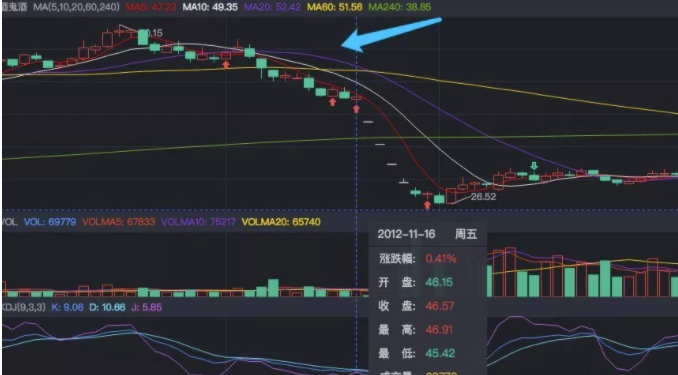
2012年11月19号消息公布时紧急停牌,复牌后有三个跌停,股价暴跌48%,但我相信某些人已经成功躲开了这场股灾。
找到已有或潜在食品安全问题的企业的重点在于两个方面:
1.该股票在该板块或者该股强走势的情况下却发生连续多日的下跌
2.不正常的跌停板
如果我们在消息公布/(不公布)前能提前捕捉到这个异常信息,我们就能提前捕捉到某个食品的安全问题,而且也能规避投资风险。当然,出现这种异常的可能性非常多,这种异常只能作为参考。
下面让我们尝试用Python来找到第一种趋势的企业,当然我最后不会公布结果,大家感兴趣可以自己试试:
首先利用tushare找到和食品安全相关的上市企业:
import tushare as ts
def food_codes():
data = ts.get_industry_classified()
print data[data.c_name.isin(['食品行业','农药化肥','酿酒行业'])]得到结果:


均线是我们获得该股票趋势的基础,下面我们编写均线函数:
def get_ma(code,start='',end=datetime.date.today().strftime("%Y-%m-%d")):
data = ts.get_k_data(code)
data = data.sort_index(ascending=False)
data['ma2'] = data['close'].rolling(2).mean().shift(-1)
data['ma5'] = data['close'].rolling(5).mean().shift(-4)
data['ma10'] = data['close'].rolling(10).mean().shift(-9)
data['ma20'] = data['close'].rolling(20).mean().shift(-19)
data['ma60'] = data['close'].rolling(60).mean().shift(-59)
data['ma240'] = data['close'].rolling(240).mean().shift(-239)
data['date'] = pd.to_datetime(data['date'])
if start == '':
return data
start = pd.to_datetime(start)
end = pd.to_datetime(end)
if data['date'][len(data) - 1] < start:
return 0
while data.loc[data.date == start].empty:
start = start + dateutil.relativedelta.relativedelta(days=1)
while data.loc[data.date == end].empty:
end = end - dateutil.relativedelta.relativedelta(days=1)
return data.loc[(data.date >= start) & (data.date <= end)]我们只需要确定两点:
1. 以20个交易日为窗口期,其内最高价和最低价的差距大于其最高价的15%。
2. 该股票处于涨势。
def analyzeOne(code):
rng = pd.date_range('2018-1-1', datetime.date.today().strftime("%Y-%m-%d"), freq='D')
# 获得日期
flag = 0
for i in range(20,len(rng)):
data = get_ma(code,rng[i-20],rng[i])
count = 0
data = data.sort_index(ascending=True)
# 升序
max = data['close'][data['close'].argmax()]
min = data['close'][data['close'].argmin()]
for j in range(len(data)):
if data.iloc[j]['ma5'] >= data.iloc[j]['ma20'] and data.iloc[j]['ma20'] >= data.iloc[j]['ma60'] and \
data.iloc[j]['ma60'] >= data.iloc[j]['ma240']:
count = count + 1
if count >= 5 and (max-min) - max*0.15 > 0:
print 'Code: ' + str(code) +', Problem:' + str(rng[i-20])+ ' ' + str(rng[i])
else:
count = 0如果存在这样的趋势,就输出这个趋势的窗口时间段,当然这只是一个粗略的模型,结果中可能会有很多意外的情况,但是我觉得足够启发大家了。
想要应用于所有食品相关股票:
def find_down():
for i in food_codes().code:
analyzeOne(i)通过这样的操作,我找到了两支类似的股票:



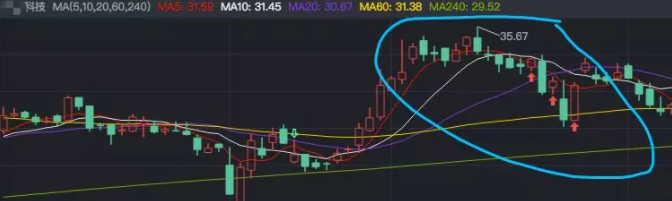
但这些股票都没有新闻报道发生了问题,最后也让我怀疑自己的模型的准确性,到底是市场正常波动,还是这个企业存在问题。
因此,这个模型存在许多的优化空间,如何通过股市最准确地找出那些出问题的企业,还有待进一步研究,本实验只是提出一个初步的模型和一些想法。
个人愚见,欢迎讨论。
我们的文章到此就结束啦,如果你喜欢今天的Python 实战教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应红字验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
点击下方阅读原文可获得更好的阅读体验
Python实用宝典 (pythondict.com)
不只是一个宝典
欢迎关注公众号:Python实用宝典
