

双十一刚过,天猫的销售额创新高占领了各大新闻媒体头条。但是,知乎上的一个问题对本次双十一的销售额提出了一个非常有意思的问题:《如何看待双十一销售额完美分布在三次回归曲线上且拟合高达 99.94%?是巧合还是造假?》
本文的重点放在如何用Python实现三次回归曲线的预测功能。
1.数据源
采用cnbeta新闻报道中的数据:《[直击]2019年天猫双11落幕:交易额2684亿元》

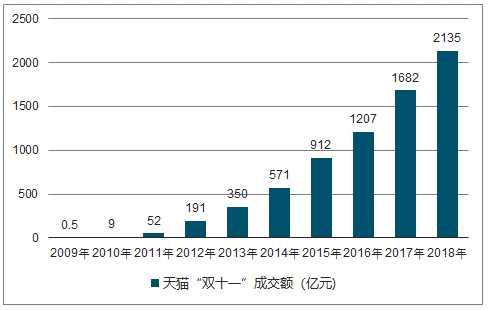
有效数字保留三位,其中2009年为0.52亿、2010年为9.36亿、2011年为52.0亿。
2.代码构建
我们将使用scikitlearn的多项式回归实现预测。训练集是2009至2014年的数据,后续测试中将陆续增加训练集至2018年。
2.1 数据预处理
构造三次多项式特征需要以列的形式,因此代码中会将numpy数组reshape成列形式。
# 数据集 datasets_X = [2009, 2010, 2011, 2012, 2013, 2014] datasets_Y = [0.52, 9.36, 52.0, 191, 350, 571] test_X = [2015, 2016, 2017, 2018, 2019] real_Y = [912, 1207, 1682, 2132, 2684] # 数据预处理 dataset_length = len(datasets_X) test_length = len(test_X) # 将数据转化为numpy数组,并变为列的形式 datasets_X = np.array(datasets_X).reshape([dataset_length, 1]) test_X = np.array(test_X).reshape([test_length, 1]) datasets_Y = np.array(datasets_Y) real_Y = np.array(real_Y)
2.2 数据建模训练
这里需要注意的是,必须先构建三次多项式特征后才可放入线性回归模型。
# 数据建模 # 构造三次多项式特征 poly_reg = PolynomialFeatures(degree=3) X_poly = poly_reg.fit_transform(datasets_X) # 使用线性回归模型学习X_poly和datasets_Y之间的映射关系 lin_reg_3 = LinearRegression() lin_reg_3.fit(X_poly, datasets_Y)
2.3 数据预测
训练完毕后,就可以将lin_reg_3模型用于预测:
data = poly_reg.fit_transform(test_X) pred = lin_reg_3.predict(data) print(pred)
结果:
[ 830.64251041 1127.88919544 1457.47841358 1814.48141575 2193.96944141]
在这个训练集的基础上,预测2019年的销售额是2193亿,和真实的2684亿还是差了点。不过这样看不是很直观,让我们可视化一下数据,并逐渐增加训练集。
3.数据可视化
用 matplotlib 可以非常简单地实现这一步,设定X轴范围—绘制数据点—绘制线,最后加上横纵轴说明。
# 数据可视化
# X轴
X = np.arange(2009, 2020).reshape([-1, 1])
# 蓝色显示训练数据点
plt.scatter(datasets_X, datasets_Y, color='blue')
# 红色显示真实数据点
plt.scatter(test_X, real_Y, color='red')
# 黄色显示预测数据点
plt.scatter(test_X, pred, color='yellow')
plt.plot(X, lin_reg_3.predict(poly_reg.fit_transform(X)), color='black')
plt.xlabel('年份')
plt.ylabel('销售额(亿)')
plt.show() 结果如下,蓝色点是训练值,红色点是真实值,而黄色的点是预测值:


训练集增加2015年的真实数据,结果如下:
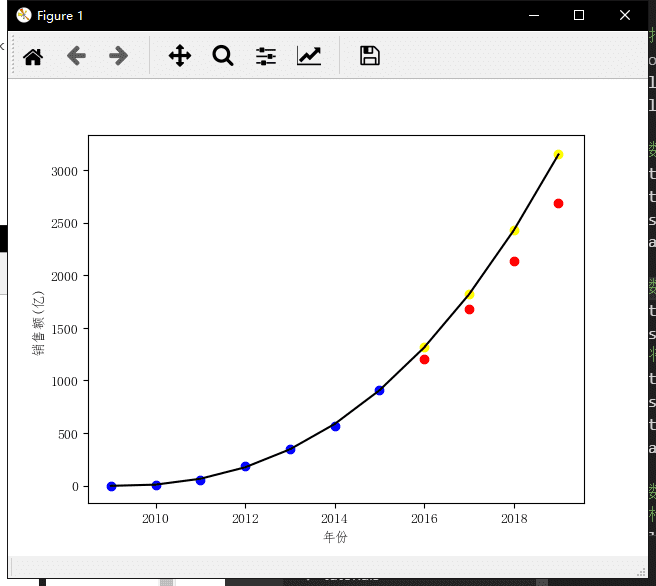
有意思,真实值反而比预测值低了,说明2015年这一年的成交额非常优秀。
再增加2016年的真实数据到训练集里看一下。
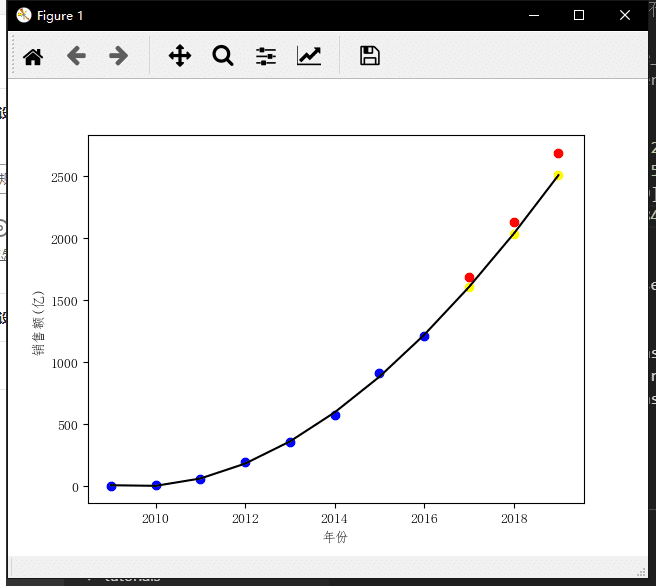
现在,2017年、2018年的预测值非常接近,预测2019年的销售额是2507.3990亿元,离真实的2684亿差了100多亿。让我们继续增加2017年的真实数据到训练集中,预测2018年和2019年的销售额。
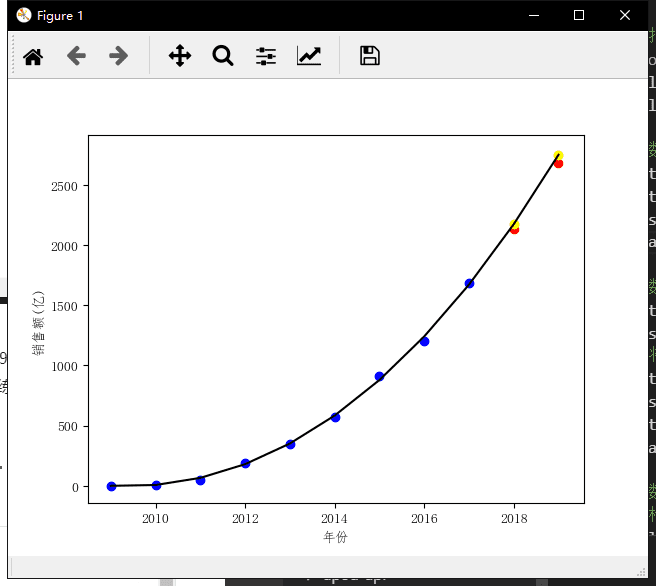
优秀,不过2019年预测的销售额为2750亿,略高于真实值2684亿,我们最后将2018年真实值加入到训练集中,看看2019年该模型的预测值是多少。

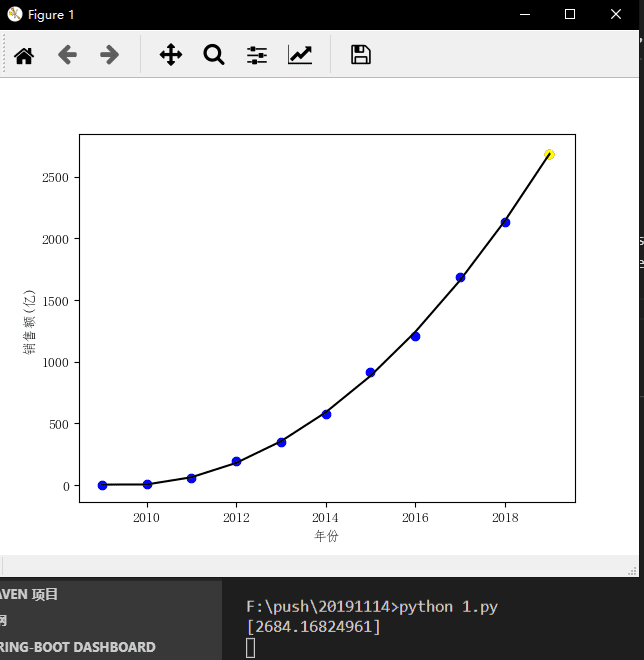
惊呆了,小红点和小黄点完美重合。按照这个模型,2020年的双十一销售额将会是3293亿元。
关注文章最下方Python实用宝典公众号二维码,回复 天猫销售额预测 或阅读原文下载查阅本模型完整源代码:
import matplotlib.pyplot as plt
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
from sklearn.metrics import r2_score
# 指定默认字体否则图片显示不了中文
from pylab import mpl
mpl.rcParams['axes.unicode_minus'] = False # 解决符号显示问题
mpl.rcParams['font.sans-serif'] = ['FangSong']
# 数据集
datasets_X = [2009, 2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018]
datasets_Y = [0.52, 9.36, 52.0, 191, 350, 571, 912, 1207, 1682, 2132]
test_X = [2019]
real_Y = [2684]
# 数据预处理
dataset_length = len(datasets_X)
test_length = len(test_X)
# 将数据转化为numpy数组
datasets_X = np.array(datasets_X).reshape([dataset_length, 1])
test_X = np.array(test_X).reshape([test_length, 1])
datasets_Y = np.array(datasets_Y)
real_Y = np.array(real_Y)
# 数据建模
# 构造三次多项式特征
poly_reg = PolynomialFeatures(degree=3)
X_poly = poly_reg.fit_transform(datasets_X)
# 使用线性回归模型学习X_poly和datasets_Y之间的映射关系
lin_reg_3 = LinearRegression()
lin_reg_3.fit(X_poly, datasets_Y)
data = poly_reg.fit_transform(test_X)
pred = lin_reg_3.predict(data)
print(pred)
# 数据可视化
# X轴
X = np.arange(2009, 2020).reshape([-1, 1])
# 蓝色显示训练数据点
plt.scatter(datasets_X, datasets_Y, color='blue')
# 红色显示真实数据点
plt.scatter(test_X, real_Y, color='red')
# 黄色显示预测数据点
plt.scatter(test_X, pred, color='yellow')
plt.plot(X, lin_reg_3.predict(poly_reg.fit_transform(X)), color='black')
plt.xlabel('年份')
plt.ylabel('销售额(亿)')
plt.show() 如果你喜欢今天的Python 教程,请持续关注Python实用宝典,如果对你有帮助,麻烦在下面点一个赞/在看哦![]()

Python实用宝典 (pythondict.com)
不只是一个宝典
欢迎关注公众号:Python实用宝典

