
Reddit Hyped Stocks — 是GitHub上开源的一个查找 Reddit 当前被炒作的股票的Web应用程序。
通过它,你或许能找到下一支“游戏驿站”。


1.怎么判断“炒作”?
作者使用“炒作得分”的概念对Reddit上所有被炒作的股票进行了排序,其中炒作得分的计算如下:
收集的原始数据包含所选子Reddit的前n个帖子,每次都会收集包括点赞在内的所有基本数据。
每个帖子都会被标记为某只股票的炒作贴(基于标题)。
然后建立一个矩阵,其中每一行代表一个时间点,每一列代表一只股票。矩阵的值表示在某个时间点,一只股票的所有帖子的炒作分数的总和。
然后计算每个时间点的差值作为增量值,比如我想知道过去7天的炒作分数排行,我会对各个股票将过去7天的增量值之和作为总和来计算炒作分数并进行排行。
有关确切的算法,请查看源代码中的 ticker_score_calulation.py。
2.功能与说明
炒作图(顶部),即下图所示:

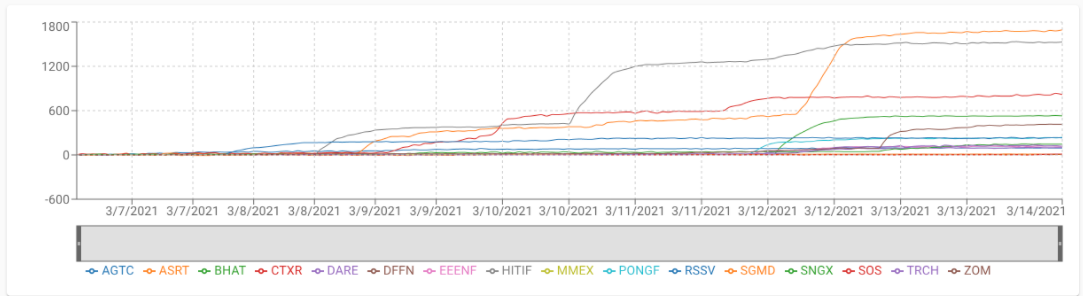
该图表显示了Reddit上当前炒作分数最高的一些股票,显示了排名前15位的股票的累计炒作得分。默认情况下,这个图表显示过去一星期内各个股票的分数变化。
炒作表(左侧),如下图所示:

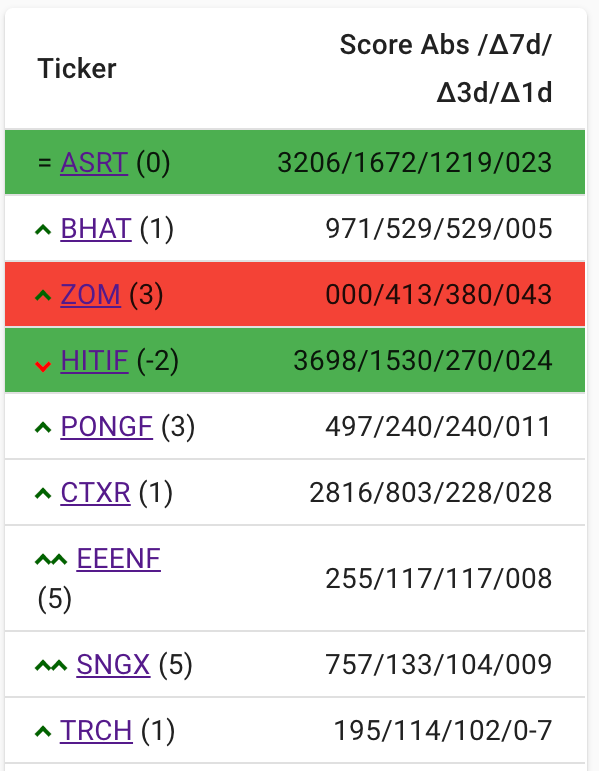
这里会显示排名前30位的炒作股票及其各自的炒作得分,以下值:
- Score Abs:所有相关帖子的炒作分数总和
- Δ7d/Δ3d/Δ1d:周期分别为7/3/1天的增量炒作得分
另外,每一行都指示一天的仓位增/减(两个上/下箭头表示+/- 5个排名,一个上/下箭头表示小于+/- 5个排名,= 表示不变)。
单击股票名字后,会打开详细信息视图:

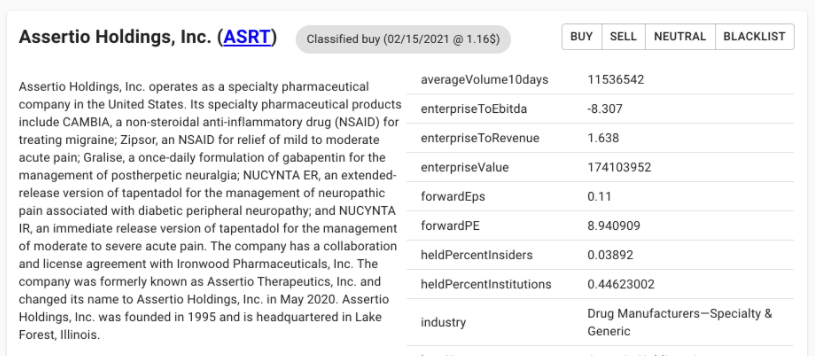
这里会展示股票的基本信息,每股收益、所属行业、PE值、关联的Reddit帖子等等。
3.安装部署
在Python实用宝典后台回复:Reddit 可以获取此开源代码库的代码和数据(reddit-hyped-stocks 及 data.db)。
(选项1)使用Docker运行应用程序:
- 1. 克隆此仓库或将其下载到本地计算机
- 2. 要使用没有你自己的数据的应用程序,你可以从:https://drive.google.com/file/d/12aAc35F5a0_doGE7Af8xsukRyNKPo1g0/view?usp=sharing
获取示例数据库,下载并将文件复制到backend/data.db(我将尝试保留它是最新的) - 3. 运行
./run-server-docker.sh这将需要一些时间来下载依赖项并构建应用程序 - 4. 浏览器打开 http://localhost:5000 访问页面
(选项2)在没有Docker的情况下运行应用程序/设置开发环境
- 1. 将存储库克隆到本地计算机
- 2. 安装Python 3和Node.js
- 3. cd 到
backend并运行pip3 install -r requirements.txt以安装后端依赖项。运行backend/start.sh以运行后端开发服务器 - 4. cd到
frontend并运行npm i以安装前端依赖项。运行npm run start以运行前端开发服务器。
(非必须)收集原始数据
由于炒作得分取决于帖子,因此必须定期(例如每小时)爬取Reddit帖子数据。
必须条件:获取 Reddit API token:
- 1. 前往 https://www.reddit.com/prefs/apps
- 2. 点击“创建应用”并填写信息,使用“script”类型
- 3. 将密钥和应用程序ID复制到文件中:
backend/praw.ini
默认情况下,子论坛 robinhoodpennystocks 和 pennystocks 会被爬取(可在中配置backend/load_data.py)。
数据会被保存到Sqlite数据库中。要查询数据,请使用脚本 backend/load_data.py 或运行 ./run-load-data-docker.sh。
我们的文章到此就结束啦,如果你喜欢今天的 Python 教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 ( pythondict.com )
不只是一个宝典
欢迎关注公众号:Python实用宝典

