
今天是机器学习100天学习计划的第2天,我们将实现一个简单的线性回归模型。
线性回归模型就是基于单一特征(X)来预测结果(Y),回归任务的难点在于找到最佳的拟合线,而我们使用机器学习训练模型的目的就是为了找到这条最佳的拟合线。
构建模型的整个流程如下:

第零步:准备 #
开始之前,你要确保Python和pip已经成功安装在电脑上,如果没有,请访问这篇文章:超详细Python安装指南 进行安装。如果你用Python的目的是数据分析,可以直接安装Anaconda:Python数据分析与挖掘好帮手—Anaconda,它内置了Python和pip.
此外,推荐大家用VSCode编辑器,非常方便:Python 编程的最好搭档—VSCode 详细指南
Windows环境下打开Cmd(开始—运行—CMD),苹果系统环境下请打开Terminal(command+空格输入Terminal),输入命令安装依赖:
pip install pandas pip install numpy pip install matplotlib pip install scikit-learn
第一步:数据预处理 #
按照第一天学习的数据预处理知识,这一步我们将执行以下步骤:
1.导入库
2.导入数据集
3.检查缺失数据
4.划分数据集
5.特征归一化(缩放)
代码如下,studentscores.csv 和本文完整源代码,可在Python实用宝典公众号后台回复:机器学习2 下载。
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
dataset = pd.read_csv('studentscores.csv')
X = dataset.iloc[:, : 1].values
Y = dataset.iloc[:, 1].values
X_train, X_test, Y_train, Y_test = train_test_split(
X, Y, test_size=1/4, random_state=0)studentscores.csv 这份文件存在两列数据,学习时长和分数。我们将用线性回归的方式探讨学习时长和分数的关系。
第二步:训练模型 #
使用 sklearn 的 LinearRegression 能够很轻易地实现一个线性模型的训练。
我们曾经在这篇文章中讲解过:Python 用5行代码学机器学习—线性回归
from sklearn.linear_model import LinearRegression regressor = LinearRegression() regressor = regressor.fit(X_train, Y_train)
第三步:预测结果 #
基于 sklearn 优秀的代码封装能力,预测测试集的结果仅需要一行代码:
Y_pred = regressor.predict(X_test)
第四步:可视化 #
单纯看数据不是很直观,我们可以使用 matplotlib 将数据可视化。
值得一提的是在真正的实际生活应用中,使用 matplotlib 进行数据可视化这一步往往是在训练模型之前做的,因为我们拿到数据后该做的第一步是探索性数据分析,也叫EDA分析。
不过因为这是一篇教程似的文章,并没有需要进行探索性数据分析的必要,因此我们略过了EDA分析。
训练集可视化:
plt.scatter(X_train, Y_train, color='red') plt.plot(X_train, regressor.predict(X_train), color='blue') plt.show()
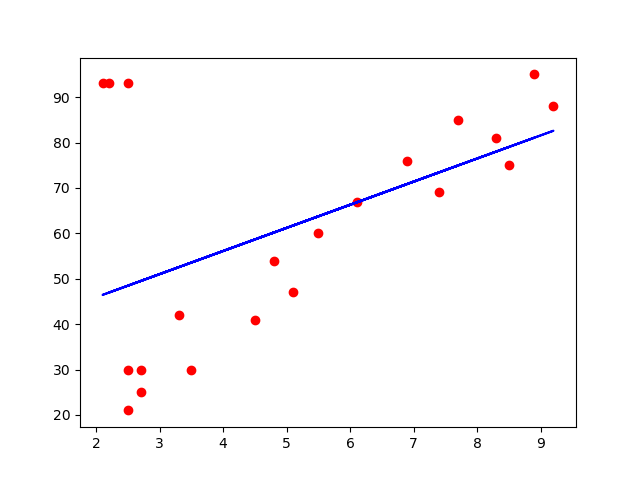
测试集可视化:
plt.scatter(X_test, Y_test, color='red') plt.plot(X_test, regressor.predict(X_test), color='blue') plt.show()

这样,我们便完成了一次简单线性回归模型的训练和测试,还是比较简单的。
如果你想看进一步的应用,可以阅读这篇文章:
我们的文章到此就结束啦,如果你喜欢今天的 Python 教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 ( pythondict.com )
不只是一个宝典
欢迎关注公众号:Python实用宝典





评论(0)