

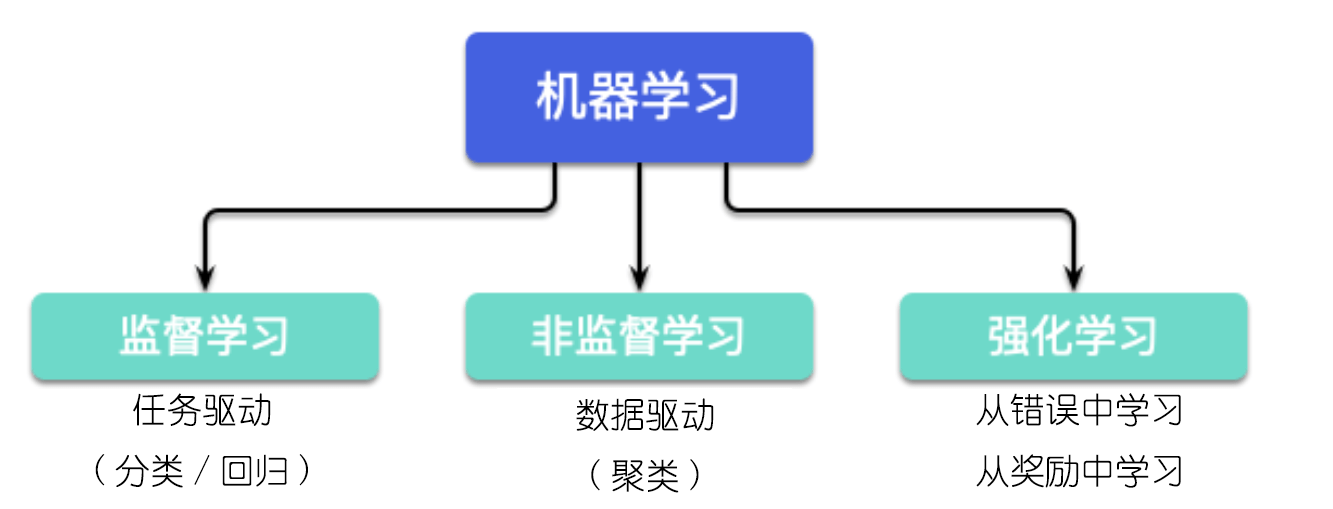
强化学习是机器学习的方式之一,它与监督学习、无监督学习并列,是三种机器学习训练方法之一。

在围棋上击败世界第一的李世石的 AlphaGo、在《星际争霸2》中以 10:1 击败了人类顶级职业玩家的AlphaStar,他们都是强化学习模型。诸如此类的模型还有 AlphaGo Zero 等。
强化学习的原理非常简单,它非常像心理学中新行为主义派的斯金纳发现的操作性条件反射。

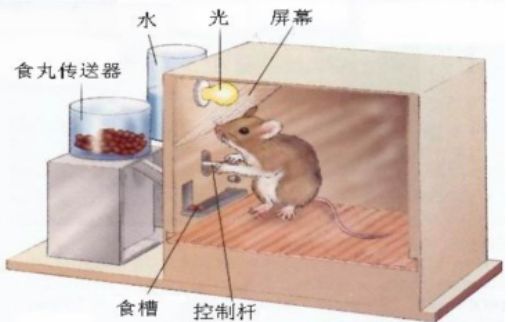
操作性条件反射是什么?当年斯金纳做了一个箱子,进行了两次实验。
第一次实验,箱子里放了一只饥饿的老鼠,在箱子的一边有一个可供按压的杠杆,在杠杆旁边有一个放置食物的小盒子。动物在箱内按下杠杆,食盒就会释放食物进入箱内,动物可以取食。结果:小鼠自发学会了按按钮。这是积极强化。
另一次实验是,每次小白鼠不按下按钮,则给箱子通电,小白鼠因此学会了按按钮以防自己遭受电击。这是消极强化(负向强化)。
这就是斯金纳发现的操作性条件反射,当行为得到奖励或惩罚时出现刺激,反过来控制这种行为。

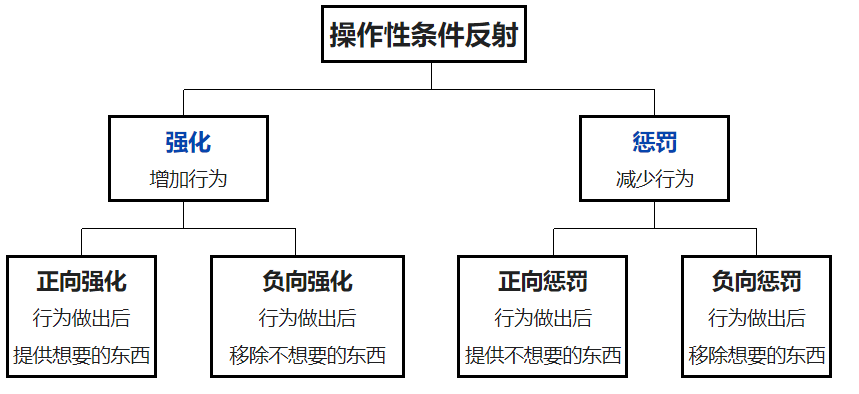
强化学习与操作性条件反射有异曲同工之妙,以人类玩游戏为例,如果在游戏中采取某种策略购买某种类型的装备可以取得较高的得分,那么就会进一步“强化”这种策略,以期继续取得较好的结果。
网上有不少强化学习的例子,鉴于读者中对股票感兴趣的同学比较多,我们以股票预测为例,实验一下 wangshub 的 RL-Stock 项目。
使用强化学习预测股价,需要在决策的时候采取合适的行动 (Action) 使最后的奖励最大化。与监督学习预测未来的数值不同,强化学习根据输入的状态(如当日开盘价、收盘价等),输出系列动作(例如:买进、持有、卖出),并对好的动作结果不断进行奖励,对差的动作结果不断进行惩罚,使得最后的收益最大化,实现自动交易。
下面就试一下这个强化学习项目,前往GitHub下载 RL-Stock。
如果你无法使用GitHub,也可以在Python实用宝典公众号后台回复:股票强化学习1 下载全文完整代码,包括第三部分的多进程优化逻辑。
1.准备
开始之前,你要确保Python和pip已经成功安装在电脑上,如果没有,请访问这篇文章:超详细Python安装指南 进行安装。
(可选1) 如果你用Python的目的是数据分析,可以直接安装Anaconda:Python数据分析与挖掘好帮手—Anaconda,它内置了Python和pip.
(可选2) 此外,推荐大家用VSCode编辑器来编写小型Python项目:Python 编程的最好搭档—VSCode 详细指南
请注意,由于TensorFlow版本限制,这个强化学习项目只支持 Python3 以上,Python3.6 及以下的版本,因此我建议使用Anaconda创建一个新的虚拟环境运行这个项目:
conda create -n rlstock python=3.6
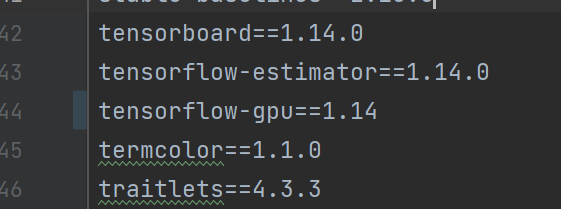
另外,实测依赖需要改动 requirements.txt 的tensorflow-gpu版本至1.14:

Windows环境下打开Cmd(开始—运行—CMD),苹果系统环境下请打开Terminal(command+空格输入Terminal),进入 RL-Stock 项目文件夹输入命令安装依赖:
pip install -r requirements.txt
2.小试强化学习预测股票价格
运行RL-Stock项目前,需要下载数据。进入刚创建的虚拟环境,运行get_stock_data.py代码会自动下载数据到 stockdata 目录中:
python get_stock_data.py
如果你使用的是在Github上下载的代码而不是Python实用宝典后台改好的代码,请注意 get_stock_data.py 的第46行,必须对 row[“code_name”] 去除 * 号,否则Windows系统下可能会存在问题:
df_code.to_csv(f'{self.output_dir}/{row["code"]}.{row["code_name"].strip("*")}.csv', index=False)数据下载完成后就可以运行 main.py 执行强化学习训练和测试,不过在训练之前,我们先简单了解下整个项目的输入状态、动作、和奖励函数。
输入状态(观测 Observation)
策略网络观测的就是一只股票的各类数据,比如开盘价、收盘价、成交量等,它可以由许多因子组成。为了训练时网络收敛,观测状态数据输入时必须要进行归一化,变换到 [-1, 1] 的区间内。RL-Stock输入的观测数据字段如下:
| 参数名称 | 参数描述 | 说明 |
|---|---|---|
| date | 交易所行情日期 | 格式:YYYY-MM-DD |
| code | 证券代码 | 格式:sh.600000。sh:上海,sz:深圳 |
| open | 今开盘价格 | 精度:小数点后4位;单位:人民币元 |
| high | 最高价 | 精度:小数点后4位;单位:人民币元 |
| low | 最低价 | 精度:小数点后4位;单位:人民币元 |
| close | 今收盘价 | 精度:小数点后4位;单位:人民币元 |
| preclose | 昨日收盘价 | 精度:小数点后4位;单位:人民币元 |
| volume | 成交数量 | 单位:股 |
| amount | 成交金额 | 精度:小数点后4位;单位:人民币元 |
| adjustflag | 复权状态 | 不复权、前复权、后复权 |
| turn | 换手率 | 精度:小数点后6位;单位:% |
| tradestatus | 交易状态 | 1:正常交易 0:停牌 |
| pctChg | 涨跌幅(百分比) | 精度:小数点后6位 |
| peTTM | 滚动市盈率 | 精度:小数点后6位 |
| psTTM | 滚动市销率 | 精度:小数点后6位 |
| pcfNcfTTM | 滚动市现率 | 精度:小数点后6位 |
| pbMRQ | 市净率 | 精度:小数点后6位 |
动作 Action
共有买入、卖出和持有 3 种动作,定义动作(action)为长度为 2 的数组
action[0]为操作类型;action[1]表示买入或卖出百分比;
动作类型 action[0] | 说明 |
|---|---|
| 1 | 买入 action[1] |
| 2 | 卖出 action[1] |
| 3 | 持有 |
注意,当动作类型 action[0] = 3 时,表示不买也不抛售股票,此时 action[1] 的值无实际意义,网络在训练过程中,Agent 会慢慢学习到这一信息。Agent,实称代理,在我们的上下文中,你可以视其为策略。
奖励 Reward
奖励函数的设计,对强化学习的目标至关重要。在股票交易的环境下,最应该关心的就是当前的盈利情况,故用当前的利润作为奖励函数。
# profits reward = self.net_worth - INITIAL_ACCOUNT_BALANCE reward = 1 if reward > 0 else -100
为了使网络更快学习到盈利的策略,当利润为负值时,给予网络一个较大的惩罚 (-100)。
梯度策略
作者采用了基于策略梯度的PPO 算法,OpenAI 和许多文献已把 PPO 作为强化学习研究中首选的算法。PPO 优化算法 Python 实现参考 stable-baselines。
数据集及自定义
在数据集上,作者使用了1990年至2019年11月作为训练集,2019年12月作为测试集。
1990-01-01 ~ 2019-11-29 | 2019-12-01 ~ 2019-12-31 |
|---|---|
| 训练集 | 测试集 |
如果你要调整这个训练集和测试集的时间,可以更改 get_stock_data.py 的以下部分:
if __name__ == '__main__':
# 获取全部股票的日K线数据
# 训练集
mkdir('./stockdata/train')
downloader = Downloader('./stockdata/train', date_start='1990-01-01', date_end='2019-11-29')
downloader.run()
# 测试集
mkdir('./stockdata/test')
downloader = Downloader('./stockdata/test', date_start='2019-12-01', date_end='2019-12-31')
downloader.run()训练并测试
首先,我们尝试一下单一代码的训练和测试,修改main.py里的股票代码,比如我这里修改为601919中远海控:
if __name__ == '__main__':
# multi_stock_trade()
test_a_stock_trade('sh.601919')
# ret = find_file('./stockdata/train', '601919')
# print(ret)
运行下面的命令,执行此深度学习模型的训练和测试。
python main.py
训练完成后,会自动进行模拟操作测试集这20个交易日,然后会输出这20个交易日的测试结果:
------------------------------ Step: 20 Balance: 0.713083354256014 Shares held: 2060 (Total sold: 2392) Avg cost for held shares: 5.072161917927474 (Total sales value: 12195.091008936648) Net worth: 10930.56492977963 (Max net worth: 10930.56492977963) Profit: 930.5649297796299 ------------------------------ Step: 21 Balance: 0.713083354256014 Shares held: 2060 (Total sold: 2392) Avg cost for held shares: 5.072161917927474 (Total sales value: 12195.091008936648) Net worth: 10815.713083354256 (Max net worth: 10930.56492977963) Profit: 815.713083354256
利润图如下:

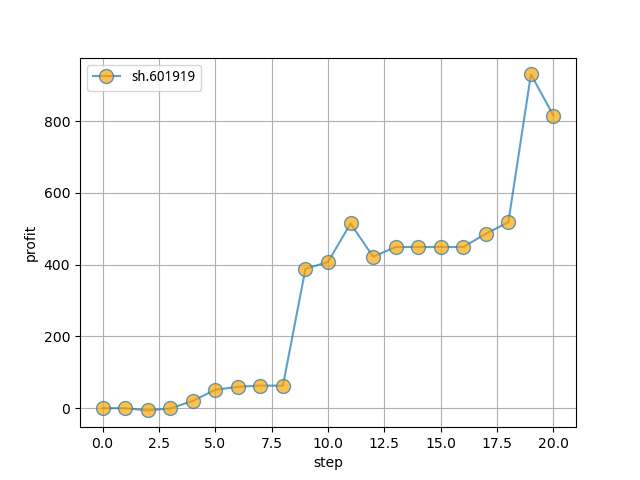
然后我们看一下中远海控2019年12月的走势:

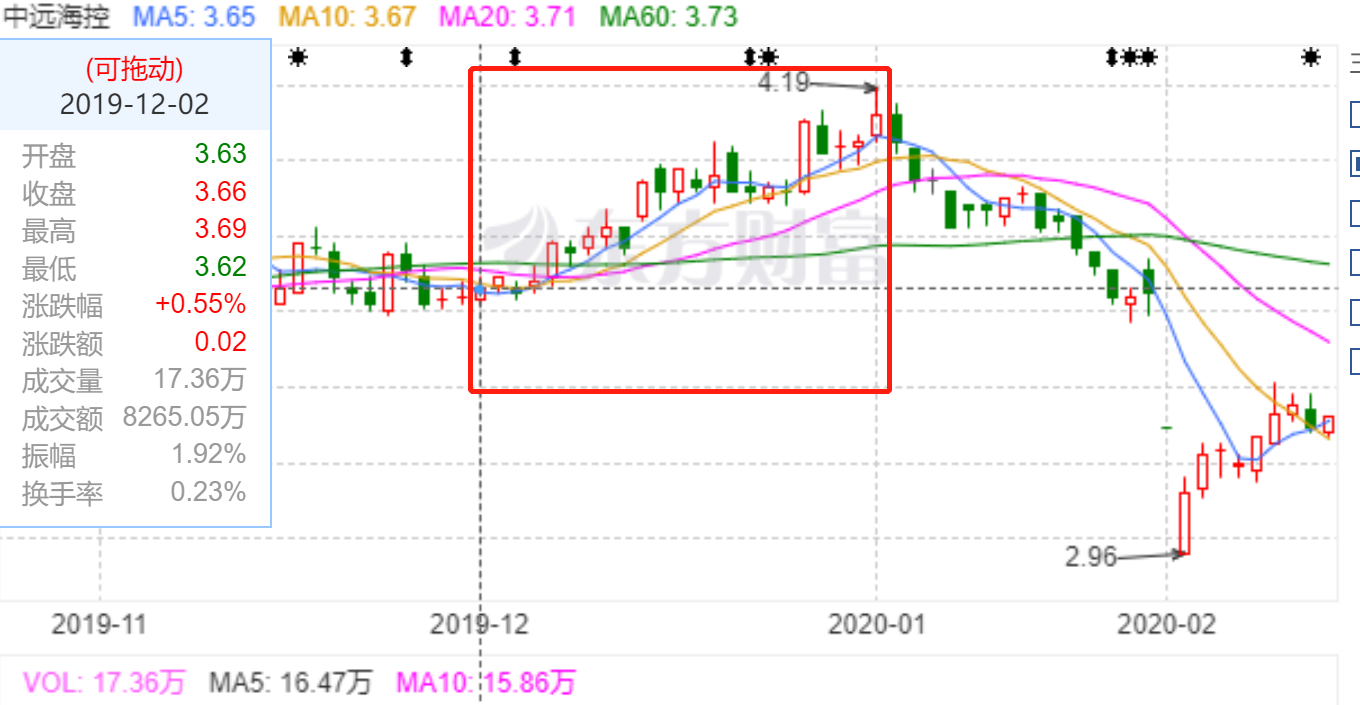
可以看到这个月的中远海控是一个上升趋势,一共上涨了12%,而这个模型捕捉到其中8%左右的利润,还是相当不错的。当然,凡事不能只看个体,下面我们修改下作者的源代码,试一下其在市场里的整体表现。
3.强化学习模型整体表现
由于作者原有的模型是单进程的计算,为了测试全市场的表现,我进行了多进程改造。
我将作者的训练及测试任务集成到一个函数中,并使用celery做并行:
@app.task
def multi_stock_trade(code):
stock_file = find_file('./stockdata/train', str(code))
if stock_file:
try:
profits = stock_trade(stock_file)
with open(f'result/code-{code}.pkl', 'wb') as f:
pickle.dump(profits, f)
except Exception as err:
print(err)将测试集的测试周期改为最近一个月:
1990-01-01 ~ 2021-11-25 | 2021-11-26 ~ 2021-12-25 |
|---|---|
| 训练集 | 测试集 |
开启redis-server 及 Celery Worker:
# redis-server 独占一个进程,所以需要另开一个窗口 celery -A tasks worker -l info
遍历所有的股票代码做并发测试:
files = os.listdir("stockdata/train")
files_test = os.listdir("stockdata/test")
all_files_list = list(set(files) & set(files_test))
for i in all_files_list:
# 使用celery做并发
code = ".".join(i.split(".")[:2])
# multi_stock_trade.apply_async(args=(code,))
multi_stock_trade(code)再对生成的结果进行统计,测试结果如下:

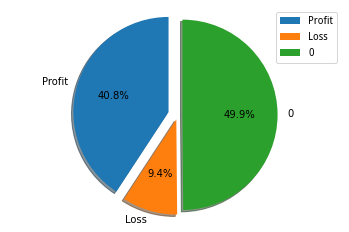
对这个模型在2021-11-26到2021-12-25的测试结果表明,有40.8%的股票进行了交易并且获利,有49.9%的股票没有进行操作,有9.4%的股票进行了交易并亏损。平均每次交易利润为445元,作为一个测试策略,这个结果已经很不错了。
由于只是一个测试策略,这里就不做详细的风险分析了,实际上我们还需要观察这个策略的最大回撤率、夏普率等指标才能更好地评判此策略的好坏。
我认为这个项目还有很大的改造空间,原逻辑中只观察了OHLC等基本数据,我们还可以增加很多指标,比如基于Ta-lib,算出MACD、RSI等技术指标,再将其加入Observation中,让模型观察学习这些数据的特征,可能会有不错的表现。有兴趣的同学可以试一下,本文源代码存放于:
https://github.com/Ckend/pythondict-quant
我们的文章到此就结束啦,如果你喜欢今天的 Python 教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 ( pythondict.com )
不只是一个宝典
欢迎关注公众号:Python实用宝典

