

最近要做一个关于自动从微博等短文本数据中判断人是否有自杀倾向的项目,在这之前需要先收集许多具有自杀倾向的人发的微博或短文本数据作为训练集。
其实这样的数据是挺难找的,尤其是对于我这种需求量比较大的项目。不过好在最后发现了突破口:“微博树洞”。“微博树洞”是指宣告了自杀行为的过世的人的微博,其留言区成为成千上万的抑郁症或是绝望的人的归属,在其下方发布许多负能量甚至是寻死的宣言。
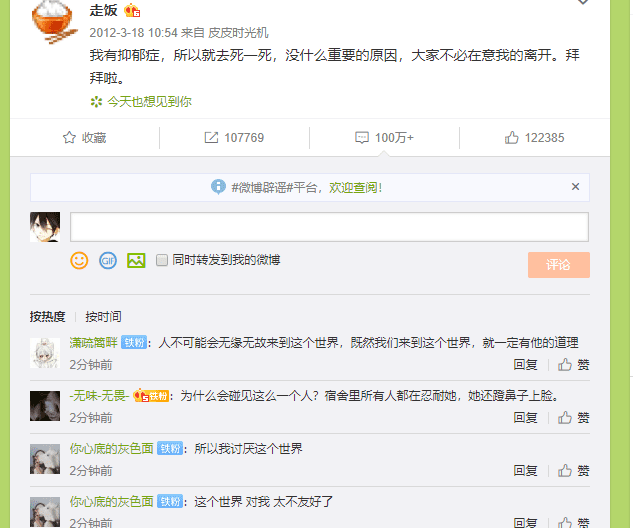
比如走饭的微博:

1.找到微博评论数据接口
微博评论的数据接口有两种,一种是手机版、一种是PC版。手机版能爬到的数据仅仅只有十五页,因此我们从PC版入手,先来看看PC版的接口怎么找,长啥样儿。
首先,在当前微博的页面右键—检查(F12)打开开发者工具,然后按照下图的步骤进行操作(选择NetWork—选择XHR—随便点击另一个评论页—查看右侧新增的请求):

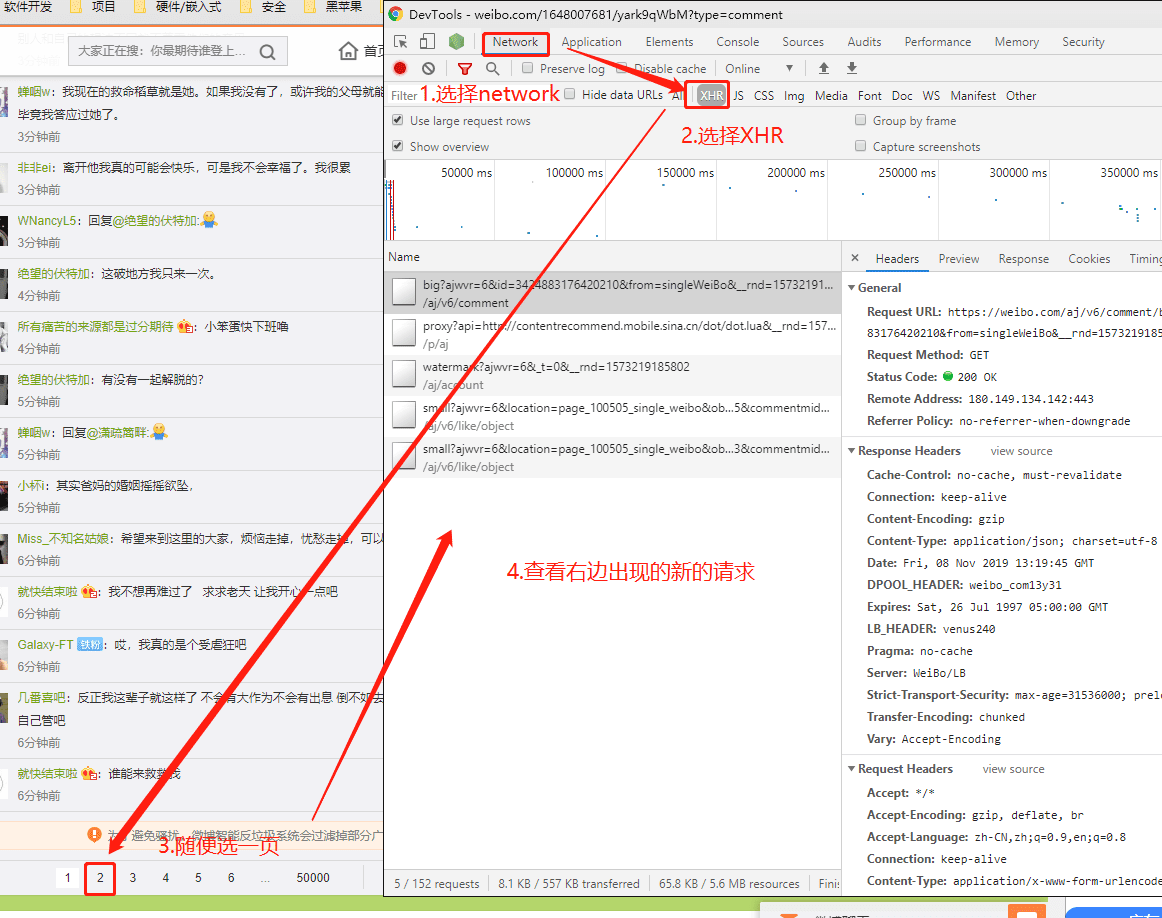
然后我们看新增的请求,你会发现在Preview中能看到格式化后的数据,而且里面有个html,仔细观察这个html你会发现这个就是评论列表的数据。我们仅需要将这个html解析出来即可。


再看看get请求的URL:
https://weibo.com/aj/v6/comment/big?ajwvr=6&id=3424883176420210&page=2&__rnd=1573219876141
ajwvr是一个固定值为6、id是指想要爬取评论的微博id、page是指第几页评论、_rnd是请求时的毫秒级时间戳。
不过微博是要求登录才能看更多评论的,因此我们需要先访问微博,拿到cookie的值才能开始爬。
2.编写爬虫
关注文章最下方的Python实用宝典,回复微博评论爬虫即可获得本项目的完整源代码。
设定四个参数:
params = {
'ajwvr': 6,
'id': '3424883176420210',
'page': 1,
'_rnd': int(round(time.time() * 1000))
} 设定cookie:
headers = {
'X-Requested-With': 'XMLHttpRequest',
'Cookie': '你的微博cookie',
} 发送请求并解析数据
URL = 'https://weibo.com/aj/v6/comment/big'
for num in range(1,51,1):
print(f'============== 正在爬取第 {num} 页 ====================')
params['page'] = num
params['_rnd'] = int(round(time.time() * 1000))
resp = requests.get(URL, params=params, headers=headers)
resp = json.loads(resp.text) 解析这串HTML中我们所需要的数据,这里用到了XPATH,如果你还不了解XPATH,可以看这篇文章: 学爬虫利器XPath,看这一篇就够了
if resp['code'] == '100000':
html = resp['data']['html']
html = etree.HTML(html)
data = html.xpath('//div[@node-type="comment_list"]')
for i in data:
# 评论人昵称
nick_name = i.xpath('.//div[@class="WB_text"]/a[1]/text()')
# 评论内容
text = i.xpath('.//div[@class="WB_text"]')
text = [i.xpath('string(.)') for i in text]
# 头像地址
pic_url = i.xpath('.//div[@class="WB_face W_fl"]/a/img/@src')
print(len(nick_name),len(text),len(pic_url))
write_comment([i.strip() for i in text], pic_url, nick_name) 其中写入文件的函数和下载图片的函数如下:
# 下载图片
def download_pic(url, nick_name):
if not url:
return
if not os.path.exists(pic_file_path):
os.mkdir(pic_file_path)
resp = requests.get(url)
if resp.status_code == 200:
with open(pic_file_path + f'/{nick_name}.jpg', 'wb') as f:
f.write(resp.content)
# 写入留言内容
def write_comment(comment, pic_url, nick_name):
f = open('comment.txt', 'a', encoding='utf-8')
for index, i in enumerate(comment):
if ':' not in i and '回复' not in i and i != '':
# 去除评论的评论
w_comment = i.strip().replace(':', '').replace('\n', '')
# 写入评论
f.write(w_comment.replace('等人', '').replace('图片评论', '')+'\n')
# 获得头像
download_pic(pic_url[index], nick_name[index]) 以上就是我们所用到的代码。在公众号后台回复 微博评论爬虫 即可下载完整源代码(附手机版爬虫)。
3.定时爬虫
尽管如此,我们得到的数据还是不够,PC版的微博评论页面也仅仅支持爬到第五十页,第五十一页后就拿不到数据了,如图:

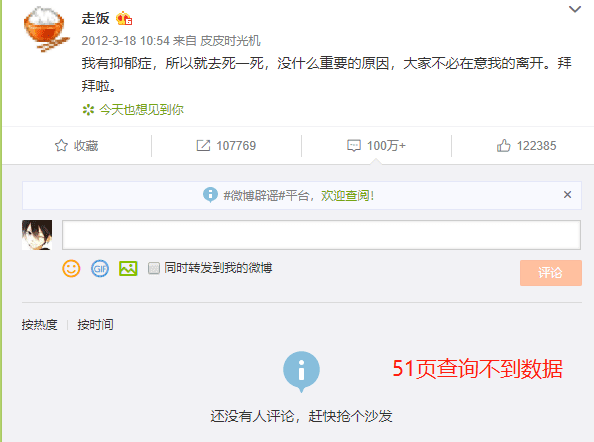
不过,走饭这个微博真的很多人回复,一天的数据就差不多50页了,我们可以通过每天定时爬50页来获取数据。linux系统可以使用crontab定时脚本实现,windows系统可以通过计划任务实现,这里讲讲crontab实现方法。
假设你的Python存放在/usr/bin/且将脚本命名为weibo.py 存放在home中,在终端输入crontab -e后,在最后面增加上这一条语句即可:
0 0 * * * /usr/bin/python /home/weibo.py
在公众号后台回复 微博评论爬虫 即可下载本文完整源代码(附手机版爬虫) 。
如果你喜欢今天的Python 教程,请持续关注Python实用宝典,如果对你有帮助,麻烦在下面点一个赞/在看哦![]()

Python实用宝典 (pythondict.com)
不只是一个宝典
欢迎关注公众号:Python实用宝典


怎么运行不了,使用的什么框架,python几点几?
在公众号后台回复 微博评论爬虫 下载完整源代码
请问爬取一条微博下面指定日期的评论应该在哪儿加什么代码呢
两张方案:
1.爬取全部评论再按实际排序筛选
2.在微博页面上找到按时间搜索评论的接口