

微博的热搜榜对于研究大众的流量有非常大的价值。今天的教程就来说说如何爬取微博的热搜榜。 热搜榜的链接是:
https://s.weibo.com/top/summary/
用浏览器浏览,发现在不登录的情况下也可以正常查看,那就简单多了。使用开发者工具(F12)查看页面逻辑,并拿到每条热搜的CSS位置,方法如下:

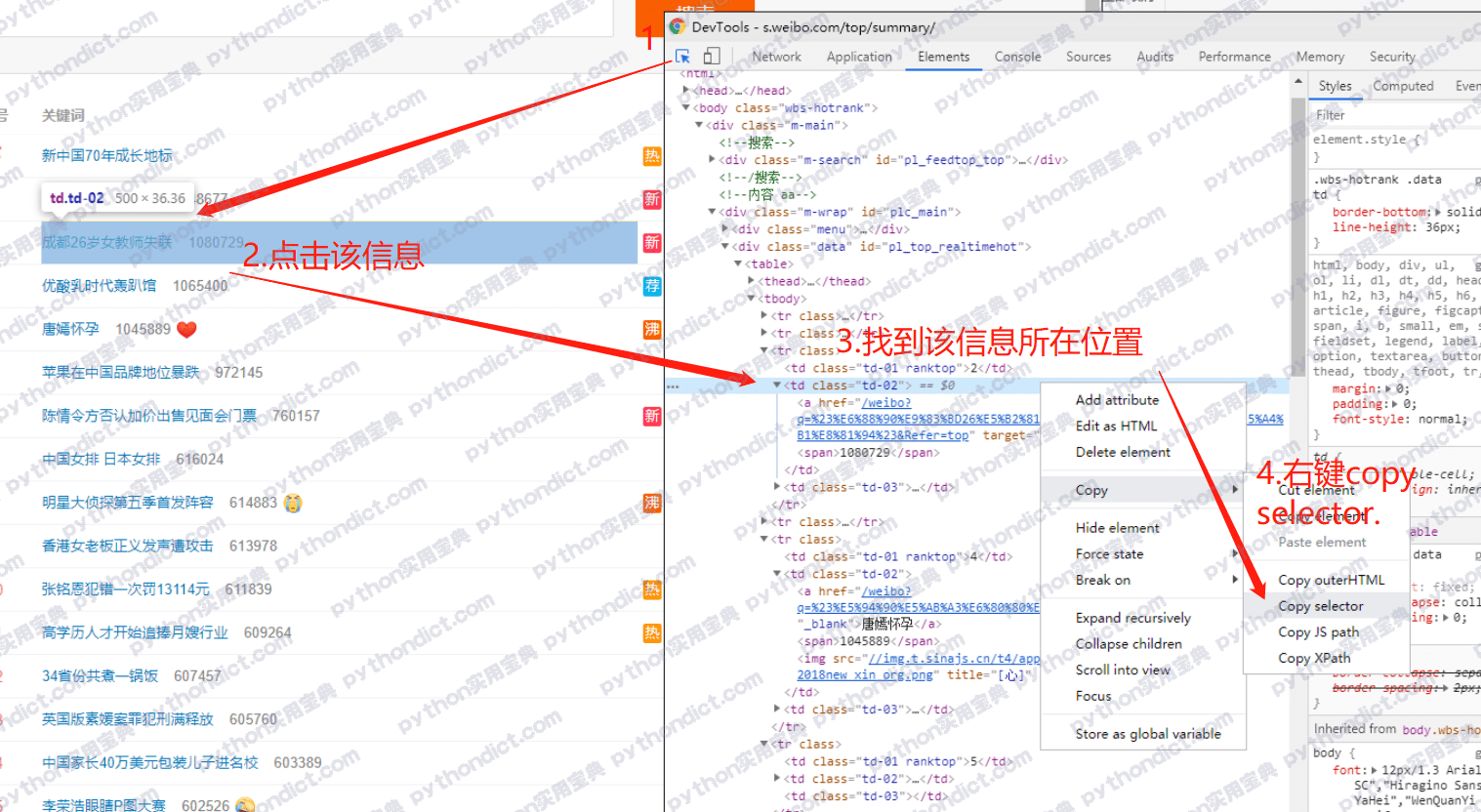
按照这个方法,拿到这个td标签的selector是:
pl_top_realtimehot > table > tbody > tr:nth-child(3) > td.td-02
其中nth-child(3)指的是第三个tr标签,因为这条热搜是在第三名的位置上,但是我们要爬的是所有热搜,因此:nth-child(3)可以去掉。
还要注意的是 pl_top_realtimehot 是该标签的id,id前需要加#号,最后变成:
#pl_top_realtimehot > table > tbody > tr > td.td-02
你可以自定义你想要爬的信息,这里我需要的信息是:热搜的链接及标题、热搜的热度。它们分别对应的CSS选择器是:
链接及标题:#pl_top_realtimehot > table > tbody > tr > td.td-02 > a
热度:#pl_top_realtimehot > table > tbody > tr > td.td-02 > span
值得注意的是链接及标题是在同一个地方,链接在a标签的href属性里,标题在a的文本中,用beautifulsoup有办法可以都拿到,请看后文代码。
现在这些信息的位置我们都知道了,接下来可以开始编写程序。默认你已经安装好了python,并能使用cmd的pip,如果没有的话请见这篇教程:python安装。需要用到的python的包有:
BeautifulSoup4 安装指令:
pip install beautifulsoup4
lxml解析器安装指令:
pip install lxml
lxml是python中的一个包,这个包中包含了将html文本转成xml对象的工具,可以让我们定位标签的位置。而能用来识别xml对象中这些标签的位置的包就是 Beautifulsoup4.
编写代码:
# https://s.weibo.com/top/summary/
import requests
from bs4 import BeautifulSoup
if __name__ == "__main__":
news = []
# 新建数组存放热搜榜
hot_url = 'https://s.weibo.com/top/summary/'
# 热搜榜链接
r = requests.get(hot_url)
# 向链接发送get请求获得页面
soup = BeautifulSoup(r.text, 'lxml')
# 解析页面
urls_titles = soup.select('#pl_top_realtimehot > table > tbody > tr > td.td-02 > a')
hotness = soup.select('#pl_top_realtimehot > table > tbody > tr > td.td-02 > span')
for i in range(len(urls_titles)-1):
hot_news = {}
# 将信息保存到字典中
hot_news['title'] = urls_titles[i+1].get_text()
# get_text()获得a标签的文本
hot_news['url'] = "https://s.weibo.com"+urls_titles[i]['href']
# ['href']获得a标签的链接,并补全前缀
hot_news['hotness'] = hotness[i].get_text()
# 获得热度文本
news.append(hot_news)
# 字典追加到数组中
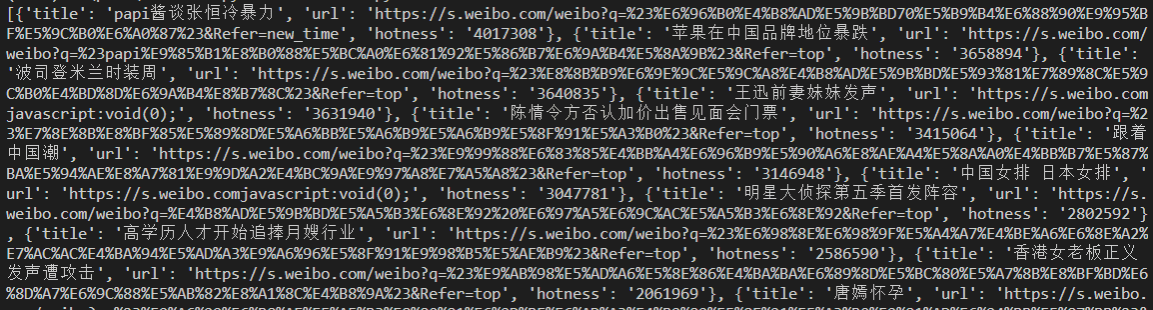
print(news)代码说明请看注释,不过这样做,我们仅仅是将结果保存到数组中,如下所示,其实不易观看,我们下面将其保存为csv文件。

import datetime
today = datetime.date.today()
f = open('./热搜榜-%s.csv'%(today), 'w', encoding='utf-8')
for i in news:
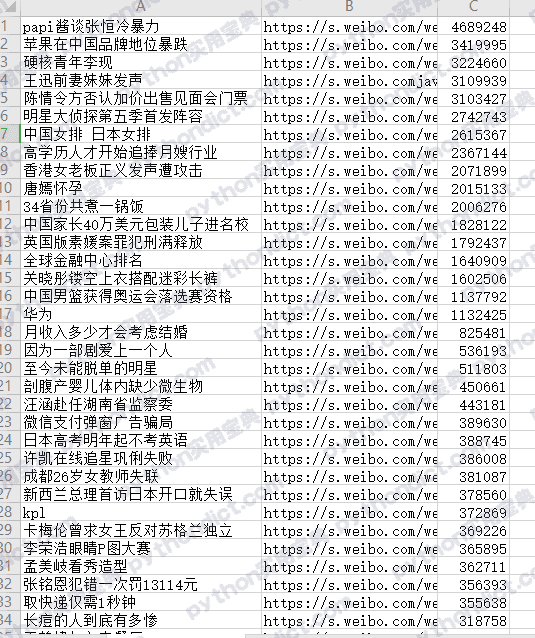
f.write(i['title'] + ',' + i['url'] + ','+ i['hotness'] + '\n')效果如下,怎么样,是不是好看很多:

完整代码如下:
# https://s.weibo.com/top/summary/
import requests
from bs4 import BeautifulSoup
if __name__ == "__main__":
news = []
# 新建数组存放热搜榜
hot_url = 'https://s.weibo.com/top/summary/'
# 热搜榜链接
r = requests.get(hot_url)
# 向链接发送get请求获得页面
soup = BeautifulSoup(r.text, 'lxml')
# 解析页面
urls_titles = soup.select('#pl_top_realtimehot > table > tbody > tr > td.td-02 > a')
hotness = soup.select('#pl_top_realtimehot > table > tbody > tr > td.td-02 > span')
for i in range(len(urls_titles)-1):
hot_news = {}
# 将信息保存到字典中
hot_news['title'] = urls_titles[i+1].get_text()
# get_text()获得a标签的文本
hot_news['url'] = "https://s.weibo.com"+urls_titles[i]['href']
# ['href']获得a标签的链接,并补全前缀
hot_news['hotness'] = hotness[i].get_text()
# 获得热度文本
news.append(hot_news)
# 字典追加到数组中
print(news)
import datetime
today = datetime.date.today()
f = open('./热搜榜-%s.csv'%(today), 'w', encoding='utf-8')
for i in news:
f.write(i['title'] + ',' + i['url'] + ','+ i['hotness'] + '\n')Python实用宝典 (pythondict.com)
不只是一个宝典
欢迎关注公众号:Python实用宝典


我爬出来为啥是乱码?
乱码一般是编码出现问题,如果是Excel里变成乱码,且print正常显示中文的话,说明可能是Excel读取的默认编码有问题,可以改一下文件的编码为gb2312试一下。可参考:https://www.zhihu.com/question/21869078
提示 request不存在 如下 楞个办哦?
Traceback (most recent call last):
File “C:/Users/Administrator/PycharmProjects/untitled/weibo.py”, line 2, in
import requests
ImportError: No module named ‘requests’
Process finished with exit code 1
没有requests模块,打开CMD 输入以下命令安装:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple requests
啊大佬 cmd指令输进去提示已经安装了requests,通过pip list也能看到requests已经安装了 , 但是运行pycharm代码还是提示和之前一样, 如下
Traceback (most recent call last):
File “C:/Users/Administrator/PycharmProjects/untitled/weibo.py”, line 2, in
import requests
ModuleNotFoundError: No module named ‘requests’
Process finished with exit code 1
该如何是好
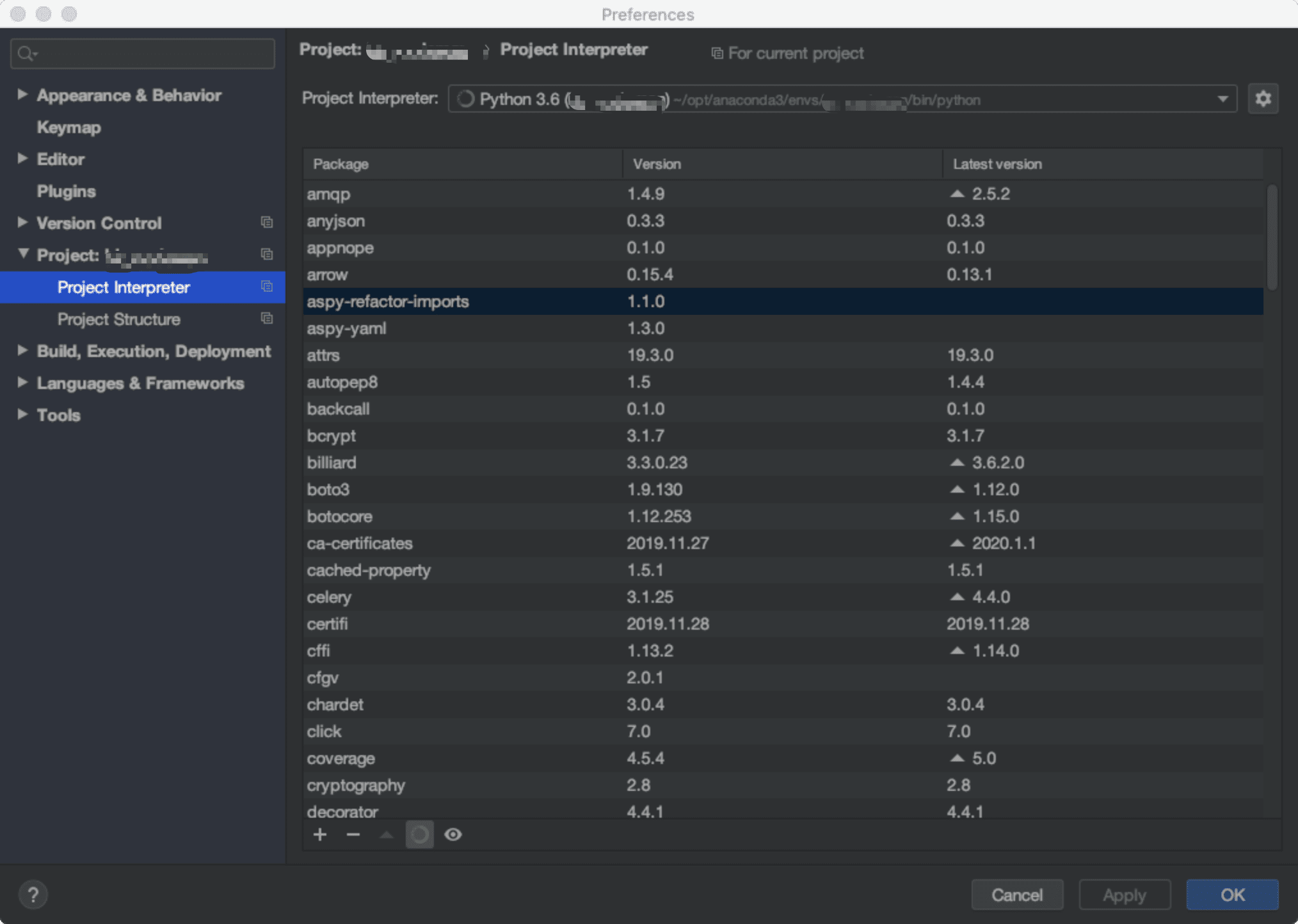
有可能你的Pycharm里的Python是另一个环境和CMD的默认环境不同,建议你直接在设置里安装模块,点+号即可:

感谢!!不过最后数据还是一堆乱放着的,您这个是导出了Excel表吗?我照着代码进去运行之后还是一样乱,没有变哎