

新浪微博的数据可是非常有价值的,你可以拿来数据分析、拿来做网站、甚至是*****。不过很多人由于技术限制,想要使用的时候只能使用复制粘贴这样的笨方法。没关系,现在就教大家如何批量爬取微博的数据,大大加快数据迁移速度!
我们使用到的是第三方作者开发的爬虫库weiboSpider(有工具当然要用工具啦)。这里默认大家已经装好了Python,如果没有的话可以看我们之前的文章:Python详细安装指南。
1. 下载项目
进入下方的网址,点击Download ZIP下载项目文件
https://github.com/dataabc/weiboSpider


或者
你有git的话可以在cmd/terminal中输入以下命令安装
git clone https://github.com/dataabc/weiboSpider.git
2.安装依赖
将该项目压缩包解压后,打开你的cmd/Termianl进入该项目目录,输入以下命令:
pip install -r requirements.txt
便会开始安装项目依赖,等待其安装完成即可。
打开weibospider文件夹下的weibospider.py文件,将”your cookie”替换成爬虫微博的cookie,具体替换位置大约在weibospider.py文件的22行左右。cookie获取方法:
3.1 登录微博

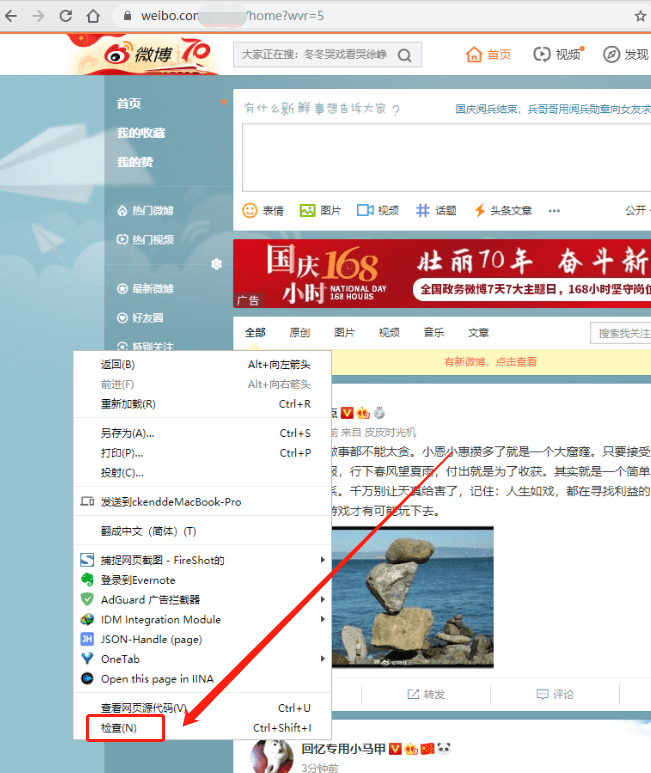
3.2 按F12键或者右键页面空白处—检查,打开开发者工具

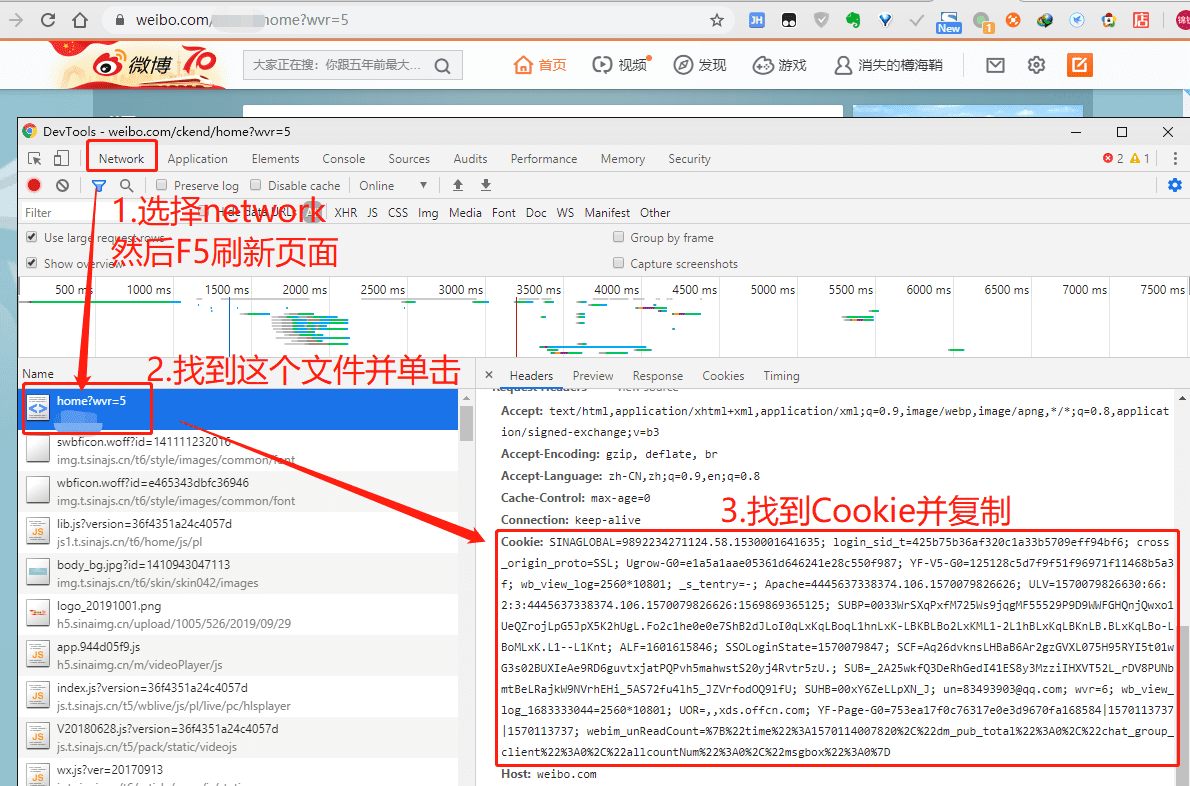
3.3 选择network — 按F5刷新一下 — 选择第一个文件 — 在右边窗口找到cookie

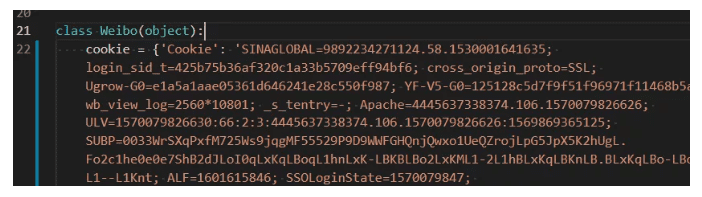
然后替换大约在weibospider.py文件的22行左右的cookie,如图所示:
替换前:


替换后:

4.设置要爬的用户user_id
4.1 获取user_id
点开你希望爬取的用户主页,然后查看此时的url:
你会发现有一串数字在链接中,这个就是我们要用到的userID, 复制即可。

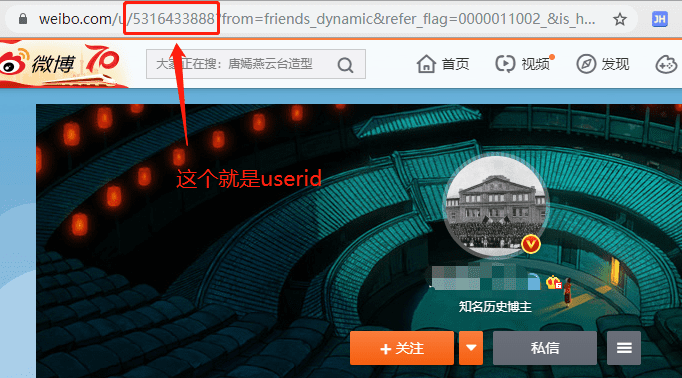
4.2 设置要爬取的user_id
打开config.json文件,你会看到如下内容:
{
"user_id_list": ["1669879400"],
"filter": 1,
"since_date": "2018-01-01",
"write_mode": ["csv", "txt"],
"pic_download": 1,
"video_download": 1,
"cookie": "your cookie",
"mysql_config": {
"host": "localhost",
"port": 3306,
"user": "root",
"password": "123456",
"charset": "utf8mb4"
}
}下面讲解每个参数的含义与设置方法。
设置user_id_list
user_id_list是我们要爬取的微博的id,可以是一个,也可以是多个,例如:
"user_id_list": ["1223178222", "1669879400", "1729370543"],
上述代码代表我们要连续爬取user_id分别为“1223178222”、 “1669879400”、 “1729370543”的三个用户的微博。
user_id_list的值也可以是文件路径,我们可以把要爬的所有微博用户的user_id都写到txt文件里,然后把文件的位置路径赋值给user_id_list。
在txt文件中,每个user_id占一行,也可以在user_id后面加注释(可选),如用户昵称等信息,user_id和注释之间必需要有空格,文件名任意,类型为txt,位置位于本程序的同目录下,文件内容示例如下:
1223178222 胡歌 1669879400 迪丽热巴 1729370543 郭碧婷
假如文件叫user_id_list.txt,则user_id_list设置代码为:
"user_id_list": "user_id_list.txt",
如果有需要还可以设置Mysql数据库和MongoDB数据库写入,如果不设置的话就默认写入到txt和csv文件中。
5. 运行爬虫
打开cmd/terminal 进入该项目目录,输入:
python weibospider.py
即可开始爬取数据了,怎么样,是不是超级方便?而且你还可以自定义爬取的信息,比如微博的起始时间、是否写入数据库,甚至能在它代码的基础上增加新的功能!(比如加个cookie池或者代理池之类的)
我们的文章到此就结束啦,如果你希望我们今天的Python 教程,请持续关注我们,如果对你有帮助,麻烦在下面点一个赞/在看哦![]()

Python实用宝典 (pythondict.com)
不只是一个宝典
欢迎关注公众号:Python实用宝典


大佬我这个运行之后提示错误 是怎么回事
Error: ‘1221045561’
Traceback (most recent call last):
File “C:/Users/Administrator/Desktop/weiboSpider-master/weiboSpider.py”, line 1108, in main
wb = Weibo(config)
File “C:/Users/Administrator/Desktop/weiboSpider-master/weiboSpider.py”, line 41, in __init__
user_id_list = config[‘1221045561’]
KeyError: ‘1221045561’
看下我刚修改好的文章,你改在config.json里了吗?
config.json里的代码我没动 然后全程是在weibospider.py中改了cookie和user ID,点运行之后就是这样报错了
对,新版的userID要在config.json里改
啊啊 config.json里是只改userID就可以了吗
是的
还是不行啊 完全按照您这个步骤来的 config.json里也改了 并且运行错误几次之后我网页点开想爬取用户的主页居然发现地址栏没有该用户的ID了???地址栏整个长度也很短,是微博的反扒机制???求大佬指教 我是python小白
报错了显示什么?请求次数过多是会被block掉的,过几个小时就好了
和之前的报错一样 config.json里的id我改过的
Traceback (most recent call last):
File “C:/Users/Administrator/Desktop/weiboSpider-master/weiboSpider.py”, line 1108, in main
wb = Weibo(config)
File “C:/Users/Administrator/Desktop/weiboSpider-master/weiboSpider.py”, line 41, in __init__
user_id_list = config[‘1221045561’]
KeyError: ‘1221045561’
是不是之前改了源代码了?改回原样就行,建议从github上重新拉一个项目下来,只改config.json和Cookie
刚刚试过 还是报错 这次报错和最开始报错的提示是一样的
Traceback (most recent call last):
File “C:/Users/Administrator/Desktop/w000eiboSpider-master/weiboSpider-master/weiboSpider.py”, line 1108, in main
wb = Weibo(config)
File “C:/Users/Administrator/Desktop/w000eiboSpider-master/weiboSpider-master/weiboSpider.py”, line 39, in __init__
self.cookie = {‘Cookie’: config[‘SINAGLOBAL=7387469940568.376.1573559486477; U……..这部分就是自己cookie那部分 太长了评论交不了…….; TC-Page-G0=8dc78264df14e433a87ecb460ff08bfe|1583302258|1583302138’
Process finished with exit code 0
Cookie是新的吗,会不会过期了?
啥意思?我从网页沾过来cookie立马就放进去开始运行呀 这个过程cookie就过期了吗 那该怎么粘贴?
那按道理不会这样,我晚上看一下,你可以先看看无cookie版的,试试能不能用:https://github.com/dataabc/weibo-crawler
好的 感谢大佬!有劳!!
大佬为什么我找不到weibospider.py的文件啊,求帮助
作者把文件夹改成weibo_spider了,weibospider.py被拆分成了两个文件,cookie要修改config_sample.json内的内容,还有许多修改,这篇文章需要做更新,你可以等我更新。
好的,我等大佬更新,比较急,还希望大佬能抽点时间,谢谢了!!!
大佬,什么时候更新?