

[download_code]
原文:python 小文件下载、大文件下载、异步批量下载 教程
按照不同的情况,python下载文件可以分为三种:
- 小文件下载
- 大文件下载
- 批量下载
python 小文件下载
流程:使用request.get请求链接,返回的内容放置到变量r中,然后将r写入到你想放的地方。


以下载上述流程图为例子:
# 例1
import requests
def request_zip(url):
r = requests.get(url)
# 请求链接后保存到变量r中
with open("new/名字.png",'wb') as f:
# r.content写入至文件
f.write(r.content)
request_zip('https://pythondict.com/wp-content/uploads/2019/08/2019082807222049.png')
运行完毕后,它将会被保存到当前文件夹的new文件夹里。
python 大文件下载
我们在小文件下载的时候,是将文件内容暂存到变量里,大家想想,下载大文件的时候还这样做会有什么问题![]()

流式分块下载
原理:一块一块地将内存写入到文件中,以避免内存占用过大。

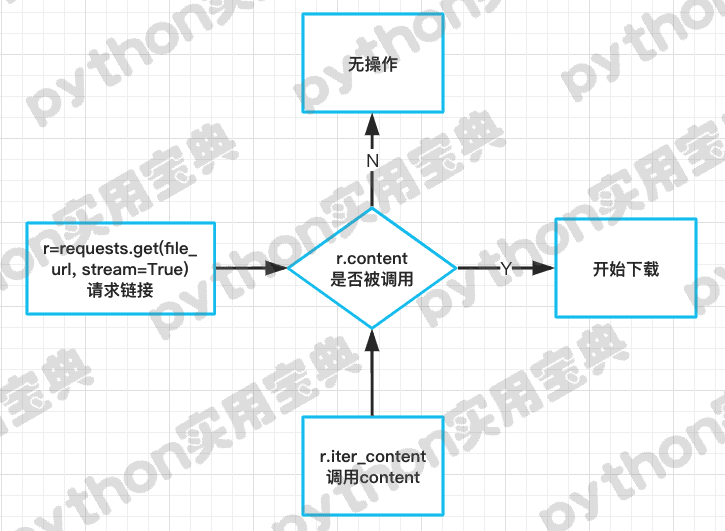
当设置了request.get(stream=True)的时候,就是启动流模式下载,典型特征:在r变量的content被调用的时候才会启动下载。代码如下:
# 例2
import requests
def request_big_data(url):
name = url.split('/')[-1]
# 获取文件名
r = requests.get(url, stream=True)
# stream=True 设置为流读取
with open("new/"+str(name), "wb") as pdf:
for chunk in r.iter_content(chunk_size=1024):
# 每1024个字节为一块进行读取
if chunk:
# 如果chunk不为空
pdf.write(chunk)
request_big_data(url="https://www.python.org/ftp/python/3.7.4/python-3.7.4-amd64.exe")
Python 批量文件下载
所谓批量下载,当然不是一个一个文件的下载了,比如说我们要下载百度图片,如果一个一个下载会出现两种负面情况:
- 如果某个请求堵塞,整个队列都会被堵塞
- 如果是小文件,单线程下载太慢
我们的解决方案是使用异步策略。如果你会用scrapy框架,那就轻松许多了,因为它结合了twisted异步驱动架构,根本不需要你自己写异步。不过我们python实用宝典讲的可是教程,还是跟大家说一下怎么实现异步下载![]()

我们需要使用到两个包,一个是asyncio、一个是aiohttp. asyncio是Python3的原装库,但是aiohttp则需要各位使用cmd/Terminal打开,输入以下命令安装:
pip install aiohttp
注意asyncio是单进程并发库,不是多线程,也不是多进程,单纯是在一个进程里面异步(切来切去运行),切换的地方用await标记,能够切换的函数用async标记。比如下载异步批量下载两个图片的代码如下:
# 例3
import aiohttp
import asyncio
import time
async def job(session, url):
# 声明为异步函数
name = url.split('/')[-1]
# 获得名字
img = await session.get(url)
# 触发到await就切换,等待get到数据
imgcode = await img.read()
# 读取内容
with open("new/"+str(name),'wb') as f:
# 写入至文件
f.write(imgcode)
return str(url)
async def main(loop, URL):
async with aiohttp.ClientSession() as session:
# 建立会话session
tasks = [loop.create_task(job(session, URL[_])) for _ in range(2)]
# 建立所有任务
finished, unfinished = await asyncio.wait(tasks)
# 触发await,等待任务完成
all_results = [r.result() for r in finished]
# 获取所有结果
print("ALL RESULT:"+str(all_results))
URL = ['https://pythondict.com/wp-content/uploads/2019/07/2019073115192114.jpg',
'https://pythondict.com/wp-content/uploads/2019/08/2019080216113098.jpg']
loop = asyncio.get_event_loop()
loop.run_until_complete(main(loop, URL))
loop.close()
注意: img = await session.get(url)
这时候,在你请求第一个图片获得数据的时候,它会切换请求第二个图片或其他图片,等第一个图片获得所有数据后再切换回来。从而实现多线程批量下载的功能,速度超快,下载超清大图用这个方法可以一秒一张![]()
我们的文章到此就结束啦,如果你希望我们今天的Python 教程,请持续关注我们,如果对你有帮助,麻烦在下面点一个赞/在看哦![]()
