
本文重点在于讲解什么是REST规范及Django RestFramework中的APIview请求流程,这个流程包括源代码分析和后续的解析器组件及序列化器组件。
1.什么是REST
编程是数据结构和算法的结合,而在Web类型的App中,我们对于数据的操作请求是通过url来承载的,本文详细介绍了REST规范和CBV请求流程。
编程是数据结构和算法的结合,小程序如简单的计算器,我们输入初始数据,经过计算,得到最终的数据,这个过程中,初始数据和结果数据都是数据,而计算过程是我们所说的广义上的算法。
大程序,如一个智能扫地机器人,我们可以设置打扫的距离,左右摆动的幅度来打扫房间,这里面打扫的举例,摆动幅度,都是数据,而打扫的过程是较为复杂的算法过程,总之,也是算法,即程序的实现方式。
另外,我们还可以设置打扫时间等等初始数据。
总之一句话,编程即数据结构和算法的结合。简单的程序可能不需要跟用户交互数据,但是现代的应用程序几乎都需要跟用户进行交互,不分应用程序类型,不管是CS型还是BS型的程序都是如此,而Python最擅长的Web App即BS型的程序,就是通过url和http来跟用户进行数据交互的,通过url和http请求,用户可以操作服务器端的程序,主要操作分为:增、删、改、查几类。
引入
在开始之前,我们回顾一下咱们之前写过的图书管理系统项目,请仔细回想一下,对于该项目的设计,我们大概是以下面这种方式来实现的
传统url设计风格
- url各式各样,设计混乱

理论上来说,这种方式完全可以实现我们的需求,但是一旦项目丰富起来,随着数据量增加,随着各个业务系统之间的逻辑关系不断的复杂,url会越来越复杂,理论上来说,不管是什么类型、什么名称的url都能指向具体的业务逻辑(视图函数),从而实现业务需求,但是如果没有明确的规范,因每个人的思维方式不一样、命名方式不一样而导致的url非常的乱,不方便项目的后期维护和扩展。
- 对于请求处理成功或者失败的返回信息没有明确的响应信息规范,返回给客户端的信息往往都是很随意的
以上这些情况的出现,导致了很多的问题,让互联网的世界变得杂乱不堪,日益复杂且臃肿。
因此http协议创始人警告我们这些凡人们正在错误的使用http协议,除了警告,他还发表了一篇博客,大概意思就是教大家如何正确使用http协议,如何正确定义url,这就是REST(Representational State Transfer),不需要管这几个英文单词代表什么意思,只需要记住下面一句话:
- 用url唯一定位资源,用Http请求方式(GET, POST, DELETE, PUT)描述用户行为
根据这句话,我们重新定义图书管理系统中的url
RESTful Api设计风格

可以看到,url非常简洁优雅,不包含任何操作,不包含任何动词,简简单单,用来描述服务器中的资源而已,服务器根据用户的请求方式对资源进行各种操作。而对数据的操作,最常见的就是CRUD(创建,读取,更新,删除),通过不同的请求方式,就足够描述这些操作方式了。
如果不够用,Http还有其他的请求方式呢!比如:PATCH,OPTIONS,HEAD, TRACE, CONNECT。
REST定义返回结果

每一种请求方式的返回结果不同。
REST定义错误信息
{
"error": "Invalid API key"
}通过一个字典,返回错误信息。
这就是REST,上图中的url就是根据REST规范进行设计的RESTful api。
因此REST是一种软件架构设计风格,不是标准,也不是具体的技术实现,只是提供了一组设计原则和约束条件。
它是目前最流行的 API 设计规范,用于 Web 数据接口的设计。2000年,由Roy Fielding在他的博士论文中提出,Roy Fielding是HTTP规范的主要编写者之一。
那么,我们所要讲的Django RestFramework与rest有什么关系呢?
其实,DRF(Django RestFramework)是一套基于Django开发的、帮助我们更好的设计符合REST规范的Web应用的一个Django App,所以,本质上,它是一个Django App。
2.为什么使用DRF
从概念就可以看出,有了这样的一个App,能够帮助我们更好的设计符合RESTful规范的Web应用,实际上,没有它,我们也能自己设计符合规范的Web应用。下面的代码演示如何手动实现符合RESTful规范的Web应用。
class CoursesView(View):
def get(self, request):
courses = list()
for item in Courses.objects.all():
course = {
"title": item.title,
"price": item.price,
"publish_date": item.publish_date,
"publish_id": item.publish_id
}
courses.append(course)
return HttpResponse(json.dumps(courses, ensure_ascii=False))如上代码所示,我们获取所有的课程数据,并根据REST规范,将所有资源的通过对象列表返回给用户。
可见,就算没有DRF我们也能够设计出符合RESTful规范的接口甚至是整个Web App,但是,如果所有的接口都自定义,难免会出现重复代码,为了提高工作效率,我们建议使用优秀的工具。
DRF就是这样一个优秀的工具,另外,它不仅仅能够帮助我们快速的设计符合REST规范的接口,还提供诸如认证、权限等等其他的强大功能。
什么时候使用DRF?
前面提到,REST是目前最流行的 API 设计规范,如果使用Django开发你的Web应用,那么请尽量使用DRF,如果使用的是Flask,可以使用Flask-RESTful。
3.Django View请求流程
首先安装Django,然后安装DRF:
pip install django pip install djangorestframework
安装完成之后,我们就可以开始使用DRF框架来实现咱们的Web应用了,本篇文章包括以下知识点:
- APIView
- 解析器组件
- 序列化组件
介绍DRF,必须要介绍APIView,它是重中之重,是下面所有组件的基础,因为所有的请求都是通过它来分发的,至于它究竟是如何分发请求的呢?
想要弄明白这个问题,我们就必须剖析它的源码,而想要剖析DRF APIView的源码,我们需要首先剖析django中views.View类的源码,为什么使用视图类调用as_view()之后,我们的请求就能够被不同的函数处理呢?
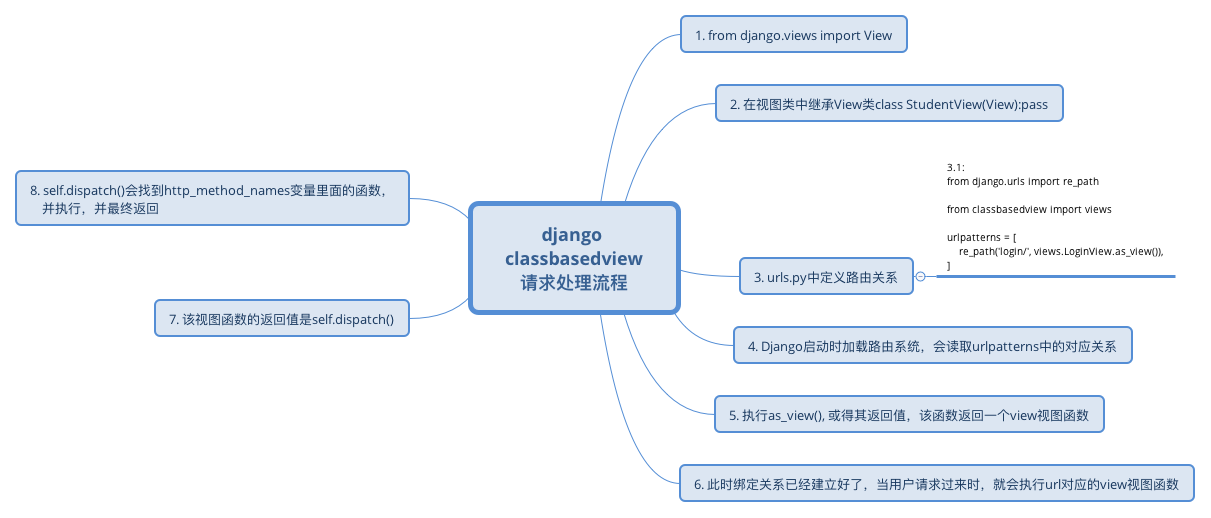
源码中最后会通过getattr在self中查找request.method.lower(),也就是get、post或者delete这些方法中的一个,那么,self是谁,就是至关重要的一点,前面讲到过,谁调用类中的方法,self就指向谁,此时,一层层往回找,我们会发现,self = cls(**initkwargs),self就是我们视图类的实例化对象,所以,dispatch函数肯定会到该视图类中找对应的方法(get或者post)。
接下来是提问时间,请问如果有如下函数,不修改函数内容的情况下,如何给函数新增一个统计执行时间的功能:
def outer(func):
def inner(*args, **kwargs):
import time
start_time = time.time()
ret = func(*args, **kwargs)
end_time = time.time()
print("This function elapsed %s" % str(end_time - start_time))
return ret
return inner
@outer
def add(x, y):
return x + y这是函数,如果是类呢?面向对象编程,如何扩展你的程序,比如有如下代码:
class Person(object):
def show(self):
print("Person's show method executed!")
class MyPerson(Person):
def show(self):
print("MyPerson's show method executed")
super().show()
mp = MyPerson()
mp.show()这就是面向对象的程序扩展,现在大家是否对面向对象有了更加深刻的认识呢?接下来给大家十分钟时间,消化一下上面两个概念,然后请思考,那么假设你是Django RestFramework的开发者,你想自定制一些自己想法,如何实现。
好了,相信大家都已经有了自己的想法,接下来,我们一起来分析一下,Django RestFramework的APIView是如何对Django框架的View进行功能扩展的。
from django.shortcuts import HttpResponse
import json
from .models import Courses
# 引入APIView
from rest_framework.views import APIView
# Create your views here.
class CoursesView(APIView): # 继承APIView而不是原来的View
def get(self, request):
courses = list()
for item in Courses.objects.all():
course = {
"title": item.title,
"description": item.description
}
courses.append(course)
return HttpResponse(json.dumps(courses, ensure_ascii=False))
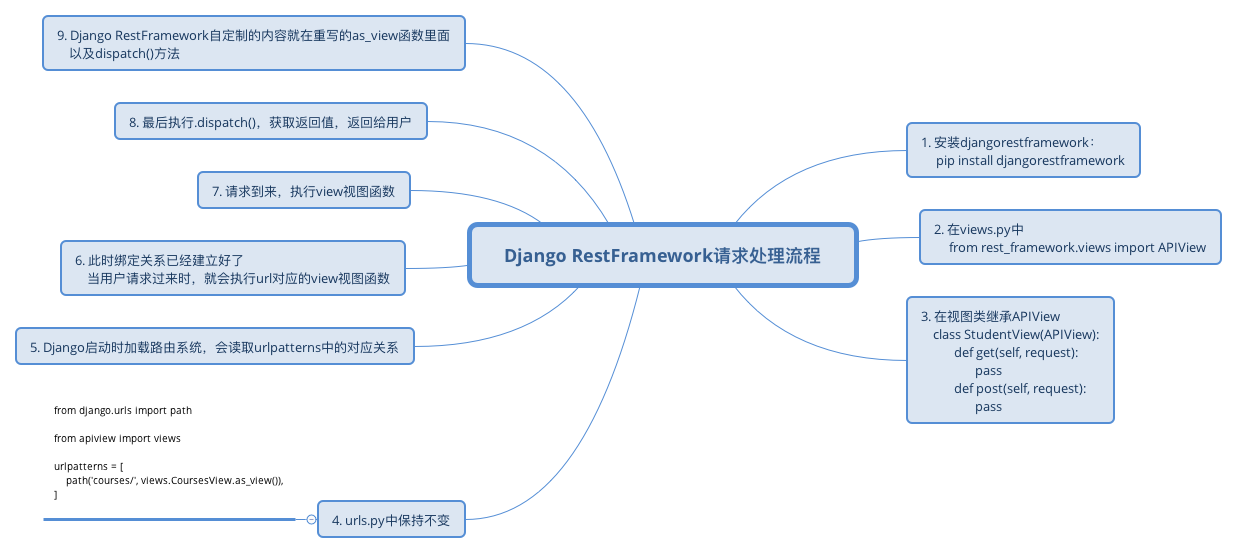
以上就是Django RestFramework APIView的请求处理流程,我们可以通过重写dispatch()方法或者重写as_view()方法来自定制自己的想法。
那么,Django RestFramework到底自定制了哪些内容呢?在本文的最开始,我们已经介绍过了,就是那些组件,比如解析器组件、序列化组件、权限、频率组件等。
Ajax发送Json数据给服务器
接下来,我们就开始介绍Django RestFramework中的这些组件,首先,最基本的,就是解析器组件,在介绍解析器组件之前,我提一个问题,请大家思考,如何发送Json格式的数据给后端服务器?
好了,时间到,请看下面的代码,通过ajax请求,我们可以发送json格式的数据到后端:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<script src="https://cdn.bootcss.com/jquery/3.3.1/jquery.min.js"></script>
<script src="/static/jquery-1.10.2.min.js"></script>
</head>
<body>
<form action="" method="post" enctype="application/x-www-form-urlencoded">
{% csrf_token %}
用户名: <input type="text" name="username"/>
密码: <input type="password" name="password"/>
提交: <input type="submit" value="提交"/>
</form>
<hr>
<button class="btn">点击发送Ajax请求</button>
<script>
$(".btn").click(function () {
$.ajax({
url: '',
type: 'post',
contentType: 'application/json',
data: JSON.stringify({
username: "alex",
password: 123
}
),
success: function (data) {
console.log(data);
}
})
})
</script>
</body>
</html>通过上文的知识点复习我们已经知道,Content-Type用来定义发送数据的编码协议,所以,在上面的代码中,我们指定Content-Type为application/json,即可将我们的Json数据发送到后端,那么后端如何获取呢?
服务器对Json数据的处理方式
按照之前的方式,我们使用request.POST, 如果打印该值,会发现是一个空对象:request post <QueryDict: {}>,该现象证明Django并不能处理请求协议为application/json编码协议的数据,我们可以去看看request源码,可以看到下面这一段:
if self.content_type == 'multipart/form-data':
if hasattr(self, '_body'):
# Use already read data
data = BytesIO(self._body)
else:
data = self
try:
self._post, self._files = self.parse_file_upload(self.META, data)
except MultiPartParserError:
# An error occurred while parsing POST data. Since when
# formatting the error the request handler might access
# self.POST, set self._post and self._file to prevent
# attempts to parse POST data again.
# Mark that an error occurred. This allows self.__repr__ to
# be explicit about it instead of simply representing an
# empty POST
self._mark_post_parse_error()
raise
elif self.content_type == 'application/x-www-form-urlencoded':
self._post, self._files = QueryDict(self.body, encoding=self._encoding), MultiValueDict()
else:
self._post, self._files = QueryDict(encoding=self._encoding), MultiValueDict()
可见Django原生解析器并不处理application/json编码协议的数据请求,好了,有了这样的认识之后,咱们就可以开始正式介绍DRF的解析器了,解析器,顾名思义,就是用来解析数据的请求的。
虽然Django的原生解析器不支持application/json编码协议,但是我们可以通过拿到原始的请求数据(request.body)来手动处理application/json请求,虽然这种方式不方便,也并不推荐,请看如下代码:
class LoginView(View):
def get(self, request):
return render(request, 'classbasedview/login.html')
def post(self, request):
print(request.POST) # <QueryDict: {}>
print(request.body) # b'{"username":"alex","password":123}'
data = request.body.decode('utf-8')
dict_data = json.loads(data)
username = dict_data['username']
password = dict_data['password']
return HttpResponse(json.dumps(dict_data))通过上面的代码,我们可以通过request.body手动处理application/json请求,不过,如上文所说,并不推荐。
4.DRF 解析器组件
首先,来看看解析器组件的使用,稍后我们一起剖析其源码:
from django.http import JsonResponse
from rest_framework.views import APIView
from rest_framework.parsers import JSONParser, FormParser
# Create your views here.
class LoginView(APIView):
parser_classes = [FormParser]
def get(self, request):
return render(request, 'parserver/login.html')
def post(self, request):
# request是被drf封装的新对象,基于django的request
# request.data是一个property,用于对数据进行校验
# request.data最后会找到self.parser_classes中的解析器
# 来实现对数据进行解析
print(request.data) # {'username': 'alex', 'password': 123}
return JsonResponse({"status_code": 200, "code": "OK"})使用方式非常简单,分为如下两步:
- from rest_framework.views import APIView
- 继承APIView
- 直接使用request.data就可以获取Json数据
如果你只需要解析Json数据,不允许任何其他类型的数据请求,可以这样做:
- from rest_framework.parsers import JsonParser
- 给视图类定义一个parser_classes变量,值为列表类型[JsonParser]
- 如果parser_classes = [], 那就不处理任何数据类型的请求了
问题来了,这么神奇的功能,DRF是如何做的?因为昨天讲到Django原生无法处理application/json协议的请求,所以拿json解析来举例,请同学们思考一个问题,如果是你,你会在什么地方加入新的Json解析功能?
首先,需要明确一点,我们肯定需要在request对象上做文章,为什么呢?
因为只有有了用户请求,我们的解析才有意义,没有请求,就没有解析,更没有处理请求的逻辑,所以,我们需要弄明白,在整个流程中,request对象是什么时候才出现的,是在绑定url和处理视图之间的映射关系的时候吗?我们来看看源码:
@classonlymethod
def as_view(cls, **initkwargs):
"""Main entry point for a request-response process."""
for key in initkwargs:
if key in cls.http_method_names:
raise TypeError("You tried to pass in the %s method name as a "
"keyword argument to %s(). Don't do that."
% (key, cls.__name__))
if not hasattr(cls, key):
raise TypeError("%s() received an invalid keyword %r. as_view "
"only accepts arguments that are already "
"attributes of the class." % (cls.__name__, key))
def view(request, *args, **kwargs):
self = cls(**initkwargs)
if hasattr(self, 'get') and not hasattr(self, 'head'):
self.head = self.get
self.request = request
self.args = args
self.kwargs = kwargs
return self.dispatch(request, *args, **kwargs)
view.view_class = cls
view.view_initkwargs = initkwargs
# take name and docstring from class
update_wrapper(view, cls, updated=())
# and possible attributes set by decorators
# like csrf_exempt from dispatch
update_wrapper(view, cls.dispatch, assigned=())
return view看到了吗?在执行view函数的时候,那么什么时候执行view函数呢?当然是请求到来,根据url查找映射表,找到视图函数,然后执行view函数并传入request对象,所以,如果是我,我可以在这个视图函数里面加入处理application/json的功能:
@classonlymethod
def as_view(cls, **initkwargs):
"""Main entry point for a request-response process."""
for key in initkwargs:
if key in cls.http_method_names:
raise TypeError("You tried to pass in the %s method name as a "
"keyword argument to %s(). Don't do that."
% (key, cls.__name__))
if not hasattr(cls, key):
raise TypeError("%s() received an invalid keyword %r. as_view "
"only accepts arguments that are already "
"attributes of the class." % (cls.__name__, key))
def view(request, *args, **kwargs):
if request.content_type == "application/json":
import json
return HttpResponse(json.dumps({"error": "Unsupport content type!"}))
self = cls(**initkwargs)
if hasattr(self, 'get') and not hasattr(self, 'head'):
self.head = self.get
self.request = request
self.args = args
self.kwargs = kwargs
return self.dispatch(request, *args, **kwargs)
view.view_class = cls
view.view_initkwargs = initkwargs
# take name and docstring from class
update_wrapper(view, cls, updated=())
# and possible attributes set by decorators
# like csrf_exempt from dispatch
update_wrapper(view, cls.dispatch, assigned=())
return view看到了吧,然后我们试试发送json请求,看看返回结果如何?是不是非常神奇?事实上,你可以在这里,也可以在这之后的任何地方进行功能的添加。
那么,DRF是如何做的呢?我们在使用的时候只是继承了APIView,然后直接使用request.data,所以,我斗胆猜测,功能肯定是在APIView中定义的,废话,具体在哪个地方呢?
接下来,我们一起来分析一下DRF解析器源码,看看DRF在什么地方加入了这个功能。
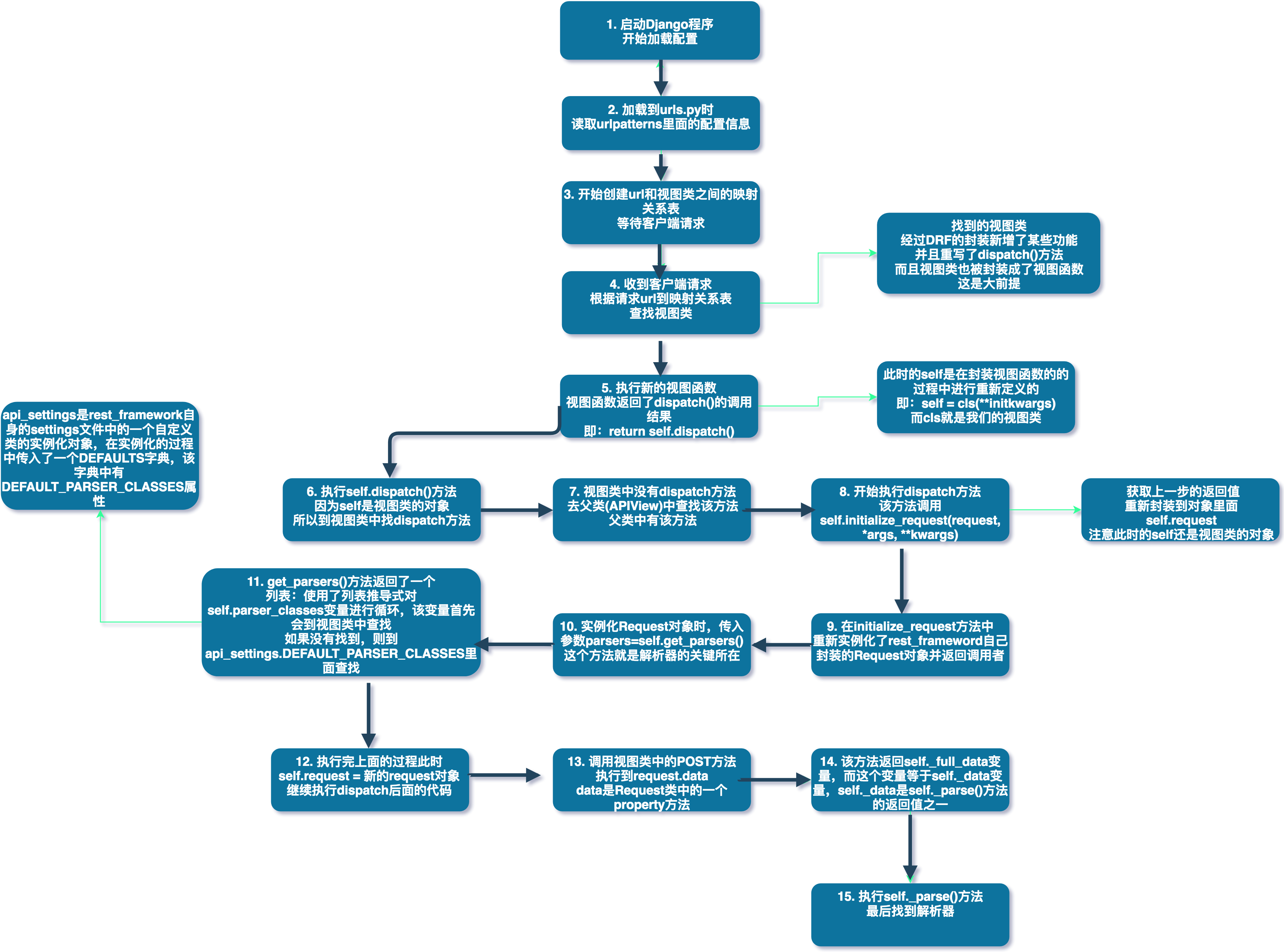
上图详细描述了整个过程,最重要的就是重新定义的request对象,和parser_classes变量,也就是我们在上面使用的类变量。好了,通过分析源码,验证了我们的猜测。
5.序列化组件
首先我们要学会使用序列化组件。定义几个 model:
from django.db import models
# Create your models here.
class Publish(models.Model):
nid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
city = models.CharField(max_length=32)
email = models.EmailField()
def __str__(self):
return self.name
class Author(models.Model):
nid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
age = models.IntegerField()
def __str__(self):
return self.name
class Book(models.Model):
title = models.CharField(max_length=32)
publishDate = models.DateField()
price = models.DecimalField(max_digits=5, decimal_places=2)
publish = models.ForeignKey(to="Publish", to_field="nid", on_delete=models.CASCADE)
authors = models.ManyToManyField(to="Author")
def __str__(self):
return self.title通过序列化组件进行GET接口设计
设计url,本次我们只设计GET和POST两种接口:
from django.urls import re_path
from serializers import views
urlpatterns = [
re_path(r'books/$', views.BookView.as_view())
]我们新建一个名为app_serializers.py的模块,将所有的序列化的使用集中在这个模块里面,对程序进行解耦:
# -*- coding: utf-8 -*-
from rest_framework import serializers
from .models import Book
class BookSerializer(serializers.Serializer):
title = serializers.CharField(max_length=128)
publish_date = serializers.DateTimeField()
price = serializers.DecimalField(max_digits=5, decimal_places=2)
publish = serializers.CharField(max_length=32)
authors = serializers.CharField(max_length=32)接着,使用序列化组件,开始写视图类:
# -*- coding: utf-8 -*-
from rest_framework.views import APIView
from rest_framework.response import Response
# 当前app中的模块
from .models import Book
from .app_serializer import BookSerializer
# Create your views here.
class BookView(APIView):
def get(self, request):
origin_books = Book.objects.all()
serialized_books = BookSerializer(origin_books, many=True)
return Response(serialized_books.data)如此简单,我们就已经,通过序列化组件定义了一个符合标准的接口,定义好model和url后,使用序列化组件的步骤如下:
- 导入序列化组件:from rest_framework import serializers
- 定义序列化类,继承serializers.Serializer(建议单独创建一个专用的模块用来存放所有的序列化类):class BookSerializer(serializers.Serializer):pass
- 定义需要返回的字段(字段类型可以与model中的类型不一致,参数也可以调整),字段名称必须与model中的一致
- 在GET接口逻辑中,获取QuerySet
- 开始序列化:将QuerySet作业第一个参数传给序列化类,many默认为False,如果返回的数据是一个列表嵌套字典的多个对象集合,需要改为many=True
- 返回:将序列化对象的data属性返回即可
上面的接口逻辑中,我们使用了Response对象,它是DRF重新封装的响应对象。该对象在返回响应数据时会判断客户端类型(浏览器或POSTMAN),如果是浏览器,它会以web页面的形式返回,如果是POSTMAN这类工具,就直接返回Json类型的数据。
此外,序列化类中的字段名也可以与model中的不一致,但是需要使用source参数来告诉组件原始的字段名,如下:
class BookSerializer(serializers.Serializer):
BookTitle = serializers.CharField(max_length=128, source="title")
publishDate = serializers.DateTimeField()
price = serializers.DecimalField(max_digits=5, decimal_places=2)
# source也可以用于ForeignKey字段
publish = serializers.CharField(max_length=32, source="publish.name")
authors = serializers.CharField(max_length=32)下面是通过POSTMAN请求该接口后的返回数据,大家可以看到,除ManyToManyField字段不是我们想要的外,其他的都没有任何问题:
[
{
"title": "Python入门",
"publishDate": null,
"price": "119.00",
"publish": "浙江大学出版社",
"authors": "serializers.Author.None"
},
{
"title": "Python进阶",
"publishDate": null,
"price": "128.00",
"publish": "清华大学出版社",
"authors": "serializers.Author.None"
}
]那么,多对多字段如何处理呢?如果将source参数定义为”authors.all”,那么取出来的结果将是一个QuerySet,对于前端来说,这样的数据并不是特别友好,我们可以使用如下方式:
class BookSerializer(serializers.Serializer):
title = serializers.CharField(max_length=32)
price = serializers.DecimalField(max_digits=5, decimal_places=2)
publishDate = serializers.DateField()
publish = serializers.CharField()
publish_name = serializers.CharField(max_length=32, read_only=True, source='publish.name')
publish_email = serializers.CharField(max_length=32, read_only=True, source='publish.email')
# authors = serializers.CharField(max_length=32, source='authors.all')
authors_list = serializers.SerializerMethodField()
def get_authors_list(self, authors_obj):
authors = list()
for author in authors_obj.authors.all():
authors.append(author.name)
return authors请注意,get_必须与字段名称一致,否则会报错。
通过序列化组件进行POST接口设计
接下来,我们设计POST接口,根据接口规范,我们不需要新增url,只需要在视图类中定义一个POST方法即可,序列化类不需要修改,如下:
# -*- coding: utf-8 -*-
from rest_framework.views import APIView
from rest_framework.response import Response
# 当前app中的模块
from .models import Book
from .app_serializer import BookSerializer
# Create your views here.
class BookView(APIView):
def get(self, request):
origin_books = Book.objects.all()
serialized_books = BookSerializer(origin_books, many=True)
return Response(serialized_books.data)
def post(self, request):
verified_data = BookSerializer(data=request.data)
if verified_data.is_valid():
book = verified_data.save()
# 可写字段通过序列化添加成功之后需要手动添加只读字段
authors = Author.objects.filter(nid__in=request.data['authors'])
book.authors.add(*authors)
return Response(verified_data.data)
else:
return Response(verified_data.errors)POST接口的实现方式,如下:
- url定义:需要为post新增url,因为根据规范,url定位资源,http请求方式定义用户行为
- 定义post方法:在视图类中定义post方法
- 开始序列化:通过我们上面定义的序列化类,创建一个序列化对象,传入参数data=request.data(application/json)数据
- 校验数据:通过实例对象的is_valid()方法,对请求数据的合法性进行校验
- 保存数据:调用save()方法,将数据插入数据库
- 插入数据到多对多关系表:如果有多对多字段,手动插入数据到多对多关系表
- 返回:将插入的对象返回
请注意,因为多对多关系字段是我们自定义的,而且必须这样定义,返回的数据才有意义,而用户插入数据的时候,serializers.Serializer没有实现create,我们必须手动插入数据,就像这样:
# 第二步, 创建一个序列化类,字段类型不一定要跟models的字段一致
class BookSerializer(serializers.Serializer):
# nid = serializers.CharField(max_length=32)
title = serializers.CharField(max_length=128)
price = serializers.DecimalField(max_digits=5, decimal_places=2)
publish = serializers.CharField()
# 外键字段, 显示__str__方法的返回值
publish_name = serializers.CharField(max_length=32, read_only=True, source='publish.name')
publish_city = serializers.CharField(max_length=32, read_only=True, source='publish.city')
# authors = serializers.CharField(max_length=32) # book_obj.authors.all()
# 多对多字段需要自己手动获取数据,SerializerMethodField()
authors_list = serializers.SerializerMethodField()
def get_authors_list(self, book_obj):
author_list = list()
for author in book_obj.authors.all():
author_list.append(author.name)
return author_list
def create(self, validated_data):
# {'title': 'Python666', 'price': Decimal('66.00'), 'publish': '2'}
validated_data['publish_id'] = validated_data.pop('publish')
book = Book.objects.create(**validated_data)
return book
def update(self, instance, validated_data):
# 更新数据会调用该方法
instance.title = validated_data.get('title', instance.title)
instance.publishDate = validated_data.get('publishDate', instance.publishDate)
instance.price = validated_data.get('price', instance.price)
instance.publish_id = validated_data.get('publish', instance.publish.nid)
instance.save()
return instance这样就会非常复杂化程序,如果我希望序列化类自动插入数据呢?
这是问题一:如何让序列化类自动插入数据?
另外问题二:如果字段很多,那么显然,写序列化类也会变成一种负担,有没有更加简单的方式呢?
答案是肯定的,我们可以这样做:
class BookSerializer(serializers.ModelSerializer):
class Meta:
model = Book
fields = ('title',
'price',
'publish',
'authors',
'author_list',
'publish_name',
'publish_city'
)
extra_kwargs = {
'publish': {'write_only': True},
'authors': {'write_only': True}
}
publish_name = serializers.CharField(max_length=32, read_only=True, source='publish.name')
publish_city = serializers.CharField(max_length=32, read_only=True, source='publish.city')
author_list = serializers.SerializerMethodField()
def get_author_list(self, book_obj):
# 拿到queryset开始循环 [{}, {}, {}, {}]
authors = list()
for author in book_obj.authors.all():
authors.append(author.name)
return authors步骤如下:
- 继承ModelSerializer:不再继承Serializer
- 添加extra_kwargs类变量:extra_kwargs = {‘publish’: {‘write_only’: True}}
使用ModelSerializer完美的解决了上面两个问题。好了,这就是今天的全部内容。
参考资料:
我们的文章到此就结束啦,如果你喜欢今天的 Python 教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 ( pythondict.com )
不只是一个宝典
欢迎关注公众号:Python实用宝典

评论(0)