
最常见的深度学习框架应该是TensorFlow、Pytorch、Keras,但是这些框架在面向大规模模型的时候都不是很方便。
比如Pytorch的分布式并行计算框架(Distributed Data Parallel,简称DDP),它也仅仅是能将数据并行,放到各个GPU的模型上进行训练。
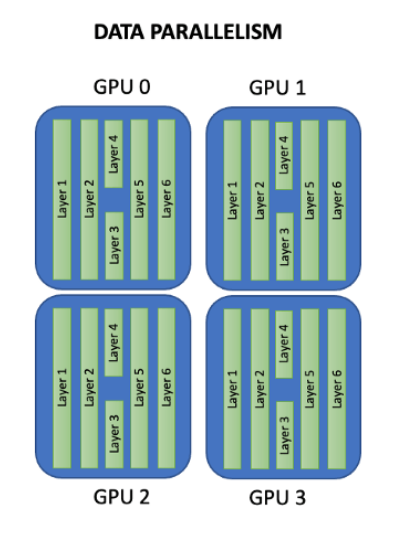
也就是说,DDP的应用场景在你的模型大小大于显卡显存大小时,它就很难继续使用了,除非你自己再将模型参数拆散分散到各个GPU上。
今天要给大家介绍的DeepSpeed,它就能实现这个拆散功能,它通过将模型参数拆散分布到各个GPU上,以实现大型模型的计算,弥补了DDP的缺点,非常方便,这也就意味着我们能用更少的GPU训练更大的模型,而且不受限于显存。
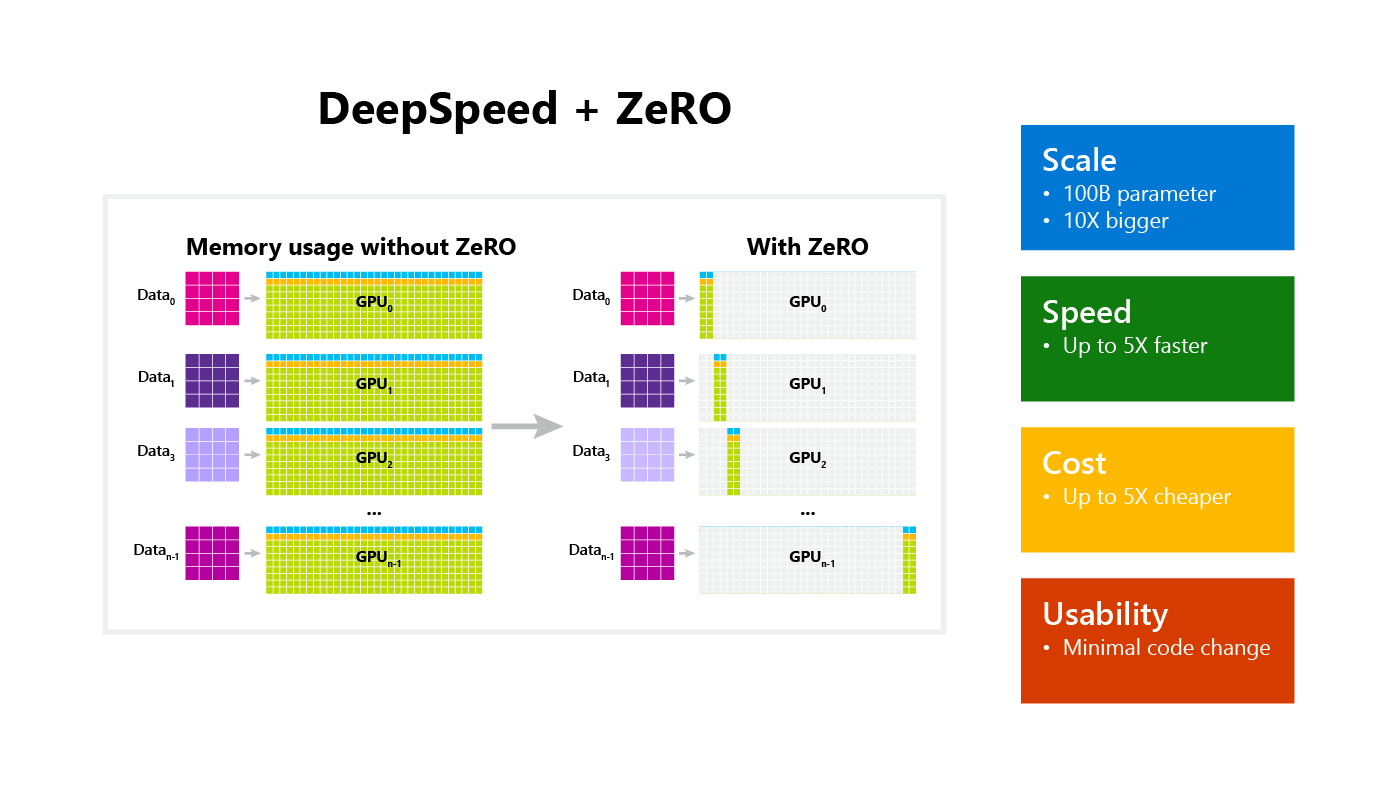
DeepSpeed入门并不简单,尽管是微软开源的框架,文档却写的一般,缺少条理性,也没有从零到一的使用示例。下面我就简单介绍一下怎么使用DeepSpeed这个框架。
1.准备
开始之前,你要确保Python和pip已经成功安装在电脑上,如果没有,请访问这篇文章:超详细Python安装指南 进行安装。
(可选1) 如果你用Python的目的是数据分析,可以直接安装Anaconda:Python数据分析与挖掘好帮手—Anaconda,它内置了Python和pip.
(可选2) 此外,推荐大家用VSCode编辑器来编写小型Python项目:Python 编程的最好搭档—VSCode 详细指南
Windows环境下打开Cmd(开始—运行—CMD),苹果系统环境下请打开Terminal(command+空格输入Terminal),输入命令安装依赖:
pip install deepspeed
此外,你还需要下载 Pytorch,在官网选择自己对应的系统版本和环境,按照指示安装即可:
https://pytorch.org/get-started/locally/
2.使用 DeepSpeed 分布式框架
使用DeepSpeed其实和写一个pytorch模型只有部分区别,一开始的流程是一样的。
2.1 载入数据集:
import torch
import torchvision
import torchvision.transforms as transforms
trainset = torchvision.datasets.CIFAR10(root='./data',
train=True,
download=True,
transform=transform)
trainloader = torch.utils.data.DataLoader(trainset,
batch_size=16,
shuffle=True,
num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data',
train=False,
download=True,
transform=transform)
testloader = torch.utils.data.DataLoader(testset,
batch_size=4,
shuffle=False,
num_workers=2)2.2 编写模型:
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
criterion = nn.CrossEntropyLoss()这里我写了一个非常简单的模型作测试。
2.3 初始化Deepspeed
DeepSpeed 通过输入参数来启动训练,因此需要使用argparse解析参数:
import argparse
def add_argument():
parser = argparse.ArgumentParser(description='CIFAR')
parser.add_argument('-b',
'--batch_size',
default=32,
type=int,
help='mini-batch size (default: 32)')
parser.add_argument('-e',
'--epochs',
default=30,
type=int,
help='number of total epochs (default: 30)')
parser.add_argument('--local_rank',
type=int,
default=-1,
help='local rank passed from distributed launcher')
parser.add_argument('--log-interval',
type=int,
default=2000,
help="output logging information at a given interval")
parser = deepspeed.add_config_arguments(parser)
args = parser.parse_args()
return args
此外,模型初始化的时候除了参数,还需要model及其parameters,还有训练集:
args = add_argument()
net = Net()
parameters = filter(lambda p: p.requires_grad, net.parameters())
model_engine, optimizer, trainloader, __ = deepspeed.initialize(
args=args, model=net, model_parameters=parameters, training_data=trainset)2.4 训练逻辑
下面的部分和我们平时训练模型是几乎一样的代码,请注意 local_rank 是你不需要管的参数,在后面启动模型训练的时候,DeepSpeed会自动给这个参数赋值。
for epoch in range(2):
running_loss = 0.0
for i, data in enumerate(trainloader):
inputs, labels = data[0].to(model_engine.local_rank), data[1].to(
model_engine.local_rank)
outputs = model_engine(inputs)
loss = criterion(outputs, labels)
model_engine.backward(loss)
model_engine.step()
# print statistics
running_loss += loss.item()
if i % args.log_interval == (args.log_interval - 1):
print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / args.log_interval))
running_loss = 0.02.5 测试逻辑
模型测试和模型训练的逻辑类似:
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images.to(model_engine.local_rank))
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels.to(
model_engine.local_rank)).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' %
(100 * correct / total))2.6 编写模型参数
在当前目录下新建一个 config.json 里面写好我们的调优器、训练batch等参数:
{
"train_batch_size": 4,
"steps_per_print": 2000,
"optimizer": {
"type": "Adam",
"params": {
"lr": 0.001,
"betas": [
0.8,
0.999
],
"eps": 1e-8,
"weight_decay": 3e-7
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": 0,
"warmup_max_lr": 0.001,
"warmup_num_steps": 1000
}
},
"wall_clock_breakdown": false
}完整的开发流程就结束了,可以看到其实和我们平时使用pytorch开发模型的区别不大,就是在初始化的时候使用 DeepSpeed,并以输入参数的形式初始化。完整代码可以在Python实用宝典后台回复 Deepspeed 下载。
3. 测试代码
现在就来测试我们上面的代码能不能正常运行。
在这里,我们需要用环境变量控制使用的GPU,比如我的机器有10张GPU,我只使用6, 7, 8, 9号GPU,输入命令:
export CUDA_VISIBLE_DEVICES="6,7,8,9"
然后开始运行代码:
deepspeed test.py --deepspeed_config config.json
看到下面的输出说明开始正常运行,在下载数据了:
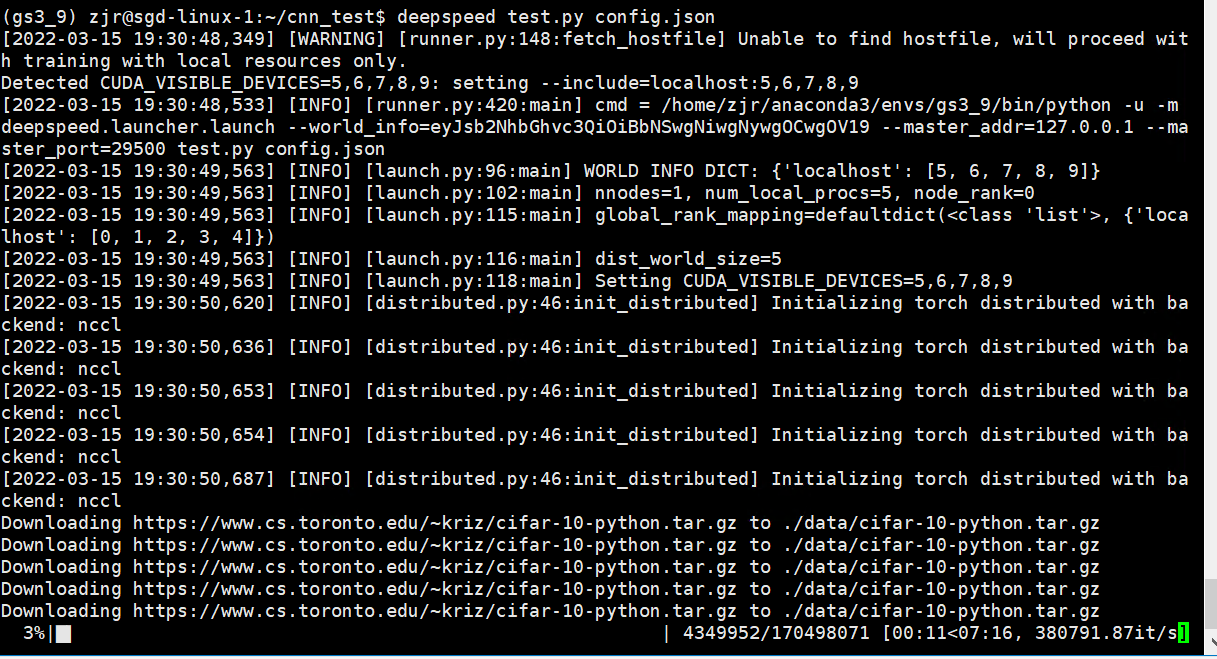
开始训练的时候 DeepSpeed 通常会打印更多的训练细节供用户监控,包括训练设置、性能统计和损失趋势,效果类似于:
worker-0: [INFO 2020-02-06 20:35:23] 0/24550, SamplesPerSec=1284.4954513975558 worker-0: [INFO 2020-02-06 20:35:23] 0/24600, SamplesPerSec=1284.384033658866 worker-0: [INFO 2020-02-06 20:35:23] 0/24650, SamplesPerSec=1284.4433482972925 worker-0: [INFO 2020-02-06 20:35:23] 0/24700, SamplesPerSec=1284.4664449792422 worker-0: [INFO 2020-02-06 20:35:23] 0/24750, SamplesPerSec=1284.4950124403447 worker-0: [INFO 2020-02-06 20:35:23] 0/24800, SamplesPerSec=1284.4756105952233 worker-0: [INFO 2020-02-06 20:35:24] 0/24850, SamplesPerSec=1284.5251526215386 worker-0: [INFO 2020-02-06 20:35:24] 0/24900, SamplesPerSec=1284.531217073863 worker-0: [INFO 2020-02-06 20:35:24] 0/24950, SamplesPerSec=1284.5125323220368 worker-0: [INFO 2020-02-06 20:35:24] 0/25000, SamplesPerSec=1284.5698818883018 worker-0: Finished Training worker-0: GroundTruth: cat ship ship plane worker-0: Predicted: cat car car plane worker-0: Accuracy of the network on the 10000 test images: 57 %
当你运行到最后,出现了这样的输出,恭喜你,完成了你的第一个 DeepSpeed 模型,可以开始你的大规模训练之路了。
我们的文章到此就结束啦,如果你喜欢今天的 Python 教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 ( pythondict.com )
不只是一个宝典
欢迎关注公众号:Python实用宝典

评论(0)