
K近邻算法通过计算被分类对象与训练集对象之间的距离,确定其k个临近点,然后使用这k个临近点中最多的分类作为分类结果。

如上图,当K=3时,它会被分类为 Class B。因为K=3时,3个临近点里有2个是B类的。
同理,K=7时它会被分类为 Class A,因为K=7时,7个临近点里4个是A类的。
KNN算法一个比较不好的缺点是K值由人主观决定。因为这样有一个问题,你取的K值不同,对于某些点的分类结果就不同,比如上图分别取k=3和k=7会得到不同的结果。
K值不能取太小,比如K=1的情况,此时容易被错误的样本干扰,造成过拟合等问题。当然,K值也不能取太大,越大分类效果越差。
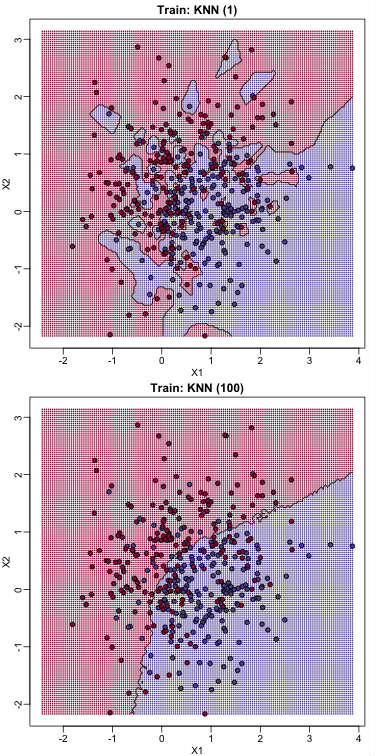
如上图所示,当k=1的时候,决策边界变得非常不光滑,换句话说,模型的决策规则非常复杂,容易造成过拟合。
简而言之:k越小,模型越容易过拟合;k越大,越容易欠拟合。
所以K值应该取一个不大不小的奇数,比如3、7、9、11等,千万不能选偶数,因为偶数会有两个分类打平的情况,不要给自己找麻烦。
一图总结KNN算法:

下面我们就同样使用第三天的数据集来使用KNN预测用户是否会购买SUV,并计算KNN算法在这个应用场景上的准确率。
1.导入库与数据 #
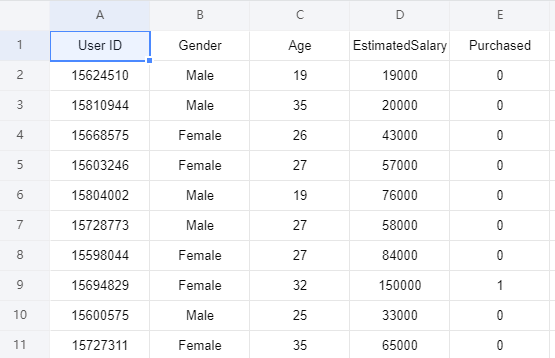
现在有一个数据集包含了社交网络中用户的信息。这些信息涉及用户ID,性别,年龄以及预估薪资。
一家汽车公司刚刚推出了他们新型的豪华SUV,我们尝试使用KNN算法预测哪些用户会购买这种全新SUV。并且在最后一列用来表示用户是否购买:
导入库:
import numpy as np import matplotlib.pyplot as plt import pandas as pd from sklearn.metrics import confusion_matrix from sklearn.linear_model import LogisticRegression from sklearn.preprocessing import StandardScaler from sklearn.model_selection import train_test_split from sklearn.preprocessing import LabelEncoder
导入数据,包括性别:
# 1.导入数据集
dataset = pd.read_csv('Social_Network_Ads.csv')
X = dataset.iloc[:, [1, 2, 3]].values
Y = dataset.iloc[:, 4].values
# 性别转化为数字
labelencoder_X = LabelEncoder()
X[:, 0] = labelencoder_X.fit_transform(X[:, 0])2.数据集切分与特征缩放 #
我们对数据源进行处理,将其中25%的数据设置为测试集。
# 2.将数据集分成训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, Y, test_size=0.25, random_state=0)此外,还需要进行特征缩放,因为在K近邻算法中,分类器主要是计算两点之间的欧几里得距离,如果一个特征比其它的特征有更大的范围值,那么距离将会被这个特征值所主导。
因此每个特征应该被归一化,比如将取值范围处理为0到1之间或权重相同的值。
# 3.特征缩放 sc = StandardScaler() X_train = sc.fit_transform(X_train) X_test = sc.transform(X_test)
3.数据训练与预测 #
使用scikit-learn中的KNN算法进行训练,设置k值=5:
# 4.训练 classifier = KNeighborsClassifier(n_neighbors=5) classifier.fit(X_train, y_train)
对分类器调用predict方法进行预测:
# 5.预测 y_pred = classifier.predict(X_test)
你可以把预测结果输出出来,但这里我觉得没有必要,我们直接进入下一步评估模型就能知道结果好坏了。
4.模型评估 #
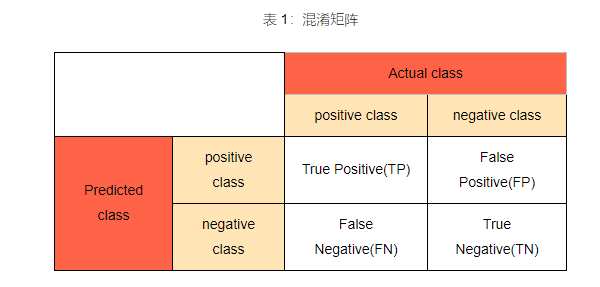
与上一节教程一样,我们使用混淆矩阵进行评估:
# 6.评估预测 # 生成混淆矩阵 from sklearn.metrics import confusion_matrix cm = confusion_matrix(y_test, y_pred) print(cm)
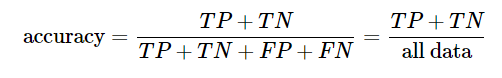
得到结果如下:
(base) G:\push\20210210>python test_with_gender.py [[64 4] [ 3 29]]
可以看到,分类正确的值有 64+29=93个,分类错误的值有 3+4=7个。
准确率达 93/100 = 93%,比上节使用逻辑回归的准确率高了4%,你也可以选择不同的K值,看看能不能拿到更加优秀的结果。
我们的文章到此就结束啦,如果你喜欢今天的 Python 教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 ( pythondict.com )
不只是一个宝典
欢迎关注公众号:Python实用宝典

推荐阅读 #
下周重要经济事件和财报(2025-03-10~2025-03-14) #
我开发了一款APP… #
How I make 47% profit on NFLX earnings #
我是如何在美股NFLX财报上盈利 47% 的 #
新年快乐!!Market Moments 重磅更新!! #
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
Python实用宝典 (pythondict.com)
关注公众号:Python实用宝典
更多精彩文章等你阅读




评论(0)