
Python中字符和数字的转换主要有两种形式:
ord() : 将字符转为数字
ord('a')
# 97
chr():将数字转为字符
char(97) # a
对于unicode字符,我们需要用以下两种方法
ord(): unicode转数字
ord(u'\u1111') # 4369
hex(): 数字转unicode字符
a = hex(4369) # 0x1111 u = chr(a) # ᄑ
Python中字符和数字的转换主要有两种形式:
ord() : 将字符转为数字
ord('a')
# 97
chr():将数字转为字符
char(97) # a
对于unicode字符,我们需要用以下两种方法
ord(): unicode转数字
ord(u'\u1111') # 4369
hex(): 数字转unicode字符
a = hex(4369) # 0x1111 u = chr(a) # ᄑ
大部门人使用python是因为它非常方便,而不是因为它速度快。过多的第三方库使得python相比于Java和C的性能差距较大。但也是可以理解的,因为在大部分情况下,开发速度优先于执行速度。
但也不要过于担心python的速度![]() ,这并不一定是一个非此即彼的命题。经过适当优化,Python应用程序可以以惊人的速度运行——也许还不能达到Java或C语言的速度,但是对于Web应用程序、数据分析、管理和自动化工具以及大多数其他用途来说,速度已经足够快了。快到你可能会忘记了你是在用应用程序性能换取开发人员的生产力。
,这并不一定是一个非此即彼的命题。经过适当优化,Python应用程序可以以惊人的速度运行——也许还不能达到Java或C语言的速度,但是对于Web应用程序、数据分析、管理和自动化工具以及大多数其他用途来说,速度已经足够快了。快到你可能会忘记了你是在用应用程序性能换取开发人员的生产力。
优化Python性能不能单从一个角度上看。而是应用所有可用的优化方法,并选择最适合当前场景的多种方法的集合。(Dropbox的员工有一个最令人瞠目的例子,展示了python优化的强大功能,点击链接查看。)
在本文中,我将简单讲述许多常见的python优化方法。有些是临时措施,只需要简单地将一项转换为另一项(例如更换Python解释器),但是那些带来最大收益的方法将需要更详细的工作。
如果你不能够找出速度慢的原因所在,你就不能确定你的python应用程序为什么运行地不够理想![]() 。
。
计算的方法有很多,你可以尝试python内置的 cProfile模块 进行简单的计算分析,如果需要更高的精度(计算每行语句运行时间),可以使用 line_profiler 第三方工具。通常而言,从计算程序的函数运行时间进行分析就能够给你提供改进方案,所以推荐使用 profilehooks 第三方库,它能计算单个函数的运行时间。
你可能需要更多的挖掘才能发现为什么你的程序某个地方这么慢、怎么修复它。重点在于缩小你的排查范围,逐渐细化到某条语句上。
当你可以把需要计算出来的数据保存下来的时候,千万不要重复上千次去计算它。如果你有一个经常需要使用的函数,而且返回的是可预测的结果,Python已经给你提供了一个选项,能将其缓存到内存中。后续的函数调用如果是一样的,将立即返回结果。
有许多方法都可以做到,比如说:使用python的一个本地库:functools,拥有一个装饰器,叫@functools.lru_cache,它能够缓存函数最近的N个调用,当缓存的值在特定时间内保持不变的时候这个非常好用,比如说列出最近一天使用的物品。
如果你的Python程序中有基于矩阵或数组的数学运算,并且希望更高效地对它们进行计算,那么你就应该使用NumPy,因为它通过使用C库来完成繁重的工作,比原生python解释器能更快得处理数组,而且能比Python内置数据结构更有效地存储数字数据。
NumPy还可以极大地加速相对普通的数学运算![]() 。该包为许多常见的Python数学操作(如min和max)提供了替换,这些操作的速度比原始Python快很多倍。
。该包为许多常见的Python数学操作(如min和max)提供了替换,这些操作的速度比原始Python快很多倍。
NumPy的另一个优点是对大型对象(比如包含数百万项的列表)能更有效地使用内存。一般来说,如果用传统的Python表示类似于NumPy中的大型对象,那么它们将占用大约四分之一的内存。
重写Python算法以使用NumPy需要做一些工作,因为需要使用NumPy的语法重新声明数组对象。但是NumPy在实际的数学操作中使用Python现有的习惯用法(+、-等等),所以切换到NumPy并不会让人太迷惑。
NumPy使用C编写的库是一种很好的方法![]() 。如果现有的C库能够满足你的需求,那么Python及其生态系统将提供几个选项来连接到该库并利用其提高速度。
。如果现有的C库能够满足你的需求,那么Python及其生态系统将提供几个选项来连接到该库并利用其提高速度。
最常用的方法是Python的ctypes库。因为ctypes与其他Python应用程序广泛兼容,所以它是最好的起点,但也并不是唯一的,CFFI项目为C. Cython提供了一个更优雅的接口(参见下面第五点),也可以用来包装外部库,代价是你必须学习Cython的标记方法。
如果你非常追求速度,应该用C而不是python,但是对于我这种有python依赖症的人来说,对C天生就有种畏惧![]() 。现在有一个很好的解决办法出来了。
。现在有一个很好的解决办法出来了。
Cython允许Python用户方便地访问C的速度。现有的Python代码可以逐步转换为C :首先通过Cython将所述代码编译为C,然后通过添加类型注释以获得更快的速度。
不过,Cython不能变魔术。按原样转换为Cython的代码通常运行速度通常不会加快超过15%到50%,因为该级别的大多数优化都集中在减少Python解释器的开销上。只有在为Cython模块提供类型注释时才允许将相关代码转换为纯C,这时候的速度提升才最大。
由于全局解释器锁(GIL)的存在,Python规定一次只执行一个线程,以避免在使用多个线程时出现状态问题。它的存在有充分的理由,但依然很讨厌![]() 。
。
随着时间的推移,GIL的效率显著提高(这是为什么你应该用python3的其中一个原因),但是核心问题仍然存在。为了解决这个问题,Python提供了多处理模块(multiprocessing)来在单独的内核上运行Python解释器的多个进程。状态可以通过共享内存或服务器进程共享,数据可以通过队列或管道在进程实例之间传递。
您仍然必须手动管理进程之间的状态。此外,启动多个Python实例并在它们之间传递对象也会涉及不少开销。尽管如此,多处理库还是很有用的。另外,使用了C库的Python模块和包(如NumPy)也是完全避免GIL的。这也是推荐它们提高速度的另一个原因。
简单地输入import xyz是多么方便啊![]() !但是你知道,第三方库虽然可以改变应用程序的性能,但并不总是向好的方向发展。
!但是你知道,第三方库虽然可以改变应用程序的性能,但并不总是向好的方向发展。
有时,你加了某个模块的时候,应用程序反而变慢了,这就是来自特定库的模块构成瓶颈。同样,仔细计算运行时间也会有所帮助,有时则不那么明显。示例:Pyglet是一个用于创建窗口图形化应用程序的库,它自动启用调试模式,这将极大地影响性能,直到显式禁用为止。除非阅读文档,否则你可能永远不会意识到这一点![]() 。多读书,多了解情况。
。多读书,多了解情况。
Python的运行是跨平台的,但这并不意味着每个操作系统(Windows、Linux、OS X)的特性都可以在Python下抽象出来。大多数情况下,你需要了解平台的细节,比如路径命名约定等等。
但在性能方面,理解平台的差异也很重要。例如,有些python脚本需要使用Windows的api去访问一些特定的应用,这些应用也可能会减慢运行速度。
CPython是Python最常用的优化方案,因为它优先考虑兼容性而不是原始速度。对于那些想把速度放在首位的程序员来说,PyPy是一个Python更好的方案,它配备了一个JIT编译器来加速代码的执行(编译为C代码)。
因为PyPy被设计为CPython的一个临时替代品,所以它是获得快速性能提升的最简单方法之一。大多数Python应用程序将完全按原样运行在PyPy上。然而,充分利用PyPy可能需要不断地测试。你将会发现,长时间运行的应用程序更有可能从PyPy中获得了最大的性能收益,因为编译器会随着时间分析执行情况。对于运行和退出的简短脚本,最好使用CPython,因为性能的提高不足以克服JIT的开销![]() 。
。
如果你用的是python2。而且没有压倒一切的理由(比如一个不兼容的模块)坚持使用它,你应该跳到python3。
Python 3中还有许多Python 2.x中没有的构造和优化。例如,Python 3.5使异步变得不那么棘手,async和await关键字成为语言语法的一部分。Python 3.2对全局解释器锁进行了重大升级,显著改进了Python处理多线程的方式。
以上就是全部十点的改进方案啦,尽管使用了这些方法可能运行速度还是无法超过C和Java,但是代码跑得快不快,不取决于语言,而是取决于人,况且Python本身不必是最快的,只要足够快就行。
如果你希望我们今天的Python 教程,请持续关注我们,如果对你有帮助,麻烦在下面点一个赞/在看哦![]() 有任何问题都可以在下方留言区留言,我们都会耐心解答的!
有任何问题都可以在下方留言区留言,我们都会耐心解答的!
Python实用宝典 (pythondict.com)
不只是一个宝典
欢迎关注公众号:Python实用宝典

按照不同的情况,Python下载文件可以分为三种:小文件下载、大文件下载、批量下载。
本文源代码: https://pythondict.com/download/python-file-download-source-code/
流程:使用request.get请求链接,返回的内容放置到变量r中,然后将r写入到你想放的地方。

以下载上述流程图为例子:
# 例1
import requests
def request_zip(url):
r = requests.get(url)
# 请求链接后保存到变量r中
with open("new/名字.png",'wb') as f:
# r.content写入至文件
f.write(r.content)
request_zip('https://pythondict.com/wp-content/uploads/2019/08/2019082807222049.png')运行完毕后,它将会被保存到当前文件夹的new文件夹里。
我们在小文件下载的时候,是将文件内容暂存到变量里,大家想想,下载大文件的时候还这样做会有什么问题?
很简单,如果你的内存只有8G,结果要下载文件却有10G那么大,那就肯定无法下载成功了。而且本机软件运行占的内存也比较大,如果你的内存只有8G,实际上剩余可用的内存可能低于2G-4G. 这种情况下怎么下载大文件呢?
原理:一块一块地将内存写入到文件中,以避免内存占用过大。
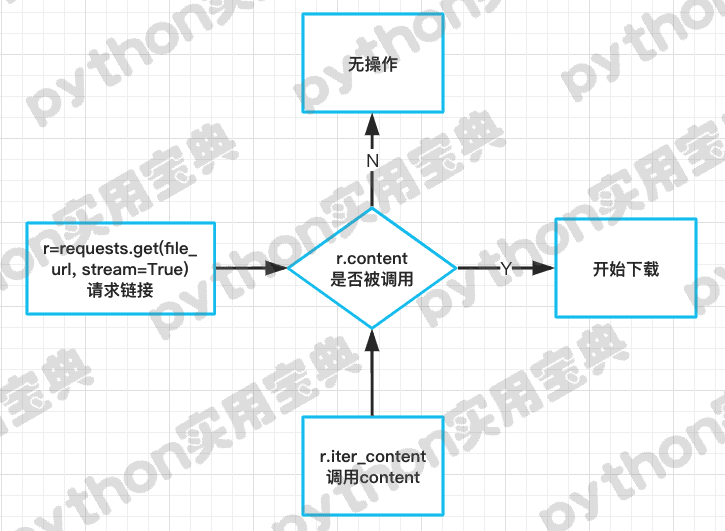
当设置了request.get(stream=True)的时候,就是启动流模式下载,典型特征:在r变量的content被调用的时候才会启动下载。代码如下:
# 例2
import requests
def request_big_data(url):
name = url.split('/')[-1]
# 获取文件名
r = requests.get(url, stream=True)
# stream=True 设置为流读取
with open("new/"+str(name), "wb") as pdf:
for chunk in r.iter_content(chunk_size=1024):
# 每1024个字节为一块进行读取
if chunk:
# 如果chunk不为空
pdf.write(chunk)
request_big_data(url="https://www.python.org/ftp/python/3.7.4/python-3.7.4-amd64.exe")所谓批量下载,当然不是一个一个文件的下载了,比如说我们要下载百度图片,如果一个一个下载会出现两种负面情况:
我们的解决方案是使用异步策略。如果你会用scrapy框架,那就轻松许多了,因为它结合了twisted异步驱动架构,根本不需要你自己写异步。不过我们python实用宝典讲的可是教程,还是跟大家说一下怎么实现异步下载:
我们需要使用到两个包,一个是asyncio、一个是aiohttp. asyncio是Python3的原装库,但是aiohttp则需要各位使用cmd/Terminal打开,输入以下命令安装:
pip install aiohttp
注意asyncio是单进程并发库,不是多线程,也不是多进程,是协程。单纯是在一个进程里面异步(切来切去运行),切换的地方用await标记,能够切换的函数用async标记。比如下载异步批量下载两个图片的代码如下:
# 例3
import aiohttp
import asyncio
import time
async def job(session, url):
# 声明为异步函数
name = url.split('/')[-1]
# 获得名字
img = await session.get(url)
# 触发到await就切换,等待get到数据
imgcode = await img.read()
# 读取内容
with open("new/"+str(name),'wb') as f:
# 写入至文件
f.write(imgcode)
return str(url)
async def main(loop, URL):
async with aiohttp.ClientSession() as session:
# 建立会话session
tasks = [loop.create_task(job(session, URL[_])) for _ in range(2)]
# 建立所有任务
finished, unfinished = await asyncio.wait(tasks)
# 触发await,等待任务完成
all_results = [r.result() for r in finished]
# 获取所有结果
print("ALL RESULT:"+str(all_results))
URL = ['https://pythondict.com/wp-content/uploads/2019/07/2019073115192114.jpg',
'https://pythondict.com/wp-content/uploads/2019/08/2019080216113098.jpg']
loop = asyncio.get_event_loop()
loop.run_until_complete(main(loop, URL))
loop.close()注意: img = await session.get(url)
这时候,在你请求第一个图片获得数据的时候,它会切换请求第二个图片或其他图片,等第一个图片获得所有数据后再切换回来。从而实现多线程批量下载的功能,速度超快,下载超清大图用这个方法可以一秒一张。
我们的文章到此就结束啦,如果你希望我们今天的Python 教程,请持续关注我们,如果对你有帮助,麻烦在下面点一个赞/在看哦,有任何问题都可以在下方留言区留言,我们都会耐心解答的!
Python实用宝典 (pythondict.com)
不只是一个宝典
欢迎关注公众号:Python实用宝典
plotly 是目前已知的Python最强绘图库,它比上次我们讲的echarts还强大许多许多![]() ,它的绘制通过生成一个web页面得到,而且支持调整图像大小后保存,而且还能支持可动态调节的页面,方便python web端的开发。
,它的绘制通过生成一个web页面得到,而且支持调整图像大小后保存,而且还能支持可动态调节的页面,方便python web端的开发。
开始之前,你要确保Python和pip已经成功安装在电脑上噢,如果没有,请访问这篇文章:超详细Python安装指南 进行安装。
Windows环境下打开Cmd(开始—运行—CMD),苹果系统环境下请打开Terminal(command+空格输入Terminal),准备开始输入命令安装依赖。
当然,我更推荐大家用VSCode编辑器,把本文代码Copy下来,在编辑器下方的终端装依赖模块,多舒服的一件事啊:Python 编程的最好搭档—VSCode 详细指南。
在终端输入以下命令安装我们所需要的依赖模块:
pip install plotly
看到 Successfully installed xxx 则说明安装成功。
你只需要知道某些图的生成函数及其传入参数,就可以生成很漂亮的统计图。比如生成文章开头的那个官方平行类别图,你只要需要知道它的生成函数是 px.parallel_categories。支持的参数列表如下:
data_frame:数据,需要以DataFrame格式。
color: 可指定每一列的特定颜色。
color_continuous_scale: 构建连续的颜色
详细参数可阅读官方文档:
https://plotly.github.io/plotly.py-docs/generated/plotly.express.parallel_categories.html
在这里,我们使用官方生成好的数据作为展示的例子,编写以下代码即可:
# 文件命名为:test.py import plotly.express as px tips = px.data.tips() fig = px.parallel_categories(tips, color="size", color_continuous_scale=px.colors.sequential.Inferno) fig.show()
在cmd/Terminal或者vscode的终端里,运行这份代码:python test.py 你会看到浏览器自动生成了一个页面,页面上就是这幅图,而且是可以进行交互的图。
除此之外还有这样的图:

import plotly.express as px
gapminder = px.data.gapminder()
fig = px.scatter(gapminder.query("year==2007"), x="gdpPercap", y="lifeExp", size="pop", color="continent",
hover_name="country", log_x=True, size_max=60)
fig.show()代码其实非常简单,你只需要符合它的数据格式就可以生成了![]() ,真的是坐着收图啊,还有以下这些例子,这些例子都是可以在页面上进行交互的(放大缩小等),相当方便!
,真的是坐着收图啊,还有以下这些例子,这些例子都是可以在页面上进行交互的(放大缩小等),相当方便!
其实在执行完程序后生成的页面里,右上角有个小摄像头,点击那个摄像头可以直接生成页面:

但是你可能会希望直接在程序中将图片保存下载,方便批量生成图片,这个时候我们需要添加这样的一个离线plot语句:
import plotly.offline as offline offline.plot(figure_or_data = fig, image = 'png', image_filename='plot_image', output_type='file', image_width=800, image_height=600, validate=False)
在得到了图像的fig变量后,你只需要继续编写上述语句就可以保存下来,比如我们的第一个例子,将会是这样保存的。
# 文件命名为:test.py
import plotly.express as px
import plotly.offline as offline
tips = px.data.tips()
fig = px.parallel_categories(tips, color="size", color_continuous_scale=px.colors.sequential.Inferno)
fig.show()
offline.plot(figure_or_data = fig, image = 'png', image_filename='plot_image',
output_type='file', image_width=800, image_height=600, validate=False)以上这些,我们在未来都会陆续讲到,如果你想要获得更多的图形及其编写方法,可以参考官方文档,也可以继续关注本公众号/网站,我们将陆续推出plotly的具体例子的制作方案!!
我们的文章到此就结束啦,如果你希望我们今天的Python 教程,请持续关注我们,如果对你有帮助,麻烦在下面点一个赞/在看哦![]() 有任何问题都可以在下方留言区留言,我们都会耐心解答的!
有任何问题都可以在下方留言区留言,我们都会耐心解答的!
Python实用宝典 (pythondict.com)
不只是一个宝典
欢迎关注公众号:Python实用宝典
工作的时候,尤其是自媒体,我们必备水印添加工具以保护我们的知识产权![]() ,网上有许多的在线/下载的水印添加工具,但他们或多或少都存在以下问题:
,网上有许多的在线/下载的水印添加工具,但他们或多或少都存在以下问题:
现在只要你会使用命令,我们就能教大家怎么使用Python超级简单地为图片添加水印,而且具备以下特点:
是不是超棒,已经具备你所需要的所有功能了![]() ? 下面进入正题。
? 下面进入正题。
我们需要使用的是2Dou的开源项目:
https://github.com/2Dou/watermarker
非常有用的开源项目,感谢原作者。
有三种方法可以下载这个项目:
下载解压到你想要放置的任意一个文件夹下。路径中最好不要带中文名,如果你是用前两种方法下载的,而且是windows系统用户,注意要把该项目的字体文件名改为英文,而且marker.py里也有一个地方需要改动,如下:

将font文件夹里的 青鸟华光简琥珀.ttf 改为 bird.ttf, 什么名字不重要,重点是不要用中文名,否则pillow会无法使用改文件![]() 。注意marker.py文件里的第十行要改成相应的名字,与font文件夹下的字体文件名相对应。
。注意marker.py文件里的第十行要改成相应的名字,与font文件夹下的字体文件名相对应。
刚刚我们提到了pillow这个库,这个包的运行需要使用到这个第三方库,它是专门用来处理图像的,打开CMD/Terminal, 输入以下命令即可安装:
pip install pillow
安装完毕后,我们就可以试一下了![]() !最普通的例子如下,将你所需要加水印的图片放在该项目的input文件夹下,然后在cmd/Terminal中进入你存放该项目的文件夹输入以下命令:
!最普通的例子如下,将你所需要加水印的图片放在该项目的input文件夹下,然后在cmd/Terminal中进入你存放该项目的文件夹输入以下命令:
python marker.py -f ./input/baby.jpg -m python实用宝典
各个参数的含义如下:
-f 文件路径:是你的图片的路径
-m 文本内容:是你想要打的水印的内容
其他参数不设置则为默认值,运行完毕后会在output文件夹下出现相应的加了水印的图片,效果如下:

默认水印的颜色是…屎黄色的![]() ?但是没关系,我们可以修改它的颜色,添加-c参数即可!(参数默认格式为 #号后加6位16进制),利用图像工具,我们可以找到你喜欢的颜色的值:
?但是没关系,我们可以修改它的颜色,添加-c参数即可!(参数默认格式为 #号后加6位16进制),利用图像工具,我们可以找到你喜欢的颜色的值:
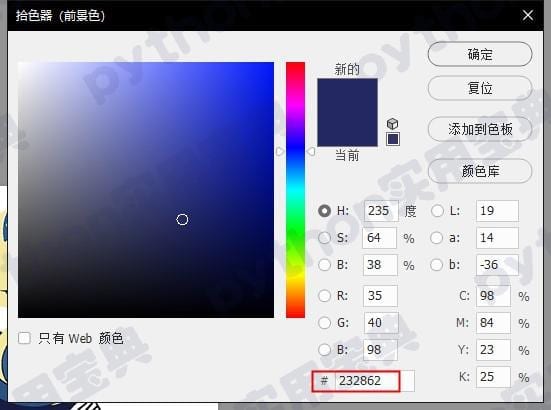
然后我们输入命令:
python marker.py -f ./input/baby.jpg -m python实用宝典 -c #232862
成功了!看看效果:

恩!变好看了![]() ,但是好像水印的颜色有点深,我们可以修改一下透明度让它变浅一点,默认的透明度为0.15,可以让这个值变得更小,设定opacity参数:
,但是好像水印的颜色有点深,我们可以修改一下透明度让它变浅一点,默认的透明度为0.15,可以让这个值变得更小,设定opacity参数:
python marker.py -f ./input/baby.jpg -m python实用宝典 -c #232862 –opacity 0.08
结果如下:

其实还有其他参数可以,我们就不一一展示了,一共有这些参数:
接下来给大家试试批量处理功能,首先把所有图片放置到项目的input文件夹下:

然后输入命令里,指定文件夹即可!
python marker.py -f ./input -m python实用宝典 -c #232862 –opacity 0.05
你会看到input文件夹名后没有/baby.jpg了,这表明将input文件夹下所有的图片打水印。
还有一个隐藏功能!如果你想要修改字体也可以哦!还记得我们前面怎么修复windows的中文名问题吗?如图,你只要将新的字体文件放到font文件夹下,然后修改TTF_FONT变量里的字体名字,与font文件夹下的新字体名字相对应即可改成你想要的字体了![]() !
!
我们的文章到此就结束啦,如果你希望我们今天的Python 教程,请持续关注我们,如果对你有帮助,麻烦在下面点一个赞/在看哦![]() 有任何问题都可以在下方留言区留言,我们都会耐心解答的!
有任何问题都可以在下方留言区留言,我们都会耐心解答的!
Python实用宝典 (pythondict.com)
不只是一个宝典
欢迎关注公众号:Python实用宝典
Mybridge AI 将github上的每个Python项目根据分享总数,读取的分钟数等特征,并用他们的算法计算出了以下2019年7月的十大开源项目![]() 。这些项目可能对你的技术生涯会很有帮助。
。这些项目可能对你的技术生涯会很有帮助。
作者用事实告诉你,建造一个机器人是一件很简单的事情。只要你的智商高于90,而且周围有一些“垃圾”可以用(树莓派、面包板等),你也可以像他一样创建一个机器人![]() 在美国,这些“垃圾”的总价格约139.96美元,在中国,你可能只要500元人民币就可以做到了。
在美国,这些“垃圾”的总价格约139.96美元,在中国,你可能只要500元人民币就可以做到了。

该项目作者讲述了将杂乱的数据源导入到PostgreSQL的多种方法。并计算了各个方法的耗时及内存消耗![]()
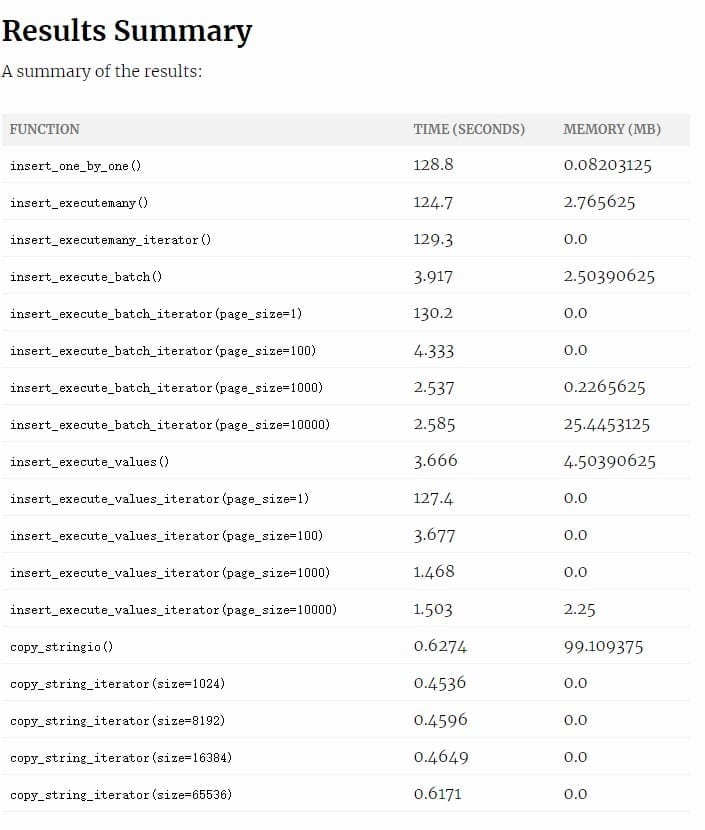
链接:https://hakibenita.com/fast-load-data-python-postgresql
一点点的小技巧可以节省你大量的时间,作者在文章中讲述了如何利用可视化、交互式、编辑器技巧等深入讲解了加速数据分析的办法,比如说神奇的Python -i XX.py可以让你的python在遇到问题的时候进入DEBUG状态,你可以在此时调试各个变量![]()
链接:https://towardsdatascience.com/10-simple-hacks-to-speed-up-your-data-analysis-in-python-ec18c6396e6b
作者通过Beautiful Soup构建了一个亚马逊的非常简单的爬虫,通过监控页面上的价格设定邮件发送机制,如果价格低于预想价格,则邮件通知用户![]() ,实现起来非常简单,不过没想到在油管上竟然有23W的观看数,惊呆了。
,实现起来非常简单,不过没想到在油管上竟然有23W的观看数,惊呆了。
链接: https://www.youtube.com/watch?v=Bg9r_yLk7VY
类型标注是Python于2014年发布的新特性,很多人都不知道这个特性到底要怎么用最有效,不过最近,确实越来越多的模块和库开始使用它了,来看看作者是怎么介绍这个新特性的吧!

链接:https://veekaybee.github.io/2019/07/08/python-type-hints/
如果你是一位爸爸或者一位妈妈,是不是会想着时时刻刻关注着婴儿的状态![]() 作者使用了一个树莓派、树莓派相机、温度传感器制作了这么一套系统,非常有趣,有兴趣的可以跟着学着做一套,相信对你的Python和树莓派知识会有很大的提高。
作者使用了一个树莓派、树莓派相机、温度传感器制作了这么一套系统,非常有趣,有兴趣的可以跟着学着做一套,相信对你的Python和树莓派知识会有很大的提高。

链接:https://www.twilio.com/blog/smart-baby-monitor-python-raspberry-pi-twilio-sms-peripheral-sensors
你有没有试过执行一个上百万条数据的清洗的时候电脑卡死![]() 有没有试过训练机器学习模型5个小时,刚到一半的时候内存溢出,自动关闭程序
有没有试过训练机器学习模型5个小时,刚到一半的时候内存溢出,自动关闭程序![]() 有没有试过服务跑着跑着自动退出,灵异事件还以为是键盘冒奶,结果发现是内存爆表
有没有试过服务跑着跑着自动退出,灵异事件还以为是键盘冒奶,结果发现是内存爆表![]() 作者告诉你,这些问题都是有办法避免的!
作者告诉你,这些问题都是有办法避免的!
链接:https://habr.com/en/post/458518/
作者在一天里就将instagram发布的机制用Python进行了自动化,能够更有效地进行任务的批处理![]() ,可惜的是视频发布在油管上,不过代码对于大家是可见的github.
,可惜的是视频发布在油管上,不过代码对于大家是可见的github.
github: https://github.com/KalleHallden/InstaAutomator
视频: https://www.youtube.com/watch?v=vnfhv1E1dU4
在这篇文章里,你将学习如何使用tweepy(一个推特爬虫软件)在Python中创建自己的Twitter Bot, 能够基本完成新的推文发表、关注账号和转推,保持账号的活跃度,俗称:养号![]()
链接: https://realpython.com/twitter-bot-python-tweepy/
Python的循环和其他语言的循环有点不太一样,这这篇文章中,作者带你深入了解Python的for循环,看看它们是怎么运作的,以及为什么它们是按照那样的方法运作的![]()

链接: https://treyhunner.com/2019/06/loop-better-a-deeper-look-at-iteration-in-python
我们的文章到此就结束啦,如果你希望我们今天的Python 教程,请持续关注我们,如果对你有帮助,麻烦在下面点一个赞/在看哦![]() 有任何问题都可以在下方留言区留言,我们都会耐心解答的!
有任何问题都可以在下方留言区留言,我们都会耐心解答的!
Python实用宝典 (pythondict.com)
不只是一个宝典
欢迎关注公众号:Python实用宝典
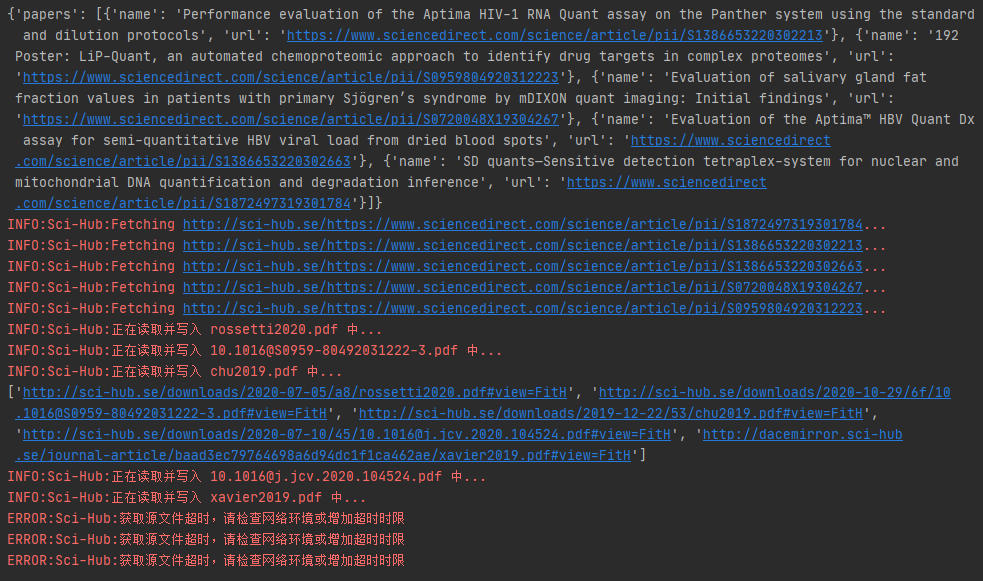
文献搜索对于广大学子来说真的是个麻烦事,如果你的学校购买的论文下载权限不够多,或者不在校园内,那就很头痛了。幸好,我们有Python制作的这个论文搜索工具,简化了我们学习的复杂性。
2020-05-28 补充:已用最新的scihub提取网,目前项目可用,感谢@lisenjor的分享。另外分享一个可用下载地址:https://sci-hub.shop/
2020-06-25 补充:增加关键词搜索批量下载论文功能。
2021-01-07 补充:增加异步下载方式,加快下载速度;加强下载稳定性,不再出现文件损坏的情况。
2021-04-08 补充:由于sciencedirect增加了机器人检验,现在搜索下载功能需要先在HEADERS中填入Cookie才可爬取。
2021-04-25 补充:搜索下载增加百度学术、publons渠道。
2021-08-10 补充:修复scihub页面结构变化导致无法下载的问题,增加DOI下载函数。
首先给大家介绍一下sci-hub这个线上数据库,这个数据库提供了 81,600,000 篇科学学术论文和文章下载。起初由一名叫 亚历珊卓·艾尔巴金 的研究生建立,她过去在哈佛大学从事研究时发现支付所需要的数百篇论文的费用实在是太高了,因此就萌生了创建这个网站,让更多人获得知识的想法

后来,这个网站越来越出名,逐渐地在更多地国家如印度、印度尼西亚、中国、俄罗斯等国家盛行,并成功地和一些组织合作,共同维护和运营这个网站。到了2017年的时候,网站上已有81600000篇学术论文,占到了所有学术论文的69%,基本满足大部分论文的需求,而剩下的31%是研究者不想获取的论文。
在起初,这个网站是所有人都能够访问的,但是随着其知名度的提升,越来越多的出版社盯上了他们,在2015年时被美国法院封禁后其在美国的服务器便无法被继续访问,因此从那个时候开始,他们就跟出版社们打起了游击战。
游击战的缺点就是导致scihub的地址需要经常更换,所以我们没办法准确地一直使用某一个地址访问这个数据库。当然也有一些别的方法可让我们长时间访问这个网站,比如说修改DNS,修改hosts文件,不过这些方法不仅麻烦,而且也不是长久之计,还是存在失效的可能的。
这是一个来自github的开源非官方API工具,下载地址为:
https://github.com/zaytoun/scihub.py
但由于作者长久不更新,原始的下载工具已经无法使用,Python实用宝典修改了作者的源代码,适配了中文环境的下载器,并添加了异步批量下载等方法:
https://github.com/Ckend/scihub-cn
欢迎给我一个Star,鼓励我继续维护这个仓库。如果你访问不了GitHub,请在 Python实用宝典 公众号后台回复 scihub,下载最新可用代码。
解压后使用CMD/Terminal进入这个文件夹,输入以下命令(默认你已经安装好了Python)安装依赖:
pip install -r requirements.txt
然后我们就可以准备开始使用啦!
这个工具使用起来非常简单,你可以先在 Google 学术(搜索到论文的网址即可)或ieee上找到你需要的论文,复制论文网址如:
http://img3.imgtn.bdimg.com/it/u=664814095,2334584570&fm=11&gp=0.jpg

然后在scihub-cn文件夹里新建一个文件叫download.py, 输入以下代码:
from scihub import SciHub
sh = SciHub()
# 第一个参数输入论文的网站地址
# path: 文件保存路径
result = sh.download('https://ieeexplore.ieee.org/document/26502', path='paper.pdf')进入该文件夹后在cmd/terminal中运行:
python download.py
你就会发现文件成功下载到你的当前目录啦,名字为paper.pdf,如果不行,多试几次就可以啦,还是不行的话,可以在下方留言区询问哦。
上述是第一种下载方式,第二种方式你可以通过在知网或者百度学术上搜索论文拿到DOI号进行下载,比如:
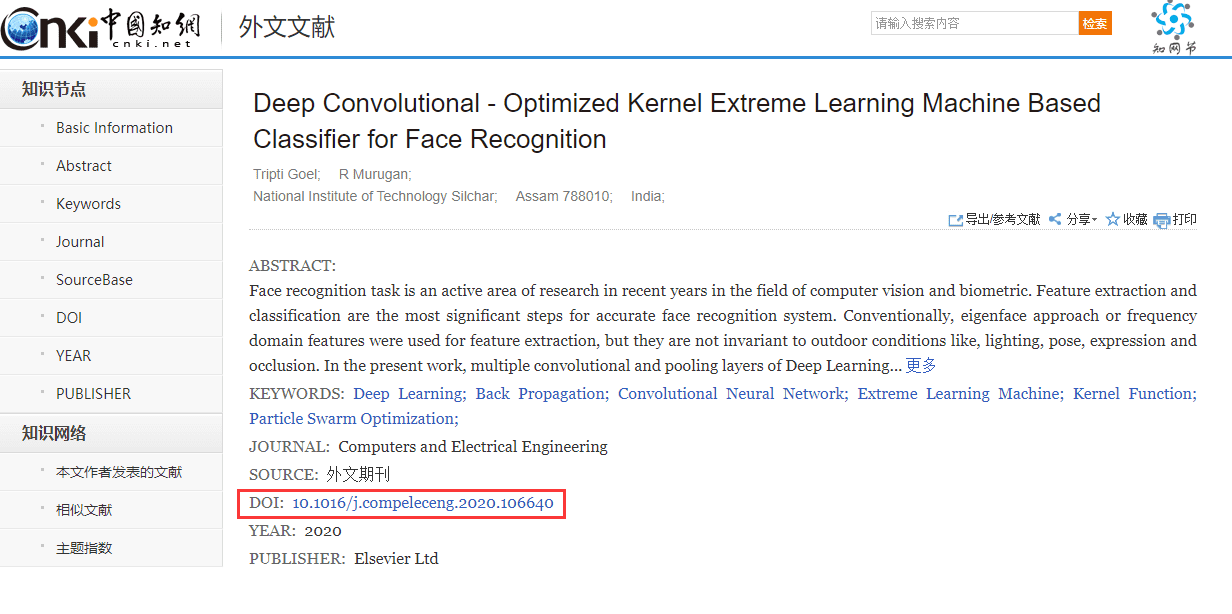
from scihub import SciHub
sh = SciHub()
result = sh.download('10.1016/j.compeleceng.2020.106640', path='paper2.pdf')下载完成后就会在文件夹中出现该文献:
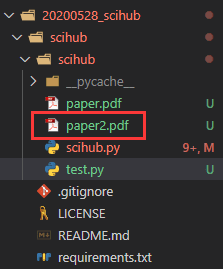
除了这种最简单的方式,我们还提供了 论文关键词搜索批量下载 及 论文关键词批量异步下载 两种高级的下载方法。
我们在下文将会详细地讲解这两种方法的使用,大家可以看项目内的 test.py 文件,你可以了解到论文搜索批量下载的方法。
进一步的高级方法在download.py 中可以找到,它可以实现论文搜索批量异步下载,大大加快下载速度。具体实现请看后文。
支持使用搜索的形式批量下载论文,比如说搜索关键词 量化投资(quant):
from scihub import SciHub
sh = SciHub()
# 搜索词
keywords = "quant"
# 搜索该关键词相关的论文,limit为篇数
result = sh.search(keywords, limit=10)
print(result)
for index, paper in enumerate(result.get("papers", [])):
# 批量下载这些论文
sh.download(paper["doi"], path=f"files/{keywords.replace(' ', '_')}_{index}.pdf")运行结果,下载成功:
2021-04-25 更新:
由于读者们觉得Sciencedirect的搜索实在太难用了,加上Sciencedirect现在必须要使用Cookie才能正常下载,因此我新增了百度学术和publons这2个检索渠道。
由于 Web of Science 有权限限制,很遗憾我们无法直接使用它来检索,不过百度学术作为一个替代方案也是非常不错的。
现在默认的 search 函数调用了百度学术的接口进行搜索,大家不需要配置任何东西,只需要拉一下最新的代码,使用上述例子中的代码就可以正常搜索下载论文。
其他两个渠道的使用方式如下:
sciencedirect渠道:
由于 sciencedirect 加强了他们的爬虫防护能力,增加了机器人校验机制,所以现在必须在HEADER中填入Cookie才能进行爬取。
操作如下:
1.获取Cookie
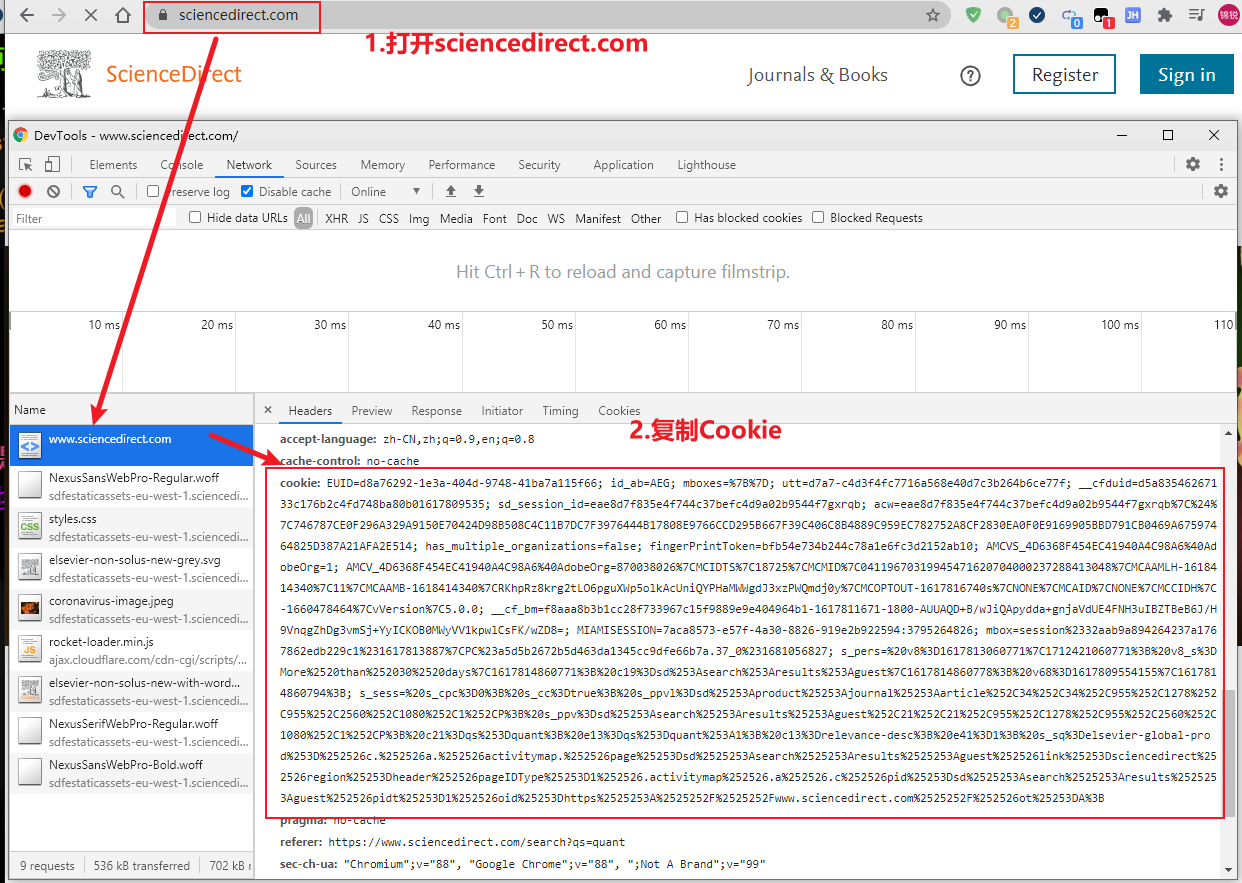
2.使用sciencedirect搜索时,需要用search_by_science_direct函数,并将cookie作为参数之一传入:
from scihub import SciHub
sh = SciHub()
# 搜索词
keywords = "quant"
# 搜索该关键词相关的论文,limit为篇数
result = sh.search_by_science_direct(keywords, cookie="你的cookie", limit=10)
print(result)
for index, paper in enumerate(result.get("papers", [])):
# 批量下载这些论文
sh.download(paper["doi"], path=f"files/{keywords.replace(' ', '_')}_{index}.pdf")这样就能顺利通过sciencedirect搜索论文并下载了。
publons渠道:
其实有了百度学术的默认渠道,大部分文献我们都能覆盖到了。但是考虑到publons的特殊性,这里还是给大家一个通过publons渠道搜索下载的选项。
使用publons渠道搜索下载其实很简单,你只需要更改搜索的函数名即可,不需要配置Cookie:
from scihub import SciHub
sh = SciHub()
# 搜索词
keywords = "quant"
# 搜索该关键词相关的论文,limit为篇数
result = sh.search_by_publons(keywords, limit=10)
print(result)
for index, paper in enumerate(result.get("papers", [])):
# 批量下载这些论文
sh.download(paper["doi"], path=f"files/{keywords.replace(' ', '_')}_{index}.pdf")这份代码已经运行了几个月,经常有同学反馈搜索论文后批量下载论文的速度过慢、下载的文件损坏的问题,这几天刚好有时间一起解决了。
下载速度过慢是因为之前的版本使用了串行的方式去获取数据和保存文件,事实上对于这种IO密集型的操作,最高效的方式是用 asyncio 异步的形式去进行文件的下载。
而下载的文件损坏则是因为下载时间过长,触发了超时限制,导致文件传输过程直接被腰斩了。
因此,我们将在原有代码的基础上添加两个方法:1.异步请求下载链接,2.异步保存文件。
此外增加一个错误提示:如果下载超时了,提示用户下载超时并不保存损坏的文件,用户可自行选择调高超时限制。
首先,新增异步获取scihub直链的方法,改为异步获取相关论文的scihub直链:
async def async_get_direct_url(self, identifier):
"""
异步获取scihub直链
"""
async with aiohttp.ClientSession() as sess:
async with sess.get(self.base_url + identifier) as res:
logger.info(f"获取 {self.base_url + identifier} 中...")
# await 等待任务完成
html = await res.text(encoding='utf-8')
s = self._get_soup(html)
frame = s.find('iframe') or s.find('embed')
if frame:
return frame.get('src') if not frame.get('src').startswith('//') \
else 'http:' + frame.get('src')
else:
logger.error("Error: 可能是 Scihub 上没有收录该文章, 请直接访问上述页面看是否正常。")
return html这样,在搜索论文后,调用该接口就能获取所有需要下载的scihub直链,速度很快:
def search(keywords: str, limit: int):
"""
搜索相关论文并下载
Args:
keywords (str): 关键词
limit (int): 篇数
"""
sh = SciHub()
result = sh.search(keywords, limit=limit)
print(result)
loop = asyncio.get_event_loop()
# 获取所有需要下载的scihub直链
tasks = [sh.async_get_direct_url(paper["doi"]) for paper in result.get("papers", [])]
all_direct_urls = loop.run_until_complete(asyncio.gather(*tasks))
print(all_direct_urls)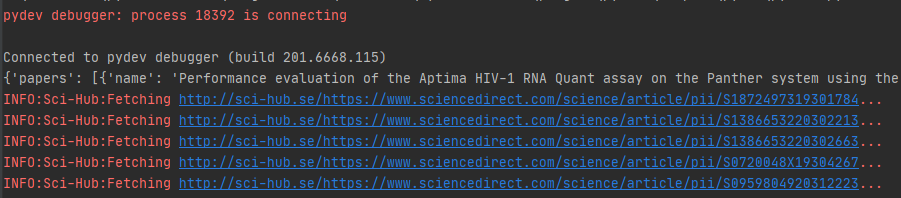
获取直链后,需要下载论文,同样也是IO密集型操作,增加2个异步函数:
async def job(self, session, url, destination='', path=None):
"""
异步下载文件
"""
if not url:
return
file_name = url.split("/")[-1].split("#")[0]
logger.info(f"正在读取并写入 {file_name} 中...")
# 异步读取内容
try:
url_handler = await session.get(url)
content = await url_handler.read()
except Exception as e:
logger.error(f"获取源文件出错: {e},大概率是下载超时,请检查")
return str(url)
with open(os.path.join(destination, path + file_name), 'wb') as f:
# 写入至文件
f.write(content)
return str(url)
async def async_download(self, loop, urls, destination='', path=None):
"""
触发异步下载任务
如果你要增加超时时间,请修改 total=300
"""
async with aiohttp.ClientSession(timeout=aiohttp.ClientTimeout(total=300)) as session:
# 建立会话session
tasks = [loop.create_task(self.job(session, url, destination, path)) for url in urls]
# 建立所有任务
finished, unfinished = await asyncio.wait(tasks)
# 触发await,等待任务完成
[r.result() for r in finished]这样,最后,在search函数中补充下载操作:
import asyncio
from scihub import SciHub
def search(keywords: str, limit: int):
"""
搜索相关论文并下载
Args:
keywords (str): 关键词
limit (int): 篇数
"""
sh = SciHub()
result = sh.search(keywords, limit=limit)
print(result)
loop = asyncio.get_event_loop()
# 获取所有需要下载的scihub直链
tasks = [sh.async_get_direct_url(paper["doi"]) for paper in result.get("papers", [])]
all_direct_urls = loop.run_until_complete(asyncio.gather(*tasks))
print(all_direct_urls)
# 下载所有论文
loop.run_until_complete(sh.async_download(loop, all_direct_urls, path=f"files/"))
loop.close()
if __name__ == '__main__':
search("quant", 10)
一个完整的下载过程就OK了:
比以前的方式舒服太多太多了… 如果你要增加超时时间,请修改async_download函数中的 total=300,把这个请求总时间调高即可。
最新代码前往GitHub上下载:
https://github.com/Ckend/scihub-cn
或者从Python实用宝典公众号后台回复 scihub 下载。
最近有同学希望直接通过DOI号下载文献,因此补充了这部分内容。
import asyncio
from scihub import SciHub
def fetch_by_doi(dois: list, path: str):
"""
根据 doi 获取文档
Args:
dois: 文献DOI号列表
path: 存储文件夹
"""
sh = SciHub()
loop = asyncio.get_event_loop()
# 获取所有需要下载的scihub直链
tasks = [sh.async_get_direct_url(doi) for doi in dois]
all_direct_urls = loop.run_until_complete(asyncio.gather(*tasks))
print(all_direct_urls)
# 下载所有论文
loop.run_until_complete(sh.async_download(loop, all_direct_urls, path=path))
loop.close()
if __name__ == '__main__':
fetch_by_doi(["10.1088/1751-8113/42/50/504005"], f"files/")默认存储到files文件夹中,你也可以根据自己的需求对代码进行修改。
这个API的源代码其实非常好读懂。
首先它会在这个网址里找到sci-hub当前可用的域名,用于下载论文:
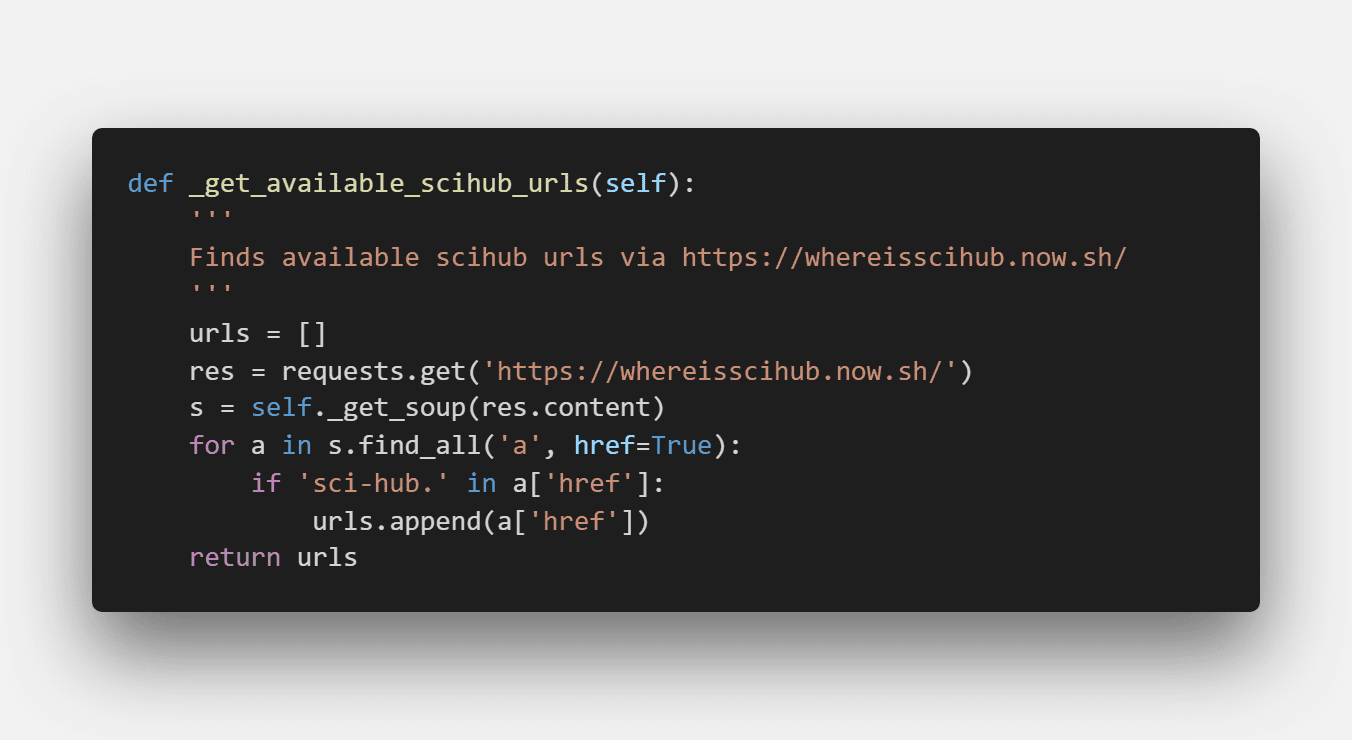
可惜的是,作者常年不维护,该地址已经失效了,我们就是在这里修改了该域名,使得项目得以重新正常运作:

1. 如果用户输入的链接不是直接能下载的,则使用sci-hub进行下载
2. 如果scihub的网址无法使用则切换另一个网址使用,除非所有网址都无法使用。

3.如果用户输入的是关键词,将调用sciencedirect的接口,拿到论文地址,再使用scihub进行论文的下载。
1. 拿到论文后,它保存到data变量中
2. 然后将data变量存储为文件即可
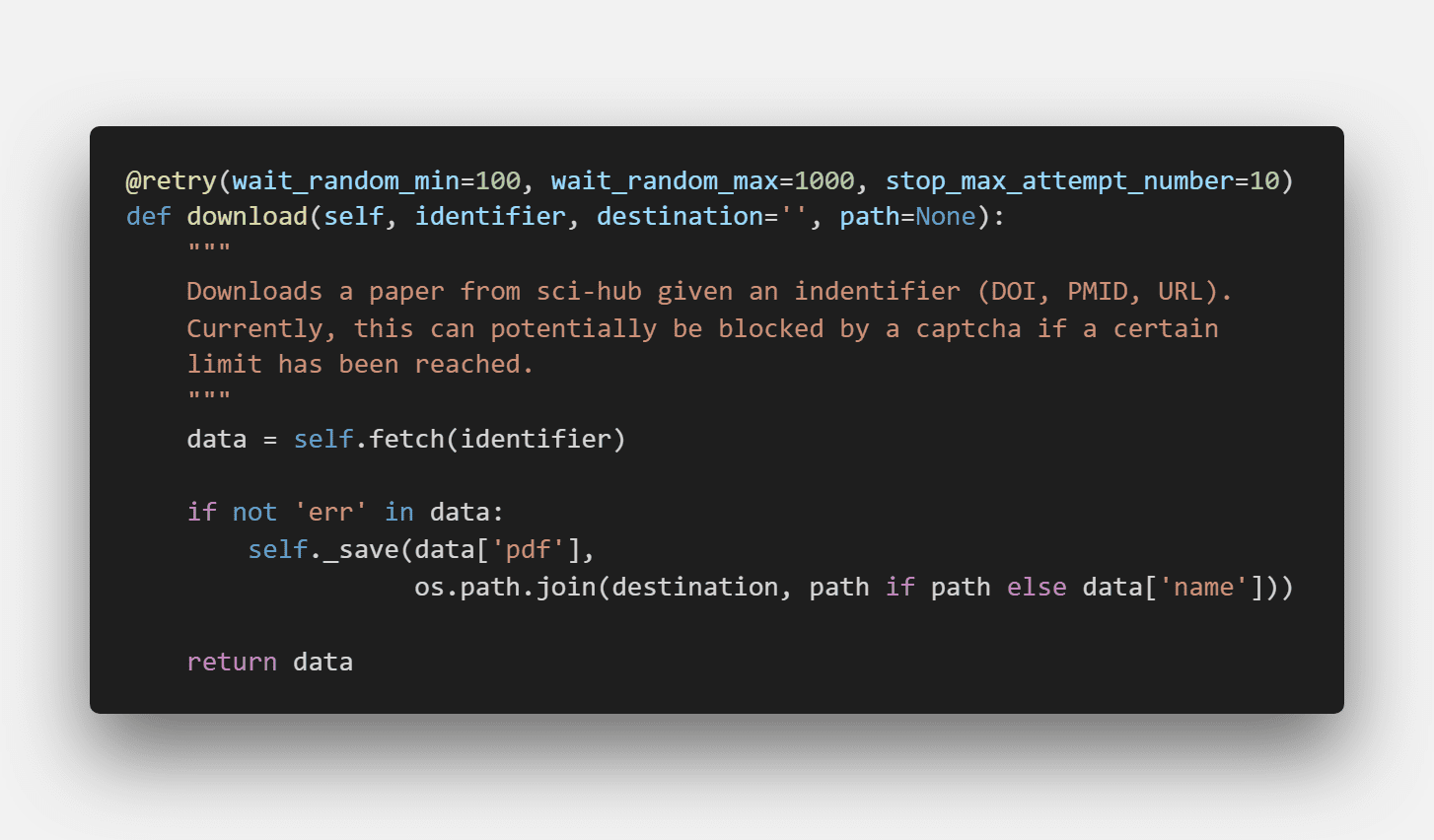
此外,代码用到了一个retry装饰器,这个装饰器可以用来进行错误重试,作者设定了重试次数为10次,每次重试最大等待时间不超过1秒。
我们的文章到此就结束啦,如果你希望我们今天的文章,请持续关注我们,如果对你有帮助,麻烦在下面点一个赞/在看哦,有任何问题都可以在下方留言区留言,我们都会耐心解答的!
Python实用宝典 (pythondict.com)
不只是一个宝典
欢迎关注公众号:Python实用宝典
想知道Python取得如此巨大成功的原因吗?只要看看Python提供的大量库就知道了![]() ,包括原生库和第三方库。不过,有这么多Python库,有些库得不到应有的关注也就不足为奇了。此外,只在一个领域里的工作的人并不知道另一个领域里有什么好东西,不知道其他领域的东西能产出什么有用的价值。
,包括原生库和第三方库。不过,有这么多Python库,有些库得不到应有的关注也就不足为奇了。此外,只在一个领域里的工作的人并不知道另一个领域里有什么好东西,不知道其他领域的东西能产出什么有用的价值。
下面给大家列出10个你可能忽略,但绝对值得注意的Python库![]() ,这些工具的用途非常广泛, 简化了从文件系统访问、数据库编程、云服务到构建轻量级web应用程序、创建gui、图像工具、Excel和Word文件等等的事情的工作复杂度。有些库是众所周知的,有些则不太为人所知,但是所有这些Python库都应该在各位的工具箱中占有一席之地。
,这些工具的用途非常广泛, 简化了从文件系统访问、数据库编程、云服务到构建轻量级web应用程序、创建gui、图像工具、Excel和Word文件等等的事情的工作复杂度。有些库是众所周知的,有些则不太为人所知,但是所有这些Python库都应该在各位的工具箱中占有一席之地。
Arrow: 让你更方便地处理日期和时间。
为什么要使用Arrow:还记得我们之前讲过的日期计算吗?实际上那是一个简单的计算教程,思考一下,如果我们想要切换时区怎么办、更加灵活地日期格式化怎么做?即便是像python这么好用的工具,如果你只用原生库,你也得折腾上一阵子。现在我们有了更好的选择:Arrow.
Arrow拥有四大优势。首先,箭头是Python的datetime模块的一个替代品,这意味着像.now()和.utcnow()这样的公共函数调用可以正常工作。第二,Arrow提供了一些通用的方法,比如转换时区。第三,Arrow提供了“人性化”的日期/时间信息,比如能够毫不费力地说出“一小时前”或“两小时后”发生的事情(就如同我们在暑期余额里讲的那样)。第四,Arrow可以轻松地本地化日期/时间信息。
下面是Arrow使用的三个例子:
import arrow
# 例1:获得当前时间戳
t = arrow.utcnow()
print(t.timestamp) # 1566128587
# 例2:获得当前时间,并格式化为字符串
t = arrow.now()
s1 = t.format()
print(s1) # 2019-08-18 19:43:07+08:00
s2 = t.format("YYYY-MM-DD")
print(s2) # 2019-08-18
# 例3:字符串转Arrow,并格式化为其他格式的字符串
t = arrow.get("2019-12-31 11:30", "YYYY-MM-DD HH:mm")
s3 = t.format('YYYYMMDD')
print(s3) # 20191231Behold: 强大的代码调试工具。
如果你只是使用print进行项目的调试,你会发现在大型项目的时候,这一招根本行不通![]() 因为大型项目的数据流动非常复杂,你必须跟踪一个变量的流动才行,这时候你可能会出现每隔几句就写一个print的尴尬情况。这时候Behold就非常有优势了,它具有搜索、筛选、排序功能,而且能跨模块地展示数据流向。
因为大型项目的数据流动非常复杂,你必须跟踪一个变量的流动才行,这时候你可能会出现每隔几句就写一个print的尴尬情况。这时候Behold就非常有优势了,它具有搜索、筛选、排序功能,而且能跨模块地展示数据流向。
建议阅读官方例子: https://behold.readthedocs.io/en/latest/ref/behold.html
black:使用严格的规则格式化Python代码。
black是一个毫不妥协的格式化工具,它检测到不符合规范的代码风格直接给你全部格式化了,不需要你自己确定,非常适合代码风格紊乱的人群进行自我纠正![]() ,使用也非常简单, CMD/Terminal安装black:
,使用也非常简单, CMD/Terminal安装black:
pip install black
然后同样,CMD/Terminal进入到你的Python文件的文件夹里,输入:
black 你的文件名.py
即可格式化该文件里的代码
Bottle:轻量级网站/api开发工具。
当你想要构建一个快速的RESTful API或者使用web框架的基本框架来构建一个应用程序时,Bottle完全就够用了。路由、模板、请求和响应、支持许多种请求协议,甚至如websockets之类的高级功能都支持。同样,启动所需的工作量也很小,而且当需要更高级的功能时,Bottle可以很好地扩展,非常优秀![]() 。
。
Click: 让你快速地为Python应用程序构建命令行界面。
在没有用click之前,我们是如何获取用户输入的? 是用 val = input(xxx) 这样的形式吧?虽然也非常简单,但是当你想要给它设定默认值的时候就麻烦了![]() 然而click可以让你消去这样的烦恼:
然而click可以让你消去这样的烦恼:
import click
@click.option('--count', default=1, help='Number of greetings')
@click.option('--name', prompt='您的名字是', help='用户的名称')我的天,简直是上天给予Python程序员的礼物啊。更多的功能请阅读官方文档,比如它还能设定输入参数:
import click
@click.command()
@click.option('--count', default=1, help='欢迎次数.')
@click.option('--name', prompt='您的名字是', help='用户的名称')
def hello(count, name):
"""欢迎名字为name的用户count次."""
for x in range(count):
click.echo('Hello %s!' % name)
if __name__ == '__main__':
hello()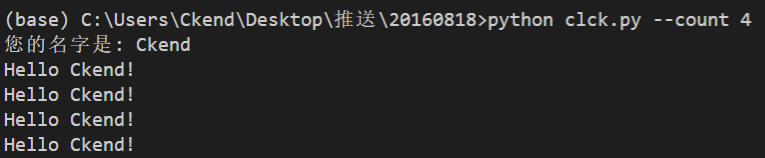
Nuitka: 将Python编译成C++级的可执行文件。
重点是C++级的应用,速度快!速度快!速度快!尽管Cython也能够把Python编译成C,但是Cython仅仅关注数学和统计应用程序,而Nuitka可以按原样使用任何Python程序编译为C,生成单文件的可执行文件。虽然目前还在早期阶段,但是可以预想到它的未来是多么的辉煌![]()
Numba: 有选择地加速数学计算。
这是我以前梦寐以求的功能,我们知道Numpy通过在Python接口中封装高速的C库进行工作,Cython将某些用户选择的类型编译为C,但是我们发现这些东西用起来都不是很顺手,感觉“命运 ” 不是由我掌控的。有了Numba之后,我们可以对函数进行加速![]() 你要做的仅仅是在函数上方加一个装饰器,这可真的是非常舒服:
你要做的仅仅是在函数上方加一个装饰器,这可真的是非常舒服:
@nb.jit(nopython=True) def acc(x):
openpyxl: 读取,写入和操作Excel文件。
还记得我们的日历文章吗?我们在那篇文章里就用到了openpyxl这个库,实质上,用于操作Excel的不止有这个库可以做到,但是它有一些独特的功能,比如,写成最新的文件格式xlsx,而且它对文件大小是没有限制的,就这两个功能已经完爆xlwt了。当然,它在速度上是比不过xlwt的,这就需要各位权衡使用了![]()
peewee: 支持sqlite, Mysql及PostgreSQL的小型ORM(方便写数据库的)。
这是我在python上接触的第一个ORM,不是所有人都喜欢用这个玩意儿,但是对于那些不喜欢接触SQL语句开发的人来说,这玩意儿简直是宝物啊![]() 。peewee非常易于构建、连接、操作数据库,然后内置了许多的查询操作功能。不过需要注意的是,peewee 3.x 并不完全向旧版本兼容。
。peewee非常易于构建、连接、操作数据库,然后内置了许多的查询操作功能。不过需要注意的是,peewee 3.x 并不完全向旧版本兼容。
PyFilesystem: 简化了文件、目录的处理方法,支持任何文件系统的操作,大幅度提高编程效率。
你的开发过程中,有没有为这样的事情忧愁过:打开一个不存在文件夹里的文件(新建),确定某个目录里是否存在某个文件,确定是否存在某个目录![]() ,当然如果你非常熟练os和io模块,你会觉得这些事情简直是so easy. 但是对于一些不熟悉这两个模块的语句的同学,这可得Google一下。幸好,现在有了PyFilesystem, 我们的编程生活能够快乐许多。它能支持任何文件系统的操作,而且提供了许多实用的函数,比如说查看当前目录下的文件:
,当然如果你非常熟练os和io模块,你会觉得这些事情简直是so easy. 但是对于一些不熟悉这两个模块的语句的同学,这可得Google一下。幸好,现在有了PyFilesystem, 我们的编程生活能够快乐许多。它能支持任何文件系统的操作,而且提供了许多实用的函数,比如说查看当前目录下的文件:
from fs import open_fs
my_fs = open_fs('.')
print(my_fs.listdir('/')) 显示目录结构树
from fs import open_fs
my_fs = open_fs('.')
my_fs.tree()当然还有更多的功能,请阅读官方文档。
Python实用宝典 (pythondict.com)
不只是一个宝典
欢迎关注公众号:Python实用宝典

本来想浪漫一把去看个日出,过去后看见天上挂着个大太阳的尴尬情景你经历过吗?![]()
本来想去海边看个日落,结果车到了,太阳也落了的悲伤情景你经历过吗?![]()
我们今天要用Python解决的,就是这种尴尬情况:想到某个地点看日出日落,却不知道那个地方准确的日出日落时间。
需要使用的包是 Astral ,这个包能通过你提供的经纬度并利用相应的数学知识计算日出日落时间。下面就来以西涌三号沙滩为例,告诉大家怎么样超级简单地计算某个地点日出日落的时间。
进行这个实验,你需要安装 python3. 如果你还没有安装,可以看这个教程: https://www.runoob.com/python3/python3-install.html
安装完毕后,Windows 点击 开始 – 运行 – 输入CMD – 回车进入CMD窗口 (macOS 则打开Terminal) 输入下面这条指令:
pip install Astral
出现 Successfully installed astral-1.10.1 则说明安装成功。
1.接下来我们就以西冲三号沙滩为例,告诉大家怎么计算它的准确日出日落时间![]()
2.首先打开百度地图的坐标拾取器: http://api.map.baidu.com/lbsapi/getpoint/index.html
3.然后搜索我们想要的地点:西冲 , 然后找到我们想要去的沙滩
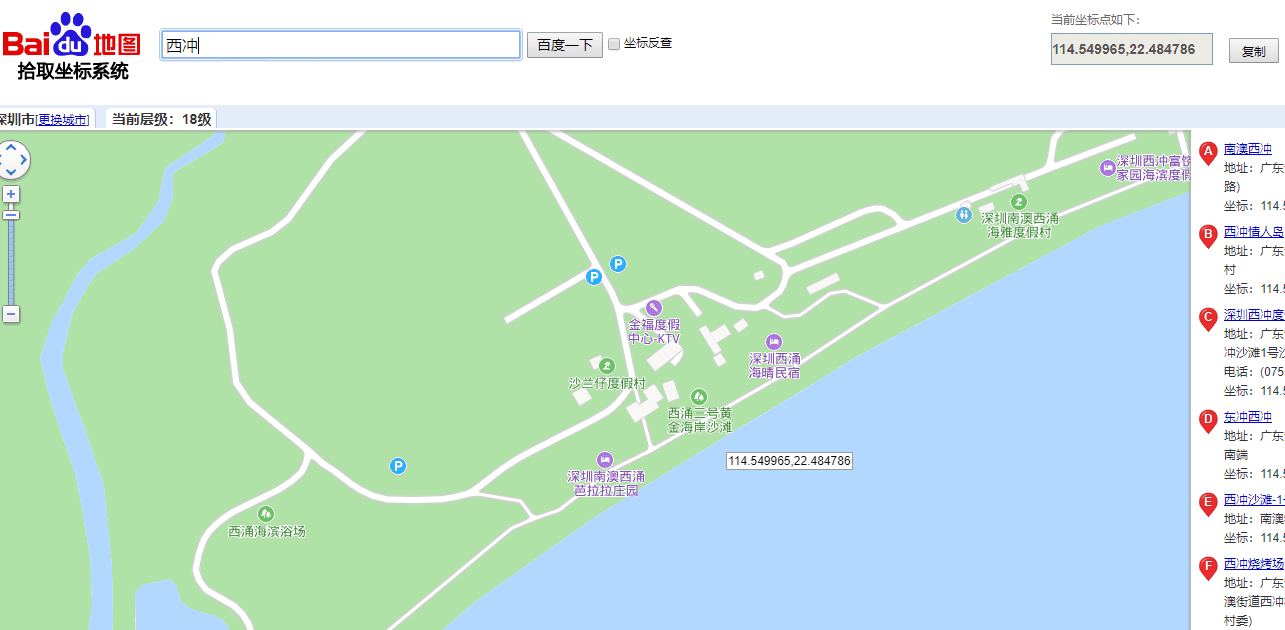
可以看到右上角就有我们想要的坐标:114.549965, 22.484786 (维度,经度),接下来我们就利用这个数据计算这个沙滩的日出时间![]()
# sun_rise_down.py
import datetime
import astral
location_XiChong = astral.Location(('XiChong', 'China', 22.484786,114.549965, 'Asia/Shanghai', 0))
# 记录西冲地点,注意先经度后维度
sunrise=location_XiChong.sunrise(date=datetime.date.today(),local=True)
# 计算今天的日出时间
time_sunrise_new = str(sunrise)
print(time_sunrise_new)新建文件并写入代码到sun_rise_down.py中,然后进入 CMD/Terminal,cd到你的文件存放的目录,输入:
python sun_rise_down.py

这是计算了今天的日出,即2019年8月16日的日出为05:59:01时。那么我想计算明天的时间怎么办呢?我们只需要将
sunrise = location_XiChong.sunrise(date=datetime.date.today(),local=True)
改为
sunrise = location_XiChong.sunrise(date=datetime.date(2019, 8, 17),local=True)
这样就能计算17日的日出时间啦!

同样地,日落时间我们只需要将sunrise函数更改成sunset函数即可:
sunset = location_XiChong.sunset(date=datetime.date(2019, 8, 17), local=True) time_sunset_new = str(sunset) print(time_sunset_new)
整体代码:
# sun_rise_down.py
import datetime
import astral
location_XiChong = astral.Location(('XiChong', 'China', 22.484786,114.549965, 'Asia/Shanghai', 0))
# 记录西冲地点,注意先经度后维度
sunrise = location_XiChong.sunrise(date=datetime.date(2019, 8, 17),local=True)
# 计算相应时间的日出
sunrise_new = str(sunrise)
print(sunrise_new)
sunset = location_XiChong.sunset(date=datetime.date(2019, 8, 17),local=True)
# 计算相应时间的日落
sunset_new = str(sunset)
print(sunset_new) 进入Cmd/Terminal,cd到文件的文件夹下,运行
python sun_rise_down.py
得到结果:

怎么样, Astral 是不是超级好用的工具![]() 简直是情侣、摄影师、吃瓜群众出行必备工具。而且!其实它还可以计算指定日期的月相,超级方便,如果大家有兴趣的话可以查看他们的官方文档: https://astral.readthedocs.io/en/stable/index.html
简直是情侣、摄影师、吃瓜群众出行必备工具。而且!其实它还可以计算指定日期的月相,超级方便,如果大家有兴趣的话可以查看他们的官方文档: https://astral.readthedocs.io/en/stable/index.html
我们的教程到此结束啦,如果你觉得有帮助的话,请记得点一个赞哦!如果你有任何的问题,不要犹豫,请在下方的留言区留言,我们会抽空回答哒![]()
Python实用宝典 (pythondict.com)
不只是一个宝典
欢迎关注公众号:Python实用宝典
Python问世至今已经三十年左右了,但其仅在过去几年人气迅速飙升超过了除java和C以外的其他语言。总的来说,Python已经成为教学、学习编程和软件开发的优秀起点,而且其可以成为任何技术栈中有价值的一部分。
不幸的是,这样的流行程度也会暴露Python的缺点,最显著且众所周知的缺点是这三个:运算性能、打包及可执行程序的生成、项目管理![]() 虽然这三个缺点都不是非常致命,但是和其他处于上升通道的语言如Julia、Nim、Rust和Go相比,Python的劣势将越来越明显。
虽然这三个缺点都不是非常致命,但是和其他处于上升通道的语言如Julia、Nim、Rust和Go相比,Python的劣势将越来越明显。
下面给大家讲讲Python程序员面临的这三个缺点,以及Python与其第三方工具开发人员提出的解决这些缺点的方法。
Python 整体性能缓慢,有限的线程和多处理能力是其未来发展的主要障碍。
Python长期以来一直重视编程的易用性而不是运行时的速度。当通过使用C或C++编写的高速外部库(如Numpy和Numba)在Python中完成如此多的性能密集型任务时,你会发现Python重视编程的易用性也是一种不错的选择。但是尽管如此,Python的开箱即用的性能速度依然落后于其他语言,比如说具有同样简单语法的Nim和Julia,却可以被编译为机器代码,具有更高的性能优势。
Python无法全面利用多核处理器是其长久以来的问题,它确实具有线程功能,但它的线程功能是局限于单个核心的。虽然Python可以使用多进程,但是调度和同步这些子进程的结果并不总是有效的![]()
目前没有单一,自上而下的整体解决方案来解决Python的性能问题,不过我们有一系列加速Python的举措。比如说:
如果你是高手,你还能尝试摆脱一下GIL(全局解释器锁),之所以Python的多线程是假的,就是因为GIL的存在:它用来保证Python同时只能有一个线程运行。因此从理论上来讲,如果你摆脱了GIL,就能进行多线程运算,可以提高性能。
还有一个正在进行的项目能够解决许多速度提升的问题,即重构Python内部C接口的实现,一个不混乱的接口可以使得许多性能的改进成为可能。
即使在Python诞生30年后,Python依然没有很好的方法来生成可执行文件(exe程序等)![]() 我们只能通过第三方工具解决。而且用起来比较麻烦。
我们只能通过第三方工具解决。而且用起来比较麻烦。
当你想将一个本地比较复杂的Python工程移植到服务器上的时候,你就知道Python项目管理是有多蛋疼了![]() 你需要不断地安装项目依赖,依赖的依赖可能还有依赖,就像俄罗斯俄罗斯套娃一样,恨不得直接把键盘吃了。
你需要不断地安装项目依赖,依赖的依赖可能还有依赖,就像俄罗斯俄罗斯套娃一样,恨不得直接把键盘吃了。
文章到此就结束啦!如果你看完后觉得有收获,记得点一下在看,让更多小伙伴看到这篇文章吧!如果你有其他的小问题,可以在下方窗口留言哦!
Python实用宝典 (pythondict.com)
不只是一个宝典
欢迎关注公众号:Python实用宝典








{kind=link}