

语音克隆是这两年比较火的深度学习应用,它允许从几秒钟的音频中学习对象的说话方式和音调,并使用它来生成新的语音。
下面来看看我使用 SV2TTS 训练模仿卷福阅读下面这句话的效果:
She is beginning to get many wrinkles around her eyes.
训练集:

克隆、模仿效果(She is beginning to get many wrinkles around her eyes.):
效果不错,如果不知道它是生成的,还以为真的是卷福念的。
下面就来教大家如何使用 Real-Time-Voice-Cloning 项目克隆语音并生成自己想要的语句。
1.准备
大家可以前往 Real-Time-Voice-Cloning 项目下载这个项目的代码以及预训练完成的模型。(注意,需要Python 3.6以上才能运行该项目)
如果你的网络速度比较差,下载不了 github 项目及其预训练模型,可以在 Python 实用宝典 公众号后台回复 克隆语音 下载完整项目代码及预训练模型。
下载完项目代码后,你还需要下载两个重要依赖:
安装 PyTorch
其中,PyTorch的官方指南已经写得很清楚了,大家根据自己的需求安装即可。
安装 ffmpeg
而 ffmpeg 的安装我们已经在这篇文章详细地讲过:Python 多种音乐格式转换(批量)实战教程,在此重新讲解一下:
Mac (打开终端(Terminal), 用 homebrew 安装):
brew install ffmpeg --with-libvorbis --with-sdl2 --with-theora
Linux:
apt-get install ffmpeg libavcodec-extra
Windows:
1. 进入 http://ffmpeg.org/download.html#build-windows,点击 windows 对应的图标,进入下载界面点击 download 下载按钮,
2. 解压下载好的zip文件到指定目录
3. 将解压后的文件目录中 bin 目录(包含 ffmpeg.exe )添加进 path 环境变量中
安装模块依赖
安装完成以上两个重要依赖后,在终端、命令行中进入项目目录中,安装依赖:
pip install -r requirements.txt
这会安装所有 requirements.txt 中的所有依赖。
2.下载预训练模型(可选)
如果你用的是我们提供的项目文件,你就不需要再进行这一步了,因为把预训练的模型都已经放进去了。
如果你没有用Python实用宝典提供的项目代码,你还需要去下载预训练的模型:
https://github.com/CorentinJ/Real-Time-Voice-Cloning/wiki/Pretrained-models
下载完成后解压 pretrained.zip 分别将对应的模型放入项目对应的位置中:
encoder\saved_models\pretrained.pt synthesizer\saved_models\pretrained\pretrained.pt vocoder\saved_models\pretrained\pretrained.pt
3.试一下克隆语音
随便选取一段你想要克隆的人的语音,大概30秒左右,放入项目文件夹中。然后在该文件夹中运行命令:
python demo_cli.py
如果一切正常,它会出现让你选择训练语音文件:

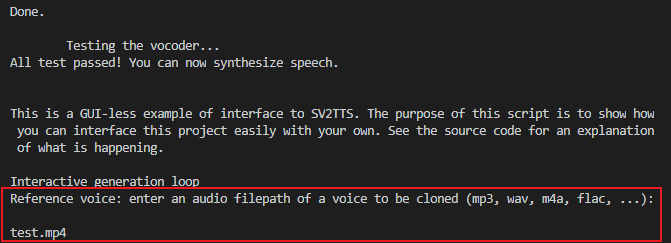
此时输入你准备好的一段语音,等待它训练完成后,它会让你输入想要模仿的文字:

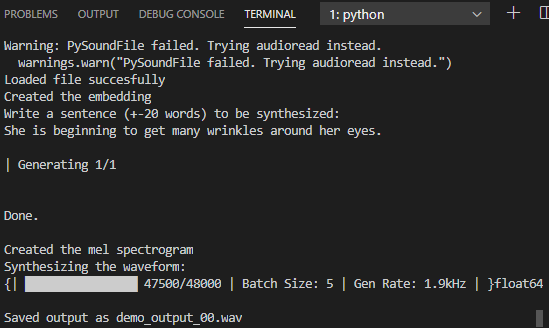
比如上图中,我输入了:
She is beginning to get many wrinkles around her eyes.
程序生成完毕后会自动念出克隆结果,如果你没有听见克隆结果,没关系,程序会将其保存在当前文件夹下,命名为 demo_output_xx.wav.
双击打开这个文件,就是它生成的语音克隆结果啦,听听看,是不是你想要的效果?
如果没有达到你的理想效果,请检查一下训练集是否有杂音、时间够不够长、有没有其他人的介入,这些因素都可能导致克隆效果不理想。
我们的文章到此就结束啦,如果你喜欢今天的 Python 教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 ( pythondict.com )
不只是一个宝典
欢迎关注公众号:Python实用宝典

