

bert-serving 模型及源代码
提供百度网盘下载。
bert-serving 模型及源代码
提供百度网盘下载。

鼎鼎大名的 Bert 算法相信大部分同学都听说过,它是Google推出的NLP领域“王炸级”预训练模型,其在NLP任务中刷新了多项记录,并取得state of the art的成绩。
但是有很多深度学习的新手发现BERT模型并不好搭建,上手难度很高,普通人可能要研究几天才能勉强搭建出一个模型。
没关系,今天我们介绍的这个模块,能让你在3分钟内基于BERT算法搭建一个问答搜索引擎。它就是 bert-as-service 项目。这个开源项目,能够让你基于多GPU机器快速搭建BERT服务(支持微调模型),并且能够让多个客户端并发使用。
开始之前,你要确保Python和pip已经成功安装在电脑上,如果没有,请访问这篇文章:超详细Python安装指南 进行安装。
(可选1) 如果你用Python的目的是数据分析,可以直接安装Anaconda:Python数据分析与挖掘好帮手—Anaconda,它内置了Python和pip.
(可选2) 此外,推荐大家用VSCode编辑器来编写小型Python项目:Python 编程的最好搭档—VSCode 详细指南
Windows环境下打开Cmd(开始—运行—CMD),苹果系统环境下请打开Terminal(command+空格输入Terminal),输入命令安装依赖:
pip install bert-serving-server # 服务端 pip install bert-serving-client # 客户端
请注意,服务端的版本要求:Python >= 3.5,Tensorflow >= 1.10 。
此外还要下载预训练好的BERT模型,在 https://github.com/hanxiao/bert-as-service#install 上可以下载,如果你无法访问该网站,也可以在 bert-serving 模型及源代码 此处下载。
也可在Python实用宝典后台回复 bert-as-service 下载这些预训练好的模型。
下载完成后,将 zip 文件解压到某个文件夹中,例如 /tmp/uncased_L-24_H-1024_A-16/.
安装完成后,输入以下命令启动BERT服务:
bert-serving-start -model_dir /tmp/uncased_L-24_H-1024_A-16/ -num_worker=4
-num_worker=4 代表这将启动一个有四个worker的服务,意味着它最多可以处理四个并发请求。超过4个其他并发请求将在负载均衡器中排队等待处理。
下面显示了正确启动时服务器的样子:
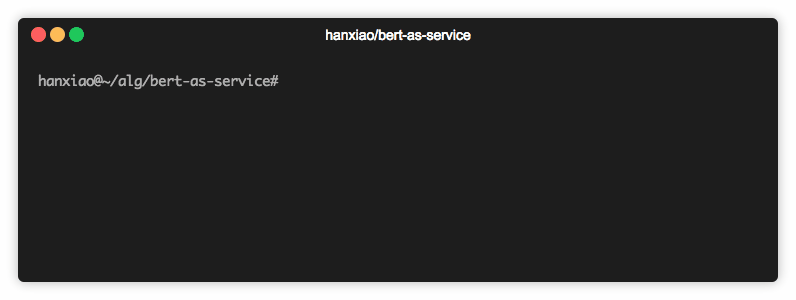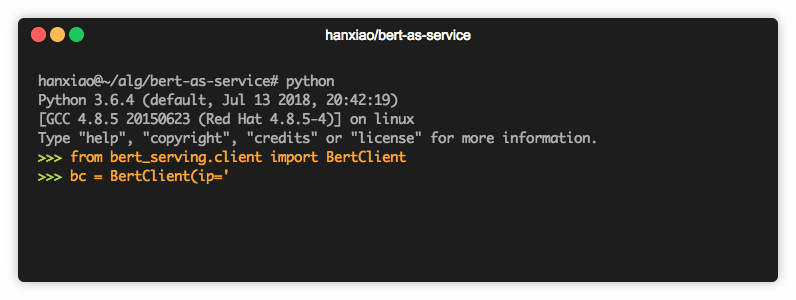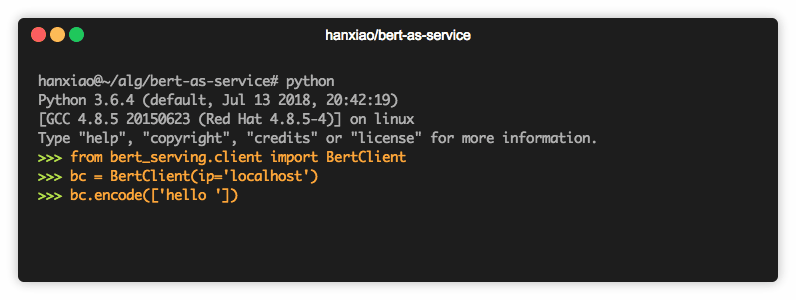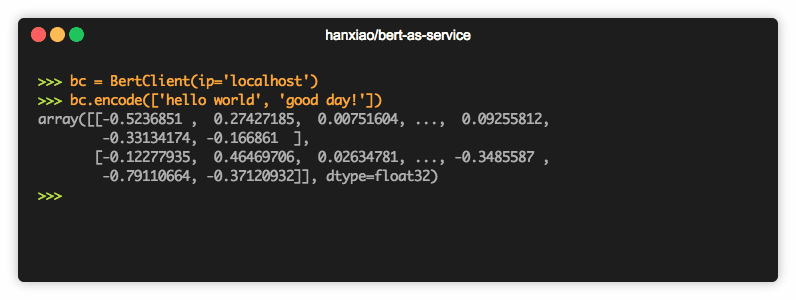
现在你可以简单地对句子进行编码,如下所示:
from bert_serving.client import BertClient bc = BertClient() bc.encode(['First do it', 'then do it right', 'then do it better'])
作为 BERT 的一个特性,你可以通过将它们与 |||(前后有空格)连接来获得一对句子的编码,例如
bc.encode(['First do it ||| then do it right'])

远程使用 BERT 服务
你还可以在一台 (GPU) 机器上启动服务并从另一台 (CPU) 机器上调用它,如下所示:
# on another CPU machine from bert_serving.client import BertClient bc = BertClient(ip='xx.xx.xx.xx') # ip address of the GPU machine bc.encode(['First do it', 'then do it right', 'then do it better'])
我们将通过 bert-as-service 从FAQ 列表中找到与用户输入的问题最相似的问题,并返回相应的答案。
FAQ列表你也可以在 Python实用宝典后台回复 bert-as-service 下载。
首先,加载所有问题,并显示统计数据:
prefix_q = '##### **Q:** '
with open('README.md') as fp:
questions = [v.replace(prefix_q, '').strip() for v in fp if v.strip() and v.startswith(prefix_q)]
print('%d questions loaded, avg. len of %d' % (len(questions), np.mean([len(d.split()) for d in questions])))
# 33 questions loaded, avg. len of 9
一共有33个问题被加载,平均长度是9.
然后使用预训练好的模型:uncased_L-12_H-768_A-12 启动一个Bert服务:
bert-serving-start -num_worker=1 -model_dir=/data/cips/data/lab/data/model/uncased_L-12_H-768_A-12
接下来,将我们的问题编码为向量:
bc = BertClient(port=4000, port_out=4001) doc_vecs = bc.encode(questions)
最后,我们准备好接收用户的查询,并对现有问题执行简单的“模糊”搜索。
为此,每次有新查询到来时,我们将其编码为向量并计算其点积 doc_vecs;然后对结果进行降序排序,返回前N个类似的问题:
while True:
query = input('your question: ')
query_vec = bc.encode([query])[0]
# compute normalized dot product as score
score = np.sum(query_vec * doc_vecs, axis=1) / np.linalg.norm(doc_vecs, axis=1)
topk_idx = np.argsort(score)[::-1][:topk]
for idx in topk_idx:
print('> %s\t%s' % (score[idx], questions[idx]))
完成!现在运行代码并输入你的查询,看看这个搜索引擎如何处理模糊匹配:
完整代码如下,一共23行代码(在后台回复关键词也能下载):
import numpy as np
from bert_serving.client import BertClient
from termcolor import colored
prefix_q = '##### **Q:** '
topk = 5
with open('README.md') as fp:
questions = [v.replace(prefix_q, '').strip() for v in fp if v.strip() and v.startswith(prefix_q)]
print('%d questions loaded, avg. len of %d' % (len(questions), np.mean([len(d.split()) for d in questions])))
with BertClient(port=4000, port_out=4001) as bc:
doc_vecs = bc.encode(questions)
while True:
query = input(colored('your question: ', 'green'))
query_vec = bc.encode([query])[0]
# compute normalized dot product as score
score = np.sum(query_vec * doc_vecs, axis=1) / np.linalg.norm(doc_vecs, axis=1)
topk_idx = np.argsort(score)[::-1][:topk]
print('top %d questions similar to "%s"' % (topk, colored(query, 'green')))
for idx in topk_idx:
print('> %s\t%s' % (colored('%.1f' % score[idx], 'cyan'), colored(questions[idx], 'yellow')))
够简单吧?当然,这是一个基于预训练的Bert模型制造的一个简单QA搜索模型。
你还可以微调模型,让这个模型整体表现地更完美,你可以将自己的数据放到某个目录下,然后执行 run_classifier.py 对模型进行微调,比如这个例子:
https://github.com/google-research/bert#sentence-and-sentence-pair-classification-tasks
它还有许多别的用法,我们这里就不一一介绍了,大家可以前往官方文档学习:
https://github.com/hanxiao/bert-as-service
我们的文章到此就结束啦,如果你喜欢今天的 Python 教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 ( pythondict.com )
不只是一个宝典
欢迎关注公众号:Python实用宝典

语音转文字在许多不同领域都有着广泛的应用,其中一些应用与金钱相关。以下是一些例子:
1.字幕制作:语音转文字可以帮助视频制作者快速制作字幕,这在影视行业和网络视频领域非常重要。通过使用语音转文字工具,字幕制作者可以更快地生成字幕,从而缩短制作时间,节省人工成本,并提高制作效率。
2.法律文书:在法律领域,语音转文字可以帮助律师和律所将听证会、辩论和其他法律活动的录音转化为文字文档。这些文档可以用于研究、起草文件和法律分析等目的,从而提高工作效率。
3.医疗文档:医疗专业人员可以使用语音转文字技术来记录病人的医疗记录、手术记录和其他相关信息。这可以减少错误和遗漏,提高记录的准确性和完整性,为患者提供更好的医疗服务。
4.市场调查和分析:语音转文字可以帮助企业快速收集和分析消费者反馈、电话调查和市场研究结果等数据。这可以帮助企业更好地了解其目标受众和市场趋势,从而制定更有效的营销策略和商业计划。
总之,语音转文字技术在许多不同的行业和场景中都有着广泛的应用,可以提高工作效率、减少成本和错误,并为企业和个人带来更多商业价值。
语音转文字是一项重要的技术,但市场上大部分语音转文字工具存在诸多问题。很多人会遇到付费工具难用的情况,效果非常差。如果你需要高效而准确的语音转文字解决方案,你应该考虑使用Whisper。下面是whisper的一段转换示例:
", ".join([i["text"] for i in result["segments"] if i is not None]) # Out[12]: '我赢了啊你说你看到没有没有这样没有减息啊我们后面是降息, 你不要去博这个东西, 我真是害怕你啊, 你不要去博不确定性, 是不是不确定性是我们的敌人, 听到没有朋友们, 好吧, 来朋友们, 你们的预约点好了啊, 朋友们, 你们的预约一定要给我点好了吧, 晚上八点钟是准时开播的, 朋友们关注点好了, 我们盘中视频见啊, 朋友们大家再见'
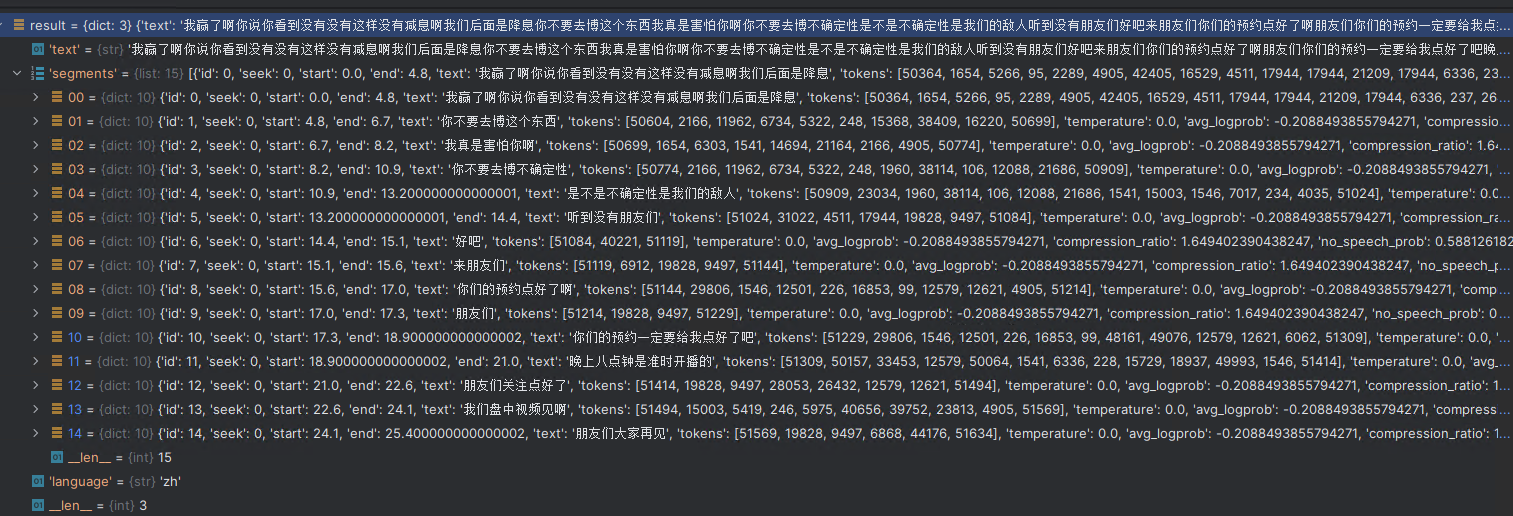
可以看到,即便是语速这么快的情况下,Whisper 依然实现了近乎完美的转换。
在接下来的教程中,我们将介绍如何使用Whisper来轻松地完成语音转文字任务。
开始之前,你要确保Python和pip已经成功安装在电脑上,如果没有,请访问这篇文章:超详细Python安装指南 进行安装。
(可选1) 如果你用Python的目的是数据分析,可以直接安装Anaconda:Python数据分析与挖掘好帮手—Anaconda,它内置了Python和pip.
(可选2) 此外,推荐大家用VSCode编辑器来编写小型Python项目:Python 编程的最好搭档—VSCode 详细指南
Windows环境下打开Cmd(开始—运行—CMD),苹果系统环境下请打开Terminal(command+空格输入Terminal),输入命令安装依赖:
pip install openai-whisper
此外你还需要安装ffmpeg:
Mac (打开终端(Terminal), 用 homebrew 安装):
brew install ffmpeg --with-libvorbis --with-sdl2 --with-theora
Linux:
apt-get install ffmpeg libavcodec-extra
Windows:
1. 进入 http://ffmpeg.org/download.html#build-windows,点击 windows 对应的图标,进入下载界面点击 download 下载按钮,
2. 解压下载好的zip文件到指定目录
3. 将解压后的文件目录中 bin 目录(包含 ffmpeg.exe )添加进 path 环境变量中
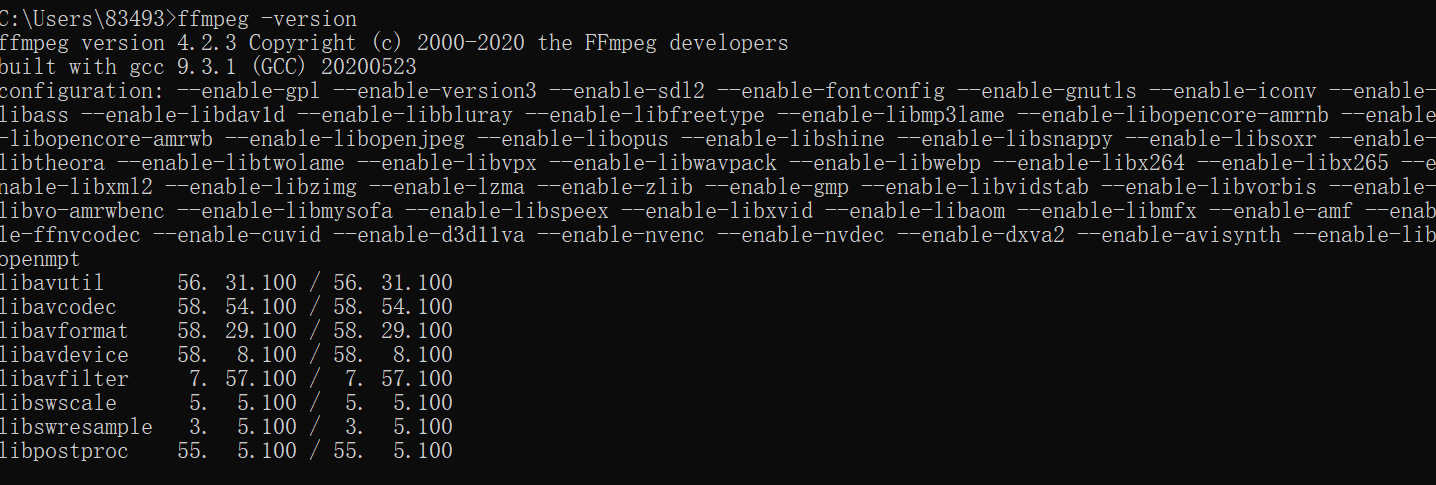
4. DOS 命令行输入 ffmpeg -version, 出现以下界面说明安装完成:
简单的使用例子:
import whisper
whisper_model = whisper.load_model("large")
result = whisper_model.transcribe(r"C:\Users\win10\Downloads\test.wav")
print(", ".join([i["text"] for i in result["segments"] if i is not None]))首先,我们建议使用Whisper的large-v2模型。根据我的实测结果,这个模型的表现非常优秀,它可以识别多种语言,包括中文,而且中文识别效果非常出色。在某些文字转换的场景中,它的表现甚至优于腾讯云、阿里云。
如果你无法下载到模型,可以用我们的模型镜像下载地址:https://pythondict.com/download/openai-whisper-large-v2/
使用前将模型文件放到指定位置:
Windows: C:\Users\你的用户名\.cache\whisper/large-v2.pt
Linux/MacOS: ~/.cache/whisper/large-v2.pt
然后重新运行程序即可得到转换结果。比如我们转换下面这个音频:
效果如下:
import whisper
whisper_model = whisper.load_model("large")
result = whisper_model.transcribe(r"C:\Users\win10\Downloads\test.wav")
print(", ".join([i["text"] for i in result["segments"] if i is not None]))
# 我赢了啊你说你看到没有没有这样没有减息啊我们后面是降息, 你不要去博这个东西, 我真是害怕你啊, 你不要去博不确定性, 是不是不确定性是我们的敌人, 听到没有朋友们, 好吧, 来朋友们, 你们的预约点好了啊, 朋友们, 你们的预约一定要给我点好了吧, 晚上八点钟是准时开播的, 朋友们关注点好了, 我们盘中视频见啊, 朋友们大家再见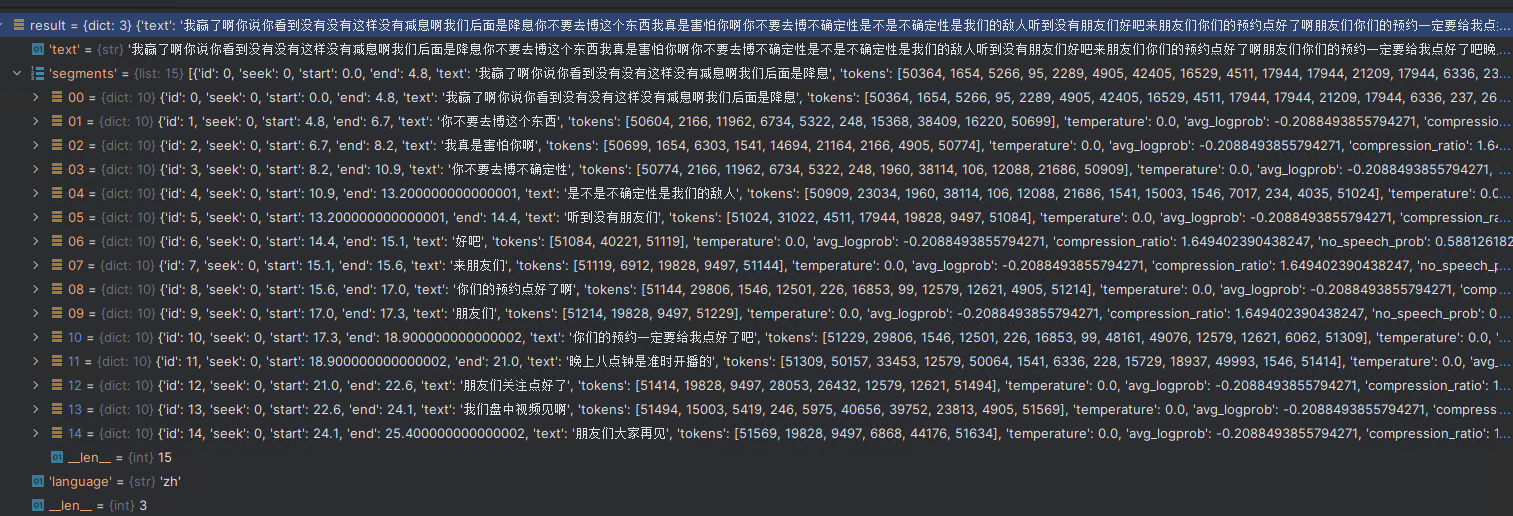
此外,不建议一次性转换长音频。如果你要转换长度很长的音频,建议先做切割并降低码率。
Whisper的生成结果是一个字典:
{'text': '我赢了啊你说你看到没有没有这样没有减息啊我们后面是降息你不要去博这个东西我真是害怕你啊你不要去博不确定性是不是不确定性是我们的敌人听到没有朋友们好吧来朋友们你们的预约点好了啊朋友们你们的预约一定要给我点好了吧晚上八点钟是准时开播的朋友们关注点好了我们盘中视频见啊朋友们大家再见', 'segments': [{'id': 0, 'seek': 0, 'start': 0.0, 'end': 4.8, 'text': '我赢了啊你说你看到没有没有这样没有减息啊我们后面是降息', 'tokens': [50364, 1654, 5266, 95, 2289, 4905, 42405, 16529, 4511, 17944, 17944, 21209, 17944, 6336, 237, 26460, 4905, 15003, 13547, 8833, 1541, 47421, 26460, 50604], 'temperature': 0.0, 'avg_logprob': -0.2088493855794271, 'compression_ratio': 1.649402390438247, 'no_speech_prob': 0.5881261825561523}, {'id': 1, 'seek': 0, 'start': 4.8, 'end': 6.7, 'text': '你不要去博这个东西', 'tokens': [50604, 2166, 11962, 6734, 5322, 248, 15368, 38409, 16220, 50699], 'temperature': 0.0, 'avg_logprob': -0.2088493855794271, 'compression_ratio': 1.649402390438247, 'no_speech_prob': 0.5881261825561523}, {'id': 2, 'seek': 0, 'start': 6.7, 'end': 8.2, 'text': '我真是害怕你啊', 'tokens': [50699, 1654, 6303, 1541, 14694, 21164, 2166, 4905, 50774], 'temperature': 0.0, 'avg_logprob': -0.2088493855794271, 'compression_ratio': 1.649402390438247, 'no_speech_prob': 0.5881261825561523}, {'id': 3, 'seek': 0, 'start': 8.2, 'end': 10.9, 'text': '你不要去博不确定性', 'tokens': [50774, 2166, 11962, 6734, 5322, 248, 1960, 38114, 106, 12088, 21686, 50909], 'temperature': 0.0, 'avg_logprob': -0.2088493855794271, 'compression_ratio': 1.649402390438247, 'no_speech_prob': 0.5881261825561523}, {'id': 4, 'seek': 0, 'start': 10.9, 'end': 13.200000000000001, 'text': '是不是不确定性是我们的敌人', 'tokens': [50909, 23034, 1960, 38114, 106, 12088, 21686, 1541, 15003, 1546, 7017, 234, 4035, 51024], 'temperature': 0.0, 'avg_logprob': -0.2088493855794271, 'compression_ratio': 1.649402390438247, 'no_speech_prob': 0.5881261825561523}, {'id': 5, 'seek': 0, 'start': 13.200000000000001, 'end': 14.4, 'text': '听到没有朋友们', 'tokens': [51024, 31022, 4511, 17944, 19828, 9497, 51084], 'temperature': 0.0, 'avg_logprob': -0.2088493855794271, 'compression_ratio': 1.649402390438247, 'no_speech_prob': 0.5881261825561523}, {'id': 6, 'seek': 0, 'start': 14.4, 'end': 15.1, 'text': '好吧', 'tokens': [51084, 40221, 51119], 'temperature': 0.0, 'avg_logprob': -0.2088493855794271, 'compression_ratio': 1.649402390438247, 'no_speech_prob': 0.5881261825561523}, {'id': 7, 'seek': 0, 'start': 15.1, 'end': 15.6, 'text': '来朋友们', 'tokens': [51119, 6912, 19828, 9497, 51144], 'temperature': 0.0, 'avg_logprob': -0.2088493855794271, 'compression_ratio': 1.649402390438247, 'no_speech_prob': 0.5881261825561523}, {'id': 8, 'seek': 0, 'start': 15.6, 'end': 17.0, 'text': '你们的预约点好了啊', 'tokens': [51144, 29806, 1546, 12501, 226, 16853, 99, 12579, 12621, 4905, 51214], 'temperature': 0.0, 'avg_logprob': -0.2088493855794271, 'compression_ratio': 1.649402390438247, 'no_speech_prob': 0.5881261825561523}, {'id': 9, 'seek': 0, 'start': 17.0, 'end': 17.3, 'text': '朋友们', 'tokens': [51214, 19828, 9497, 51229], 'temperature': 0.0, 'avg_logprob': -0.2088493855794271, 'compression_ratio': 1.649402390438247, 'no_speech_prob': 0.5881261825561523}, {'id': 10, 'seek': 0, 'start': 17.3, 'end': 18.900000000000002, 'text': '你们的预约一定要给我点好了吧', 'tokens': [51229, 29806, 1546, 12501, 226, 16853, 99, 48161, 49076, 12579, 12621, 6062, 51309], 'temperature': 0.0, 'avg_logprob': -0.2088493855794271, 'compression_ratio': 1.649402390438247, 'no_speech_prob': 0.5881261825561523}, {'id': 11, 'seek': 0, 'start': 18.900000000000002, 'end': 21.0, 'text': '晚上八点钟是准时开播的', 'tokens': [51309, 50157, 33453, 12579, 50064, 1541, 6336, 228, 15729, 18937, 49993, 1546, 51414], 'temperature': 0.0, 'avg_logprob': -0.2088493855794271, 'compression_ratio': 1.649402390438247, 'no_speech_prob': 0.5881261825561523}, {'id': 12, 'seek': 0, 'start': 21.0, 'end': 22.6, 'text': '朋友们关注点好了', 'tokens': [51414, 19828, 9497, 28053, 26432, 12579, 12621, 51494], 'temperature': 0.0, 'avg_logprob': -0.2088493855794271, 'compression_ratio': 1.649402390438247, 'no_speech_prob': 0.5881261825561523}, {'id': 13, 'seek': 0, 'start': 22.6, 'end': 24.1, 'text': '我们盘中视频见啊', 'tokens': [51494, 15003, 5419, 246, 5975, 40656, 39752, 23813, 4905, 51569], 'temperature': 0.0, 'avg_logprob': -0.2088493855794271, 'compression_ratio': 1.649402390438247, 'no_speech_prob': 0.5881261825561523}, {'id': 14, 'seek': 0, 'start': 24.1, 'end': 25.400000000000002, 'text': '朋友们大家再见', 'tokens': [51569, 19828, 9497, 6868, 44176, 51634], 'temperature': 0.0, 'avg_logprob': -0.2088493855794271, 'compression_ratio': 1.649402390438247, 'no_speech_prob': 0.5881261825561523}], 'language': 'zh'}text参数是没有做任何分词处理的纯语音原文本。
我们要重点关注的是segments参数。segments参数对音频内人物语言做了”分段”操作,比如这一段话:
{
'id': 1,
'seek': 0,
'start': 4.8,
'end': 6.7,
'text': '你不要去博这个东西',
'tokens': [50604, 2166, 11962, 6734, 5322, 248, 15368, 38409, 16220, 50699],
'temperature': 0.0,
'avg_logprob': -0.2088493855794271,
'compression_ratio': 1.649402390438247,
'no_speech_prob': 0.5881261825561523
}它就相当于人一样,去一帧帧校对每个词说话的时间:start是起始时间,end是结束时间。即”你不要去博这个东西”发生在音频的4.8秒到6.7秒之间。其他参数:
temperature 是指在语音转文本模型生成结果时,控制输出随机性和多样性的参数。
avg_logprob参数是语音转文字模型预测的置信度评分的平均值。
compression_ratio参数是指音频信号压缩的比率。
no_speech_prob参数是指模型在某段时间内检测到没有语音信号的概率。
重点在于如何应用。start和end参数你可以用来直接生成视频的字幕。大大提高生产效率。
置信度参数你可以用来提高识别准确率,如果说置信度一直不高,可以单独拎出来人工优化。
总之,Whisper的Large-v2模型绝对是目前中文语音转文字的顶级存在,有兴趣的朋友赶紧试试吧。
模型镜像下载地址:https://pythondict.com/download/openai-whisper-large-v2/
如果你存在算力计算或使用上的困难,也可以私信联系我帮你处理。
我们的文章到此就结束啦,如果你喜欢今天的 Python 教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 ( pythondict.com )
不只是一个宝典
欢迎关注公众号:Python实用宝典
开始之前,你要确保Python和pip已经成功安装在电脑上,如果没有,请访问这篇文章:超详细Python安装指南 进行安装。
(可选1) 如果你用Python的目的是数据分析,可以直接安装Anaconda:Python数据分析与挖掘好帮手—Anaconda,它内置了Python和pip.
(可选2) 此外,推荐大家用VSCode编辑器来编写小型Python项目:Python 编程的最好搭档—VSCode 详细指南
Windows环境下打开Cmd(开始—运行—CMD),苹果系统环境下请打开Terminal(command+空格输入Terminal),输入命令安装依赖:
pip install pandas pip install numpy pip install scikit-learn pip install keras
获取数据
首先,你需要准备好股市秒级数据,这个文件的内容如下(可以在二七阿尔公众号后台回复秒级数据获取):
ts_code,trade_time,open,high,low,close,volume,amount 000001.SH,2021-10-08 15:00:00.0000000+08:00,3599.8,3600.0,3599.8,3600.0,0,0 000001.SH,2021-10-08 14:59:59.0000000+08:00,3599.8,3599.8,3599.7,3599.7,0,0 000001.SH,2021-10-08 14:59:58.0000000+08:00, ...
其中包含了某只股票的每秒开盘价、最高价、最低价、收盘价和成交量等信息。
然后,你需要对数据进行预处理,例如归一化、划分训练集和测试集、构造输入和输出等。这里我们假设你想用前10秒的数据来预测下一秒的涨跌情况,即二分类问题。我们可以用以下代码实现:
import pandas as pd
import numpy as np
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
# 读取数据
data = pd.read_csv("stock_data.csv")
# 归一化数据
scaler = MinMaxScaler()
data_scaled = scaler.fit_transform(data)
# 构造输入和输出
X = []
y = []
seq_len = 10 # 前10秒作为输入
for i in range(seq_len, len(data_scaled)):
X.append(data_scaled[i-seq_len:i]) # 输入是10秒的数据
y.append(1 if data_scaled[i][3] > data_scaled[i-1][3] else 0) # 输出是下一秒的涨跌情况
X = np.array(X)
y = np.array(y)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)接下来,你需要搭建一个CNN模型来对输入进行特征提取和分类。这里我们使用Keras框架来实现一个简单的CNN模型,包含两个卷积层、两个池化层和一个全连接层:
from keras.models import Sequential from keras.layers import Conv1D, MaxPooling1D, Flatten, Dense # 定义模型参数 input_shape = (seq_len, 5) # 输入形状是(10, 5),即10秒的5个特征值 num_classes = 2 # 输出类别数是2,即涨或跌 # 搭建模型结构 model = Sequential() model.add(Conv1D(filters=32, kernel_size=3, activation="relu", input_shape=input_shape)) # 第一个卷积层,使用32个3大小的卷积核,并使用relu激活函数 model.add(MaxPooling1D(pool_size=2)) # 第一个池化层,使用2大小的池化窗口,并默认使用最大池化方法 model.add(Conv1D(filters=64, kernel_size=3, activation="relu")) # 第二个卷积层,使用64个3大小的卷积核,并使用relu激活函数 model.add(MaxPooling1D(pool_size=2)) # 第二个池化层,使用2大小的池化窗口,并默认使用最大池化方法 model.add(Flatten()) # 将多维度的输出展平为一维度的向量,以便输入全连接层 model.add(Dense(units=num_classes, activation="softmax")) # 全连接层,使用softmax激活函数输出类别概率 # 编译模型并查看摘要信息 model.compile(optimizer="adam", loss="sparse_categorical_crossentropy", metrics=["accuracy"]) model.summary()
最后,你需要训练模型并评估其性能。这里我们使用20个epoch来训练模型,并在每个epoch结束后在测试集上进行评估:
# 定义训练参数
epochs = 20 # 训练轮数
batch_size = 32 # 批次大小
# 训练模型并在测试集上评估
for epoch in range(epochs):
model.fit(X_train, y_train, batch_size=batch_size) # 在训练集上训练模型
loss, acc = model.evaluate(X_test, y_test) # 在测试集上评估模型
print(f"Epoch {epoch+1}: loss={loss:.4f}, acc={acc:.4f}") # 打印损失和准确率这样,你就完成了一个Python的CNN模型分类股市秒级数据的示例。希望对你有帮助。👍
我们的文章到此就结束啦,如果你喜欢今天的 Python 教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 ( pythondict.com )
不只是一个宝典
欢迎关注公众号:Python实用宝典

DiscoArt 是一个很牛逼的开源模块,它能根据你给定的关键词自动绘画。
绘制过程是完全可见的,你可以在 jupyter 页面上看见这个绘制的过程:
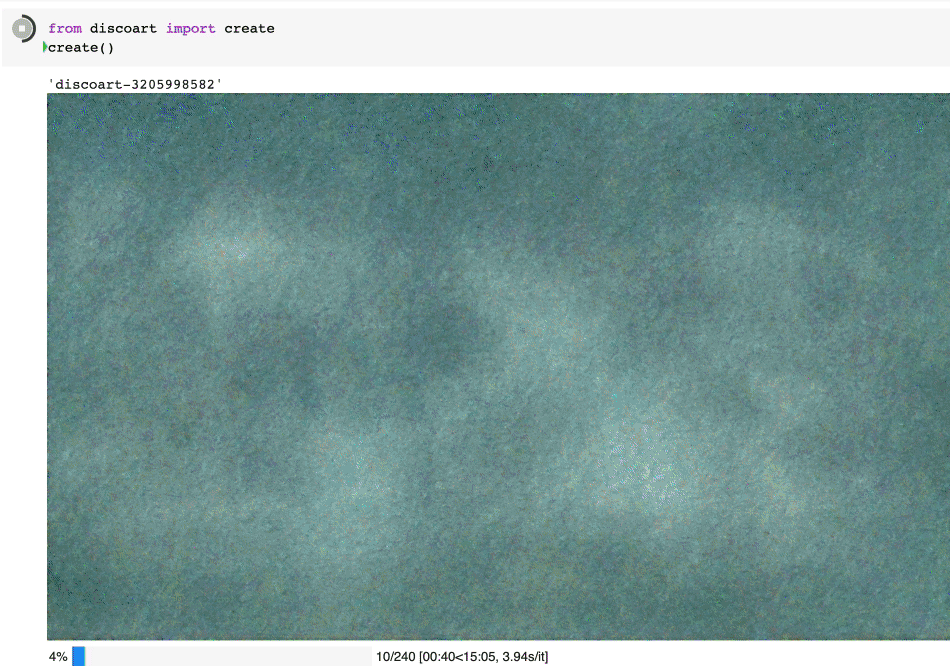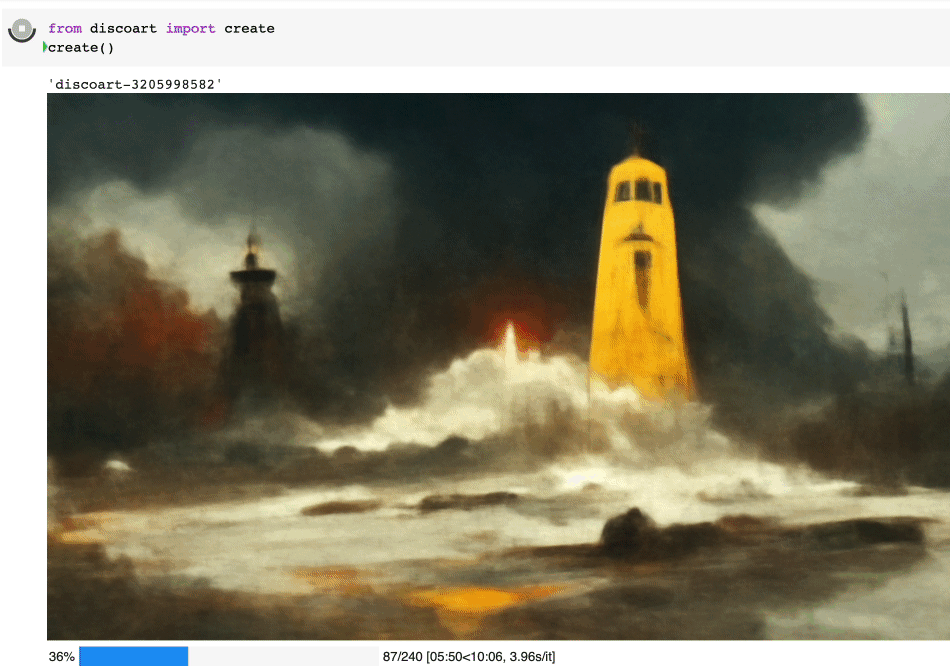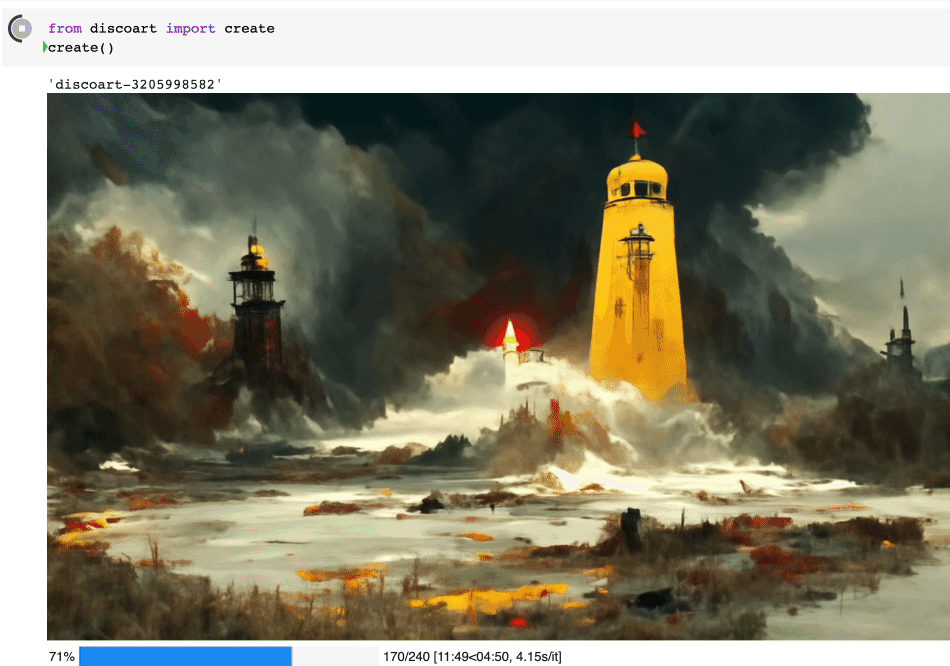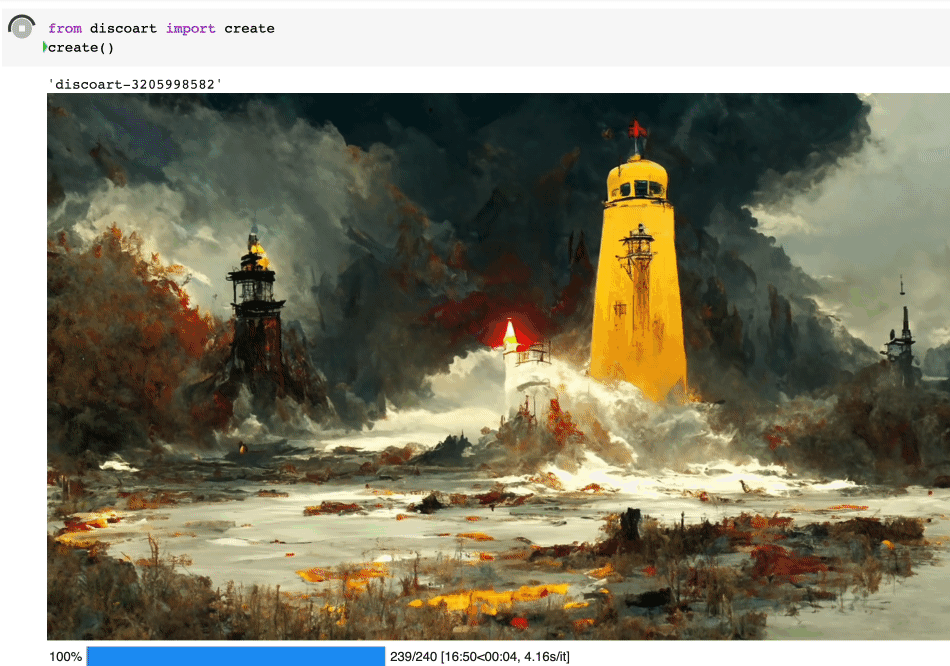
开始之前,你要确保Python和pip已经成功安装在电脑上,如果没有,请访问这篇文章:超详细Python安装指南 进行安装。
(可选1) 如果你用Python的目的是数据分析,可以直接安装Anaconda:Python数据分析与挖掘好帮手—Anaconda,它内置了Python和pip.
(可选2) 此外,推荐大家用VSCode编辑器来编写小型Python项目:Python 编程的最好搭档—VSCode 详细指南
Windows环境下打开Cmd(开始—运行—CMD),苹果系统环境下请打开Terminal(command+空格输入Terminal),输入命令安装依赖:
pip install discoart
为了运行 Discoart, 你需要Python 3.7+ 和支持 CUDA 的 PyTorch.
你可以在Jupyter中运行Discoart,这样能方便地实时展示绘制过程:
from discoart import create da = create()
这样将使用默认的 文本描述 和参数创建图像:
text_prompts: - A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation. - yellow color scheme init_image: width_height: [ 1280, 768 ] skip_steps: 0 steps: 250 init_scale: 1000 clip_guidance_scale: 5000 tv_scale: 0 range_scale: 150 sat_scale: 0 cutn_batches: 4 diffusion_model: 512x512_diffusion_uncond_finetune_008100 use_secondary_model: True diffusion_sampling_mode: ddim perlin_init: False perlin_mode: mixed seed: eta: 0.8 clamp_grad: True clamp_max: 0.05 randomize_class: True clip_denoised: False rand_mag: 0.05 cut_overview: "[12]*400+[4]*600" cut_innercut: "[4]*400+[12]*600" cut_icgray_p: "[0.2]*400+[0]*600" cut_ic_pow: 1. save_rate: 20 gif_fps: 20 gif_size_ratio: 0.5 n_batches: 4 batch_size: 1 batch_name: clip_models: - ViT-B-32::openai - ViT-B-16::openai - RN50::openai clip_models_schedules: use_vertical_symmetry: False use_horizontal_symmetry: False transformation_percent: [0.09] on_misspelled_token: ignore diffusion_model_config: cut_schedules_group: name_docarray: skip_event: stop_event: text_clip_on_cpu: False truncate_overlength_prompt: False image_output: True visualize_cuts: False display_rate: 1
创建出来的就是这个图:
Create 支持的所有参数如下:
text_prompts: - A beautiful painting of a singular lighthouse, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Trending on artstation. - yellow color scheme init_image: width_height: [ 1280, 768 ] skip_steps: 0 steps: 250 init_scale: 1000 clip_guidance_scale: 5000 tv_scale: 0 range_scale: 150 sat_scale: 0 cutn_batches: 4 diffusion_model: 512x512_diffusion_uncond_finetune_008100 use_secondary_model: True diffusion_sampling_mode: ddim perlin_init: False perlin_mode: mixed seed: eta: 0.8 clamp_grad: True clamp_max: 0.05 randomize_class: True clip_denoised: False rand_mag: 0.05 cut_overview: "[12]*400+[4]*600" cut_innercut: "[4]*400+[12]*600" cut_icgray_p: "[0.2]*400+[0]*600" cut_ic_pow: 1. save_rate: 20 gif_fps: 20 gif_size_ratio: 0.5 n_batches: 4 batch_size: 1 batch_name: clip_models: - ViT-B-32::openai - ViT-B-16::openai - RN50::openai clip_models_schedules: use_vertical_symmetry: False use_horizontal_symmetry: False transformation_percent: [0.09] on_misspelled_token: ignore diffusion_model_config: cut_schedules_group: name_docarray: skip_event: stop_event: text_clip_on_cpu: False truncate_overlength_prompt: False image_output: True visualize_cuts: False display_rate: 1
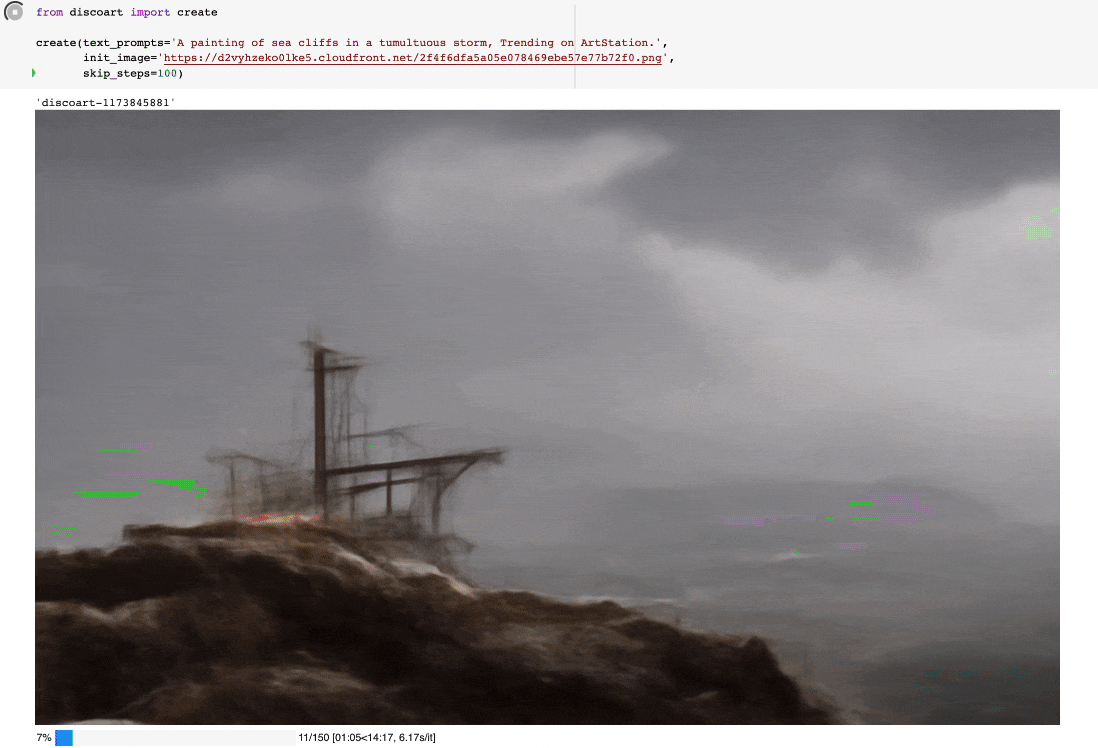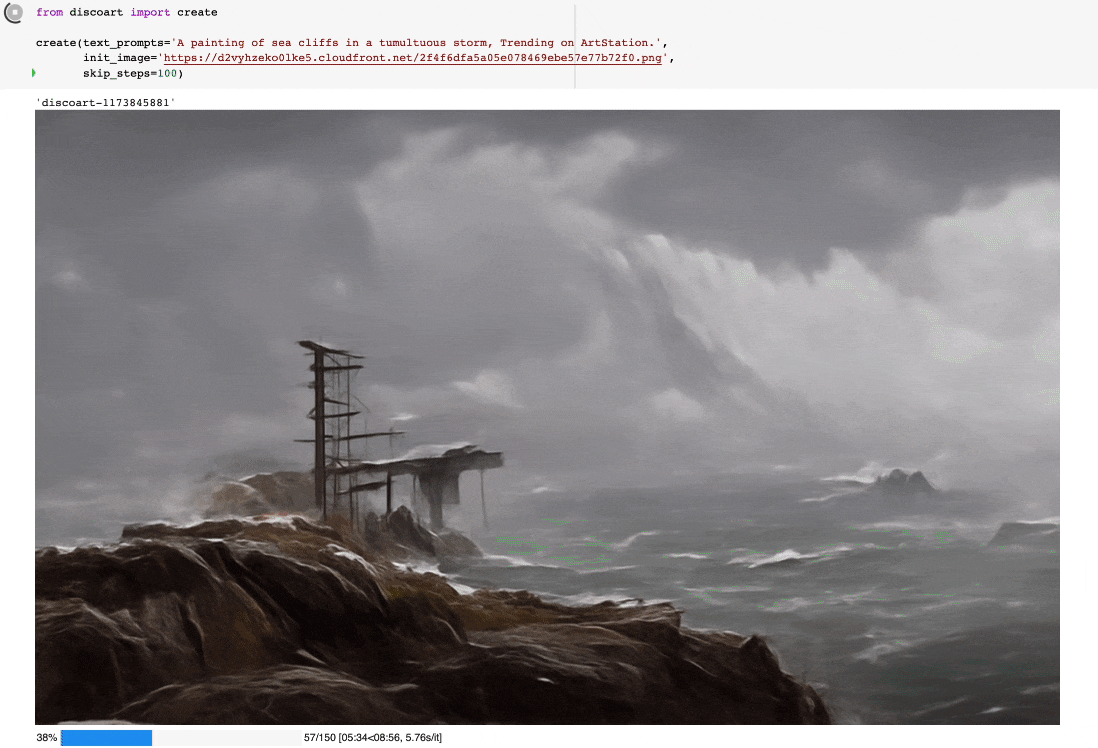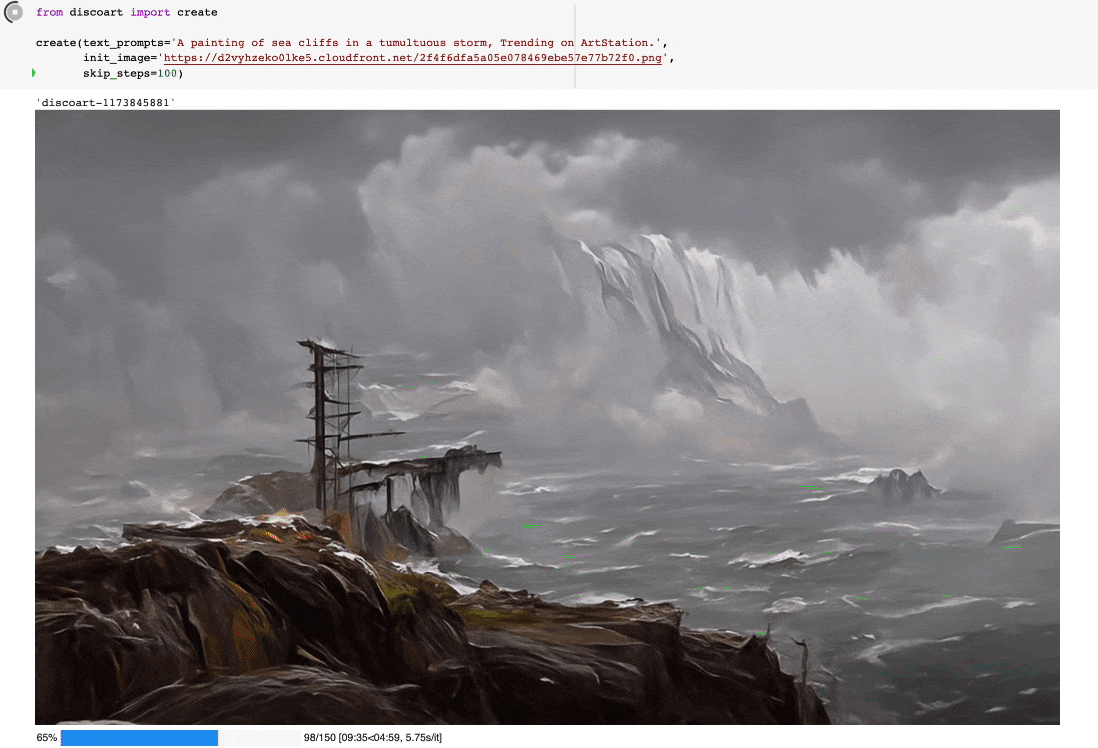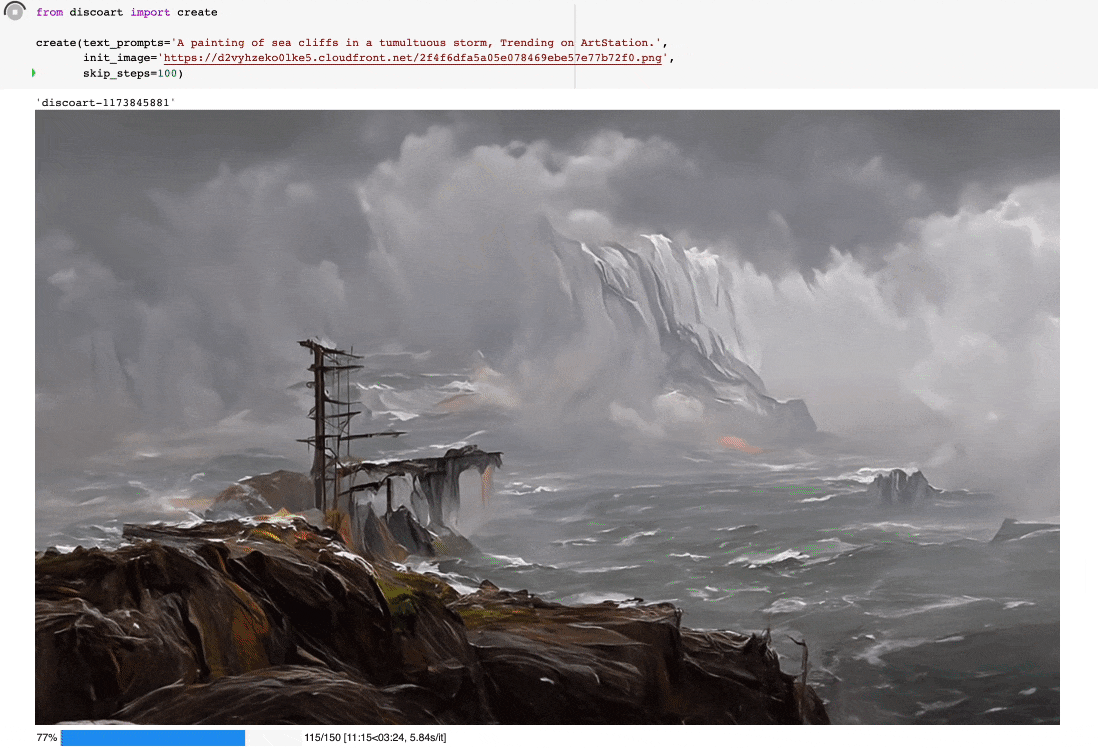
你可以这么使用:
from discoart import create
da = create(
text_prompts='A painting of sea cliffs in a tumultuous storm, Trending on ArtStation.',
init_image='https://d2vyhzeko0lke5.cloudfront.net/2f4f6dfa5a05e078469ebe57e77b72f0.png',
skip_steps=100,
)
如果你不是用jupyter运行的,你也可以看到中间结果,因为最终结果和中间结果都会被创建在当前工作目录下,即
./{name-docarray}/{i}-done.png
./{name-docarray}/{i}-step-{j}.png
./{name-docarray}/{i}-progress.png
./{name-docarray}/{i}-progress.gif
./{name-docarray}/da.protobuf.lz4name-docarray是运行时定义的名称,如果没有定义,则会随机生成。i-* 第几个Batch。*-done-* 是当前Batch完成后的最终图像。*-step-* 是某一步的中间图像,实时更新。*-progress.png 是到目前为止所有中间结果的png图像,实时更新。*-progress.gif 是到目前为止所有中间结果的动画 gif,实时更新。da.protobuf.lz4 是到目前为止所有中间结果的压缩 protobuf,实时更新。如果你想知道你当前绘图的配置,有三种方法:
from discoart import show_config
show_config(da) # show the config of the first run
show_config(da[3]) # show the config of the fourth run
show_config(
'discoart-06030a0198843332edc554ffebfbf288'
) # show the config of the run with a known DocArray ID要保存 Document/DocumentArray 的配置:
from discoart import save_config save_config(da, 'my.yml') # save the config of the first run save_config(da[3], 'my.yml') # save the config of the fourth run
从配置中导入:
from discoart import create, load_config
config = load_config('my.yml')
create(**config)此外,你还能直接把配置导出为图像的形式
from discoart.config import save_config_svg save_config_svg(da)
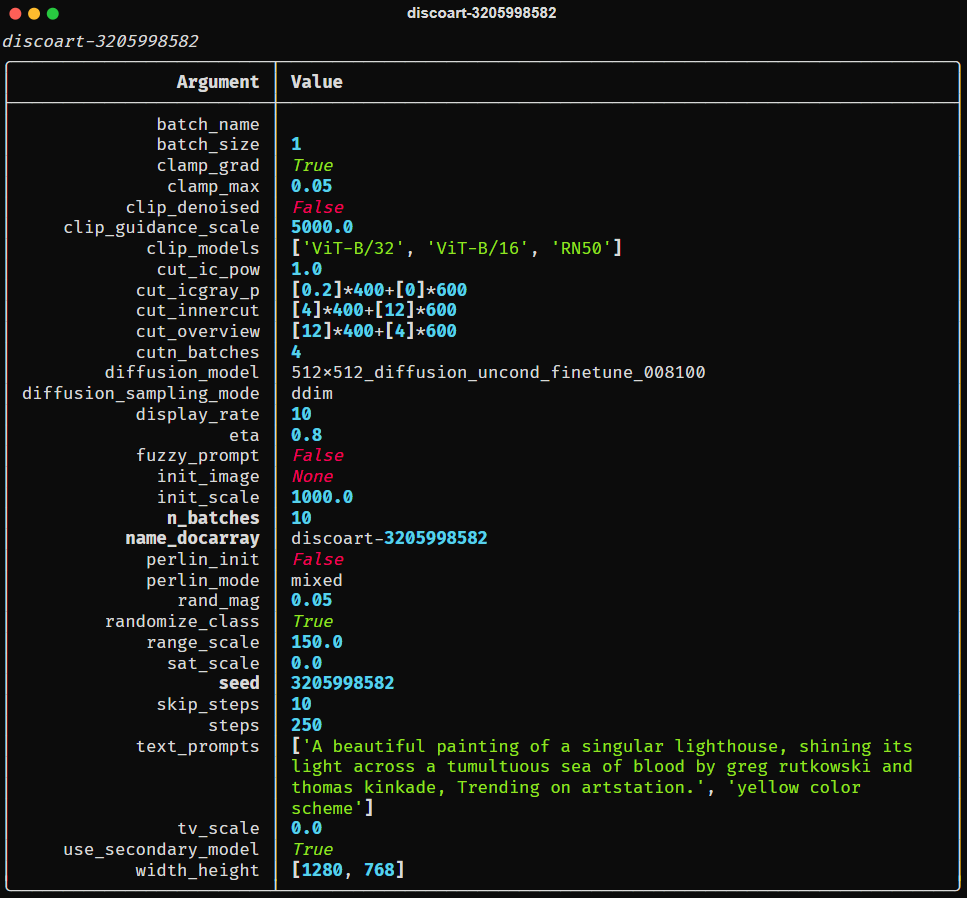
我们的文章到此就结束啦,如果你喜欢今天的 Python 教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 ( pythondict.com )
不只是一个宝典
欢迎关注公众号:Python实用宝典
Bulbea 是一个基于深度学习开发的,用于股票市场预测和建模的Python库。
Bulbea 自带了不少可用于股票深度学习训练及测试的API,并且易于对数据进行扩展和延申,构建属于我们自己的数据及模型。
下面就来介绍一下这个模块。
开始之前,你要确保Python和pip已经成功安装在电脑上,如果没有,请访问这篇文章:超详细Python安装指南 进行安装。
(可选1) 如果你用Python的目的是数据分析,可以直接安装Anaconda:Python数据分析与挖掘好帮手—Anaconda,它内置了Python和pip.
(可选2) 此外,推荐大家用VSCode编辑器来编写小型Python项目:Python 编程的最好搭档—VSCode 详细指南
Windows环境下打开Cmd(开始—运行—CMD),苹果系统环境下请打开Terminal(command+空格输入Terminal),输入命令安装依赖:
git clone https://github.com/achillesrasquinha/bulbea.git && cd bulbea pip install -r requirements.txt python setup.py install
如果你无法访问Github,请在二七阿尔量化后台回复Bulbea下载项目镜像(2022-11-28).
此外,你还需要安装 Tensorflow 的CPU版本或GPU版本:
pip install tensorflow # CPU 版本 pip install tensorflow-gpu # GPU 版本 - 需要 CUDA, CuDNN
Bulbea 和普通的深度学习研究项目一样,在做训练和测试时,分为四步(加载数据,预处理,建模,测试)。
Bulbea内置了数据下载模块,让你很轻易地能够下载雅虎财经的股票数据,比如下面下载雅虎财经源的GOOGL股票数据:
>>> import bulbea as bb
>>> share = bb.Share('YAHOO', 'GOOGL')
>>> share.data
# Open High Low Close Volume \
# Date
# 2004-08-19 99.999999 104.059999 95.959998 100.339998 44659000.0
# 2004-08-20 101.010005 109.079998 100.500002 108.310002 22834300.0
# 2004-08-23 110.750003 113.479998 109.049999 109.399998 18256100.0
# 2004-08-24 111.239999 111.599998 103.570003 104.870002 15247300.0
# 2004-08-25 104.960000 108.000002 103.880003 106.000005 9188600.0
...Bulbea 同样也内置了预处理模块,让你能够轻易地分割训练集和测试集:
>>> from bulbea.learn.evaluation import split >>> Xtrain, Xtest, ytrain, ytest = split(share, 'Close', normalize = True)
Bulbea自带了RNN模型可供使用:
>>> import numpy as np >>> Xtrain = np.reshape(Xtrain, (Xtrain.shape[0], Xtrain.shape[1], 1)) >>> Xtest = np.reshape( Xtest, ( Xtest.shape[0], Xtest.shape[1], 1)) >>> from bulbea.learn.models import RNN >>> rnn = RNN([1, 100, 100, 1]) # number of neurons in each layer >>> rnn.fit(Xtrain, ytrain) # Epoch 1/10 # 1877/1877 [==============================] - 6s - loss: 0.0039 # Epoch 2/10 # 1877/1877 [==============================] - 6s - loss: 0.0019 ...
通过调用sklearn的metrics就能对数据实现测试:
>>> from sklearn.metrics import mean_squared_error >>> p = rnn.predict(Xtest) >>> mean_squared_error(ytest, p) 0.00042927869370525931 >>> import matplotlib.pyplot as pplt >>> pplt.plot(ytest) >>> pplt.plot(p) >>> pplt.show()
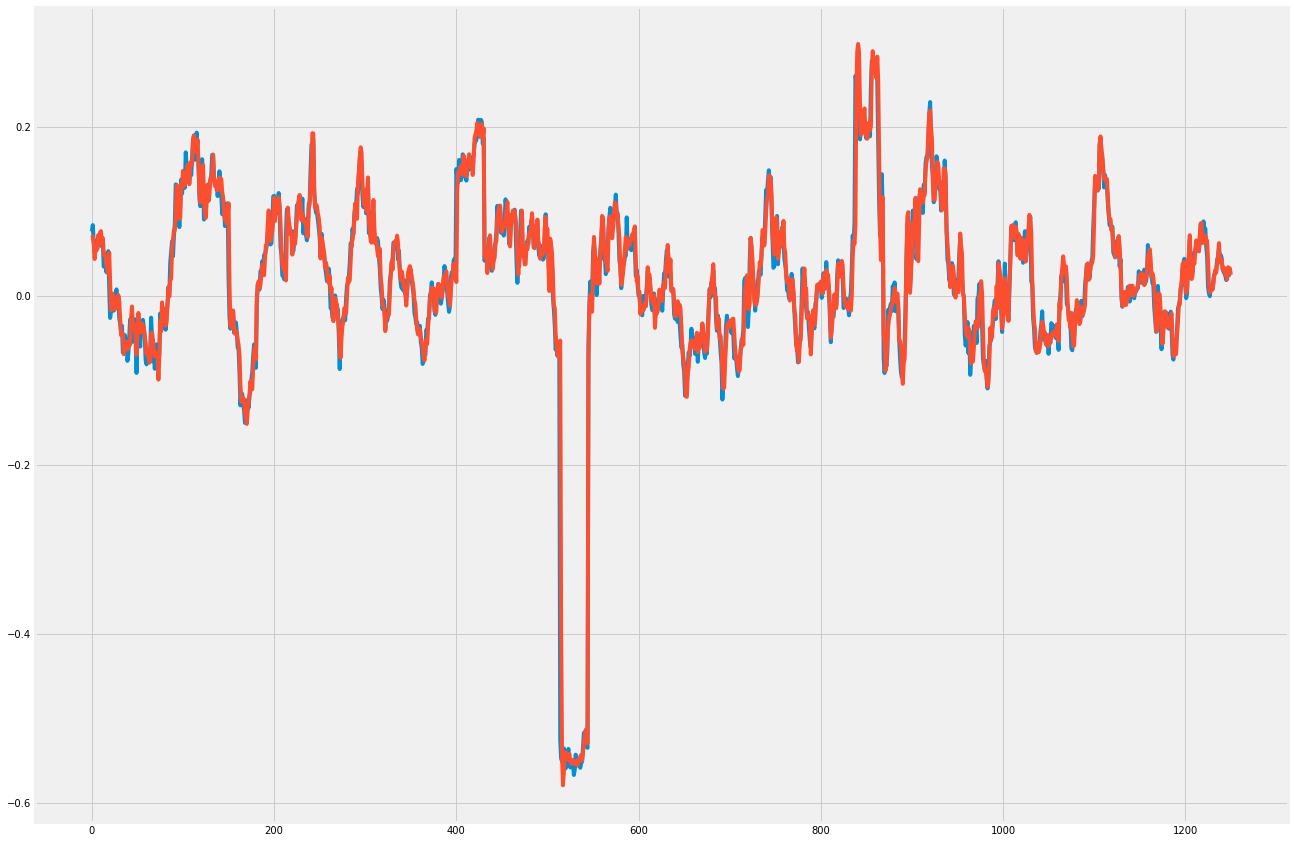
Bulbea 能自动爬取相关股票在推特上的文字,并对这些文字做一个情感分析。
你只需要给Bulbea提供以下环境变量就能够进行感情色彩分析:
export BULBEA_TWITTER_API_KEY="<YOUR_TWITTER_API_KEY>" export BULBEA_TWITTER_API_SECRET="<YOUR_TWITTER_API_SECRET>" export BULBEA_TWITTER_ACCESS_TOKEN="<YOUR_TWITTER_ACCESS_TOKEN>" export BULBEA_TWITTER_ACCESS_TOKEN_SECRET="<YOUR_TWITTER_ACCESS_TOKEN_SECRET>"
测试一下:
>>> import bulbea as bb
>>> share = bb.Share('YAHOO', 'GOOGL')
>>> bb.sentiment(share)
0.07580128205128206当然,这个分析仅供参考,太粗略了。
我们的文章到此就结束啦,如果你喜欢今天的 Python 教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 ( pythondict.com )
不只是一个宝典
欢迎关注公众号:Python实用宝典
最常见的深度学习框架应该是TensorFlow、Pytorch、Keras,但是这些框架在面向大规模模型的时候都不是很方便。
比如Pytorch的分布式并行计算框架(Distributed Data Parallel,简称DDP),它也仅仅是能将数据并行,放到各个GPU的模型上进行训练。
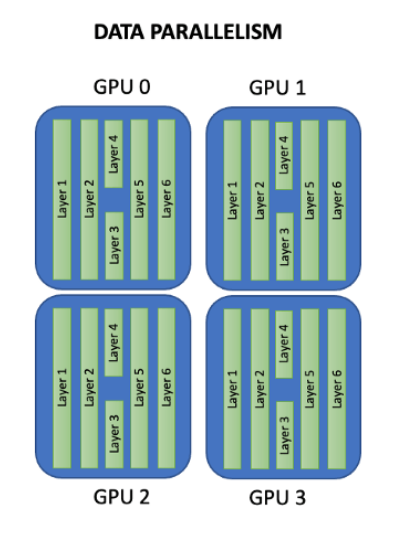
也就是说,DDP的应用场景在你的模型大小大于显卡显存大小时,它就很难继续使用了,除非你自己再将模型参数拆散分散到各个GPU上。
今天要给大家介绍的DeepSpeed,它就能实现这个拆散功能,它通过将模型参数拆散分布到各个GPU上,以实现大型模型的计算,弥补了DDP的缺点,非常方便,这也就意味着我们能用更少的GPU训练更大的模型,而且不受限于显存。
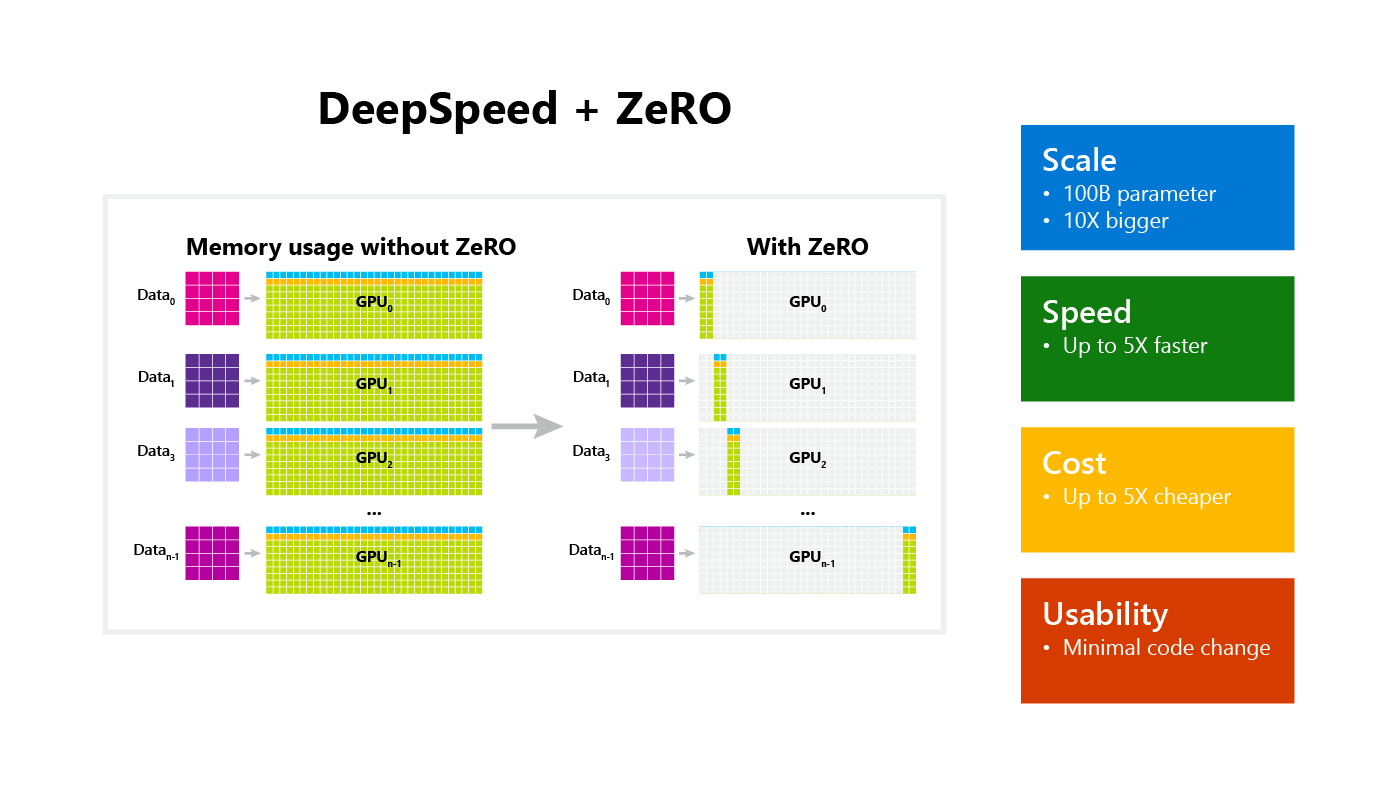
DeepSpeed入门并不简单,尽管是微软开源的框架,文档却写的一般,缺少条理性,也没有从零到一的使用示例。下面我就简单介绍一下怎么使用DeepSpeed这个框架。
开始之前,你要确保Python和pip已经成功安装在电脑上,如果没有,请访问这篇文章:超详细Python安装指南 进行安装。
(可选1) 如果你用Python的目的是数据分析,可以直接安装Anaconda:Python数据分析与挖掘好帮手—Anaconda,它内置了Python和pip.
(可选2) 此外,推荐大家用VSCode编辑器来编写小型Python项目:Python 编程的最好搭档—VSCode 详细指南
Windows环境下打开Cmd(开始—运行—CMD),苹果系统环境下请打开Terminal(command+空格输入Terminal),输入命令安装依赖:
pip install deepspeed
此外,你还需要下载 Pytorch,在官网选择自己对应的系统版本和环境,按照指示安装即可:
https://pytorch.org/get-started/locally/
使用DeepSpeed其实和写一个pytorch模型只有部分区别,一开始的流程是一样的。
2.1 载入数据集:
import torch
import torchvision
import torchvision.transforms as transforms
trainset = torchvision.datasets.CIFAR10(root='./data',
train=True,
download=True,
transform=transform)
trainloader = torch.utils.data.DataLoader(trainset,
batch_size=16,
shuffle=True,
num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data',
train=False,
download=True,
transform=transform)
testloader = torch.utils.data.DataLoader(testset,
batch_size=4,
shuffle=False,
num_workers=2)2.2 编写模型:
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
criterion = nn.CrossEntropyLoss()这里我写了一个非常简单的模型作测试。
2.3 初始化Deepspeed
DeepSpeed 通过输入参数来启动训练,因此需要使用argparse解析参数:
import argparse
def add_argument():
parser = argparse.ArgumentParser(description='CIFAR')
parser.add_argument('-b',
'--batch_size',
default=32,
type=int,
help='mini-batch size (default: 32)')
parser.add_argument('-e',
'--epochs',
default=30,
type=int,
help='number of total epochs (default: 30)')
parser.add_argument('--local_rank',
type=int,
default=-1,
help='local rank passed from distributed launcher')
parser.add_argument('--log-interval',
type=int,
default=2000,
help="output logging information at a given interval")
parser = deepspeed.add_config_arguments(parser)
args = parser.parse_args()
return args
此外,模型初始化的时候除了参数,还需要model及其parameters,还有训练集:
args = add_argument()
net = Net()
parameters = filter(lambda p: p.requires_grad, net.parameters())
model_engine, optimizer, trainloader, __ = deepspeed.initialize(
args=args, model=net, model_parameters=parameters, training_data=trainset)2.4 训练逻辑
下面的部分和我们平时训练模型是几乎一样的代码,请注意 local_rank 是你不需要管的参数,在后面启动模型训练的时候,DeepSpeed会自动给这个参数赋值。
for epoch in range(2):
running_loss = 0.0
for i, data in enumerate(trainloader):
inputs, labels = data[0].to(model_engine.local_rank), data[1].to(
model_engine.local_rank)
outputs = model_engine(inputs)
loss = criterion(outputs, labels)
model_engine.backward(loss)
model_engine.step()
# print statistics
running_loss += loss.item()
if i % args.log_interval == (args.log_interval - 1):
print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / args.log_interval))
running_loss = 0.02.5 测试逻辑
模型测试和模型训练的逻辑类似:
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images.to(model_engine.local_rank))
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels.to(
model_engine.local_rank)).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' %
(100 * correct / total))2.6 编写模型参数
在当前目录下新建一个 config.json 里面写好我们的调优器、训练batch等参数:
{
"train_batch_size": 4,
"steps_per_print": 2000,
"optimizer": {
"type": "Adam",
"params": {
"lr": 0.001,
"betas": [
0.8,
0.999
],
"eps": 1e-8,
"weight_decay": 3e-7
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": 0,
"warmup_max_lr": 0.001,
"warmup_num_steps": 1000
}
},
"wall_clock_breakdown": false
}完整的开发流程就结束了,可以看到其实和我们平时使用pytorch开发模型的区别不大,就是在初始化的时候使用 DeepSpeed,并以输入参数的形式初始化。完整代码可以在Python实用宝典后台回复 Deepspeed 下载。
现在就来测试我们上面的代码能不能正常运行。
在这里,我们需要用环境变量控制使用的GPU,比如我的机器有10张GPU,我只使用6, 7, 8, 9号GPU,输入命令:
export CUDA_VISIBLE_DEVICES="6,7,8,9"
然后开始运行代码:
deepspeed test.py --deepspeed_config config.json
看到下面的输出说明开始正常运行,在下载数据了:
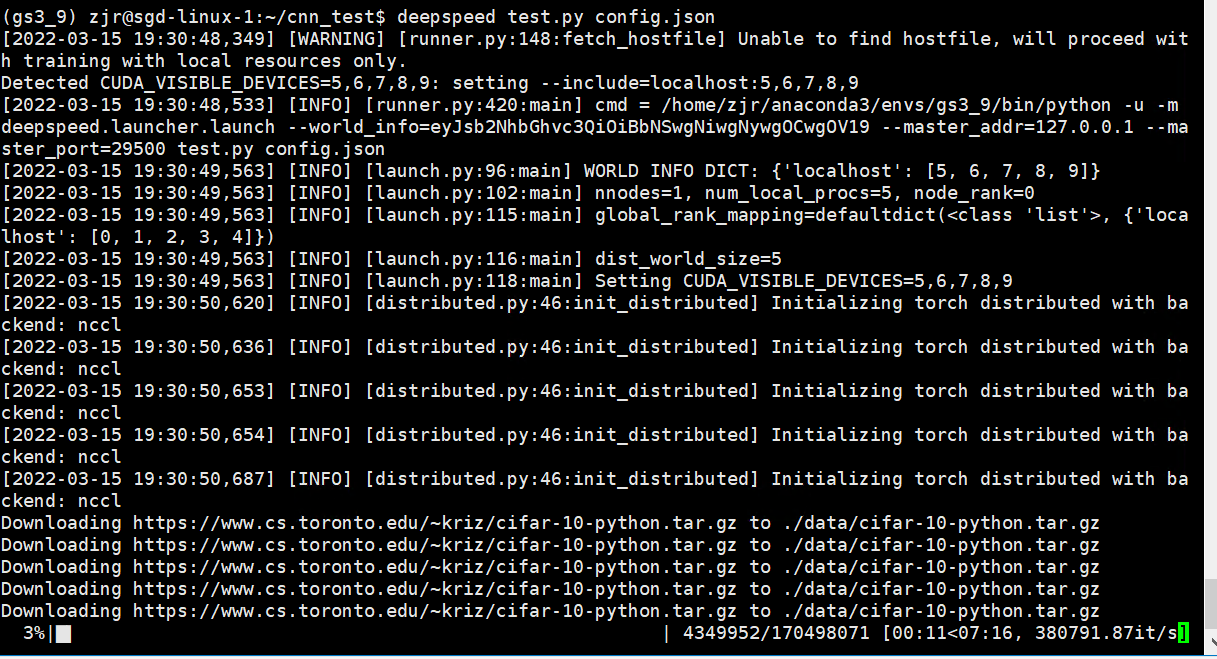
开始训练的时候 DeepSpeed 通常会打印更多的训练细节供用户监控,包括训练设置、性能统计和损失趋势,效果类似于:
worker-0: [INFO 2020-02-06 20:35:23] 0/24550, SamplesPerSec=1284.4954513975558 worker-0: [INFO 2020-02-06 20:35:23] 0/24600, SamplesPerSec=1284.384033658866 worker-0: [INFO 2020-02-06 20:35:23] 0/24650, SamplesPerSec=1284.4433482972925 worker-0: [INFO 2020-02-06 20:35:23] 0/24700, SamplesPerSec=1284.4664449792422 worker-0: [INFO 2020-02-06 20:35:23] 0/24750, SamplesPerSec=1284.4950124403447 worker-0: [INFO 2020-02-06 20:35:23] 0/24800, SamplesPerSec=1284.4756105952233 worker-0: [INFO 2020-02-06 20:35:24] 0/24850, SamplesPerSec=1284.5251526215386 worker-0: [INFO 2020-02-06 20:35:24] 0/24900, SamplesPerSec=1284.531217073863 worker-0: [INFO 2020-02-06 20:35:24] 0/24950, SamplesPerSec=1284.5125323220368 worker-0: [INFO 2020-02-06 20:35:24] 0/25000, SamplesPerSec=1284.5698818883018 worker-0: Finished Training worker-0: GroundTruth: cat ship ship plane worker-0: Predicted: cat car car plane worker-0: Accuracy of the network on the 10000 test images: 57 %
当你运行到最后,出现了这样的输出,恭喜你,完成了你的第一个 DeepSpeed 模型,可以开始你的大规模训练之路了。
我们的文章到此就结束啦,如果你喜欢今天的 Python 教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 ( pythondict.com )
不只是一个宝典
欢迎关注公众号:Python实用宝典
NNI 自动机器学习调参,是微软开源的又一个神器,它能帮助你找到最好的神经网络架构或超参数,支持各种训练环境。
它常用的使用场景如下:
它支持的框架有:
基本上市面上所有的深度学习和机器学习的框架它都支持。
下面就来看看怎么使用这个工具。
开始之前,你要确保Python和pip已经成功安装在电脑上,如果没有,请访问这篇文章:超详细Python安装指南 进行安装。
(可选1) 如果你用Python的目的是数据分析,可以直接安装Anaconda:Python数据分析与挖掘好帮手—Anaconda,它内置了Python和pip.
(可选2) 此外,推荐大家用VSCode编辑器来编写小型Python项目:Python 编程的最好搭档—VSCode 详细指南
Windows环境下打开Cmd(开始—运行—CMD),苹果系统环境下请打开Terminal(command+空格输入Terminal),输入命令安装依赖:
pip install --upgrade nni
让我们运行一个示例来验证是否安装成功,首先克隆项目:
git clone -b v2.6 https://github.com/Microsoft/nni.git
(如果你无法成功克隆项目,请在Python实用宝典后台回复nni下载项目)
运行 MNIST-PYTORCH 示例,Linux/macOS:
nnictl create --config nni/examples/trials/mnist-pytorch/config.yml
Windows:
nnictl create --config nni\examples\trials\mnist-pytorch\config_windows.yml
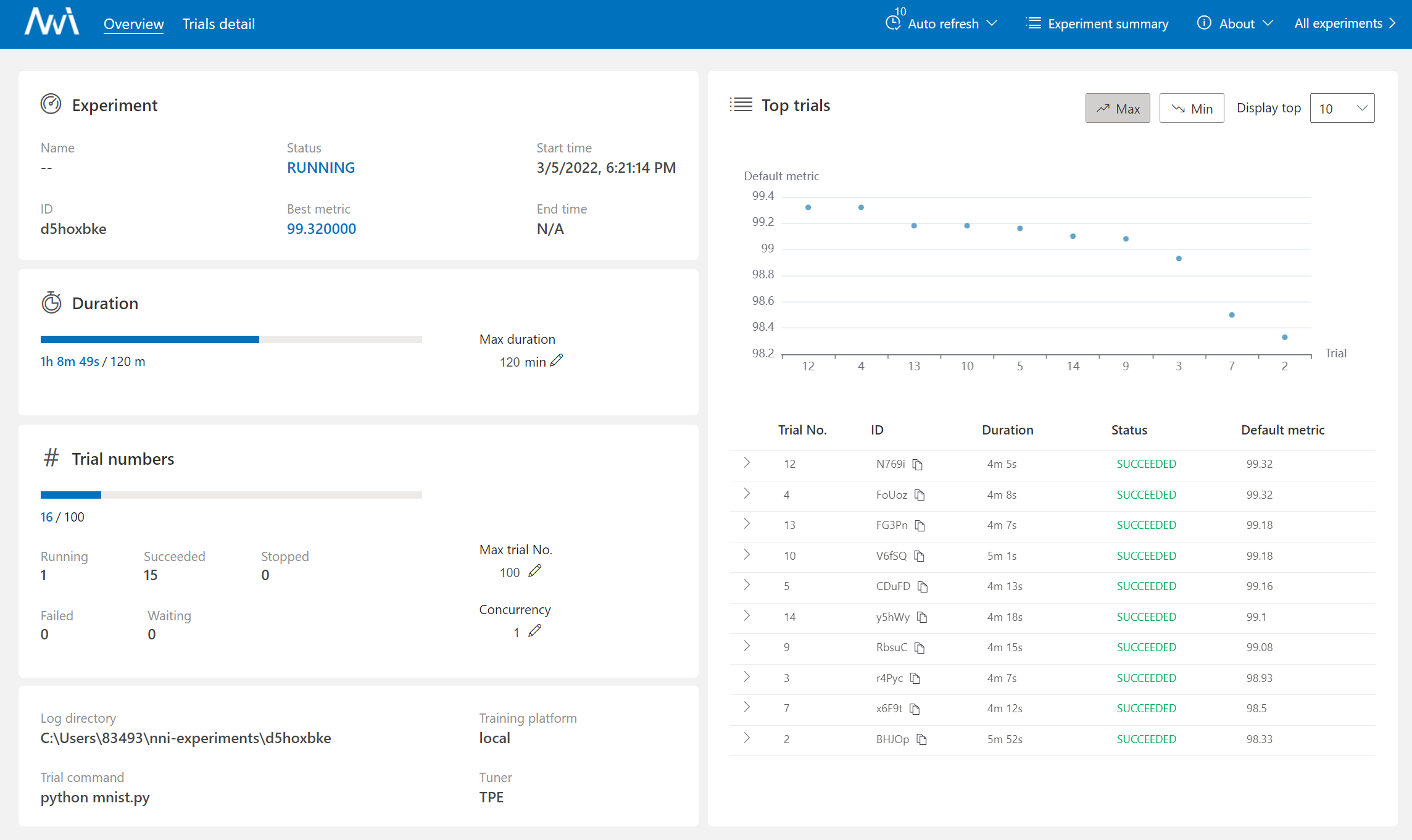
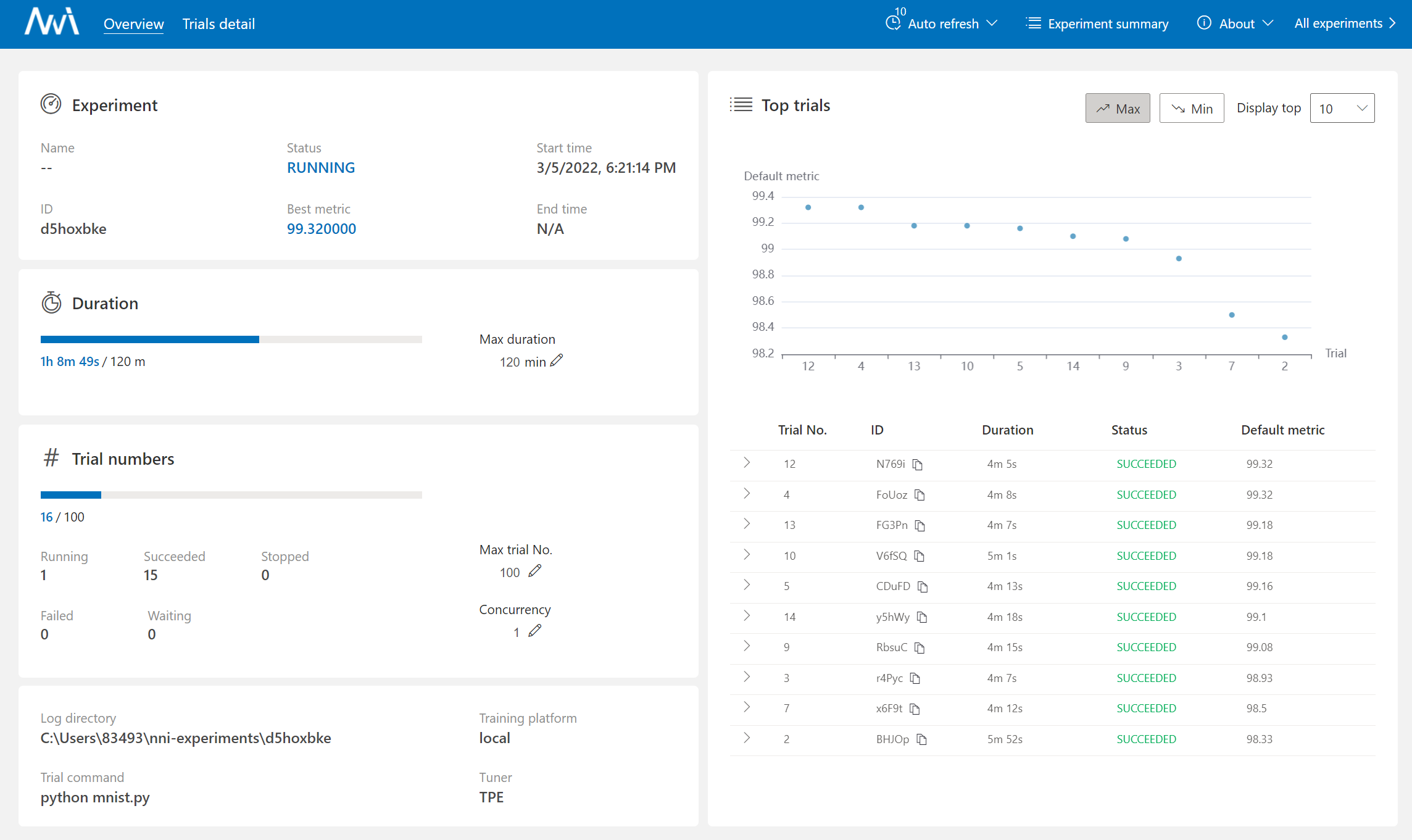
出现这样的界面就说明安装成功,示例运行正常:

访问 http://127.0.0.1:8080 可以配置运行时间、实验次数等:
那么如何让它和我们自己的模型适配呢?
观察 config_windows.yaml 会发现:
searchSpaceFile: search_space.json
trialCommand: python mnist.py
trialGpuNumber: 0
trialConcurrency: 1
tuner:
name: TPE
classArgs:
optimize_mode: maximize
trainingService:
platform: local
我们先看看 trialCommand, 这很明显是训练使用的命令,训练代码位于 mnist.py,其中有部分代码如下:
def get_params():
# Training settings
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument("--data_dir", type=str,
default='./data', help="data directory")
parser.add_argument('--batch_size', type=int, default=64, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument("--batch_num", type=int, default=None)
parser.add_argument("--hidden_size", type=int, default=512, metavar='N',
help='hidden layer size (default: 512)')
parser.add_argument('--lr', type=float, default=0.01, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--momentum', type=float, default=0.5, metavar='M',
help='SGD momentum (default: 0.5)')
parser.add_argument('--epochs', type=int, default=10, metavar='N',
help='number of epochs to train (default: 10)')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--no_cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--log_interval', type=int, default=1000, metavar='N',
help='how many batches to wait before logging training status')
args, _ = parser.parse_known_args()
return args
如上所示,这个模型里提供了 10 个参数选择。也就是说 NNI 可以帮我们自动测试这10个参数。
那么这些参数在哪里设定?答案是在 searchSpaceFile 中,对应的值也就是 search_space.json:
{
"batch_size": {"_type":"choice", "_value": [16, 32, 64, 128]},
"hidden_size":{"_type":"choice","_value":[128, 256, 512, 1024]},
"lr":{"_type":"choice","_value":[0.0001, 0.001, 0.01, 0.1]},
"momentum":{"_type":"uniform","_value":[0, 1]}
}
这里有4个选项,NNI 是怎么组合这些参数的呢?这就是tuner参数干的事,为了让机器学习和深度学习模型适应不同的任务和问题,我们需要进行超参数调优,而自动化调优依赖于优秀的调优算法。NNI 内置了先进的调优算法,并且提供了易于使用的 API。
在 NNI 中,调优算法被称为“tuner”。Tuner 向 trial 发送超参数,接收运行结果从而评估这组超参的性能,然后将下一组超参发送给新的 trial。
下表简要介绍了 NNI 内置的调优算法。
| Tuner | 算法简介 |
|---|---|
| TPE | Tree-structured Parzen Estimator (TPE) 是一种基于序列模型的优化方法 (sequential model-based optimization, SMBO)。SMBO方法根据历史数据来顺序地构造模型,从而预估超参性能,并基于此模型来选择新的超参。参考论文 |
| Random Search (随机搜索) | 随机搜索在超算优化中表现出了令人意外的性能。如果没有对超参分布的先验知识,我们推荐使用随机搜索作为基线方法。参考论文 |
| Anneal (退火) | 朴素退火算法首先基于先验进行采样,然后逐渐逼近实际性能较好的采样点。该算法是随即搜索的变体,利用了反应曲面的平滑性。该实现中退火率不是自适应的。 |
| Naive Evolution(朴素进化) | 朴素进化算法来自于 Large-Scale Evolution of Image Classifiers。它基于搜索空间随机生成一个种群,在每一代中选择较好的结果,并对其下一代进行变异。朴素进化算法需要很多 Trial 才能取得最优效果,但它也非常简单,易于扩展。参考论文 |
| SMAC | SMAC 是基于序列模型的优化方法 (SMBO)。它利用使用过的最突出的模型(高斯随机过程模型),并将随机森林引入到SMBO中,来处理分类参数。NNI 的 SMAC tuner 封装了 GitHub 上的 SMAC3。参考论文注意:SMAC 算法需要使用 pip install nni[SMAC] 安装依赖,暂不支持 Windows 操作系统。 |
| Batch(批处理) | 批处理允许用户直接提供若干组配置,为每种配置运行一个 trial。 |
| Grid Search(网格遍历) | 网格遍历会穷举搜索空间中的所有超参组合。 |
| Hyperband | Hyperband 试图用有限的资源探索尽可能多的超参组合。该算法的思路是,首先生成大量超参配置,将每组超参运行较短的一段时间,随后抛弃其中效果较差的一半,让较好的超参继续运行,如此重复多轮。参考论文 |
| Metis | 大多数调参工具仅仅预测最优配置,而 Metis 的优势在于它有两个输出:(a) 最优配置的当前预测结果, 以及 (b) 下一次 trial 的建议。大多数工具假设训练集没有噪声数据,但 Metis 会知道是否需要对某个超参重新采样。参考论文 |
| BOHB | BOHB 是 Hyperband 算法的后续工作。 Hyperband 在生成新的配置时,没有利用已有的 trial 结果,而本算法利用了 trial 结果。BOHB 中,HB 表示 Hyperband,BO 表示贝叶斯优化(Byesian Optimization)。 BOHB 会建立多个 TPE 模型,从而利用已完成的 Trial 生成新的配置。参考论文 |
| GP (高斯过程) | GP Tuner 是基于序列模型的优化方法 (SMBO),使用高斯过程进行 surrogate。参考论文 |
| PBT | PBT Tuner 是一种简单的异步优化算法,在固定的计算资源下,它能有效的联合优化一组模型及其超参来最优化性能。参考论文 |
| DNGO | DNGO 是基于序列模型的优化方法 (SMBO),该算法使用神经网络(而不是高斯过程)去建模贝叶斯优化中所需要的函数分布。 |
可以看到示例中,选择的是TPE tuner.
其他的参数比如 trialGpuNumber,指的是使用的gpu数量,trialConcurrency 指的是并发数。trainingService 中 platform 为 local,指的是本地训练。
当然,还有许多参数可以选,比如:
trialConcurrency: 2 # 同时运行 2 个 trial maxTrialNumber: 10 # 最多生成 10 个 trial maxExperimentDuration: 1h # 1 小时后停止生成 trial
不过这些参数在调优开始时的web页面上是可以进行调整的。
所以其实NNI干的事情就很清楚了,也很简单。你只需要在你的模型训练文件中增加你想要调优的参数作为输入,就能使用NNI内置的调优算法对不同的参数进行调优,而且允许从页面UI上观察调优的整个过程,相对而言还是很方便的。
不过,NNI可能不太适用一些数据量极大或模型比较复杂的情况。比如基于DDP开发的模型,在NNI中可能无法实现大型的分布式计算。
当然,绝大多数情况下的训练任务,NNI都可以用得上。大家有兴趣深入使用的可以阅读NNI官方文档:https://nni.readthedocs.io/
我们的文章到此就结束啦,如果你喜欢今天的 Python 教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 ( pythondict.com )
不只是一个宝典
欢迎关注公众号:Python实用宝典

老照片作为时光记忆的载体,不只是过去美好时光的传承者,同时也是每个人的情结和怀念的寄托。
随着时间的流逝,许多老照片都因为自然或人为原因,受到了侵蚀损坏,画面模糊、褪色、照片磨损严重等现象,甚至还有的因为保管不好导致照片面目全非。
今天的这个Python模块叫GFPGAN,它能够让这些老照片恢复原有的光泽,使用了GAN算法对照片进行修复,效果比其他同类模型都有更好的表现。本模块支持Python3.7+版本。
开始之前,你要确保Python和pip已经成功安装在电脑上,如果没有,请访问这篇文章:超详细Python安装指南 进行安装。
(可选1) 如果你用Python的目的是数据分析,可以直接安装Anaconda:Python数据分析与挖掘好帮手—Anaconda,它内置了Python和pip.
(可选2) 此外,推荐大家用VSCode编辑器来编写小型Python项目:Python 编程的最好搭档—VSCode 详细指南
Windows环境下打开Cmd(开始—运行—CMD),苹果系统环境下请打开Terminal(command+空格输入Terminal),输入命令安装依赖:
# 克隆项目 git clone https://github.com/TencentARC/GFPGAN.git # 进入项目 cd GFPGAN # 安装依赖 pip install basicsr pip install facexlib pip install -r requirements.txt pip install realesrgan # 安装程序 python setup.py develop
GFPGAN模型需要通过数据集训练得到,由于训练需要使用的数据量和算力非常大,作者团队提供了许多预处理好的模型给普通用户下载,这样我们就能绕过训练这个步骤直接使用模型,下载地址如下:
https://github.com/TencentARC/GFPGAN/releases/download/v0.2.0/GFPGANCleanv1-NoCE-C2.pth
如果你无法访问GitHub,也可以在Python实用宝典后台回复:GFPGAN 下载。包含了本项目源代码及许多其他预训练好的模型,包括:
将想要使用的预训练模型放入 experiments/pretrained_models 文件夹下就可以开始使用了。
使用方法非常简单,进入项目目录后输入以下命令:
python inference_gfpgan.py --model_path experiments/pretrained_models/GFPGANv1.pth --test_path inputs/cropped_faces --save_root results
其中,各个参数的意义如下:
model_path: 使用的模型的位置。
test_path: 需要转换的老照片的路径。
save_root: 转换结果存放的路径。
效果如下:


可见其修复效果是非常优秀的,如果你们也有需要修复的老照片,可以尝试使用手机的照片扫描仪软件扫描后使用此模块修复。
如果你对模型的输出结果不是很满意,你还可以基于作者团队给出的模型做微调。微调能实现以下目的:
1.如果你有更高质量的人脸数据,可以提高修复效果。
2.你可能需要对数据做一些微处理,比如美妆等。
微调流程如下:
1.准备好训练数据集:https://github.com/NVlabs/ffhq-dataset
2.下载预训练模型和其他你自己的数据,把它们放在 experiments/pretrained_models 文件夹里。我们公众号后台提供以下预训练模型:
3.根据自身需求,相应地修改配置文件 options/train_gfpgan_v1.yml。
4.输入命令训练:
python -m torch.distributed.launch --nproc_per_node=4 --master_port=22021 gfpgan/train.py -opt options/train_gfpgan_v1.yml --launcher pytorch
模型微调的难度比较大,可能会遇到不少问题,大家要善于利用搜索引擎解决问题。
我们的文章到此就结束啦,如果你喜欢今天的 Python 教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 ( pythondict.com )
不只是一个宝典
欢迎关注公众号:Python实用宝典
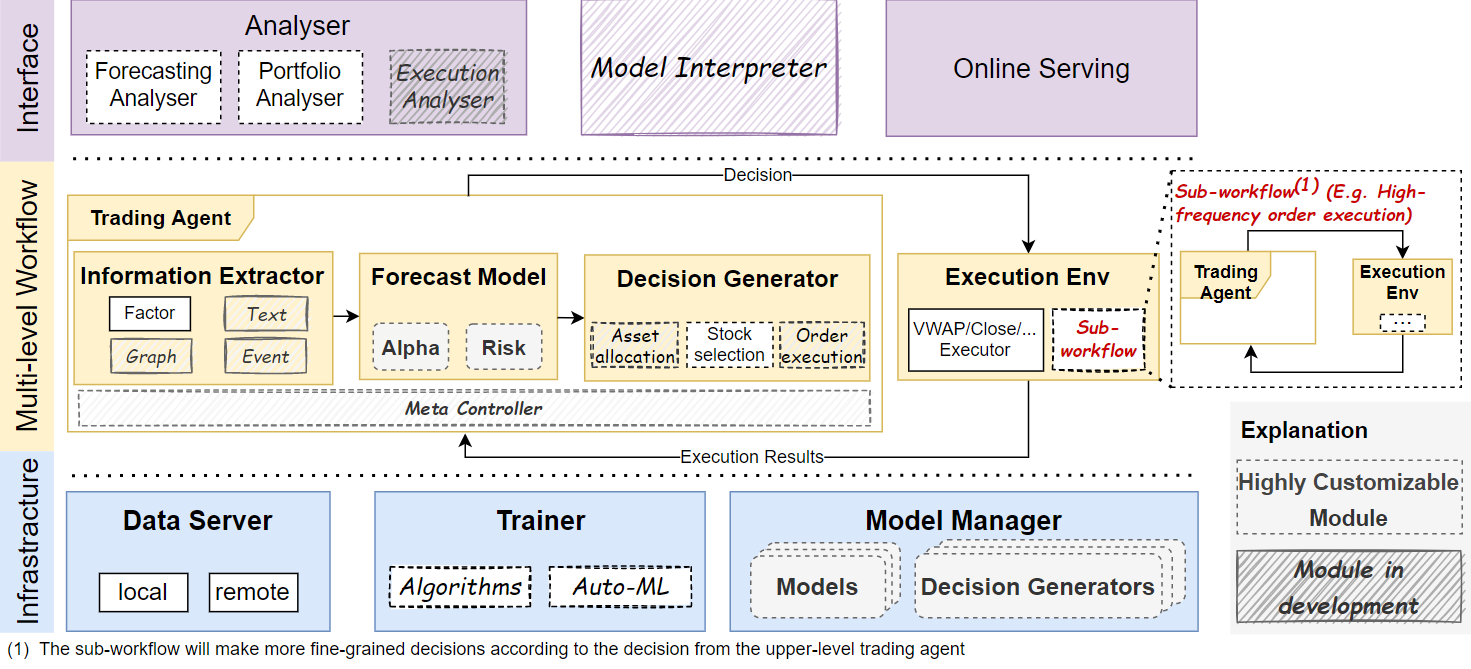
2020年9月,微软开源了AI量化投资平台Qlib的源代码,随后得到了不少的关注,Qlib的主要优势在于:
1.Python覆盖量化投资全过程,用户无需切换语言;内置许多深度学习算法模型,降低AI算法使用的门槛。
2.内置A股、美股数据接入通道,基于qrun能够自动运行整个工作流程,大大提高开发效率。
3.每个组件都是松耦合可以独立使用,用户能够自行选用某些组件。
Qlib相比于我们之前介绍的backtrader,那功能完善太多。backtrader相当于给你提供一个基本的量化框架,数据、策略、算法,你全部自己搞定。而Qlib则从数据、到策略、到算法都给了你全套的解决方案,你只需要加一点自己的想法,不需要管其他细枝末节的东西就能完成AI量化研究,非常方便。
下面我们就来试一下 Qlib 的安装和运行内置算法策略。
开始之前,你要确保Python和pip已经成功安装在电脑上,如果没有,请访问这篇文章:超详细Python安装指南 (传统) 或 Python数据分析与挖掘好帮手—Anaconda 进行安装,本文建议使用Anaconda。
由于qlib有许多许多依赖,如果你不想安装过程中出现问题,或者引起其他程序的运行问题,建议使用Conda创建一个你的量化投资虚拟环境:
conda create -n my_quant python=3.8
Qlib 仅支持 Python3.7以上的版本且暂不支持 Python3.10. 另外Python 3.9 版本不支持模型性能绘制,因此我选择创建Python3.8版本的虚拟环境。
(安装方式一)pip 安装:
pip install pyqlib
在pip安装的过程中如果遇到任何问题,请搜索引擎解决,如果无法解决,可以尝试下面的源码安装:
(安装方式二)源码安装:
# 提前安装一些依赖 pip install numpy pip install --upgrade cython # clone and install qlib git clone https://github.com/microsoft/qlib.git && cd qlib python setup.py install
Windows 机器在安装的时候可能会遇到下面这个问题:
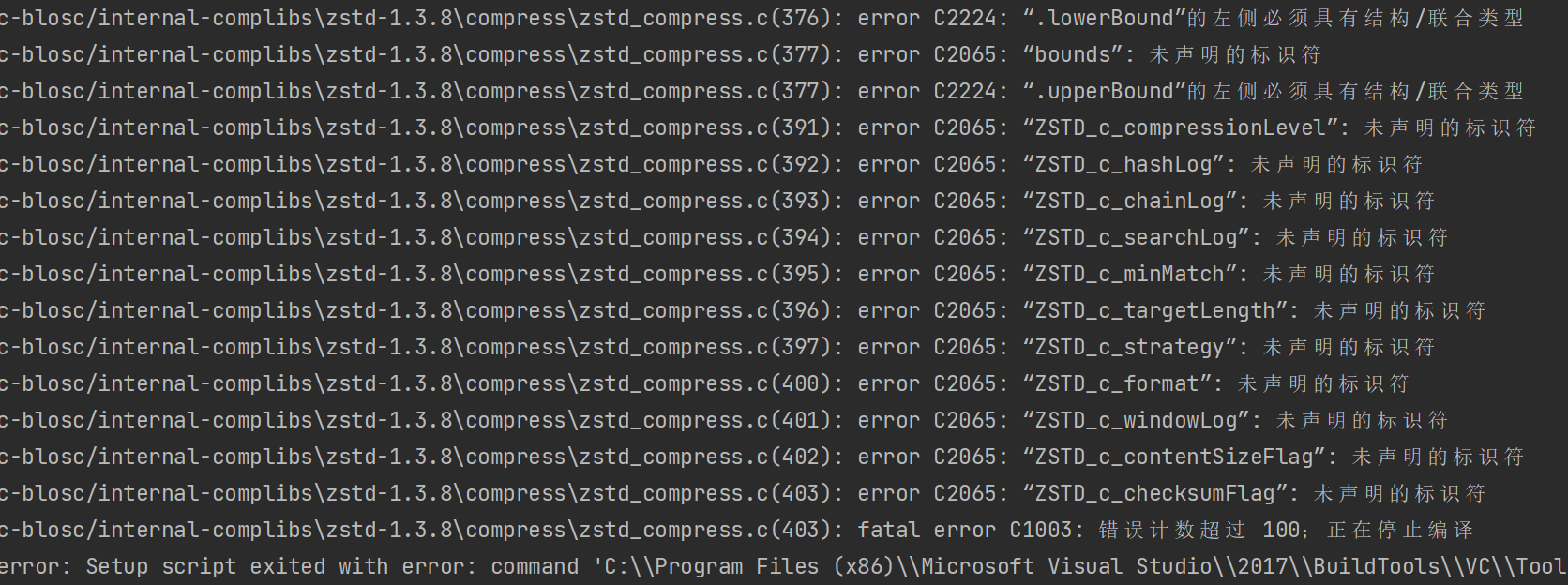
这是因为安装 qlib 的依赖 — tables 时出现了编译错误,原因很多,我选择逃学,因此建议使用 tables 的 wheel 文件进行安装,这样就不需要编译了:
https://www.lfd.uci.edu/~gohlke/pythonlibs/#pytables
在上述网站下载适合你系统的 wheel 文件:

下载完毕后,输入以下命令:
pip install 你的文件路径/tables-3.6.1-cp39-cp39-win_amd64.whl
即可完成 tables 的安装,然后再执行一遍 python setup.py install 即可。
由于这套量化开源平台的作者是中国人,所以非常贴心地准备好了A股数据,大家可以输入命令直接下载:
# 1天级别数据 python scripts/get_data.py qlib_data --target_dir ~/.qlib/qlib_data/cn_data --region cn # 1分钟级别数据 python scripts/get_data.py qlib_data --target_dir ~/.qlib/qlib_data/cn_data_1min --region cn --interval 1min
如果你需要其他分钟级的数据,修改interval即可。
你可以使用crontab定时自动更新数据(来自雅虎财经):
* * * * 1-5 python <script path> update_data_to_bin --qlib_data_1d_dir <user data dir>
手动更新数据:
python scripts/data_collector/yahoo/collector.py update_data_to_bin --qlib_data_1d_dir <user data dir> --trading_date <start date> --end_date <end date>
Qlib 提供了一个名为 qrun 自动运行整个工作流程的工具(包括构建数据集、训练模型、回测和评估)。
你可以按照以下步骤启动自动量化研究工作流程并进行图形报告分析,Quant Research 工作流程:
Qrun 运行 lightgbm 工作流程的配置 workflow_config_lightgbm_Alpha158.yaml 如下所示:
cd examples # Avoid running program under the directory contains `qlib` qrun benchmarks/LightGBM/workflow_config_lightgbm_Alpha158.yaml
结果如下:
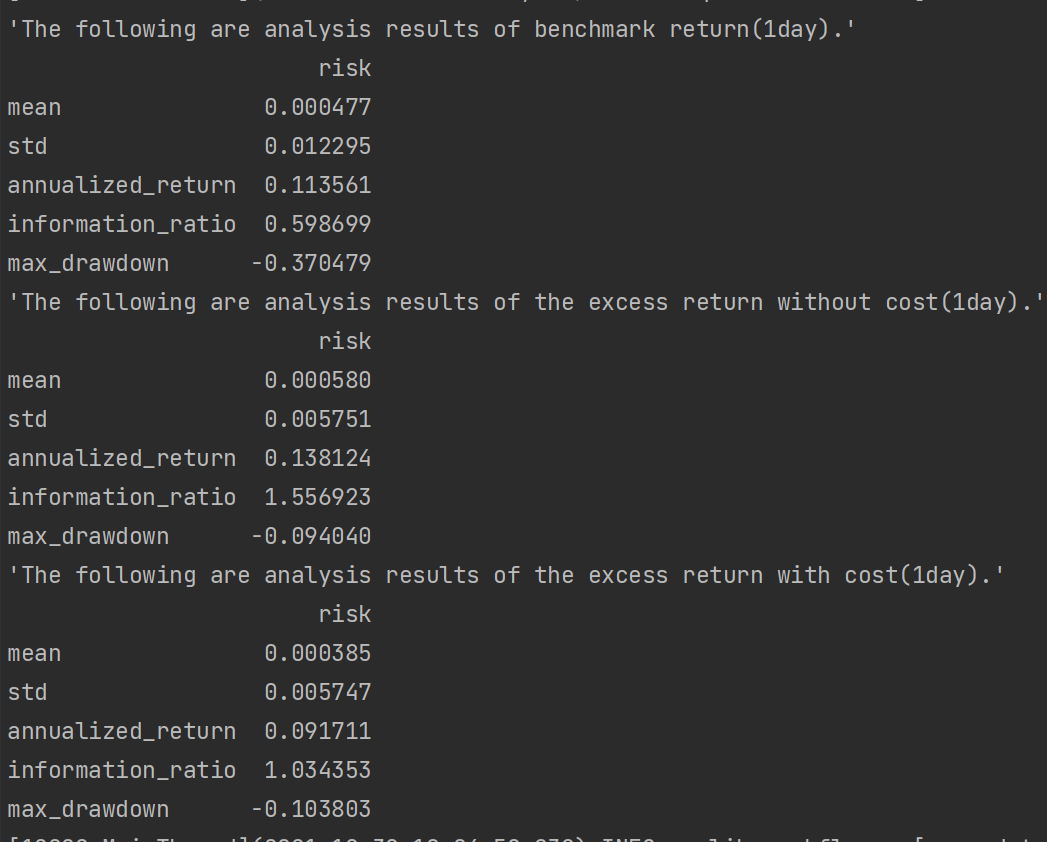
可以看到这里包括三个统计分析: benchmark return (基准收益) / excess return without cost(除去手续费的超额收益)) / excess return with cost(包含手续费的超额收益)。每个统计分析中都有如下5个参数:
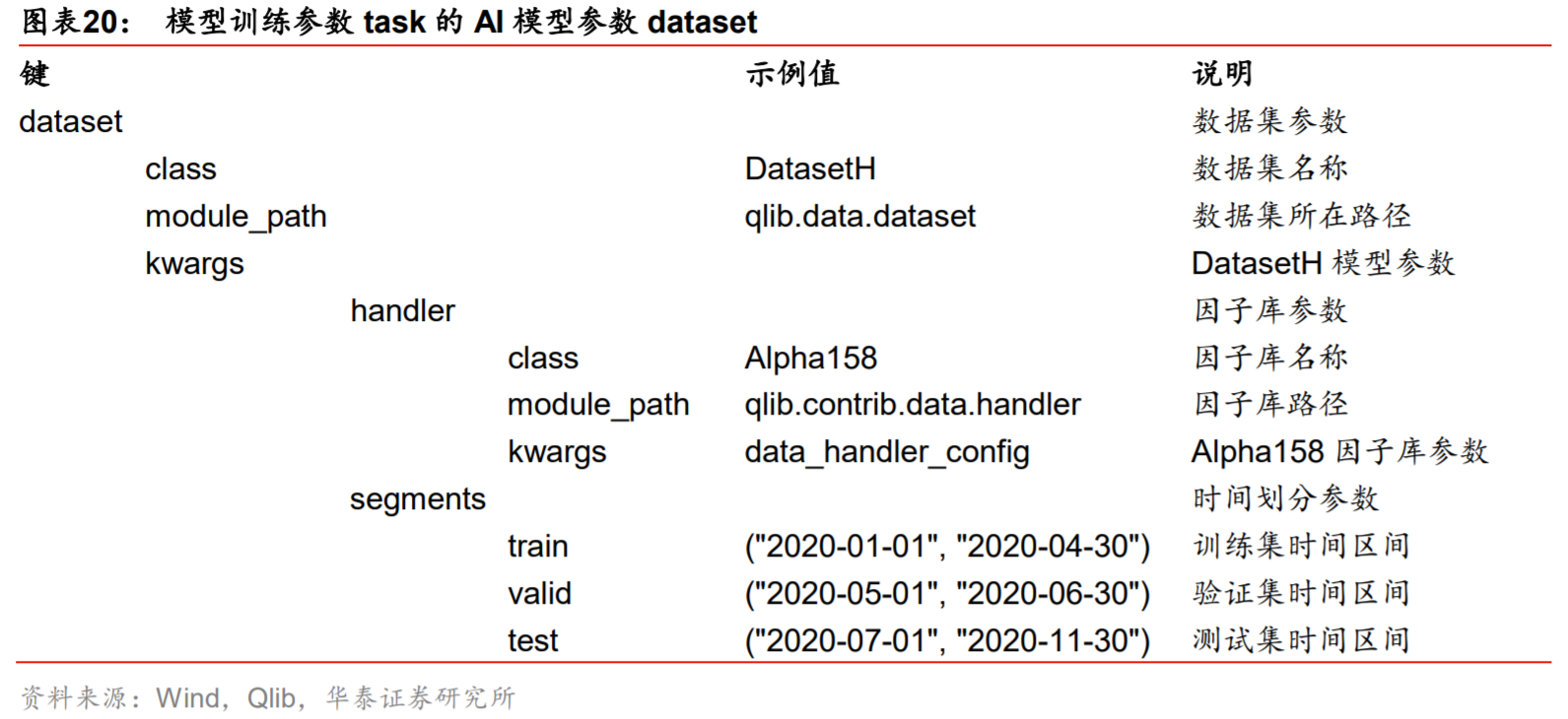
如果你想要自定义这个策略和算法的回测参数,你可以查看 workflow_config_lightgbm_Alpha158.yaml 的内容:
qlib_init:
provider_uri: "~/.qlib/qlib_data/cn_data"
region: cn
market: &market csi300
benchmark: &benchmark SH000300
data_handler_config: &data_handler_config
start_time: 2008-01-01
end_time: 2020-08-01
fit_start_time: 2008-01-01
fit_end_time: 2014-12-31
instruments: *market
port_analysis_config: &port_analysis_config
strategy:
class: TopkDropoutStrategy
module_path: qlib.contrib.strategy
kwargs:
model: <MODEL>
dataset: <DATASET>
topk: 50
n_drop: 5
backtest:
start_time: 2017-01-01
end_time: 2020-08-01
account: 100000000
benchmark: *benchmark
exchange_kwargs:
limit_threshold: 0.095
deal_price: close
open_cost: 0.0005
close_cost: 0.0015
min_cost: 5
task:
model:
class: LGBModel
module_path: qlib.contrib.model.gbdt
kwargs:
loss: mse
colsample_bytree: 0.8879
learning_rate: 0.2
subsample: 0.8789
lambda_l1: 205.6999
lambda_l2: 580.9768
max_depth: 8
num_leaves: 210
num_threads: 20
dataset:
class: DatasetH
module_path: qlib.data.dataset
kwargs:
handler:
class: Alpha158
module_path: qlib.contrib.data.handler
kwargs: *data_handler_config
segments:
train: [2008-01-01, 2014-12-31]
valid: [2015-01-01, 2016-12-31]
test: [2017-01-01, 2020-08-01]
record:
- class: SignalRecord
module_path: qlib.workflow.record_temp
kwargs:
model: <MODEL>
dataset: <DATASET>
- class: SigAnaRecord
module_path: qlib.workflow.record_temp
kwargs:
ana_long_short: False
ann_scaler: 252
- class: PortAnaRecord
module_path: qlib.workflow.record_temp
kwargs:
config: *port_analysis_config
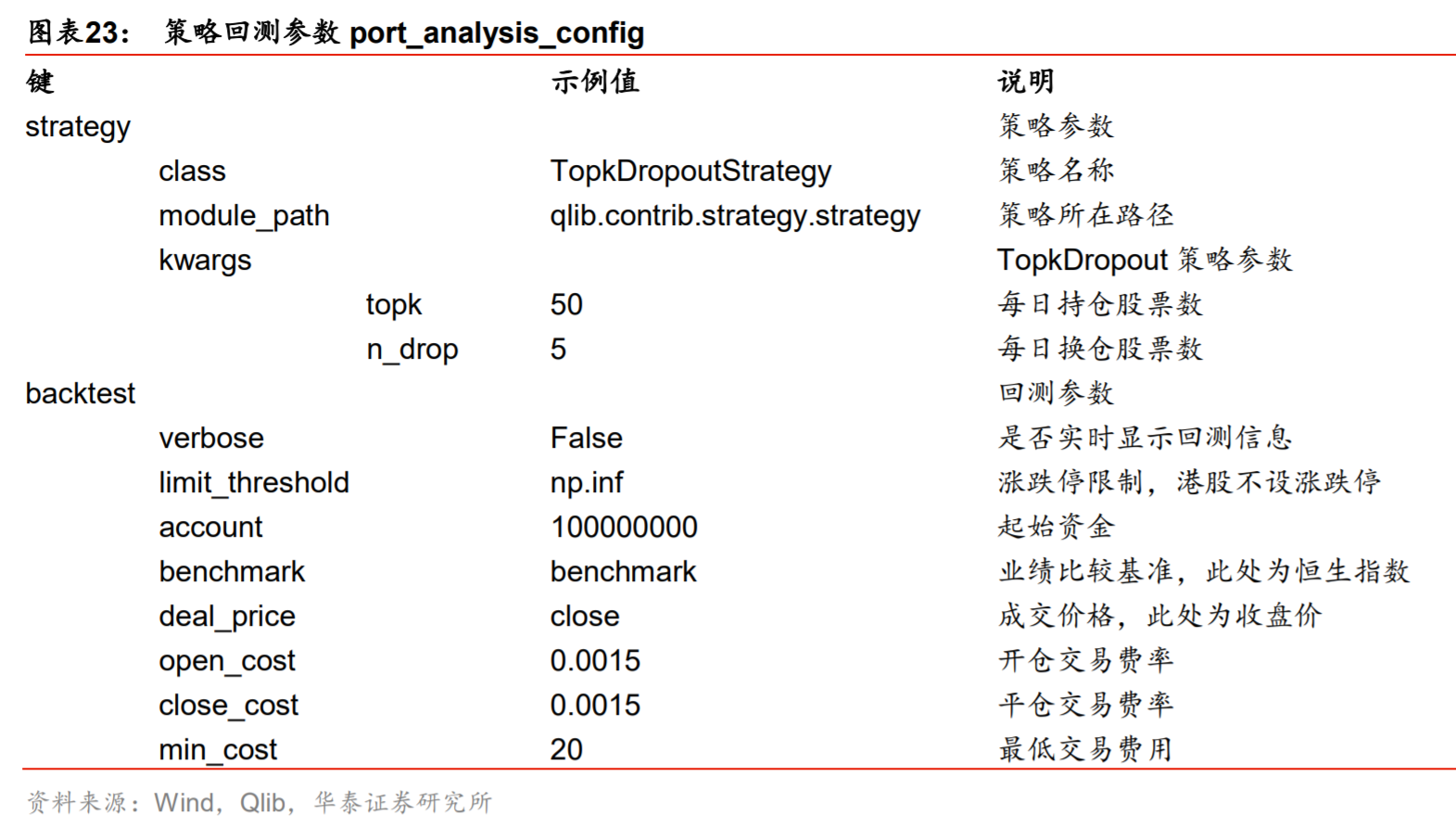
参数比较多,大家翻译一下应该都能看懂。这里摘取华泰的一个研究报告,里面对参数做了具体的翻译:

为了方便用户的使用,微软内置了许多模型,如上文我们用到的 gbdt 位于你克隆的文件夹下的 qlib/contrib/model/gbdt.py:
注意:pytorch 开头的模型需要预先安装pytorch.
Qlib里,策略和算法的区别是什么?
大家注意到,Qlib这里,必须定义策略和算法两个配置,而在backtrader里面,我们更加重视策略,而非“算法”这个概念。那么这两者在Qlib中的区别是什么?我们看默认TOPK策略的源代码:
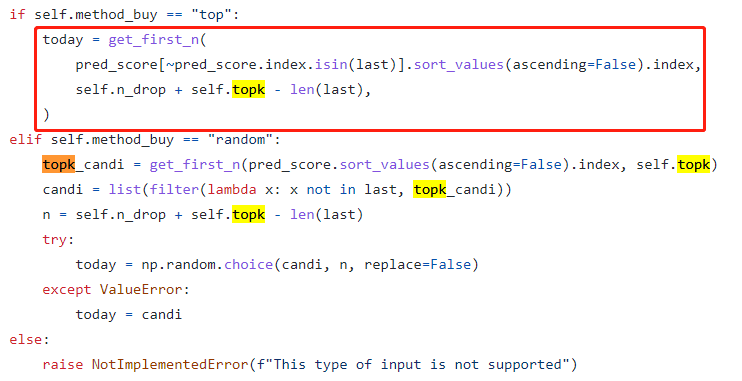
可以看到,默认的这个策略,选择了算法预测分数结果中排名 TOP K 的股票,也就是策略从算法得到的结果中去做筛选需要交易的股票。算法相当于生成一个新的可用于判断买入卖出的评判标准。这就是策略和AI算法这两者的最重要区别。
最后,得益于松耦合的代码设计,我认为 Qlib 是一个能够让不同层次的研究者各取所需的开源项目,是一个不可多得的量化开源平台,特别适合重度Python使用者,有兴趣的朋友可以试一下,我未来也会考虑出 Qlib 相关的使用教程,敬请期待。
我们的文章到此就结束啦,如果你喜欢今天的 Python 教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 ( pythondict.com )
不只是一个宝典
欢迎关注公众号:Python实用宝典





































