

Paddle是一个比较高级的深度学习开发框架,其内置了许多方便的计算单元可供使用,我们之前写过PaddleHub相关的文章:
在这些文章里面,我们基于PaddleHub训练好的模型直接进行预测,用起来特别方便。不过,我并没提到如何用自己的数据进行训练,因此本文将弥补前几篇文章缺少的内容,讲解如何使用paddle训练、测试、推断自己的数据。
2023-04-26更新:
提供一个5W行的数据源,数据结构请自行组合:https://pythondict.com/download/%e8%b5%b0%e9%a5%ad%e5%be%ae%e5%8d%9a%e8%af%84%e8%ae%ba%e6%95%b0%e6%8d%ae/
2024-04-26更新:
很多同学要源代码和模型,下载地址:
【源代码+模型】基于Paddle训练一个98%准确率的抑郁文本预测
1.准备
开始之前,你要确保Python和pip已经成功安装在电脑上噢,如果没有,请访问这篇文章:超详细Python安装指南 进行安装。
Windows环境下打开Cmd(开始—运行—CMD),苹果系统环境下请打开Terminal(command+空格输入Terminal),准备开始输入命令安装依赖。
当然,我更推荐大家用VSCode编辑器,把本文代码Copy下来,在编辑器下方的终端装依赖模块,多舒服的一件事啊:Python 编程的最好搭档—VSCode 详细指南。
我们需要安装百度的paddlepaddle, 进入他们的官方网站就有详细的指引:
https://www.paddlepaddle.org.cn/install/quick

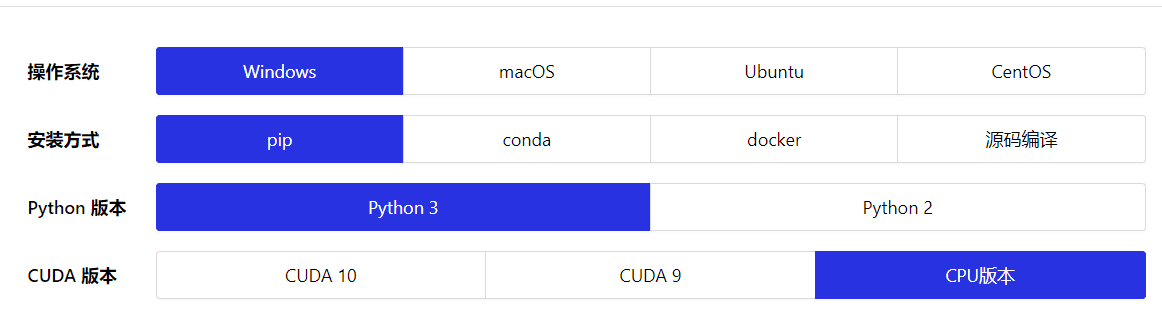
根据你自己的情况选择这些选项,最后一个CUDA版本,由于本实验不需要训练数据,也不需要太大的计算量,所以直接选择CPU版本即可。选择完毕,下方会出现安装指引,不得不说,Paddlepaddle这些方面做的还是比较贴心的(就是名字起的不好)。


要注意,如果你的Python3环境变量里的程序名称是Python,记得将语句改为Python xxx,如下进行安装:
python -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
最后是安装paddlehub:
pip install -i https://mirror.baidu.com/pypi/simple paddlehub
然后为了用paddle的模型训练我们自己的数据,还需要下载他们的源代码:
git clone https://github.com/PaddlePaddle/models.git
比较大,大概400M。
2024-04-26更新:
很多同学要源代码和模型,下载地址:
【源代码+模型】基于Paddle训练一个98%准确率的抑郁文本预测
2. 数据预处理
这次实验,我使用了8000条走饭下面的评论和8000条其他微博的正常评论作为训练集,两个分类分别使用1000条数据作为测试集。
2.1 去重去脏
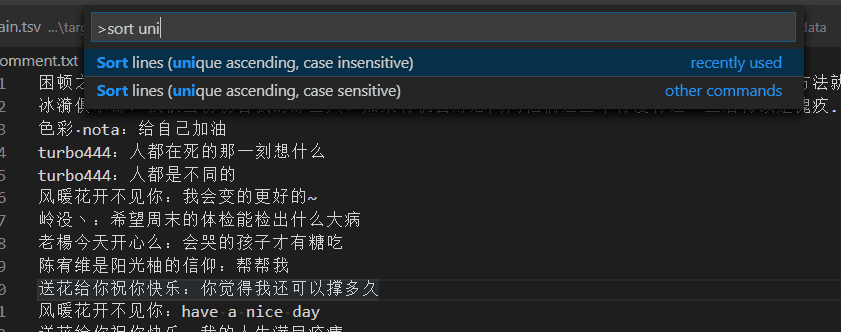
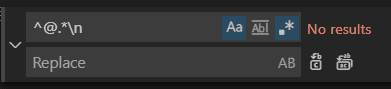
在这一步,我们需要先去除重复数据,并使用正则表达式@.* 和 ^@.*\n 去除微博@的脏数据。如果你是使用Vscode的,可以使用sort lines插件去除重复数据:

如果不是Vscode,请用Python写一个脚本,遍历文件,将每一行放入集合中进行去重。比较简单,这里不赘述啦。
正则表达式去除脏数据,我这里数据量比较少,直接编辑器解决了:

2.2 分词
首先,需要对我们的文本数据进行分词,这里我们采用结巴分词的形式进行:


然后需要在分词的结果后面使用\t隔开加入标签,我这里是将有抑郁倾向的句子标为0,将正常的句子标为1. 此外,还需要将所有词语保存起来形成词典文件,每个词为一行。
并分别将训练集和测试集保存为 train.tsv 和 dev.tsv, 词典文件命名为word_dict.txt, 方便用于后续的训练。
3.训练
下载完Paddle模型源代码后,进入 models/PaddleNLP/sentiment_classification文件夹下,这里是情感文本分类的源代码部分。

在开始训练前,你需要做以下工作:
1.将train.tsv、dev.tsv及word_dict.txt放入senta_data文件夹.
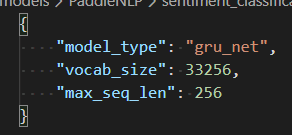
2.设置senta_config.json的模型类型,我这里使用的是gru_net:

3.修改run.sh相关的设置:


如果你的paddle是CPU版本的,请把use_cuda改为false。此外还有一个save_steps要修改,代表每训练多少次保存一次模型,还可以修改一下训练代数epoch,和 一次训练的样本数目 batch_size.
4.如果你是windows系统,还要新建一个save_models文件夹,然后在里面分别以你的每训练多少次保存一次的数字再新建文件夹。。没错,这可能是因为他们开发这个框架的时候是基于linux的,他们写的保存语句在linux下会自动生成文件夹,但是windows里不会。

好了现在可以开始训练了,由于训练启动脚本是shell脚本,因此我们要用powershell或git bash运行指令,Vscode中可以选择默认的终端,点击Select Default Shell后选择一个除cmd外的终端即可。

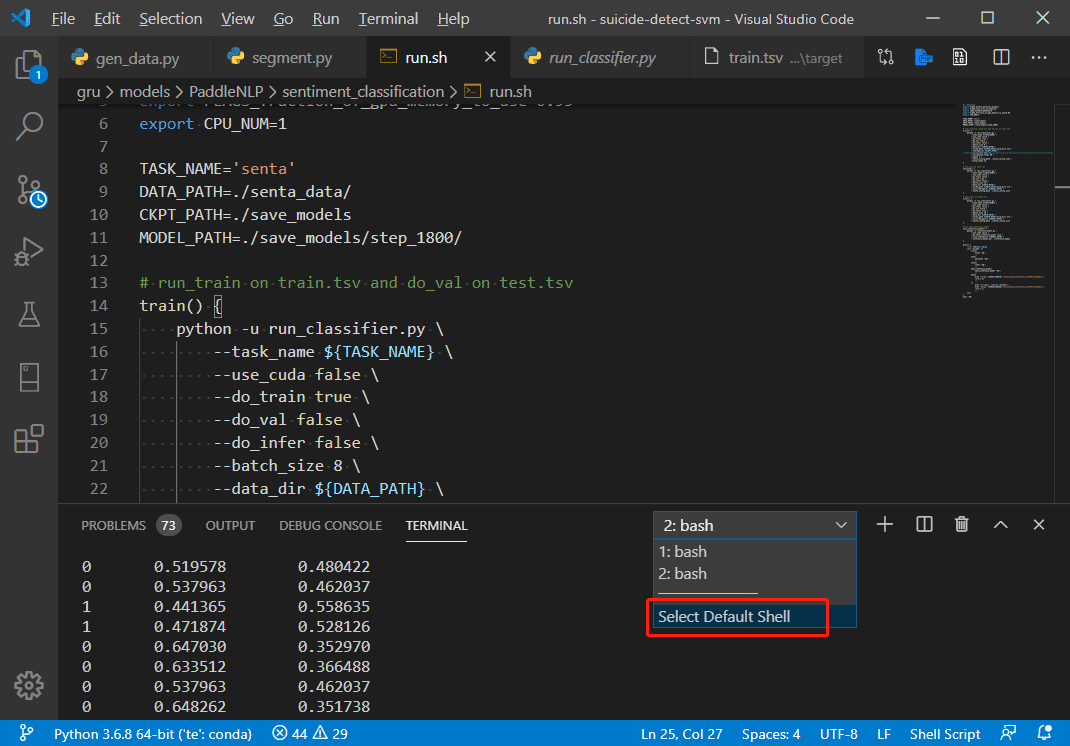
输入以下语句开始训练
$ sh run.sh train

4.测试
恭喜你走到了这一步,作为奖励,这一步你只需要做两个操作。首先是将run.sh里的MODEL_PATH修改为你刚保存的模型文件夹:

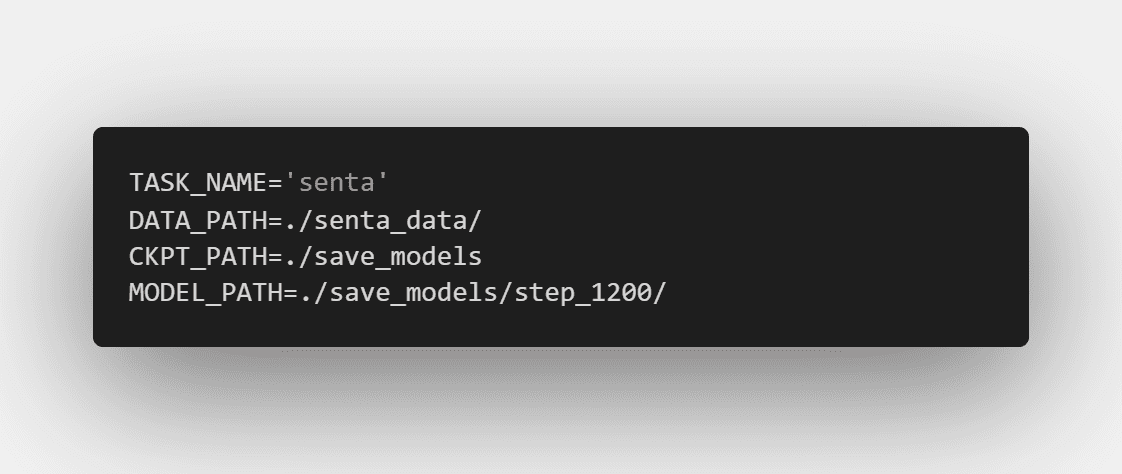
我这里最后一次训练保存的文件夹是step_1200,因此填入step_1200,要依据自己的情况填入。然后一句命令就够了:
$ sh run.sh eval
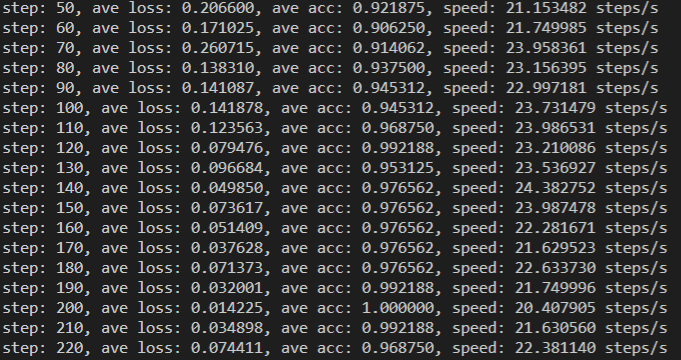
然后就会输出损失率和准确率:


可以看到我的模型准确率大概有98%,还是挺不错的。
5.预测
我们随意各取10条抑郁言论和普通言论,命名为test.txt存入senta_data文件夹中,输入以下命令进行预测:
$ sh run.sh test
这二十条句子如下,前十条是抑郁言论,后十条是普通言论:
好 崩溃 每天 都 是 折磨 真的 生不如死 姐姐 我 可以 去 找 你 吗 内心 阴暗 至极 … … 大家 今晚 都 是因为 什么 没睡 既然 儿子 那么 好 那 就 别生 下 我 啊 生下 我 又 把 我 扔下 让 我 自生自灭 这算 什么 走饭 小姐姐 怎么办 我该 怎么办 每天 都 心酸 心如刀绞 每天 都 有 想要 死 掉 的 念头 我 不想 那么 痛苦 了 你 凭 什么 那么 轻松 就 说出 这种 话 一 闭上眼睛 脑子里 浮现 的 就是 他 的 脸 和 他 的 各种 点点滴滴 好 难受 睡不着 啊 好 难受 为什么 吃 了 这么 多 东西 还是 不 快乐 呢 以前 我 看到 那些 有手 有 脚 的 人 在 乞讨 我 都 看不起 他们 我 觉得 他们 有手 有 脚 的 不 应该 乞讨 他们 完全 可以 凭 自己 的 双手 挣钱 但是 现在 我 有 手 有 脚 我 也 想 去 人 多 的 地方 乞讨 … 我 不想 努力 了 … 熬过来 吧 求求 你 了 好 吗 是 在 说 我们 合肥 吗 ? 这歌 可以 啊 用 一个 更坏 的 消息 掩盖 这 一个 坏消息 请 尊重 他人 隐私 这种 行为 必须 严惩不贷 这个 要 转发 🙏 🙏 保佑 咱们 国家 各个 省 千万别 再有 出事 的 也 别 瞒报 大家 一定 要 好好 的 坚持 到 最后 加油 我 在家 比 在 学校 有钱 在家 吃饭 零食 水果 奶 都 是 我 妈 天天 给 我 买 每天 各种 水果 还 可以 压榨 我弟 跑腿 买 衣服 也 是 水乳 也 是 除了 化妆品 反正 现在 也 用不上 比 学校 的 日子 过得 好多 了 广西 好看 的 是 柳州 的 满城 紫荆花 加油 一起 共同 度过 这次 难关 我们 可以 平安 平安 老天 保佑
得到结果如下:
Final test result:
0 0.999999 0.000001
0 0.994013 0.005987
0 0.997636 0.002364
0 0.999975 0.000025
0 1.000000 0.000000
0 1.000000 0.000000
0 0.999757 0.000243
0 0.999706 0.000294
0 0.999995 0.000005
0 0.998472 0.001528
1 0.000051 0.999949
1 0.000230 0.999770
1 0.230227 0.769773
1 0.000000 1.000000
1 0.000809 0.999191
1 0.000001 0.999999
1 0.009213 0.990787
1 0.000003 0.999997
1 0.000363 0.999637
1 0.000000 1.000000
第一列是预测结果(0代表抑郁文本),第二列是预测为抑郁的可能性,第三列是预测为正常微博的可能性。可以看到,基本预测正确,而且根据这个分数值,我们还可以将文本的抑郁程度分为:轻度、中度、重度,如果是重度抑郁,应当加以干预,因为其很可能会发展成自杀倾向。
我们可以根据这个模型,构建一个自杀预测监控系统,一旦发现重度抑郁的文本迹象,即可实行干预,不过这不是我们能一下子做到的事情,需要随着时间推移慢慢改进这个识别算法,并和相关机构联动实行干预。
我们的文章到此就结束啦,如果你希望我们今天的Python 教程,请持续关注我们,如果对你有帮助,麻烦在下面点一个赞/在看哦![]()

Python实用宝典 (pythondict.com)
不只是一个宝典
欢迎关注公众号:Python实用宝典


你好,请问可以发一下源程序资料吗,仅供个人使用,尊重版权。十分感谢!
很久之前的文章了,如果我没记错的话,源代码应该就是使用了paddle的模型,我只是放了我爬的数据进去训练而已。