

模型成品在极致安食网:https://jizhianshi.com, 木有太多时间维护。
教程源代码点击阅读原文或访问:
https://github.com/Ckend/NLP_DeepLearning_CN_Tutorial
利用朴素贝叶斯来分类食品安全新闻(标题)这种短文本其实精确度并不高,在实际的生产中,由于食品安全和非食品安全的数量差异,我们会发现1000条新闻中可能才出现2条食品安全新闻,也就是说,即便你的模型准确率为95%,1000条新闻中依然会有许多新闻 (50条) 会被错分类,这是一个非常糟糕的结果。因此在生产环境中,如果模型准确率不能高达99%,甚至都无法使用。在我们的研究下,使用朴素贝叶斯,我们的准确率能提高到97%,使用改进的朴素贝叶斯准确率能达到98%以上,使用字符级的卷积神经网络甚至能达到99%,后续的教程我会介绍这两种方法。
为了后续的教程,我们还是先利用最简单的朴素贝叶斯来理解“训练”这个概念。为了尽量简化教程的难度,我尽量不使用数学公式进行讲解,更多的以自然语言和Python代码进行分析。在这个教程中,你所需要的东西有:
1. python 3
2. jieba 分词
3. numpy
4. sklearn (用joiblib保存模型)
训练
朴素贝叶斯的训练,其实就是遍历整个训练集,算出每个词语在不同的分类下出现的概率(该词语/该分类总词数)。最后得到两个向量,这两个向量分别代表了每个词语在食品安全新闻和非食品安全新闻中出现的概率。
for i in range(numTrainNews):
if classVector[i] == 1:
p1Num += trainMatrix[i]
# 每条食品安全新闻中,每个词的数量分布
p1Sum += sum(trainMatrix[i])
# 求每条新闻出现的食品安全集合中的词语的数量总合
else:
p0Num += trainMatrix[i]
p0Sum += sum(trainMatrix[i])
p1Vect = log(p1Num / p1Sum)
# 在1的情况下每个词语出现的概率
p0Vect = log(p0Num / p0Sum)
# 在0的情况下每个词语出现的概率
#保存结果
self.p0V = p0Vect
self.p1V = p1Vect如代码所示,numTrainNews是所有新闻的个数,trainMartix 是新闻进行分词,并数字化后的矩阵(先不用在意这里的数据结构,后面会介绍),其中的[i]代表是第几条新闻,classVector与trainMatrix相对应,它是这些新闻的正确分类(1或0,本例中,1代表食品安全新闻,0代表非食品安全新闻)。
当该新闻是食品安全新闻的时候,即classVector[1] == 1,把它所有词语的频数加到p1Num中, p1Num也是一个向量,保存了所有出现词语的频数。p1Sum是所有词语出现的次数总和。同理,当该新闻不是食品安全新闻的时候,也是使用同样的方式处理。
训练结束后,会得到两个总的概率向量,即p1V和p0V,这两个向量分别代表了每个词语在食品安全新闻和非食品安全新闻中出现的概率。
这里需要注意的是,我们最后对p1V和p0V取对数( np.log( ) )是为了在后续的分类中不会出现许多很小的数(试想一个词在训练集中只出现过1次,但是总词数却有几千个)相乘,这些很小的数相乘可能会导致最后结果被四舍五入为0。取对数能让y值从[0,1]被映射到[-∞, 0],从而避免出现相乘结果被四舍五入的情况。
分类
def classify_vector(self, vec2Classify):
"""
分类函数,对输入词向量分类
:param vec2Classify: 欲分类的词向量
"""
vec2Classify = vec2Classify[0]
p1 = sum(vec2Classify * self.p1V) + log(self.p1)
# 元素相乘
p0 = sum(vec2Classify * self.p0V) + log(1.0 - self.p1)
if p1 - p0 > 0:
return 1
else:
return 0vec2Classify 是需要分类的新闻进行分词操作后每个词语在总词表中出现的次数,没有出现的则为0,有出现的为1。以”江西公布食品抽检情况 样品总体合格率95.67%”为例,它分词后的结果是:[‘江西’, ‘公布’, ‘食品’, ‘抽检’, ‘情况’, ‘ ‘, ‘样品’, ‘总体’, ‘合格率’, ‘95.67%’],转换成向量则如下图所示:


其中,像“你们”、“水果”、“购物”这样的词语是不在这条新闻里的,但是它在训练集的其他新闻里,因此总表中会出现它,但是在该新闻的向量中,它会被标记为0. 代表没有出现。
这里还需要注意的是p1这个变量,这个变量叫作“先验概率”,在我们的例子中就是:“现实生活中,多少条新闻里出现一条食品安全新闻”,根据统计,这个数值大概是1/125, 但是我偏向于保守一点的值,因此将其固定设置为1/200. 请注意,我们这里是手动设置先验概率,在scikit-learn等机器学习框架中,他们会根据训练集自动得到这个值,最典型的就是 MultinomialNB 和 GaussianNB,在我们的例子中实际上提升不了多少准确率,因此在这里不讨论。
将当前的词向量和我们刚获得的词向量相乘后,对每个词语得到的值求和,再乘以先验概率就是我们在每个分类上的结果,若该新闻在食品安全的结果大于非食品安全,则被分类为食品安全新闻。
将上面的训练和分类转换成数学公式来进行讲解,那就是这样的:
A:我们需要测试的词语
B:来自食品安全相关新闻/不是来自食品安全相关新闻的概率。
判断一个单词分别归属两类的概率:


判断一篇新闻是否是食品安全相关的概率:

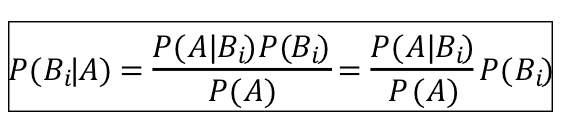
难怪数学家喜欢写公式,确实比文字简洁很多。
在下面开始讲预处理和模型之前,我需要先把我们的trainNB.py放在这里,好让大家在阅读的过程中回来翻阅,理解预处理和模型中得到的变量是用来干嘛的,以便更好地明白这些代码:
import bayes
from data_helpers import *
from sklearn.externals import joblib
posFile = "./data/train_food.txt"
negFile = "./data/train_notfood.txt"
print("正在获取训练矩阵及其分类向量")
trainList,classVec = loadTrainDataset(posFile,negFile)
print("正在将训练矩阵分词,并生成词表")
vectorized, vocabulary = jieba_cut_and_save_file(trainList,True)
bayes = bayes.oldNB(vocabulary)
# 初始化模型
print("正在训练模型")
bayes.train(vectorized,classVec)
# 训练
print("保存模型")
joblib.dump(bayes, "./arguments/train_model.m")预处理
讲完训练和测试,你基本上已经知道朴素贝叶斯的运作方式了,接下来我们讲一下如何进行预处理,并从文本中构建词向量和总词表。以下函数都位于GitHub库(见文章首行)的data_helpers.py文件中。
1. 读取训练集
首先从文件中读入我们的训练数据,在我上传的GitHub库(见文章首行)中,我们的训练数据被存在1.NaiveBayes/data/中。
def loadTrainDataset(posFile,negFile):
"""
便利函数,加载训练数据集
:param pos: 多少条食品安全相关新闻
:param neg: 多少条非食品安全相关新闻
"""
trainingList = [] # 训练集
classVec = [] # 分类向量
# 录入食品安全相关的训练集
posList = list(open(posFile, 'r').readlines())
posVec = [1] * len(posList)
trainingList += posList
classVec += posVec
# 录入非食品安全相关的训练集
negList = list(open(negFile, 'r').readlines())
negVec = [0] * len(negList)
trainingList += negList
classVec += negVec
return trainingList, classVec2.对新闻进行分词
我们需要对这些新闻进行分词,为了节省以后训练使用的时间,我们还要把分词的结果保存,同样地,这些结果会被保存到data中,名字为cleaned_trainMatrix.txt. 如下所示:
def jieba_cut_and_save_file(inputList, output_cleaned_file=False):
"""
1. 读取中文文件并分词句子
2. 可以将分词后的结果保存到文件
3. 如果已经存在经过分词的数据文件则直接加载
"""
output_file = os.path.join('./data/', 'cleaned_' + 'trainMatrix.txt')
if os.path.exists(output_file):
lines = list(open(output_file, 'r').readlines())
lines = [line.strip('\n').split(' ') for line in lines]
else:
lines = [list(jieba.cut(clean_str(line))) for line in inputList]
# 将句子进行clean_str处理后进行结巴分词
lines = [[word for word in line if word != ' '] for line in lines]
if output_cleaned_file:
with open(output_file, 'w') as f:
for line in lines:
f.write(" ".join(line) + '\n')
vocabulary = createVocabList(lines)
# 根据词典生成词向量化器,并进行词向量化
setOfWords2Vec = setOfWords2VecFactory(vocabulary)
vectorized = [setOfWords2Vec(news) for news in lines]
return vectorized, vocabulary
def clean_str(string):
"""
1. 将除汉字外的字符转为一个空格
2. 除去句子前后的空格字符
"""
string = re.sub(r'[^\u4e00-\u9fff]', ' ', string)
string = re.sub(r'\s{2,}', ' ', string)
return string.strip()下面介绍其中出现的createVocabList等函数。
3. 生成词典
还记得我们前面讲到的总词表吗,它记录了所有单词,它包含了所有新闻中出现的,但是不重复的词语。
def createVocabList(news_list):
"""
从分词后的新闻列表中构造词典
"""
# 创造一个包含所有新闻中出现的不重复词的列表。
vocabSet = set([])
for news in news_list:
vocabSet = vocabSet | set(news)
# |取并
return list(vocabSet)4.将分词后的新闻向量化
def setOfWords2VecFactory(vocabList):
"""
通过给定词典,构造该词典对应的setOfWords2Vec
"""
#优化:通过事先构造词语到索引的哈希表,加快转化
index_map = {}
for i, word in enumerate(vocabList):
index_map[word] = i
def setOfWords2Vec(news):
"""
以在构造时提供的词典为基准词典向量化一条新闻
"""
result = [0]*len(vocabList)
for word in news:
#通过默认值查询同时起到获得索引与判断有无的作用
index = index_map.get(word, None)
if index:
result[index] = 1
return result
return setOfWords2Vec5.最后是测试需要用到的向量化新闻
原理和前边对训练集的向量化相似,但是由于是测试时对单个新闻的向量化,因此我们把它分开了。
def vectorize_newslist(news_list, vocabulary):
"""
将新闻列表新闻向量化,变成词向量矩阵
注:如果没有词典,默认值为从集合中创造
"""
# 分词与过滤
cut_news_list = [list(jieba.cut(clean_str(news))) for news in news_list]
# 根据词典生成词向量化器,并进行词向量化
setOfWords2Vec = setOfWords2VecFactory(vocabulary)
vectorized = [setOfWords2Vec(news) for news in cut_news_list]
return vectorized, vocabulary贝叶斯模型(bayes.py)
为了方便保存模型,我们将模型视为一个类,类的初始化如下。
def __init__(self, vocabulary):
self.p1V = None
self.p0V = None
self.p1 = None
self.vocabulary = vocabulary其中,vocabulary是在运行完jieba_cut_and_save_file后获得的。在模型初始化的时候我们需要传入vocabulary,见前面的trainNB.py.
1.训练函数
在前面讲解训练的时候我曾经用到这里的一部分代码,下面是全部代码,其实要讲的都已经讲过了,一些细分方面的东西都已经写在注释中了。
def train(self, trainMatrix, classVector):
"""
训练函数
:param trainMatrix: 训练词向量矩阵
:param classVector: 分类向量
"""
numTrainNews = len(trainMatrix)
# 多少条新闻
numWords = len(trainMatrix[0])
# 训练集一共多少个词语
# pFood = sum(classVector) / float(numTrainNews)
# 新闻属于食品安全类的概率
pFood = float(1)/float(200)
p0Num = ones(numWords)
p1Num = ones(numWords)
p0Sum = 2.0
p1Sum = 2.0
# 以上初始化概率,避免有零的存在使后面乘积结果为0
# self.words_weight
for i in range(numTrainNews):
if classVector[i] == 1:
p1Num += trainMatrix[i]
# 每条食品安全新闻中,每个词的数量分布
p1Sum += sum(trainMatrix[i])
# 求每条新闻出现的食品安全集合中的词语的数量总合
else:
p0Num += trainMatrix[i]
p0Sum += sum(trainMatrix[i])
p1Vect = log(p1Num / p1Sum)
# 在1的情况下每个词语出现的概率
p0Vect = log(p0Num / p0Sum)
# 在0的情况下每个词语出现的概率
#保存结果
self.p0V = p0Vect
self.p1V = p1Vect
self.p1 = pFood
2. 分类新闻
测试新闻的时候我们需要用到以下两个函数,一个是用来将新闻词向量化,一个是用来将词向量进行最后的分类操作。
def classify_news(self, news):
"""
分类函数,对输入新闻进行处理,然后分类
:param vec2Classify: 欲分类的新闻
"""
vectorized, vocabulary = vectorize_newslist([news],self.vocabulary)
return self.classify_vector(vectorized)
def classify_vector(self, vec2Classify):
"""
分类函数,对输入词向量分类
:param vec2Classify: 欲分类的词向量
"""
vec2Classify = vec2Classify[0]
p1 = sum(vec2Classify * self.p1V) + log(self.p1)
# 元素相乘
p0 = sum(vec2Classify * self.p0V) + log(1.0 - self.p1)
if p1 - p0 > 0:
return 1
else:
return 0这样我们便完成了训练时所需要的所有函数,接下来尝试训练,在该文件夹中运行python trainNB.py. 训练并保存模型:


成功!接下来我们来测试这个模型:
import bayes
from data_helpers import *
from sklearn.externals import joblib
posFile = "./data/eval_food.txt"
negFile = "./data/eval_notfood.txt"
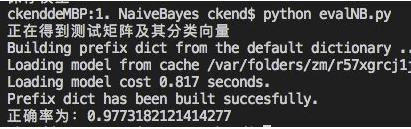
print("正在得到测试矩阵及其分类向量")
trainList,classVec = loadTrainDataset(posFile,negFile)
nb = joblib.load("arguments/train_model.m")
# 读取模型
results = []
for i in trainList:
result = nb.classify_news(i)
results.append(result)
# 测试模型
acc = 0.0
correct = 0
for i in range(len(classVec)):
if results[i] == classVec[i]:
correct += 1
acc = correct/len(classVec)
print("正确率为:"+str(acc))正确率为97.7%.

这只是第一篇教程,后续我们还有办法对食品安全新闻更加精确地进行分类,喜欢大家喜欢,有问题可以在评论区进行讨论。