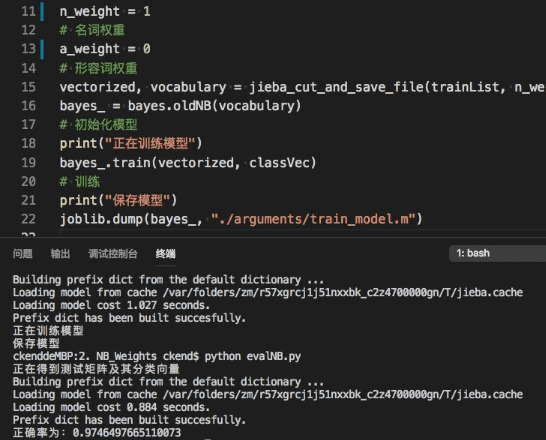
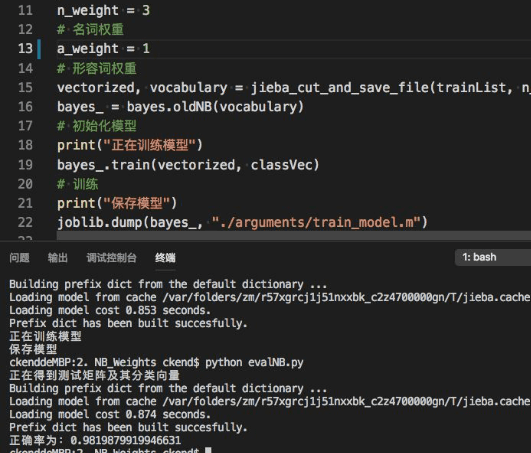
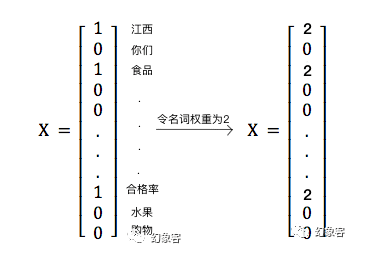
def jieba_cut_and_save_file(inputList, n_weight, a_weight, output_cleaned_file=False):
"""
1. 读取中文文件并分词句子
2. 可以将分词后的结果保存到文件
"""
output_file = os.path.join('./data/', 'cleaned_' + 'trainMatrix.txt')
lines = []
tags = []
for line in inputList:
result = pseg.cut(clean_str(line))
a = []
b = []
for word, flag in result:
# 对分词后的新闻
if word != ' ':
# 若非空
a.append(word)
if flag.find('n')==0:
# 若是名词
b.append(n_weight)
elif flag.find('a')==0:
# 若形容词
b.append(a_weight)
else:
b.append(1)
lines.append(a)
tags.append(b)
if output_cleaned_file:
with open(output_file, 'w') as f:
for line in lines:
f.write(" ".join(line) + '\n')
vocabulary = createVocabList(lines)
# 根据词典生成词向量化器,并进行词向量化
setOfWords2Vec = setOfWords2VecFactory(vocabulary)
vectorized = []
for i,news in enumerate(lines):
vector = setOfWords2Vec(news, tags[i])
vectorized.append(vector)
return vectorized, vocabulary
def jieba_cut_and_save_file(inputList, output_cleaned_file=False):
"""
1. 读取中文文件并分词句子
2. 可以将分词后的结果保存到文件
3. 如果已经存在经过分词的数据文件则直接加载
"""
output_file = os.path.join('./data/', 'cleaned_' + 'trainMatrix.txt')
if os.path.exists(output_file):
lines = list(open(output_file, 'r').readlines())
lines = [line.strip('\n').split(' ') for line in lines]
else:
lines = [list(jieba.cut(clean_str(line))) for line in inputList]
# 将句子进行clean_str处理后进行结巴分词
lines = [[word for word in line if word != ' '] for line in lines]
if output_cleaned_file:
with open(output_file, 'w') as f:
for line in lines:
f.write(" ".join(line) + '\n')
vocabulary = createVocabList(lines)
# 根据词典生成词向量化器,并进行词向量化
setOfWords2Vec = setOfWords2VecFactory(vocabulary)
vectorized = [setOfWords2Vec(news) for news in lines]
return vectorized, vocabulary
def clean_str(string):
"""
1. 将除汉字外的字符转为一个空格
2. 除去句子前后的空格字符
"""
string = re.sub(r'[^\u4e00-\u9fff]', ' ', string)
string = re.sub(r'\s{2,}', ' ', string)
return string.strip()
def setOfWords2VecFactory(vocabList):
"""
通过给定词典,构造该词典对应的setOfWords2Vec
"""
#优化:通过事先构造词语到索引的哈希表,加快转化
index_map = {}
for i, word in enumerate(vocabList):
index_map[word] = i
def setOfWords2Vec(news):
"""
以在构造时提供的词典为基准词典向量化一条新闻
"""
result = [0]*len(vocabList)
for word in news:
#通过默认值查询同时起到获得索引与判断有无的作用
index = index_map.get(word, None)
if index:
result[index] = 1
return result
return setOfWords2Vec
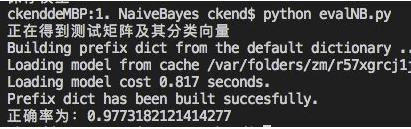
5.最后是测试需要用到的向量化新闻
原理和前边对训练集的向量化相似,但是由于是测试时对单个新闻的向量化,因此我们把它分开了。
def vectorize_newslist(news_list, vocabulary):
"""
将新闻列表新闻向量化,变成词向量矩阵
注:如果没有词典,默认值为从集合中创造
"""
# 分词与过滤
cut_news_list = [list(jieba.cut(clean_str(news))) for news in news_list]
# 根据词典生成词向量化器,并进行词向量化
setOfWords2Vec = setOfWords2VecFactory(vocabulary)
vectorized = [setOfWords2Vec(news) for news in cut_news_list]
return vectorized, vocabulary