

模型成品在极致安食网:https://jizhianshi.com, 木有太多时间维护。
这是本系列第二篇文章,位于源代码的 2. NB_Weights 中:
https://github.com/Ckend/NLP_DeepLearning_CN_Tutorial
前一篇文章中,我们学习了如何使用朴素贝叶斯自动分类食品安全新闻,准确率为97%,这一篇文章将教大家如何改进这个模型。阅读本篇文章之前,建议先阅读前一篇文章:[准确率:97%] 朴素贝叶斯自动分类食品安全新闻,否则有些概念可能无法理解。
在那篇文章中,在训练的时候,朴素贝叶斯模型中所有词语都是相同的权重,而事实上真的如此吗?我们怎么样才可以知道哪些词语更加重要呢?这时候,数理统计就派上用场了。
我们先对所有的食品安全新闻和非食品安全新闻使用结巴(jieba)分词, 然后统计各个词性在这分别在这两个类别中的数量,比如说名词的结果如下表(使用SPSS得到,其他词性就不一一展示了),显然食品安全新闻中名词的数量多于非食品安全新闻,这也是在人意料之中的结果,但是这并不代表着对于食品安全新闻,名词的重要性就大于其他的词性:

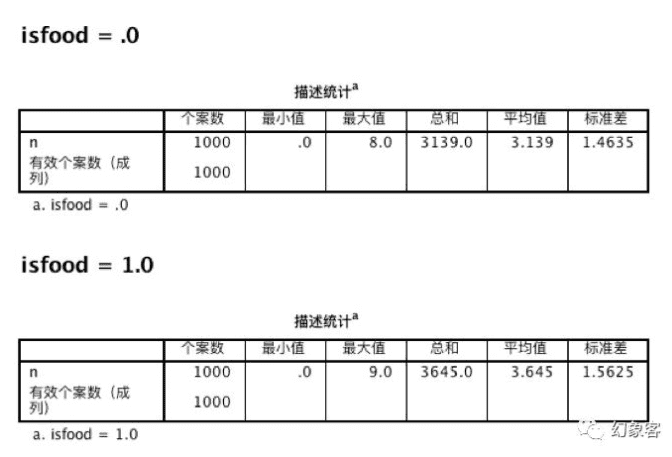
那么如何确定各个词性对分类的重要性呢?单纯根据频率和频数确定是比较复杂的,我们可以尝试使用我们的模型,比如说,先得到一个基准的准确值,然后尝试去除掉名词得到一个准确值,观察这两个准确值的差距,如果非常大,说明名词具有比较重要的地位。我们可以试一下:
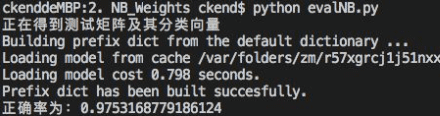
在所有词性权重都为1的情况下(基准)进行训练,准确率为:

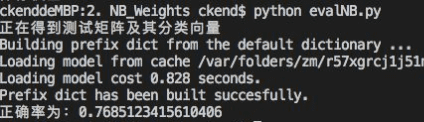
如果说,名词权重为0呢?

不过,没有对比是没有意义的,我们尝试令形容词权重为0,看看怎么样:

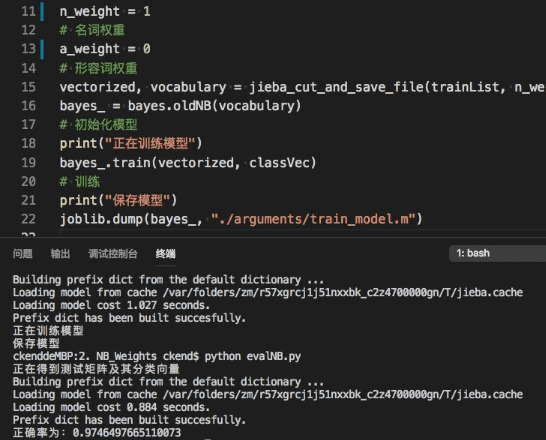
可以看到几乎没有影响,也就是说,对于我们的分类器而言,名词的重要性远远大于形容词。这样,我们可以尝试增加名词的权重,看看效果怎么样:

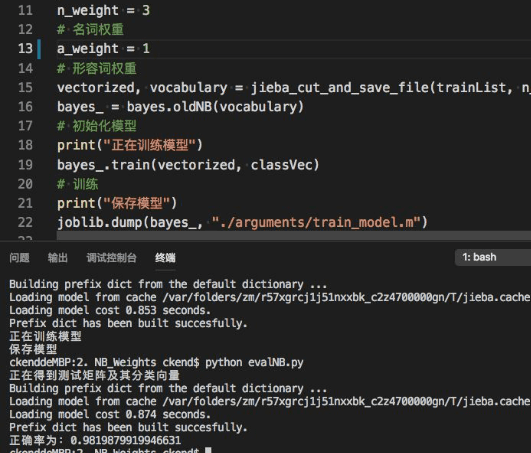
准确率 0.98,效果显著,不过我们很难确定最佳的权重,只能通过(玄学)调参来找到最合适的权重,你也可以尝试用神经网络来确定权重,虽然容易过拟合,但也是一种方法。不过既然用上了神经网络,就有更优秀的模型可以使用了,我们下次再介绍吧。
接下来讲一下这个权重的实现原理(要是不耐烦,可以直接看文章首行的源代码):基于前一篇文章,我们修改jieba_cut_and_save_file这个函数,这个函数在训练的时候用到了,它修改的就是训练时每个新闻被向量化而成的值,如下所示:

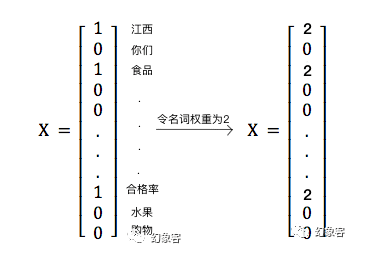
将该函数改成这样:
def jieba_cut_and_save_file(inputList, n_weight, a_weight, output_cleaned_file=False):
"""
1. 读取中文文件并分词句子
2. 可以将分词后的结果保存到文件
"""
output_file = os.path.join('./data/', 'cleaned_' + 'trainMatrix.txt')
lines = []
tags = []
for line in inputList:
result = pseg.cut(clean_str(line))
a = []
b = []
for word, flag in result:
# 对分词后的新闻
if word != ' ':
# 若非空
a.append(word)
if flag.find('n')==0:
# 若是名词
b.append(n_weight)
elif flag.find('a')==0:
# 若形容词
b.append(a_weight)
else:
b.append(1)
lines.append(a)
tags.append(b)
if output_cleaned_file:
with open(output_file, 'w') as f:
for line in lines:
f.write(" ".join(line) + '\n')
vocabulary = createVocabList(lines)
# 根据词典生成词向量化器,并进行词向量化
setOfWords2Vec = setOfWords2VecFactory(vocabulary)
vectorized = []
for i,news in enumerate(lines):
vector = setOfWords2Vec(news, tags[i])
vectorized.append(vector)
return vectorized, vocabulary最后,在主函数调用的时候传入你想需要的参数即可,你可以按照代码,修改任意词性权重,不过要注意结巴的词性表(每种词性的字母),你可以搜索“ictclas 词性表”得到。
import bayes
from data_helpers import *
from sklearn.externals import joblib
posFile = "./data/train_food.txt"
negFile = "./data/train_notfood.txt"
print("正在获取训练矩阵及其分类向量")
trainList,classVec = loadTrainDataset(posFile,negFile)
print("正在将训练矩阵分词,并生成词表")
n_weight = 3
# 名词权重
a_weight = 1
# 形容词权重
vectorized, vocabulary = jieba_cut_and_save_file(trainList, n_weight, a_weight, True)
bayes_ = bayes.oldNB(vocabulary)
# 初始化模型
print("正在训练模型")
bayes_.train(vectorized, classVec)
# 训练
print("保存模型")
joblib.dump(bayes_, "./arguments/train_model.m")最后总结一下,我们通过修改训练集新闻中不同词性的权重,加大名词权重,从而提高朴素贝叶斯模型的准确率到98%,不过,这个仅仅是在食品安全新闻这个例子中是这样,你如果想要应用到自己的程序上,应该先找到你的关键词性。下一篇文章我们将尝试一些新的模型元素。如果你喜欢的话,请继续关注幻象客。