

1.字典合并与更新运算符
在Python3.9以前,你可能需要这样合并字典:
d1 = {'name': 'revotu', 'age': 99}
d2 = {'age': 24, 'sex': 'male'}
# 方法1,使用两次update方法向字典中添加元素
d = {}
d.update(d1)
d.update(d2)
print(d)
# 方法2,先复制,后更新,缺点是增加了一个临时变量
d = d1.copy()
d.update(d2)
print(d)
# 方法3,字典构造器
d = dict(d1)
d.update(d2)
print(d)
# 方法4,关键字参数hack
# 只有一行代码,看上去很酷,缺点是这种hack技巧只有在字典的键是字符串时才有效。
d = dict(d1, **d2)
print(d)
# 方法5,字典推导式,字典推导式方法满足要求,只是嵌套的字典推导式,不那么清晰,不易于理解。
d = {k: v for d in [d1, d2] for k, v in d.items()}
print(d)
# 方法6,元素拼接
d = dict(list(d1.items()) + list(d2.items()))
print(d)
# 方法7,chain items
from itertools import chain
d = dict(chain(d1.items(), d2.items()))
print(d)
# 方法8,itemscollections.ChainMap可以将多个字典或映射,在逻辑上将它们合并为一个单独的映射结构
# 这种方法也很pythonic,而且也是通用方法
from collections import ChainMap
d = dict(ChainMap(d1, d2))
print(d)
# 方法9,字典拆分,在Python3.5+中,可以使用一种全新的字典合并方式,这行代码很pythonic
# 缺点是有点让人看不懂
d = {**d1, **d2}
print(d)现在,Python 3.9之后,合并 (|) 与更新 (|=) 运算符已被加入内置的 dict 类。 它们为现有的 dict.update 和 {**d1, **d2} 字典合并方法提供了补充。
>>> x = {"key1": "value1 from x", "key2": "value2 from x"}
>>> y = {"key2": "value2 from y", "key3": "value3 from y"}
>>> x | y
{'key1': 'value1 from x', 'key2': 'value2 from y', 'key3': 'value3 from y'}
>>> y | x
{'key2': 'value2 from x', 'key3': 'value3 from y', 'key1': 'value1 from x'}2.新增用于移除前缀和后缀的字符串方法
增加了 bytes, bytearray 以及 collections.UserString 的对应方法。
内置的str类将获得两个新方法,它们的源代码如下:
def removeprefix(self: str, prefix: str, /) -> str:
if self.startswith(prefix):
return self[len(prefix):]
else:
return self[:]
def removesuffix(self: str, suffix: str, /) -> str:
# suffix='' should not call self[:-0].
if suffix and self.endswith(suffix):
return self[:-len(suffix)]
else:
return self[:]它的使用方法如下:
>> "HelloWorld".removesuffix("World")
'Hello'
>> "HelloWorld".removeprefix("Hello")
'World'3.类型标注支持更多通用类型
在类型标注中现在你可以使用内置多项集类型例如 list 和 dict 作为通用类型而不必从 typing 导入对应的大写形式类型名 (例如 List 和 Dict)。
比如:
def greet_all(names: list[str]) -> None:
for name in names:
print("Hello", name)4.标准库新增 zoneinfo 模块
zoneinfo 模块为标准库引入了 IANA 时区数据库。 它添加了 zoneinfo.ZoneInfo,这是一个基于系统时区数据的实体 datetime.tzinfo 实现。
>>> from zoneinfo import ZoneInfo
>>> from datetime import datetime, timedelta
>>> # 夏时制 - 07:00
>>> dt = datetime(2020, 10, 31, 12, tzinfo=ZoneInfo("America/Los_Angeles"))
>>> print(dt)
2020-10-31 12:00:00-07:00
>>> dt.tzname()
'PDT'
>>> # 加7天,夏时制结束 - 08:00
>>> dt += timedelta(days=7)
>>> print(dt)
2020-11-07 12:00:00-08:00
>>> print(dt.tzname())
PST5.标准库新增 graphlib 模块
支持针对图的操作,比如获取拓扑排序:
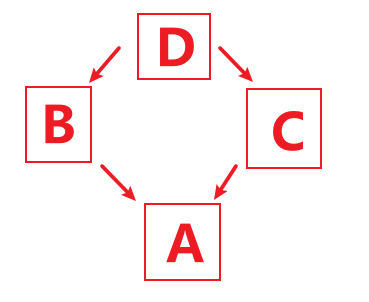
>>> from graphlib import TopologicalSorter
>>> graph = {"D": {"B", "C"}, "C": {"A"}, "B": {"A"}}
>>> ts = TopologicalSorter(graph)
>>> tuple(ts.static_order())
('A', 'C', 'B', 'D')更多可见:https://docs.python.org/zh-cn/3/library/graphlib.html#module-graphlib
6.Math模块迎来调整
以前gcd计算最大公因数的函数只能应用于2个数字,这就很蛋疼,我们必须使用 math.gcd(80, math.gcd(64, 152))来处理大于2个数字的情况。而现在 gcd 允许计算任意数量的数字:
import math # Greatest common divisor math.gcd(80, 64, 152) # 8
并新增了一个函数,计算最小公倍数:
# 最小公倍数 math.lcm(4, 8, 5) # 40
用法与gcd一样,它允许可变数量的参数。
7.os模块
以前Windows系统下是无法使用 os.unsetenv 的,这个问题在Python3.9已被修复。现在Windows系统也支持 os.unsetenv 了:
def __init__(self, *args, **kw):
if hasattr(os, 'unsetenv'):
os.unsetenv('_MEIPASS2')
else:
os.putenv('_MEIPASS2', '')8.random模块: 新增随机字节串
现在你可以使用random下的randbytes函数随机生成字节:
>> from random import randbytes >> randbytes(4) b'\xf3\xf5\xf8\x98'
9.性能优化
重点优化:
1.多个 Python 内置类型 (range, tuple, set, frozenset, list, dict) 现在通过使用 PEP 590 向量调用协议得到加速。
2.优化了在推导式中为临时变量赋值的惯用方式。 现在推导式中的 for y in [expr] 会与简单赋值语句 y = expr 一样快速。 例如:
sums = [s for s in [0] for x in data for s in [s + x]]
不同于 := 运算符,这个惯用方式不会使变量泄露到外部作用域中。
3.优化了多线程应用的信号处理。 如果一个线程不是获得信号的主线程,字节码求值循环不会在每条字节码指令上被打断以检查无法被处理的挂起信号。 只有主解释器的主线程能够处理信号。
以下是对从 Python 3.4 到 Python 3.9 的性能提升情况的总结:
Python version 3.4 3.5 3.6 3.7 3.8 3.9
-------------- --- --- --- --- --- ---
Variable and attribute read access:
read_local 7.1 7.1 5.4 5.1 3.9 3.9
read_nonlocal 7.1 8.1 5.8 5.4 4.4 4.5
read_global 15.5 19.0 14.3 13.6 7.6 7.8
read_builtin 21.1 21.6 18.5 19.0 7.5 7.8
read_classvar_from_class 25.6 26.5 20.7 19.5 18.4 17.9
read_classvar_from_instance 22.8 23.5 18.8 17.1 16.4 16.9
read_instancevar 32.4 33.1 28.0 26.3 25.4 25.3
read_instancevar_slots 27.8 31.3 20.8 20.8 20.2 20.5
read_namedtuple 73.8 57.5 45.0 46.8 18.4 18.7
read_boundmethod 37.6 37.9 29.6 26.9 27.7 41.1
Variable and attribute write access:
write_local 8.7 9.3 5.5 5.3 4.3 4.3
write_nonlocal 10.5 11.1 5.6 5.5 4.7 4.8
write_global 19.7 21.2 18.0 18.0 15.8 16.7
write_classvar 92.9 96.0 104.6 102.1 39.2 39.8
write_instancevar 44.6 45.8 40.0 38.9 35.5 37.4
write_instancevar_slots 35.6 36.1 27.3 26.6 25.7 25.8
Data structure read access:
read_list 24.2 24.5 20.8 20.8 19.0 19.5
read_deque 24.7 25.5 20.2 20.6 19.8 20.2
read_dict 24.3 25.7 22.3 23.0 21.0 22.4
read_strdict 22.6 24.3 19.5 21.2 18.9 21.5
Data structure write access:
write_list 27.1 28.5 22.5 21.6 20.0 20.0
write_deque 28.7 30.1 22.7 21.8 23.5 21.7
write_dict 31.4 33.3 29.3 29.2 24.7 25.4
write_strdict 28.4 29.9 27.5 25.2 23.1 24.5
Stack (or queue) operations:
list_append_pop 93.4 112.7 75.4 74.2 50.8 50.6
deque_append_pop 43.5 57.0 49.4 49.2 42.5 44.2
deque_append_popleft 43.7 57.3 49.7 49.7 42.8 46.4
Timing loop:
loop_overhead 0.5 0.6 0.4 0.3 0.3 0.3 可以看到,Python 3.9 相比于 Python 3.6 提升还是非常明显的,比如在列表的append 和 pop 操作上,性能提升了30%、在全局变量的读取上,性能提高了45%。
如果你的项目比较小型,升级到Python3.9的成本问题和依赖问题不多,还是非常推荐升级的。
10.未来可期
这一个更改你可能看不见、摸不着,但它可能改变Python的未来。
以前Python使用 LL(1) 解析器,从Python 3.9 开始,将使用 PEG 解析器,官方认为,PEG 在设计新语言特性时的形式化比 LL(1) 更灵活。
因此,请期待Python 3.10,Python团队或许能给我们带来更多的惊喜!
我们的文章到此就结束啦,如果你喜欢今天的 Python 教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 ( pythondict.com )
不只是一个宝典
欢迎关注公众号:Python实用宝典

评论(0)