
Python中有很多方法计算相关性,scipy中有自带的分析工具,pandas里也有非常方便的多变量相关性分析。我们今天就讲讲这两个工具的用法。
1.数据收集
本文北上广深的数据采集自东方财富网,以二手房价格指数为例:
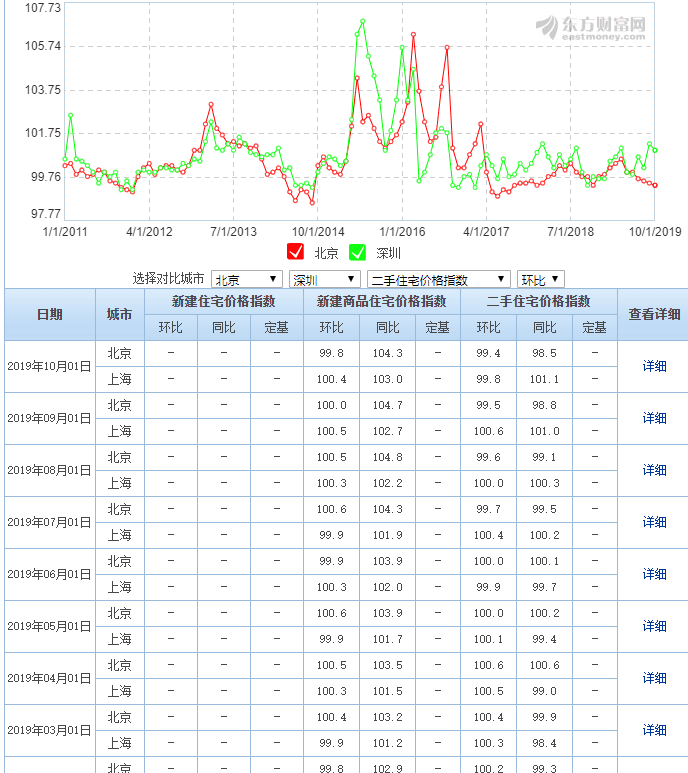
数据从2011年1月1日开始,每个数据点是当时一个月的价格指数,采集方法是用开发者工具找到请求发回来的JSON数据,方法如下:
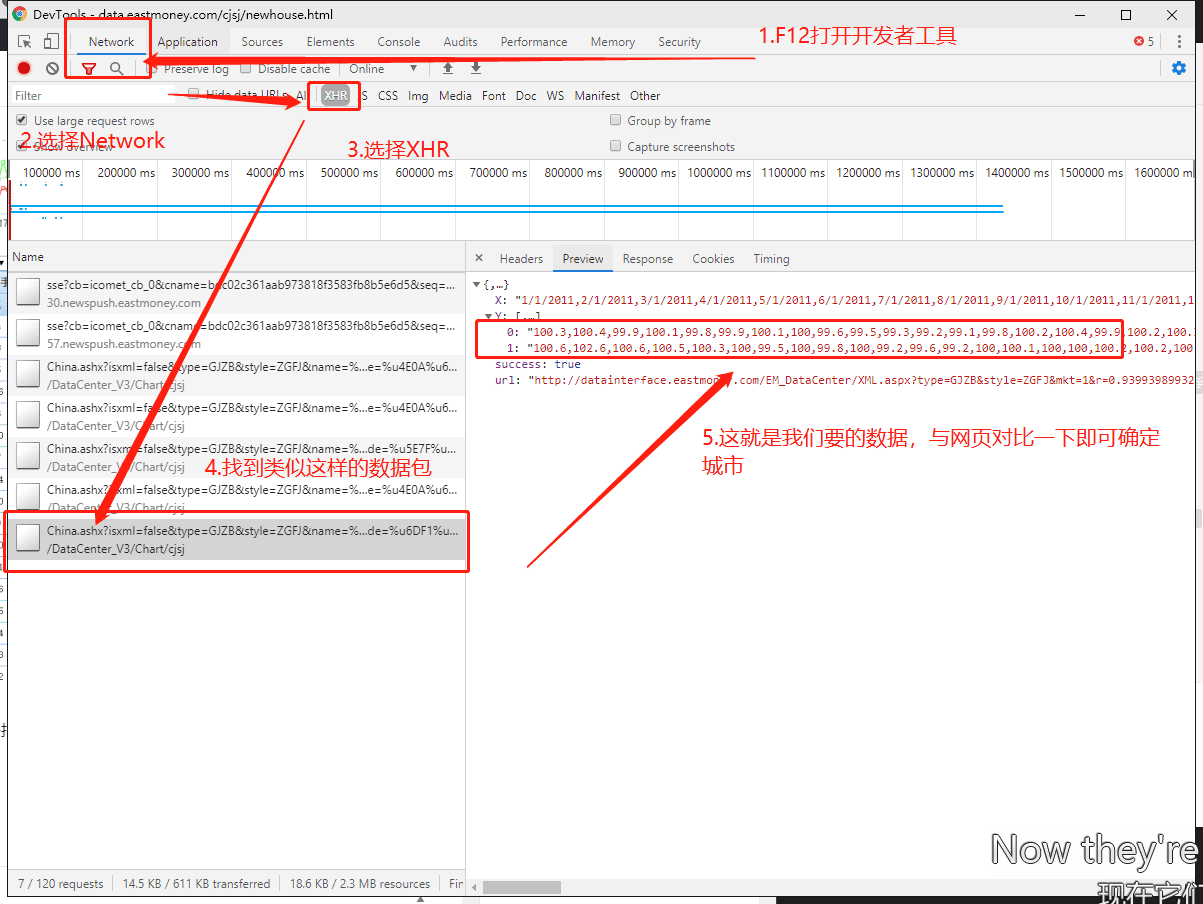
数据如下(2011/1/1-2019/10/1):
# 北京:
bj = [100.3,100.4,99.9,100.1,99.8,99.9,100.1,100,99.6,99.5,99.3,99.2,99.1,99.8,100.2,100.4,99.9,100.2,100.3,100.3,100.1,100,100.3,101,101,102.2,103.1,102,101.7,101.3,101.4,101.2,101.3,101.1,101.2,100.6,99.9,100,100.2,99.8,99.1,98.7,99.2,99.1,98.6,100.3,100.7,100.2,100,99.9,100.5,102.1,104.3,102.3,102.6,102,101.4,101.1,101.4,101.7,102.3,103.2,106.3,103.7,102.3,101.4,101.6,103.9,105.7,101.1,100.2,100.2,100.8,101.3,102.2,100,99.1,98.9,99.2,99.1,99.4,99.5,99.5,99.6,99.4,99.5,99.8,99.9,100.3,100.1,100.4,100,99.8,99.8,99.4,99.8,99.9,100.2,100.4,100.6,100,100,99.7,99.6,99.5,99.4]
# 广州:
gz = [101.2,100.6,99.5,101,99.8,100.1,100.2,100.7,100.6,99.5,99.2,99.6,99.6,99.6,99.8,99.6,99.9,100.5,100.7,100.9,100.6,100.4,100.5,100.5,100.4,101.7,101.5,100.7,101.1,100.9,101,101,100.4,101,101.2,100.6,101,100.3,100.2,100.7,100.1,99.7,98.9,98.6,98.7,100,100,100.2,99.8,99.7,100,101.1,102.3,101.8,101.3,101,101.2,101.1,100.7,101,101.3,101.2,103.5,102.6,101.9,101.6,101.4,102.8,103.3,101.6,100.8,101.3,101.6,102.7,103.3,101,100.5,100.8,100.1,100,100.2,99.7,100.1,99.6,99.9,100.2,100.2,100.5,101,100.3,100.3,100.6,100.2,99.8,99.7,99.6,99.7,99.8,99.5,99.6,99.7,100,100.4,100,99.7,99.9]
# 上海: sh = [100.5,100.4,100.4,100.6,100.2,100.2,100.3,100.1,100.1,99.8,99.5,99.6,99.3,99.7,99.5,100.1,100.3,100.2,100.2,100.3,100.2,100.2,100.2,100.4,100.8,101.6,102.6,101.3,100.9,101.1,100.8,100.8,101,100.9,100.7,100.5,100.1,100.6,100.2,100,99.8,99.3,99.1,99.3,99.2,100,100,100.4,100.3,100.1,100,100.6,102.2,101.2,101.6,101.1,101,100.8,101,101.2,102.7,105.3,106.2,102.5,101.4,102.2,102,103.7,103.4,100.3,99.8,99.5,99.6,100.2,100.7,100.8,100,99.9,99.6,99.8,99.9,100.3,99.7,99.9,100.1,99.6,99.4,99.8,99.7,99.7,99.9,99.9,99.8,99.8,99.9,99.7,100,99.9,100.3,100.5,100.1,99.9,100.4,100,100.6,99.8]
# 深圳: sz = [100.6,102.6,100.6,100.5,100.3,100,99.5,100,99.8,100,99.2,99.6,99.2,100,100.1,100,100,100.2,100.2,100.1,100.1,100.4,100.3,100.6,100.5,101.4,102.3,101.1,101,101.3,101,101.6,101.3,100.9,100.8,100.7,100.8,100.8,101.1,100.1,100.2,99.4,99.4,99.5,99.3,100,100.4,100.7,100.6,100.3,100.5,102.4,106.3,106.9,105.3,104.4,103.3,101,101.9,103.3,105.7,103.3,104.7,99.6,100,100.8,101.8,102,101.8,99.4,99.3,99.8,99.9,99.3,100.3,100.8,100.3,99.7,100.6,99.8,99.9,100.4,100.1,100.4,100.9,101.3,100.7,100.2,100.8,100.3,100.6,101.1,100,99.4,99.8,99.7,99.7,100.5,100.7,101.1,100,99.9,100.7,100.2,101.3,101]
2.准备工作
首先,你要确保你的电脑安装了Python,如果没有可以看这篇文章:超详细安装Python指南。
然后,打开CMD(开始-运行-cmd),或者Terminal(macOS) 输入以下指令安装scipy和pandas.
pip install scipy pip install pandas
3.编写代码
3.1 scipy计算相关性
scipy计算相关性其实非常简单,引入包的stats模块:
import scipy.stats as stats
然后调用函数进行计算:
# 计算广州和深圳二手房价格指数相关性 print(stats.pearsonr(gz, sz))
结果如下:
F:\push\20191130>python 1.py (0.4673289851643741, 4.4100775485723706e-07)
什么?!!广州和深圳的二手房价格指数相关性竟然才0.46?那其他一线城市和深圳对比呢?
不过,stats麻烦的地方就在于,它一次只能对比两个值,不能一次性两两对比四个一线城市,不过,有个模块可以。
3.2 pandas一次性两两对比计算相关性
首先引入pandas:
import pandas as pd
创建DataFrame存放四个数据:
df = pd.DataFrame() df['北京'] = bj df['上海'] = sh df['广州'] = gz df['深圳'] = sz
最后相关性计算:
print(df.corr())
来看看结果:
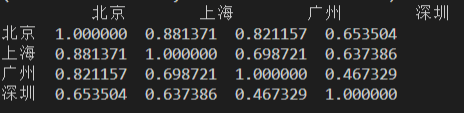
wow,看来深圳的二手房价还真是与众不同,不过从下面这个图看,确实,深圳的二手房价格和北京的二手房价格已经出现了背离的情况。
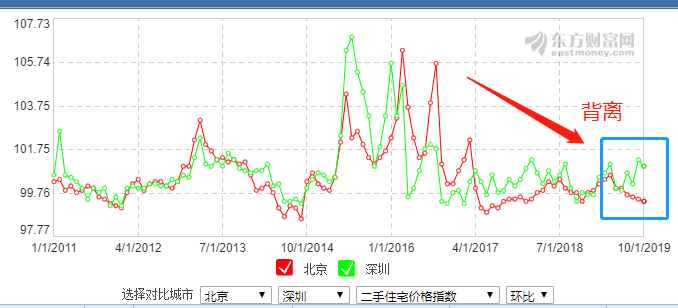
个人认为,这个背离和最近的一系列政策及香港局势有关,但当前严峻的金融形势下,不会持续太久。
我们的文章到此就结束啦,如果你希望我们今天的Python 教程,请持续关注我们,如果对你有帮助,麻烦在下面点一个赞/在看哦![]() 有任何问题都可以在下方留言区留言,我们都会耐心解答的!
有任何问题都可以在下方留言区留言,我们都会耐心解答的!
Python实用宝典 (pythondict.com)
不只是一个宝典
欢迎关注公众号:Python实用宝典

声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。
评论(0)