
Sweetviz是一个开源Python库,它只需三行代码就可以生成漂亮的高精度可视化效果来启动EDA(探索性数据分析)。输出一个HTML。
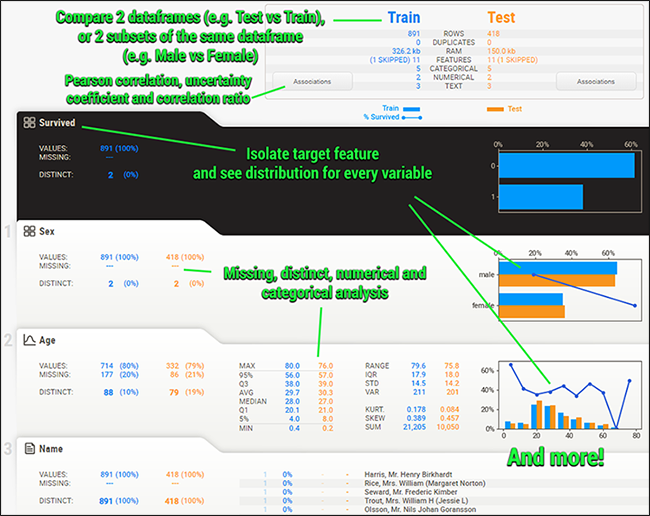
如上图所示,它不仅能根据性别、年龄等不同栏目纵向分析数据,还能对每个栏目做众数、最大值、最小值等横向对比。
所有输入的数值、文本信息都会被自动检测,并进行数据分析、可视化和对比,最后自动帮你进行总结,是一个探索性数据分析的好帮手。
1.准备
开始之前,你要确保Python和pip已经成功安装在电脑上,如果没有,请访问这篇文章:超详细Python安装指南 进行安装。
(可选1) 如果你用Python的目的是数据分析,可以直接安装Anaconda:Python数据分析与挖掘好帮手—Anaconda,它内置了Python和pip.
(可选2) 此外,推荐大家用VSCode编辑器来编写小型Python项目:Python 编程的最好搭档—VSCode 详细指南
Windows环境下打开Cmd(开始—运行—CMD),苹果系统环境下请打开Terminal(command+空格输入Terminal),输入命令安装依赖:
pip install sweetviz
2.sweetviz 基本用法
sweetviz 使用的原理是,使用一行代码,生成一个数据报告的对象(其中,my_dataframe是pandas中的DataFrame,一种表格型数据结构):
import pandas as pd
import sweetviz as sv
# 读取数据
my_dataframe = pd.read_csv('../ImpartData/iris.csv')
# 分析数据
my_report = sv.analyze(my_dataframe)
# 生成报告
my_report.show_html()执行完成后,会在当前文件夹下生成一个HTML的报告文件

双击这个html,你就能看到精美的分析报告了:
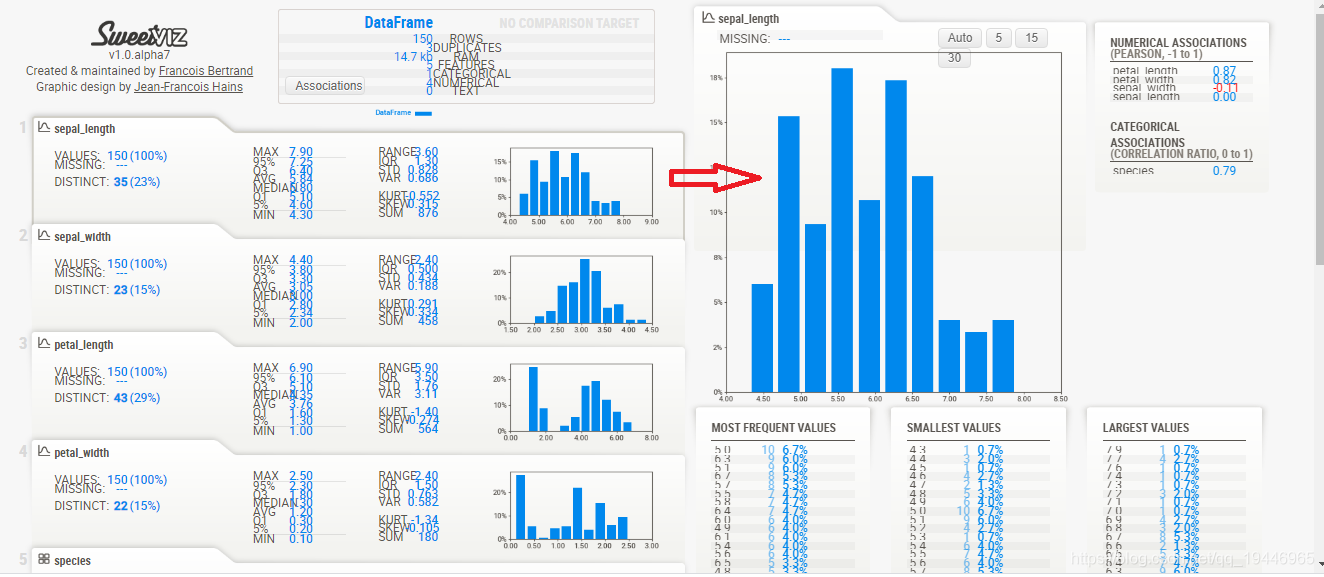
其中,分析数据有三种函数可以用,除了上面提到的analyze函数,还有 compare 和 compare_intra 函数。
首先是analyze函数:
analyze(source: Union[pd.DataFrame, Tuple[pd.DataFrame, str]],
target_feat: str = None,
feat_cfg: FeatureConfig = None,
pairwise_analysis: str = 'auto')可见其有以下4个参数可以配置:
- source:以pandas中的DataFrame数据结构作为分析对象。
- target_feat:需要被标记为目标对象的字符串。
- feat_cfg:需要被跳过、或是需要被强制转换为某种数据类型的特征。
- pairwise_analysis:相关性分析可能需要花费较长时间。如果超过了你的忍受范围,就需要设置这个参数为on或者off,以判断是否需要分析数据相关性。
compare()丨两个数据集比较
my_report = sv.compare([my_dataframe, "Training Data"], [test_df, "Test Data"], "Survived", feature_config)
要比较两个数据集,只需使用该 compare() 函数。它的参数与 analyze() 相同,只是插入了第二个参数来覆盖比较数据帧。建议使用 [dataframe, “name”] 参数格式以更好地区分基础数据帧和比较数据帧。(例如 [my_df, "Train"] 比 my_df 更好)
compare_intra()丨数据集栏目比较
my_report = sv.compare_intra(my_dataframe, my_dataframe["Sex"] == "male", ["Male", "Female"], feature_config)
想要对数据集中某个栏目下的参数进行分析,就采用这个函数进行。
例如,如果需要比较“性别”栏目下的“男性”和“女性”,就可以采用这个函数。
3.调整报告布局
一旦你创建了你的报告对象,只需将它传递给两个show函数中的一个:
1. show_html():
show_html( filepath='SWEETVIZ_REPORT.html',
open_browser=True,
layout='widescreen',
scale=None)show_html(…)将在当前文件路径中创建并保存 HTML 报告。有以下参数:
- layout (布局):无论是
'widescreen'或'vertical'。当鼠标移过每个功能时,宽屏布局会在屏幕右侧显示详细信息。新的(从 2.0 开始)垂直布局在水平方向上更加紧凑,并且可以在单击时扩展每个细节区域。 - scale:使用浮点数(
scale= 0.8或None)来缩放整个报告。 - open_browser:启用 Web 浏览器的自动打开以显示报告。如果不需要,可以在此处禁用它。
2.show_notebook():
show_notebook( w=None,
h=None,
scale=None,
layout='widescreen',
filepath=None)它将嵌入一个 IFRAME 元素,在notebook中显示报告(例如 Jupyter、Google Colab 等)。
请注意,由于Notebook通常是一个更受限制的环境,因此使用自定义宽度/高度/比例值 ( w, h, scale) 可能是个好主意。选项是:
- w(宽度):设置报告输出窗口的宽度。可以是百分比字符串 (
w="100%") 或像素 (w=900)。 - h(高度):设置报告输出窗口的高度。可以是像素数 (
h=700) 或将窗口拉伸到与所有特征 (h="Full")一样高。 - scale:与上面的 show_html 相同。
- layout:与上面的 show_html 相同。
- scale:与上面的 show_html 相同。
- filepath:可选的输出 HTML 报告。
我们的文章到此就结束啦,如果你喜欢今天的 Python 教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 ( pythondict.com )
不只是一个宝典
欢迎关注公众号:Python实用宝典

评论(0)