
本文讲解了列表和字典转化为pandas的列的多种方法及实战例子和教程。
1.问题来源
源于林胖发出的一道基础题:

2.解法
2.1 基础解法explode函数
这道题最简单的解法,相信大部分用过pandas的朋友都会,林胖也马上发出了自己的答案:
import pandas as pd
mydict = {'A': [1], 'B': [2, 3], 'C': [4, 5, 6]}
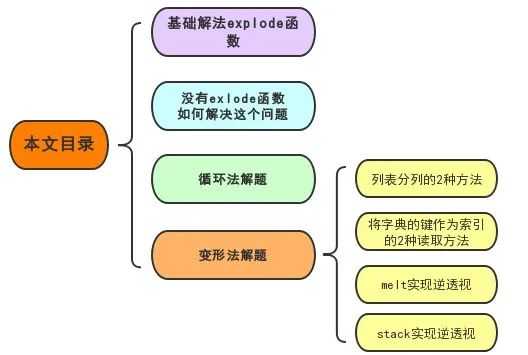
pd.DataFrame(mydict.items()).explode(1)结果:
详解
mydict.items()是python基础字典的内容,它返回了这个字典键值对组成的元组列表:
mydict.items()
返回:
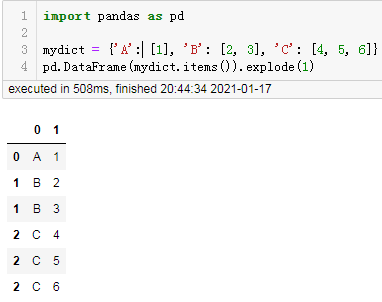
dict_items([('A', [1]), ('B', [2, 3]), ('C', [4, 5, 6])])将这个内部是元组的可迭代对象传入DataFrame的构造函数中:
pd.DataFrame(mydict.items())
返回结果:
这是pandas最基础的开篇知识点使用可迭代对象构造DataFrame,列表的每个元素都是整个DataFrame对应的一行,而这个元素内部迭代出来的每个元素将构成DataFrame的某一列。
然后再看看这个explode函数,它是pandas 0.25版本才出现的函数,只有一个参数可以传入列名,然后该函数就可以把该列的列表每个元素扩展到多行上。
效果与hive使用lateral view+explode实现的效果几乎一致,类似于:
select a,b_i from df lateral view explode(b) tmp as b_i;
可以参考很早之前的一篇文章:https://blog.csdn.net/as604049322/article/details/105985770
2.2 没有exlode函数如何解决这个问题
但是,黄佬说版本太低没有这个函数,于是我给群友们出了一道题:
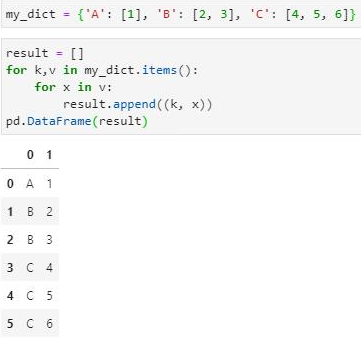
在黄佬的邀请下,一位经过我多次辅导的群友率先使用了循环法解题:
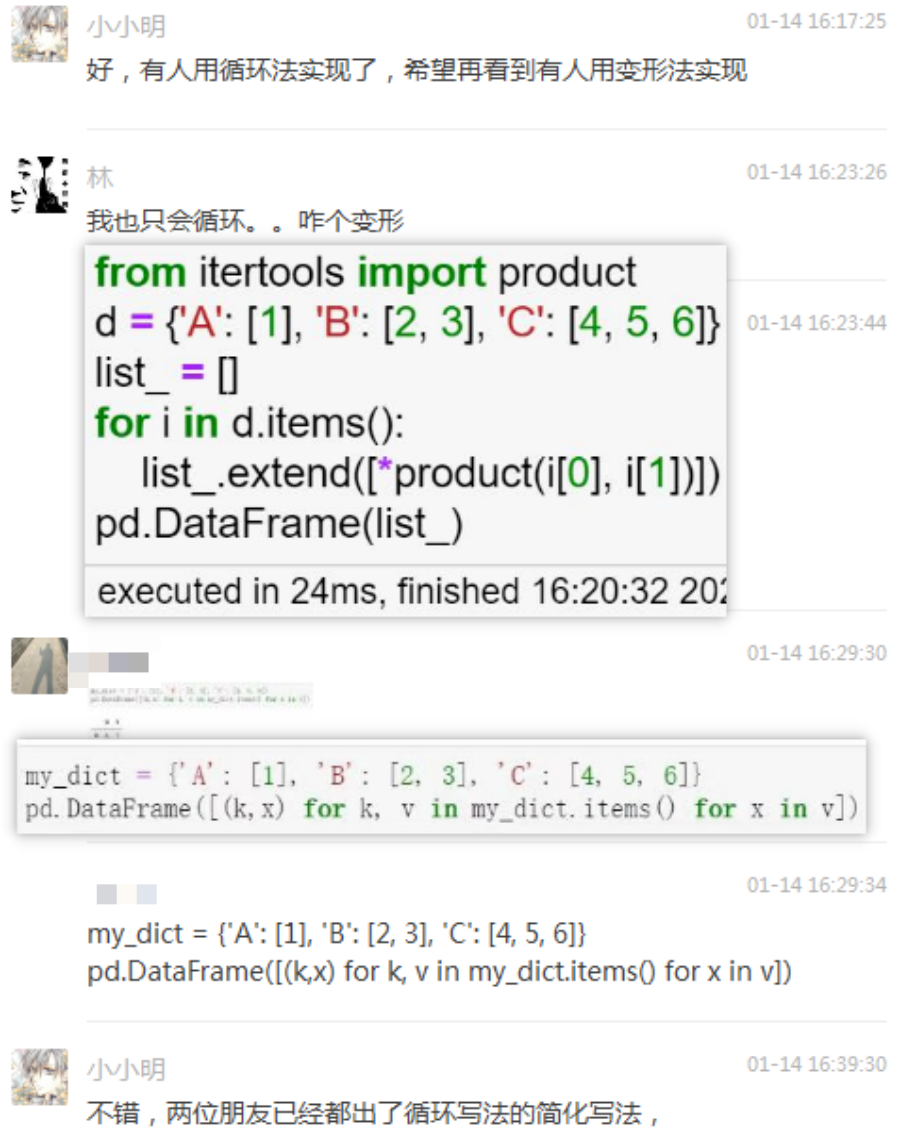
我觉得非常棒,但我也希望看到有人再用变形法实现一次。林胖和一位群友再次给出了简化版本的循环解法:
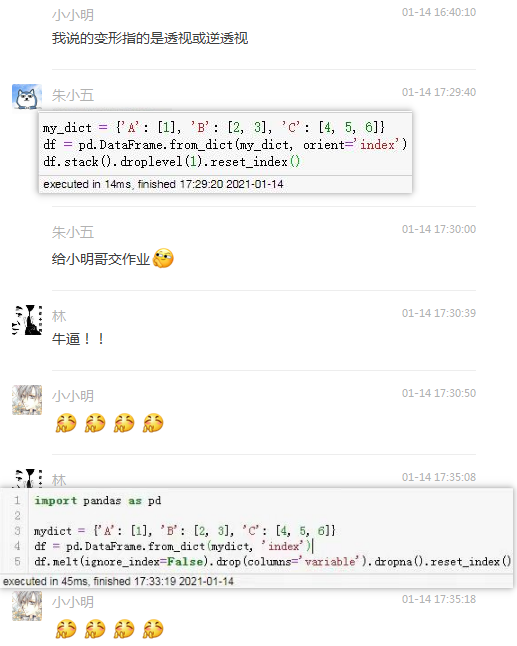
经过一番提示后,小五哥和林胖终于给出了变形法的解法:
非常不错,群友们终于独立的多思路解决了这个问题,真的要撒花呀!!!
下面我们详细分析一下,循环法和变形法的解法吧:
2.3 循环法解题
基本写法:
result = [] for k, vs in mydict.items(): for v in vs: result.append((k, v)) pd.DataFrame(result)
本质上就是实现了一个笛卡尔积的拉平操作,将mydict.items这个可迭代对象的元组构造笛卡尔积并按照整体拉平。
上面的基本写法,应该99%以上的朋友都能看懂,但 林胖 的循环简化解法:
import itertools result = [] for k, v in mydict.items(): result.extend(itertools.product(k, v)) pd.DataFrame(result)
部分朋友可能没有看明白,这个就需要查询一下product方法的官方文档(https://docs.python.org/zh-cn/3.7/library/itertools.html?highlight=product#itertools.product):
product(*iterables, repeat=1) --> product object
参数:
- iterables 为可迭代对象
- 可选参数repeat 表示重复次数
用于生成可迭代对象输入的笛卡儿积,相当于生成器表达式中的嵌套循环。
例如:product(A, B) 中的元素A和B将共同构成可迭代元素[A, B]作为iterables传入和 ((x,y) for x in A for y in B) 返回结果一样。
返回示例:
- product(‘ab’, range(3)) –> (‘a’,0) (‘a’,1) (‘a’,2) (‘b’,0) (‘b’,1) (‘b’,2)
- product((0,1), (0,1), (0,1)) –> (0,0,0) (0,0,1) (0,1,0) (0,1,1) (1,0,0) …
也可以传入可选参数 repeat 表示重复的次数:例如,product(A, repeat=4) 和 product(A, A, A, A) 的返回结果是一样的。
列表的extend方法是将可迭代对象的每个元素都添加到列表中,而append方法只能添加单个元素。
当然,我们还可以将整个for循环改写成列表生成式:
result = [(k, v) for k, vs in mydict.items() for v in vs] pd.DataFrame(result)
也可以简化代码量。
2.4 变形法解题
df = pd.DataFrame(mydict.items(), columns=["a", "b"]) df
实现思路,上面的界面是下面最左边:
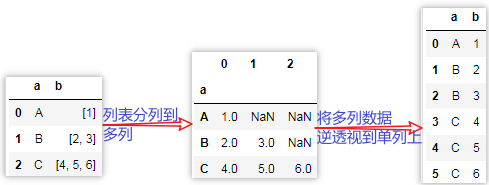
2.4.1 列表分列的2种方法
列表分列的思路:Pandas的Series对象调用apply方法单个元素返回的结果是Series时,这个Series的每个数据会作为Datafrem的每一列,索引会作为列名。
对Series进行列表分列
例如:
df["b"].apply(pd.Series)
结果:
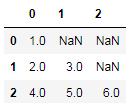
不过这样会丢失原本的”a”列,我们可以先将”a”列设置为索引,再进行Series分列操作:
df.set_index("a")["b"].apply(pd.Series)或者把结果设置成原本的”a”列为索引:
df["b"].apply(pd.Series).set_index(df["a"])
结果均为上述实现思路的第二步。
直接对Datafream进行列表分列
如果我们希望直接使用Datafream实现分列可以借助agg方法,因为agg方法是对每一列的Series对象操作:
df.agg({"a": lambda x: x, "b": pd.Series})结果:
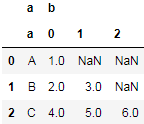
但这操作导致列多了一个级别,需要删除:
df.agg({"a": lambda x: x, "b": pd.Series}).droplevel(0, axis=1)结果:
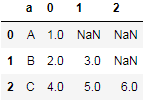
只要再执行set_index("a"):
df.agg({"a": lambda x: x, "b": pd.Series}).droplevel(0, axis=1).set_index("a")结果就会与实现思路的第二步结果一致。
2.4.2 将字典的键作为索引的2种读取方法
当然上面我只是为了给大家讲述分列的一些方法。对于这个例子,其实我们可以直接通过pd.DataFrame.from_dict方法orient参数传入’index’,直接获得第二步的结果(只是索引没有名称):
df = pd.DataFrame.from_dict(mydict, 'index')
或者分别传入data和索引index:
df = pd.DataFrame(data=mydict.values(), index=mydict.keys())
都能得到以下结果:
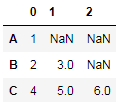
2.4.3 melt实现逆透视
说起逆透视我个人首先想到了melt方法,然后才想到melt方法实现的本质用到了stack方法。
为了避免索引丢失,我们首先还原索引为普通的列:
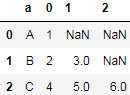
df = df.rename_axis(index="a").reset_index() df
结果:
然后使用melt方法进行逆透视:
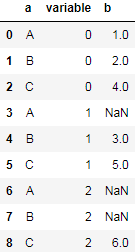
df.melt(id_vars='a', value_name='b')
结果:
然后删除第二列,再删除空值行,再将数值列转换为整数类型就搞定。
最终代码:
df = pd.DataFrame.from_dict(mydict, 'index')
df = df.melt(id_vars='a', value_name='b').drop(columns="variable").dropna()
df.b = df.b.astype("int")
df成功得到结果:

2.4.4 stack实现逆透视
df = pd.DataFrame.from_dict(mydict, 'index') df.stack()
结果:
A 0 1.0 B 0 2.0 1 3.0 C 0 4.0 1 5.0 2 6.0 dtype: float64
结果返回了一个多级索引的Series,我们首先需要删除索引中多余的部分:
df.stack().droplevel(1)
结果:
A 1.0 B 2.0 B 3.0 C 4.0 C 5.0 C 6.0 dtype: float64
此时我们再还原索引到普通列:
df.stack().droplevel(1).reset_index()
再重新设置一下列名:
df.stack().droplevel(1).reset_index().set_axis(["a", "b"], axis=1)
最后重设一下B列的类型:
df.b = df.b.astype("int")最终代码:
df = pd.DataFrame.from_dict(mydict, 'index')
df = df.stack().droplevel(1).reset_index().set_axis(["a", "b"], axis=1)
df.b = df.b.astype("int")
df结果:

2.实际应用
这次我将分享三个实际案例,让大家看看列表分列的一些实际应用。
首先,我们先导包并设置Pandas显示参数:
import pandas as pd
pd.set_option("display.max_colwidth", 100)
正则提取并分列
需求:
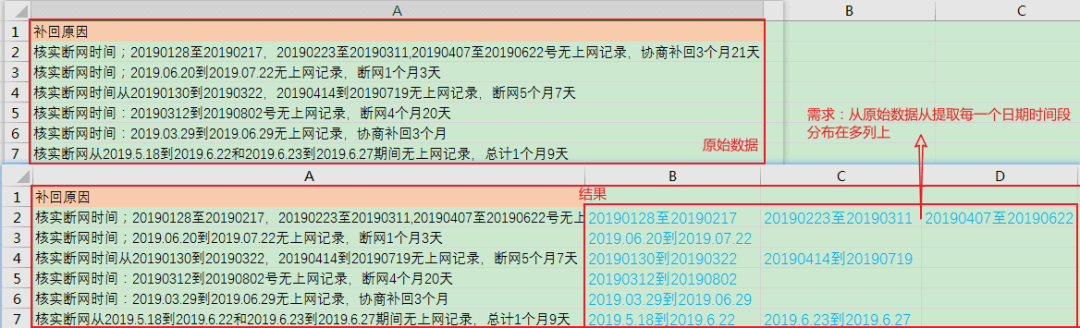
读取数据:
df = pd.read_excel("正则提取与分列.xlsm", usecols=[0])
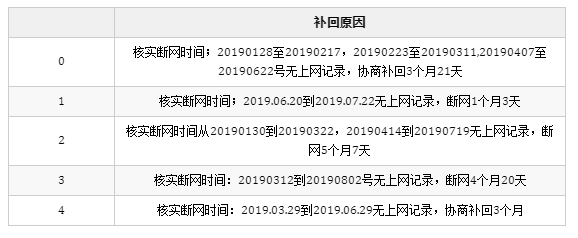
df.head()
结果:
实现代码:
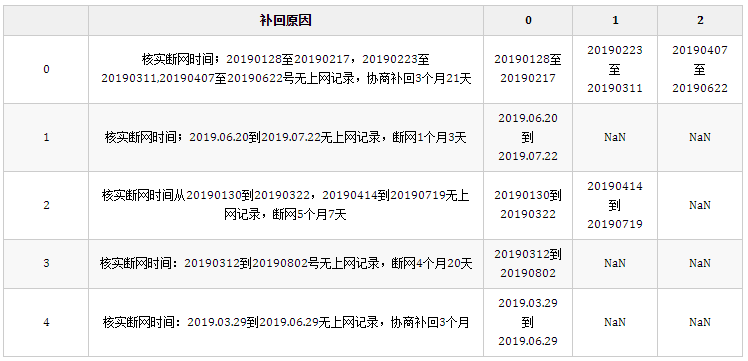
result = df.copy()
result["tmp"] = result["补回原因"].str.findall("([\d.]+[到至][\d.]+)")
result = result.agg({"补回原因": lambda x: x, "tmp": pd.Series}).droplevel(0, axis=1)
result.head()
结果:
分步解析:
df["tmp"] = df["补回原因"].str.findall("([\d.]+[到至][\d.]+)")
df.head(5)
结果:
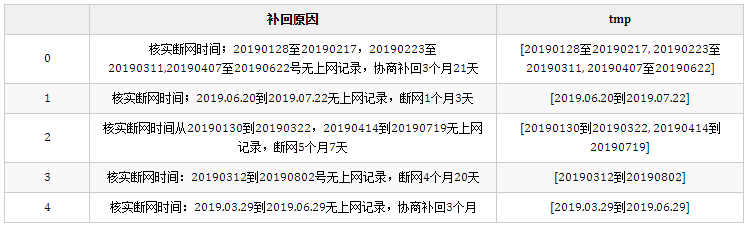
这步使用正则提取出每个日期字符串,[\d.]+表示连续的数字或.用于匹配时间字符串,两个时间之间的连接字符可能是到或至。
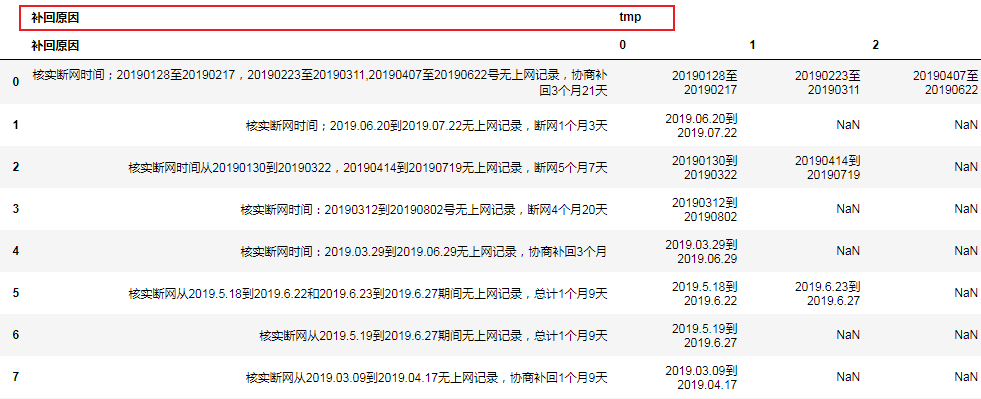
然后我使用agg函数直接对Datafream分列:
df.agg({"补回原因": lambda x: x, "tmp": pd.Series})
结果:
由于列索引多了一级,所以需要删除:
df.agg({"补回原因": lambda x: x, "tmp": pd.Series}).droplevel(0, axis=1).head()
结果:
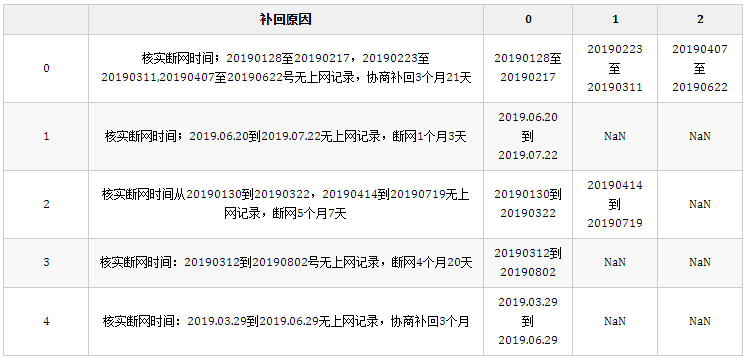
droplevel(0, axis=1)用于删除多级索引指定的级别,axis=0可以删除行索引,axis=1则可以删除列索引,第一参数表示删除级别0。当然如果列索引存在名称时还可以传入名称字符串,可参考官网文档:
df = pd.DataFrame([
... [1, 2, 3, 4],
... [5, 6, 7, 8],
... [9, 10, 11, 12]
... ]).set_index([0, 1]).rename_axis(['a', 'b'])
>>> df.columns = pd.MultiIndex.from_tuples([
... ('c', 'e'), ('d', 'f')
... ], names=['level_1', 'level_2'])
>>> df
level_1 c d
level_2 e f
a b
1 2 3 4
5 6 7 8
9 10 11 12
>>> df.droplevel('a')
level_1 c d
level_2 e f
b
2 3 4
6 7 8
10 11 12
>>> df.droplevel('level2', axis=1)
level_1 c d
a b
1 2 3 4
5 6 7 8
9 10 11 12
分组聚合并分列
需求:

首先,读取数据:
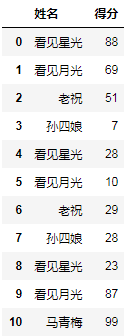
df = pd.read_excel("分组聚合并分列.xlsx")
df
结果:
实现代码:
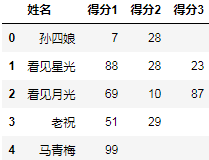
(
df.groupby("姓名")["得分"]
.apply(list)
.apply(pd.Series)
.fillna("")
.rename(columns=lambda x: f"得分{x+1}")
.reset_index()
.astype({"得分1":"int8"})
)
结果:
分布解析:
首先将每个姓名的得分聚合成列表,并最终返回一个Series:
df.groupby("姓名")["得分"].apply(list)
结果:
姓名
孙四娘 [7, 28]
看见星光 [88, 28, 23]
看见月光 [69, 10, 87]
老祝 [51, 29]
马青梅 [99]
Name: 得分, dtype: object
当然,这步的标准写法应该是使用Series的内部方法:
df.groupby("姓名")["得分"].apply(lambda x:x.to_list())
使用Series内部方法的性能比python列表方法转换快一些。
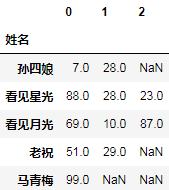
作为一个Series就可以通过将每个列表元素转换为Series,从而最终返回一个分列的Datafream:
_.apply(pd.Series)
结果:
注意:
_在ipython表示上一个输出返回的结果,jupyter还额外支持_num表示num编号单元格的输出。
_.fillna("")
结果:
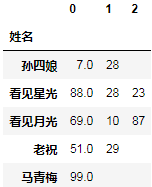
fillna表示填充缺失值,传入””表示将缺失值填充为空字符串。
下面重命名一下列名:
_.rename(columns=lambda x: f"得分{x+1}")
结果:
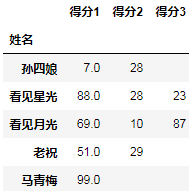
然后还原索引:
_.reset_index()
结果:
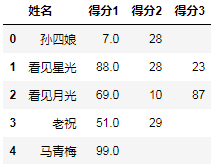
发现结果中有一列,不是整数,所以还原成整数(总分100分,8位足够存储):
_.astype({"得分1":"int8"})
结果:

解析json字符串并字典分列
需求:
首先读取数据:
df = pd.read_excel("字典分列.xlsx")
df.head()
结果:

处理代码:
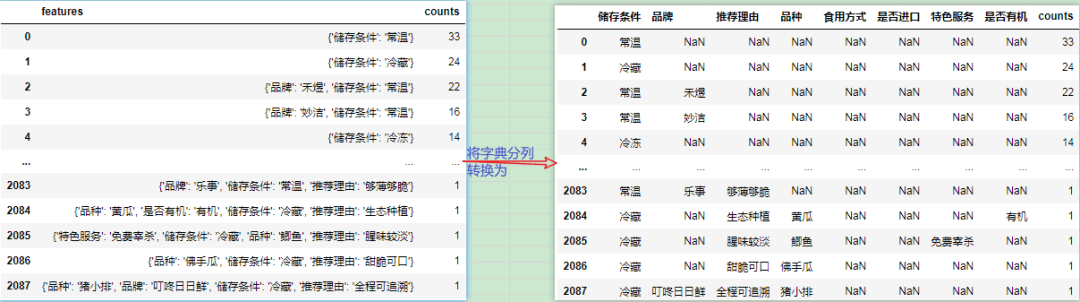
result = df.features.apply(eval).apply(pd.Series)
result["counts"] = df.counts
result
结果:
| 储存条件 | 品牌 | 推荐理由 | 品种 | 食用方式 | 是否进口 | 特色服务 | 是否有机 | counts | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 常温 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 33 |
| 1 | 冷藏 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 24 |
| 2 | 常温 | 禾煜 | NaN | NaN | NaN | NaN | NaN | NaN | 22 |
| 3 | 常温 | 妙洁 | NaN | NaN | NaN | NaN | NaN | NaN | 16 |
| 4 | 冷冻 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 14 |
| … | … | … | … | … | … | … | … | … | … |
| 2083 | 常温 | 乐事 | 够薄够脆 | NaN | NaN | NaN | NaN | NaN | 1 |
| 2084 | 冷藏 | NaN | 生态种植 | 黄瓜 | NaN | NaN | NaN | 有机 | 1 |
| 2085 | 冷藏 | NaN | 腥味较淡 | 鲫鱼 | NaN | NaN | 免费宰杀 | NaN | 1 |
| 2086 | 冷藏 | NaN | 甜脆可口 | 佛手瓜 | NaN | NaN | NaN | NaN | 1 |
| 2087 | 冷藏 | 叮咚日日鲜 | 全程可追溯 | 猪小排 | NaN | NaN | NaN | NaN | 1 |
2088 rows × 9 columns
浅析:
df.features.apply(eval)用于将features列的每个json字符串解析为字典对象。
**.apply(pd.Series)则可以将每个字典对象转换成Series,则可以将该字典扩展到多列,并将原始的Series转换为Datafream。
而result["counts"] = df.counts则将原始数据的counts列添加到结果列中。
本文转自快学Python,有部分增删。
我们的文章到此就结束啦,如果你喜欢今天的 Python 教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 ( pythondict.com )
不只是一个宝典
欢迎关注公众号:Python实用宝典
