
想知道Python取得如此巨大成功的原因吗?只要看看Python提供的大量库就知道了![]() ,包括原生库和第三方库。不过,有这么多Python库,有些库得不到应有的关注也就不足为奇了。此外,只在一个领域里的工作的人并不知道另一个领域里有什么好东西,不知道其他领域的东西能产出什么有用的价值。
,包括原生库和第三方库。不过,有这么多Python库,有些库得不到应有的关注也就不足为奇了。此外,只在一个领域里的工作的人并不知道另一个领域里有什么好东西,不知道其他领域的东西能产出什么有用的价值。
下面给大家列出10个你可能忽略,但绝对值得注意的Python库![]() ,这些工具的用途非常广泛, 简化了从文件系统访问、数据库编程、云服务到构建轻量级web应用程序、创建gui、图像工具、Excel和Word文件等等的事情的工作复杂度。有些库是众所周知的,有些则不太为人所知,但是所有这些Python库都应该在各位的工具箱中占有一席之地。
,这些工具的用途非常广泛, 简化了从文件系统访问、数据库编程、云服务到构建轻量级web应用程序、创建gui、图像工具、Excel和Word文件等等的事情的工作复杂度。有些库是众所周知的,有些则不太为人所知,但是所有这些Python库都应该在各位的工具箱中占有一席之地。
1. Arrow
Arrow: 让你更方便地处理日期和时间。
为什么要使用Arrow:还记得我们之前讲过的日期计算吗?实际上那是一个简单的计算教程,思考一下,如果我们想要切换时区怎么办、更加灵活地日期格式化怎么做?即便是像python这么好用的工具,如果你只用原生库,你也得折腾上一阵子。现在我们有了更好的选择:Arrow.
Arrow拥有四大优势。首先,箭头是Python的datetime模块的一个替代品,这意味着像.now()和.utcnow()这样的公共函数调用可以正常工作。第二,Arrow提供了一些通用的方法,比如转换时区。第三,Arrow提供了“人性化”的日期/时间信息,比如能够毫不费力地说出“一小时前”或“两小时后”发生的事情(就如同我们在暑期余额里讲的那样)。第四,Arrow可以轻松地本地化日期/时间信息。
下面是Arrow使用的三个例子:
import arrow
# 例1:获得当前时间戳
t = arrow.utcnow()
print(t.timestamp) # 1566128587
# 例2:获得当前时间,并格式化为字符串
t = arrow.now()
s1 = t.format()
print(s1) # 2019-08-18 19:43:07+08:00
s2 = t.format("YYYY-MM-DD")
print(s2) # 2019-08-18
# 例3:字符串转Arrow,并格式化为其他格式的字符串
t = arrow.get("2019-12-31 11:30", "YYYY-MM-DD HH:mm")
s3 = t.format('YYYYMMDD')
print(s3) # 201912312. Behold
Behold: 强大的代码调试工具。
如果你只是使用print进行项目的调试,你会发现在大型项目的时候,这一招根本行不通![]() 因为大型项目的数据流动非常复杂,你必须跟踪一个变量的流动才行,这时候你可能会出现每隔几句就写一个print的尴尬情况。这时候Behold就非常有优势了,它具有搜索、筛选、排序功能,而且能跨模块地展示数据流向。
因为大型项目的数据流动非常复杂,你必须跟踪一个变量的流动才行,这时候你可能会出现每隔几句就写一个print的尴尬情况。这时候Behold就非常有优势了,它具有搜索、筛选、排序功能,而且能跨模块地展示数据流向。
建议阅读官方例子: https://behold.readthedocs.io/en/latest/ref/behold.html
3. Black
black:使用严格的规则格式化Python代码。
black是一个毫不妥协的格式化工具,它检测到不符合规范的代码风格直接给你全部格式化了,不需要你自己确定,非常适合代码风格紊乱的人群进行自我纠正![]() ,使用也非常简单, CMD/Terminal安装black:
,使用也非常简单, CMD/Terminal安装black:
pip install black
然后同样,CMD/Terminal进入到你的Python文件的文件夹里,输入:
black 你的文件名.py
即可格式化该文件里的代码
4. Bottle
Bottle:轻量级网站/api开发工具。
当你想要构建一个快速的RESTful API或者使用web框架的基本框架来构建一个应用程序时,Bottle完全就够用了。路由、模板、请求和响应、支持许多种请求协议,甚至如websockets之类的高级功能都支持。同样,启动所需的工作量也很小,而且当需要更高级的功能时,Bottle可以很好地扩展,非常优秀![]() 。
。
5. Click
Click: 让你快速地为Python应用程序构建命令行界面。
在没有用click之前,我们是如何获取用户输入的? 是用 val = input(xxx) 这样的形式吧?虽然也非常简单,但是当你想要给它设定默认值的时候就麻烦了![]() 然而click可以让你消去这样的烦恼:
然而click可以让你消去这样的烦恼:
import click
@click.option('--count', default=1, help='Number of greetings')
@click.option('--name', prompt='您的名字是', help='用户的名称')我的天,简直是上天给予Python程序员的礼物啊。更多的功能请阅读官方文档,比如它还能设定输入参数:
import click
@click.command()
@click.option('--count', default=1, help='欢迎次数.')
@click.option('--name', prompt='您的名字是', help='用户的名称')
def hello(count, name):
"""欢迎名字为name的用户count次."""
for x in range(count):
click.echo('Hello %s!' % name)
if __name__ == '__main__':
hello()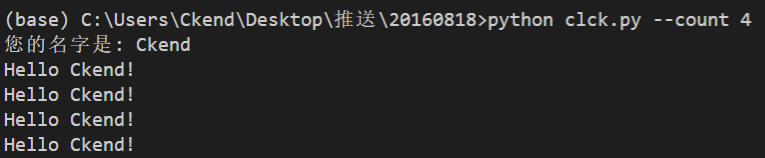
6. Nuitka
Nuitka: 将Python编译成C++级的可执行文件。
重点是C++级的应用,速度快!速度快!速度快!尽管Cython也能够把Python编译成C,但是Cython仅仅关注数学和统计应用程序,而Nuitka可以按原样使用任何Python程序编译为C,生成单文件的可执行文件。虽然目前还在早期阶段,但是可以预想到它的未来是多么的辉煌![]()
7. Numba
Numba: 有选择地加速数学计算。
这是我以前梦寐以求的功能,我们知道Numpy通过在Python接口中封装高速的C库进行工作,Cython将某些用户选择的类型编译为C,但是我们发现这些东西用起来都不是很顺手,感觉“命运 ” 不是由我掌控的。有了Numba之后,我们可以对函数进行加速![]() 你要做的仅仅是在函数上方加一个装饰器,这可真的是非常舒服:
你要做的仅仅是在函数上方加一个装饰器,这可真的是非常舒服:
@nb.jit(nopython=True) def acc(x):
8. Openpyxl
openpyxl: 读取,写入和操作Excel文件。
还记得我们的日历文章吗?我们在那篇文章里就用到了openpyxl这个库,实质上,用于操作Excel的不止有这个库可以做到,但是它有一些独特的功能,比如,写成最新的文件格式xlsx,而且它对文件大小是没有限制的,就这两个功能已经完爆xlwt了。当然,它在速度上是比不过xlwt的,这就需要各位权衡使用了![]()
9. Peewee
peewee: 支持sqlite, Mysql及PostgreSQL的小型ORM(方便写数据库的)。
这是我在python上接触的第一个ORM,不是所有人都喜欢用这个玩意儿,但是对于那些不喜欢接触SQL语句开发的人来说,这玩意儿简直是宝物啊![]() 。peewee非常易于构建、连接、操作数据库,然后内置了许多的查询操作功能。不过需要注意的是,peewee 3.x 并不完全向旧版本兼容。
。peewee非常易于构建、连接、操作数据库,然后内置了许多的查询操作功能。不过需要注意的是,peewee 3.x 并不完全向旧版本兼容。
10. PyFilesystem
PyFilesystem: 简化了文件、目录的处理方法,支持任何文件系统的操作,大幅度提高编程效率。
你的开发过程中,有没有为这样的事情忧愁过:打开一个不存在文件夹里的文件(新建),确定某个目录里是否存在某个文件,确定是否存在某个目录![]() ,当然如果你非常熟练os和io模块,你会觉得这些事情简直是so easy. 但是对于一些不熟悉这两个模块的语句的同学,这可得Google一下。幸好,现在有了PyFilesystem, 我们的编程生活能够快乐许多。它能支持任何文件系统的操作,而且提供了许多实用的函数,比如说查看当前目录下的文件:
,当然如果你非常熟练os和io模块,你会觉得这些事情简直是so easy. 但是对于一些不熟悉这两个模块的语句的同学,这可得Google一下。幸好,现在有了PyFilesystem, 我们的编程生活能够快乐许多。它能支持任何文件系统的操作,而且提供了许多实用的函数,比如说查看当前目录下的文件:
from fs import open_fs
my_fs = open_fs('.')
print(my_fs.listdir('/')) 显示目录结构树
from fs import open_fs
my_fs = open_fs('.')
my_fs.tree()当然还有更多的功能,请阅读官方文档。
Python实用宝典 (pythondict.com)
不只是一个宝典
欢迎关注公众号:Python实用宝典

评论(0)