from bert_serving.client import BertClient
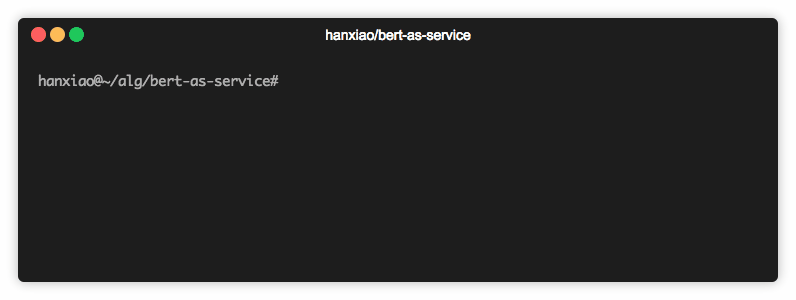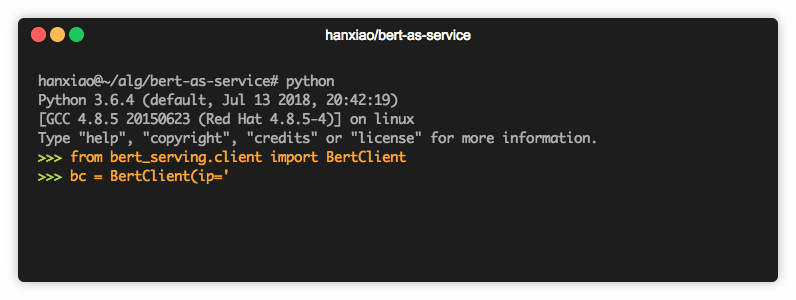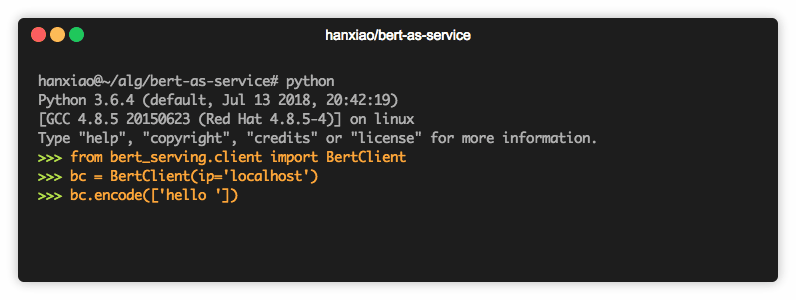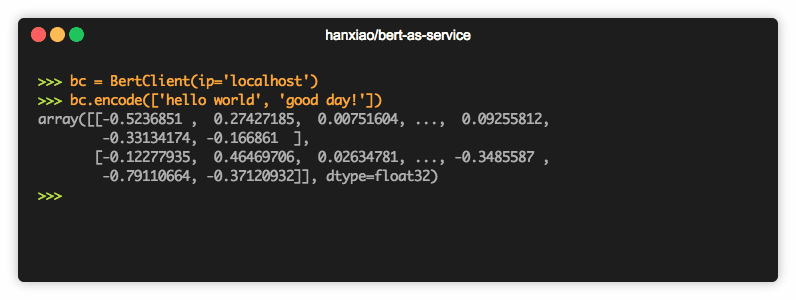
bc = BertClient()
bc.encode(['First do it', 'then do it right', 'then do it better'])
作为 BERT 的一个特性,你可以通过将它们与 |||(前后有空格)连接来获得一对句子的编码,例如
bc.encode(['First do it ||| then do it right'])
远程使用 BERT 服务
你还可以在一台 (GPU) 机器上启动服务并从另一台 (CPU) 机器上调用它,如下所示:
# on another CPU machine
from bert_serving.client import BertClient
bc = BertClient(ip='xx.xx.xx.xx') # ip address of the GPU machine
bc.encode(['First do it', 'then do it right', 'then do it better'])
prefix_q = '##### **Q:** '
with open('README.md') as fp:
questions = [v.replace(prefix_q, '').strip() for v in fp if v.strip() and v.startswith(prefix_q)]
print('%d questions loaded, avg. len of %d' % (len(questions), np.mean([len(d.split()) for d in questions])))
# 33 questions loaded, avg. len of 9
while True:
query = input('your question: ')
query_vec = bc.encode([query])[0]
# compute normalized dot product as score
score = np.sum(query_vec * doc_vecs, axis=1) / np.linalg.norm(doc_vecs, axis=1)
topk_idx = np.argsort(score)[::-1][:topk]
for idx in topk_idx:
print('> %s\t%s' % (score[idx], questions[idx]))
完成!现在运行代码并输入你的查询,看看这个搜索引擎如何处理模糊匹配:
完整代码如下,一共23行代码(在后台回复关键词也能下载):
import numpy as np
from bert_serving.client import BertClient
from termcolor import colored
prefix_q = '##### **Q:** '
topk = 5
with open('README.md') as fp:
questions = [v.replace(prefix_q, '').strip() for v in fp if v.strip() and v.startswith(prefix_q)]
print('%d questions loaded, avg. len of %d' % (len(questions), np.mean([len(d.split()) for d in questions])))
with BertClient(port=4000, port_out=4001) as bc:
doc_vecs = bc.encode(questions)
while True:
query = input(colored('your question: ', 'green'))
query_vec = bc.encode([query])[0]
# compute normalized dot product as score
score = np.sum(query_vec * doc_vecs, axis=1) / np.linalg.norm(doc_vecs, axis=1)
topk_idx = np.argsort(score)[::-1][:topk]
print('top %d questions similar to "%s"' % (topk, colored(query, 'green')))
for idx in topk_idx:
print('> %s\t%s' % (colored('%.1f' % score[idx], 'cyan'), colored(questions[idx], 'yellow')))
from bark import SAMPLE_RATE, generate_audio, preload_models
from scipy.io.wavfile import write as write_wav
from IPython.display import Audio
# download and load all models
preload_models()
# generate audio from text
text_prompt = """
Hello, my name is Suno. And, uh — and I like pizza. [laughs]
But I also have other interests such as playing tic tac toe.
"""
audio_array = generate_audio(text_prompt)
# save audio to disk
write_wav("bark_generation.wav", SAMPLE_RATE, audio_array)
# play text in notebook
Audio(audio_array, rate=SAMPLE_RATE)