

本文是一个较为完整的 mitmproxy教程,侧重于介绍如何开发拦截脚本,帮助读者能够快速得到一个自定义的代理工具。玩爬虫的小伙伴都知道,抓包工具除了MitmProxy 外,还有 Fiddler、Charles以及浏览器 netwrok 等
既然都有这么多抓包工具了,为什么还要会用 MitmProxy 呢??主要有以下几点:
- 不需要安装软件,直接在线(浏览器)进行抓包(包括手机端和 PC 端)
- 配合 Python 脚本抓包改包
- 抓包过程的所有数据包都可以自动保留到txt里面,方便过滤分析
- 使用相对简单,易上手
本文假设读者有基本的 python 知识,且已经安装好了一个 python 3 开发环境。如果你对 nodejs 的熟悉程度大于对 python,可移步到 anyproxy,anyproxy 的功能与 mitmproxy 基本一致,但使用 js 编写定制脚本。除此之外我就不知道有什么其他类似的工具了,如果你知道,欢迎评论告诉我。
本文基于 mitmproxy v5,当前版本号为 v5.0.1。
1.基本介绍
顾名思义,mitmproxy 就是用于 MITM 的 proxy,MITM 即中间人攻击(Man-in-the-middle attack)。用于中间人攻击的代理首先会向正常的代理一样转发请求,保障服务端与客户端的通信,其次,会适时的查、记录其截获的数据,或篡改数据,引发服务端或客户端特定的行为。
不同于 fiddler 或 wireshark 等抓包工具,mitmproxy 不仅可以截获请求帮助开发者查看、分析,更可以通过自定义脚本进行二次开发。举例来说,利用 fiddler 可以过滤出浏览器对某个特定 url 的请求,并查看、分析其数据,但实现不了高度定制化的需求,类似于:“截获对浏览器对该 url 的请求,将返回内容置空,并将真实的返回内容存到某个数据库,出现异常时发出邮件通知”。而对于 mitmproxy,这样的需求可以通过载入自定义 python 脚本轻松实现。
但 mitmproxy 并不会真的对无辜的人发起中间人攻击,由于 mitmproxy 工作在 HTTP 层,而当前 HTTPS 的普及让客户端拥有了检测并规避中间人攻击的能力,所以要让 mitmproxy 能够正常工作,必须要让客户端(APP 或浏览器)主动信任 mitmproxy 的 SSL 证书,或忽略证书异常,这也就意味着 APP 或浏览器是属于开发者本人的——显而易见,这不是在做黑产,而是在做开发或测试。
事实上,以上说的仅是 mitmproxy 以正向代理模式工作的情况,通过调整配置,mitmproxy 还可以作为透明代理、反向代理、上游代理、SOCKS 代理等,但这些工作模式针对 mitmproxy 来说似乎不大常用,故本文仅讨论正向代理模式。
2.特性
- 拦截HTTP和HTTPS请求和响应并即时修改它们
- 保存完整的HTTP对话以供以之后重发和分析
- 重发HTTP对话的客户端
- 重发先前记录的服务的HTTP响应
- 反向代理模式将流量转发到指定的服务器
- 在macOS和Linux上实现透明代理模式
- 使用Python对HTTP流量进行脚本化修改
- 实时生成用于拦截的SSL / TLS证书
- And much, much more…
3.配置 MitmProxy
MitmProxy可以说是客户端,也可以说是一个 python 库
方式一:客户端
https://mitmproxy.org/downloads/
在这个地址下可以下载对应的客户端安装即可
方式二:Python库
pip install mitmproxy
通过这个 pip 命令可以下载好 MitmProxy,下面将会以 Python 库的使用方式给大家讲解如何使用(推荐方式二)
2.启动 MitmProxy
MitmProxy 启动有三个命令(三种模式)
-
mitmproxy,提供命令行界面
-
mitmdump,提供一个简单的终端输出(还可以配合Python抓包改包)
-
mitmweb,提供在线浏览器抓包界面
mitmdump启动
mitmdump -w d://lyc.txt

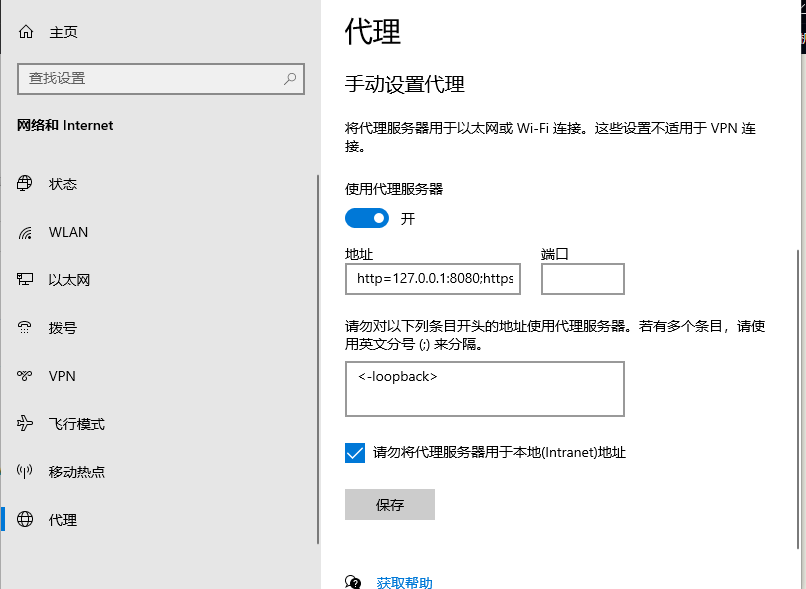
这样就启动mitmdump,接着在本地设置代理Ip是本机IP,端口8080
安装证书
访问下面这个链接
http://mitm.it/
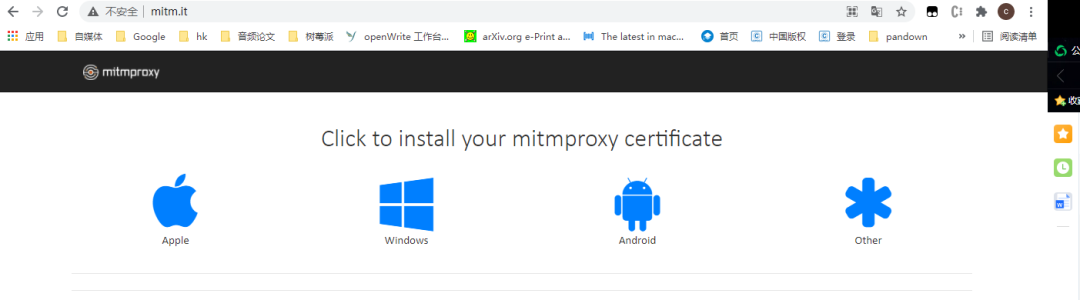
可以选择自己的设备(window,或者Android、Apple设备去)安装证书。
然后随便打开一个网页,比如百度
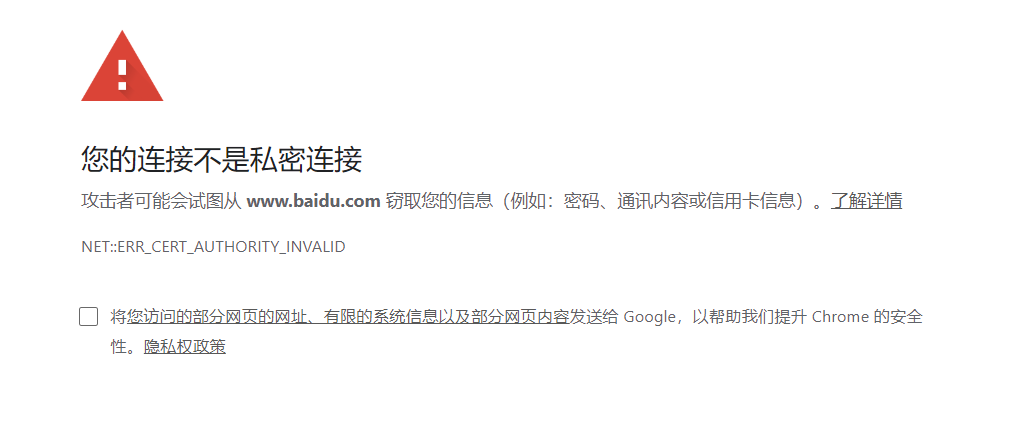
这里是因为证书问题,提示访问百度提示https证书不安全,那么下面开始解决这个问题,因此就引出了下面的这种启动方式
浏览器代理式启动
哪一个浏览器都可以,下面以Chrome浏览器为例(其他浏览器操作一样)
先找到chrome浏览器位置,我的chrome浏览器位置如下图
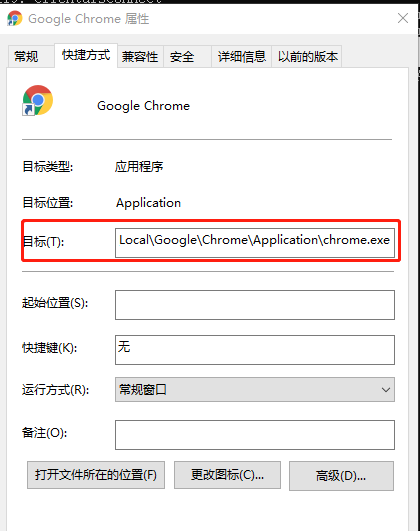
通过下面命令启动
"C:\Users\Administrator\AppData\Local\Google\Chrome\Application\chrome.exe" --proxy-server=127.0.0.1:8080 --ignore-certificate-errors
—proxy-server是设置代理和端口
–ignore-certificate-errors是忽略证书
然后会弹出来Chrome浏览器,接着我们搜索知乎
在cmd中就可以看到数据包
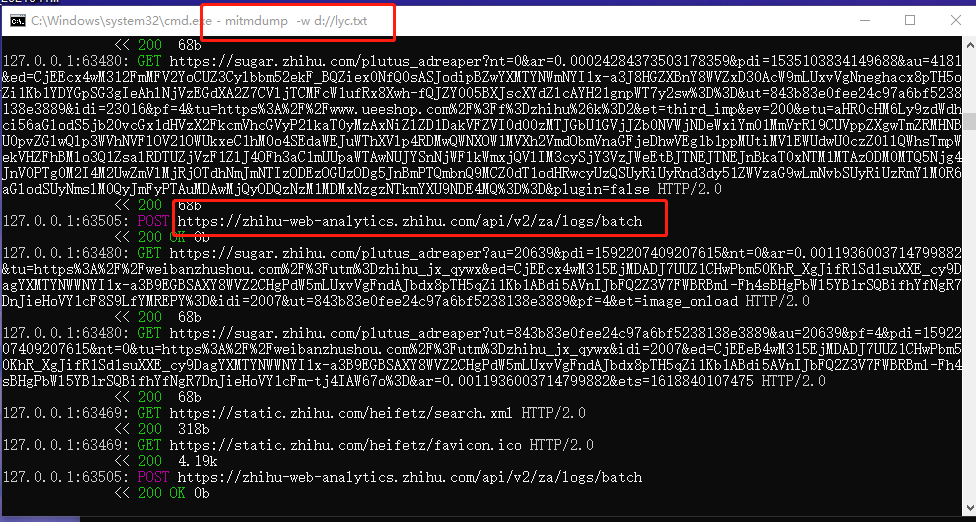
这些文本数据可以在编程中进行相应的操作,比如可以放到python中进行过来监听处理。
4.启动 Mitmweb
新开一个cmd(终端)窗口,输入下来命令启动mitmweb
mitmweb

之后会在浏览器自动打开一个网页(其实手动打开也可以,地址就是:http://127.0.0.1:8081)
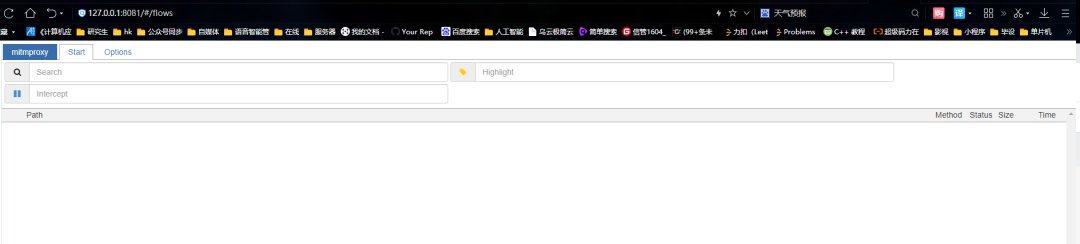
现在页面中什么也没有,那下面我们在刷新一个知乎页面
重点:关闭mitmproxy终端!关闭mitmproxy终端!关闭mitmproxy终端!
如果不改变在mitmweb中获取不到数据,数据只在mitmproxy中,因此需要关闭mitmproxy这个命令终端
刷新知乎页面之后如下:
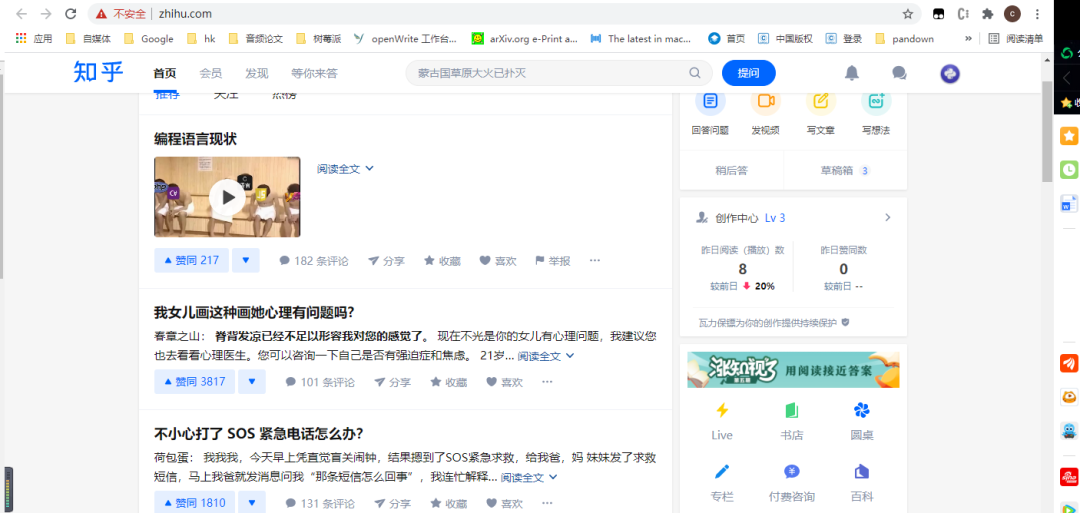
在刚刚的网页版抓包页面就可以看到数据包了
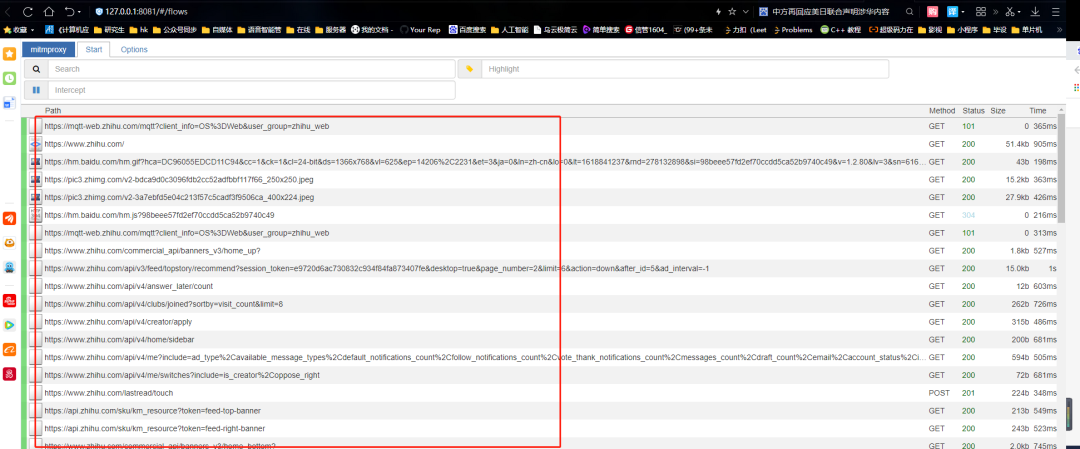
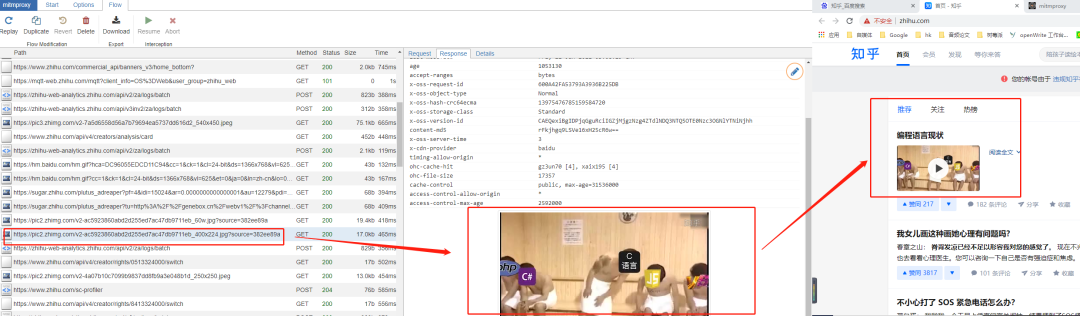
并且还包括https类型,比如查看其中一个数据包,找到数据是对应的,说明抓包成功。
5.配合 Python 脚本
mitmproxy代理(抓包)工具最强大之处在于对python脚步的支持(可以在python代码中直接处理数据包)
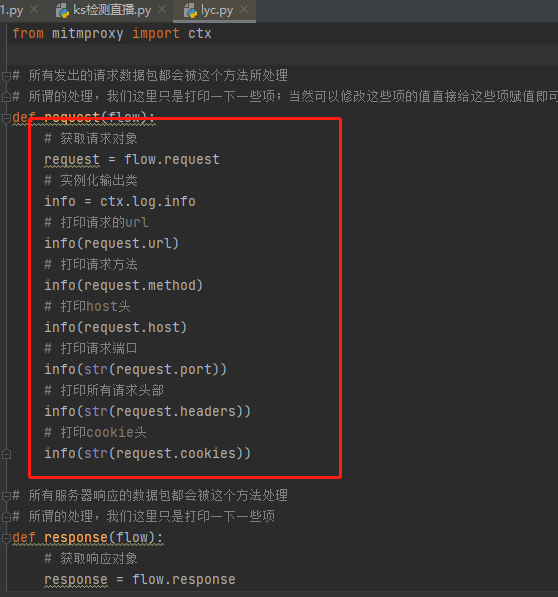
下面开始演示,先新建一个py文件(lyc.py)
from mitmproxy import ctx # 所有发出的请求数据包都会被这个方法所处理 # 所谓的处理,我们这里只是打印一下一些项;当然可以修改这些项的值直接给这些项赋值即可 def request(flow): # 获取请求对象 request = flow.request # 实例化输出类 info = ctx.log.info # 打印请求的url info(request.url) # 打印请求方法 info(request.method) # 打印host头 info(request.host) # 打印请求端口 info(str(request.port)) # 打印所有请求头部 info(str(request.headers)) # 打印cookie头 info(str(request.cookies)) # 所有服务器响应的数据包都会被这个方法处理 # 所谓的处理,我们这里只是打印一下一些项 def response(flow): # 获取响应对象 response = flow.response # 实例化输出类 info = ctx.log.info # 打印响应码 info(str(response.status_code)) # 打印所有头部 info(str(response.headers)) # 打印cookie头部 info(str(response.cookies)) # 打印响应报文内容 info(str(response.text))
在终端中输入一下命令启动
mitmdump.exe -s lyc.py

(PS:这里需要通过另一个端启动浏览器)
"C:\Users\Administrator\AppData\Local\Google\Chrome\Application\chrome.exe" --proxy-server=127.0.0.1:8080 --ignore-certificate-errors
然后访问某个网站
在终端中就可以看到信息
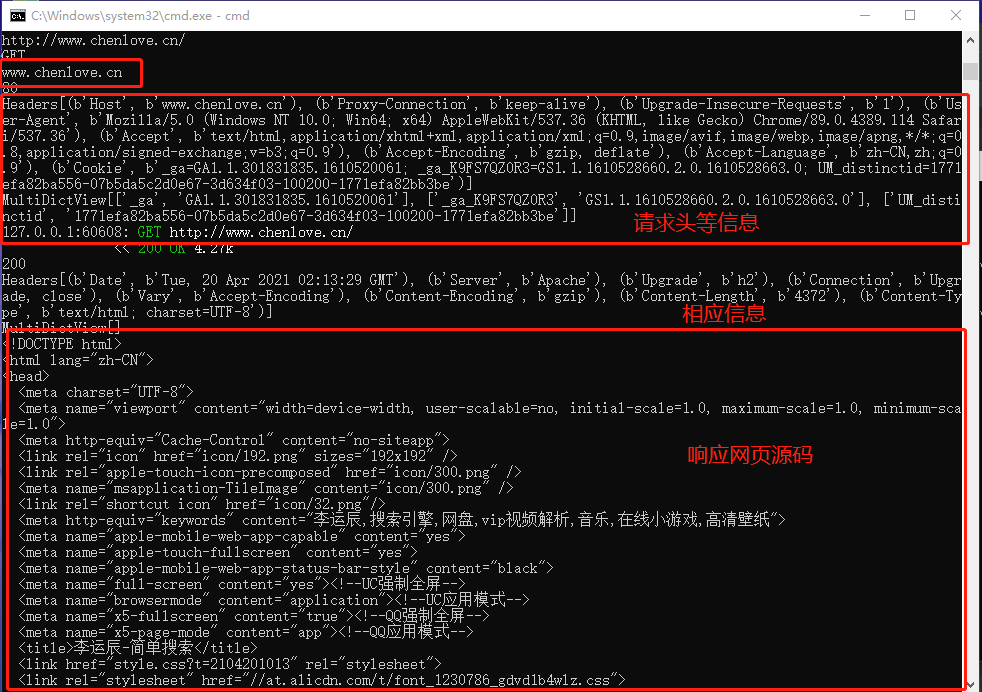
这些信息就是我们在 lyc.py 中指定的显示信息
PS:在手机上配置好代理之后,mitmproxy 同样可以抓取手机端数据
小结:
- 不需要安装软件,直接在线(浏览器)进行抓包(包括手机端和 PC 端)
- 配合 Python 脚本抓包改包
- 抓包过程的所有数据包都可以自动保留到 txt 里面,方便过滤分析
- 使用相对简单,易上手
我们的文章到此就结束啦,如果你喜欢今天的 Python 教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 ( pythondict.com )
不只是一个宝典
欢迎关注公众号:Python实用宝典
