这是Python改变生活系列的第三篇,讲到了如何通过Python的pyzbar批量识别快递单号的条形码,以提高我们的生活工作效率,这是一篇实战教程。
1.识别快递单号的前情提要
了解我的小伙伴可能都知道,小五经常给大家送书。最近一年,不算联合抽奖送书,单独我自购+出版社赞助已送出1000本书籍。
如果是自购的话,还需要自己联系快递小哥寄出书籍。


寄出后快递小哥会给我截图来反馈,然而我想要单号的时候就遇到问题了。

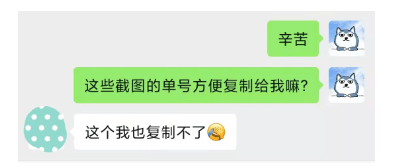
每次寄完书,我都只能得到n个截图(内含快递信息)。


为了及时反馈大家物流信息,我需要尽快将快递单号提取出来。
2.思考解决办法
每次大概都有十几到几十张截图,手动去识别真的太麻烦。
不如先看看每张截图大概是什么样子,再去想想批量处理的办法吧。


主要是为了批量获取图片中的快递单号,我想到了两个解决办法:
-
用python识别条形码来直接获得准确快递单号
-
用python调用ocr,识别截图中的快递单号文字
大家觉得哪个更简单更准确呢?


今天我先聊聊第一种方法的流程和踩坑经历。
3.实战教程-遍历图片
首先,第一步需要先获取文件夹中的所有截图,再依次进行条形码识别。
具体操作可以参考注释
import os
def get_jpg():
jpgs = []
path = os.getcwd()
for i in os.listdir(path): #获取文件列表
if i.split(".")[-1] == "jpg": #筛选jpg文件(截图)
oldname=os.path.join(path,i) #旧文件名
i = i.replace('微信图片_','')
newname=os.path.join(path,i) #新文件名
os.rename(oldname,newname) #改名
jpgs.append(i)
return jpgs
上面的代码中除了遍历筛选图片,还涉及了改名的操作。
这是因为我在后面使用 opencv 时,打开的路径只要含有中文就会一直报错,于是我就干脆把截图名称里的中文去除。
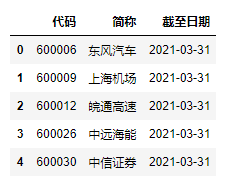
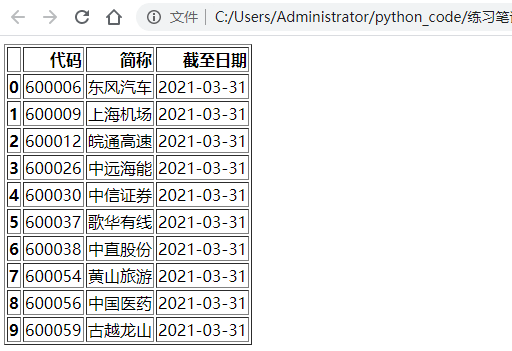
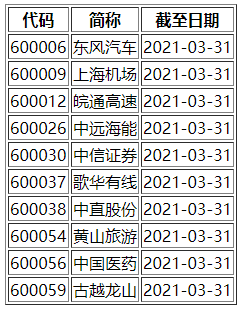
执行构建的get_jpg()函数,得到

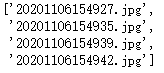
这些就是演示文件中的四个截图文件,下面开始对他们进行识别。
4.实战教程-识别条形码
python的第三方模块 pyzbar 可以很方便地处理二维码的识别。我们这次用它来识别一维条形码的话,用法也大致一样。不过还要搭配 cv2 使用,主要是为了利用cv2.imread()来读取图片文件。
注意:对于cv2模块,安装时需要输入
pip3 install opencv-python,但在导入的时候采用import cv2。
识别条形码的具体语句如下所示:
import pyzbar.pyzbar as pyzbar
import cv2
def get_barcode(img):
image = cv2.imread(img)
barcodes = pyzbar.decode(image)
barcode = barcodes[0]
barcode_data = barcode.data.decode("utf-8")
return barcode_data
上面构建的get_barcode()函数可以实现识别条形码,并返回结果数据。
我们可以用for循环遍历前文获取的所有图片,再依次使用get_barcode()函数来识别条形码。
data_m =[]
for i in jpgs:
data = get_barcode(i)
data_m.append(data)
data_m

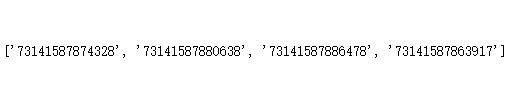
可以发现,成功识别了四张截图里的条形码,并获取了对应的快递单号。


小结
回顾今天的问题案例,我先通过思考想出了两种解决办法。第一种的优点是识别条形码比OCR更准确,但是其只获取了快递单号。后续在给获得赠书的同学反馈时,我还需要手动将名字和单号对应,不够偷懒。后续将给大家介绍第二种方法的流程和优缺点。
如果想看更多python改变生活的真实问题案例,给本文右下角点个赞吧👍
如果你也有一直想用python解决的问题,欢迎在评论区告诉我🚀
本文转自快学Python。
我们的文章到此就结束啦,如果你喜欢今天的Python 实战教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应红字验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
点击下方阅读原文可获得更好的阅读体验
Python实用宝典 (pythondict.com)
不只是一个宝典
欢迎关注公众号:Python实用宝典