

Bamboo-pipeline 是蓝鲸智云旗下SaaS标准运维的流程编排引擎。其具备以下特点:
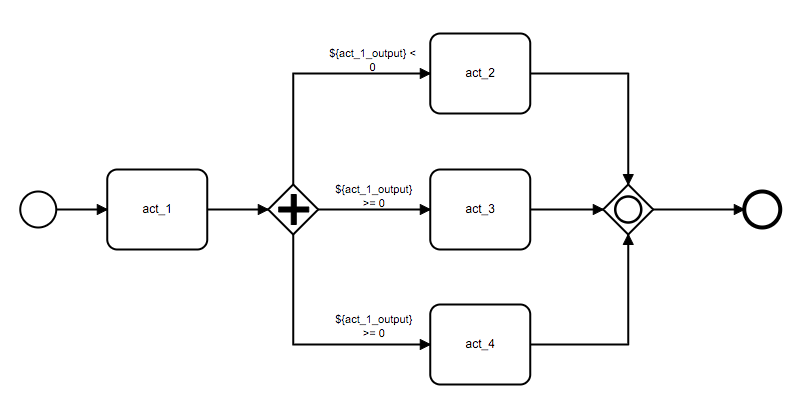
- 1. 多种流程模式:支持串行、并行,支持子流程,可以根据全局参数自动选择分支执行,节点失败处理机制可配置。
- 2. 参数引擎:支持参数共享,支持参数替换。
- 3. 可交互的任务执行:任务执行中可以随时暂停、继续、撤销,节点失败后可以重试、跳过。

本文需要涉及到 Django, Celery 的前置知识,如果你还不了解这两者,建议谷歌或百度搜索了解一下,或者阅读我之前的文章:
Django:
Celery:
什么?Python Celery 也能调度Go worker?
1.准备
开始之前,你要确保Python和pip已经成功安装在电脑上,如果没有,请访问这篇文章:超详细Python安装指南 进行安装。
(可选1) 如果你用Python的目的是数据分析,可以直接安装Anaconda:Python数据分析与挖掘好帮手—Anaconda,它内置了Python和pip.
(可选2) 此外,推荐大家用VSCode编辑器来编写小型Python项目:Python 编程的最好搭档—VSCode 详细指南
Windows环境下打开Cmd(开始—运行—CMD),苹果系统环境下请打开Terminal(command+空格输入Terminal),输入命令安装依赖:
pip install bamboo-engine pip install bamboo-pipeline pip install django pip install celery
2. 项目初始化
(选项一:无Django项目)如果你没有任何的现成Django项目,请按下面的流程初始化
由于 bamboo-pipeline 运行时基于 Django 实现,所以需要新建一个 Django 项目:
django-admin startproject easy_pipeline cd easy_pipeline
在 easy_pipeline.settings.py 下添加如下配置:
from pipeline.eri.celery.queues import *
from celery import Celery
app = Celery("proj")
app.config_from_object("django.conf:settings")
INSTALLED_APPS = [
...
"pipeline",
"pipeline.engine",
"pipeline.component_framework",
"pipeline.eri",
...
]在 easy_pipeline目录下初始化数据库:
python manage.py migrate
(选项二:有Django项目需要使用流程引擎)如果你有现成的PipeLine项目需要使用此流程引擎,请在项目的 settings.py 下添加如下配置:
from pipeline.eri.celery.queues import *
from celery import Celery
app = Celery("proj")
app.config_from_object("django.conf:settings")
INSTALLED_APPS = [
...
"pipeline",
"pipeline.engine",
"pipeline.component_framework",
"pipeline.eri",
...
]然后重新执行migrate,生成pipeline相关的流程模型:
python manage.py migrate
migrate 执行完毕后会如下图所示:


由于是在原有项目上使用流程引擎,可能会遇到一些版本不匹配的问题,如果遇到报错,请排查解决或到蓝鲸官网上进行询问。
3. 简单的流程编排实战
首先在项目目录下启动 celery worker:
python manage.py celery worker -Q er_execute,er_schedule --pool=solo -l info
启动成功类似下图所示:

(注意)如果你是在你的原有Django项目上做改造,它并不一定能够顺利地启动成功,这是因为Pipeline使用了 Django 2.2.24,会存在许多版本不兼容的情况。如果遇到报错,请排查解决或到蓝鲸官网上进行询问。
在下面的例子中,我们将会创建并执行一个简单的流程:

3.1 创建流程APP
在 bamboo_pipeline 中,一个流程由多个组件组成,官方推荐使用APP统一管控组件:
python manage.py create_plugins_app big_calculator
该命令会在 Django 工程根目录下生成拥有以下目录结构的 APP:
big_calculator
├── __init__.py
├── components
│ ├── __init__.py
│ └── collections
│ ├── __init__.py
│ └── plugins.py
├── migrations
│ └── __init__.py
└── static
└── big_calculator
└── plugins.js别忘了把新创建的这个插件添加到 Django 配置的 INSTALLED_APPS 中:
INSTALLED_APPS = (
...
'big_calculator',
...
)3.2 编写流程的Service原子
组件服务 Service 是组件的核心,Service 定义了组件被调用时执行的逻辑,下面让我们实现一个计算传入的参数 n 的阶乘,并把结果写到输出中的 Service,在 big_calculator/components/collections/plugins.py 中输入以下代码:
import math
from pipeline.core.flow.activity import Service
class FactorialCalculateService(Service):
def execute(self, data, parent_data):
"""
组件被调用时的执行逻辑
:param data: 当前节点的数据对象
:param parent_data: 该节点所属流程的数据对象
:return:
"""
n = data.get_one_of_inputs('n')
if not isinstance(n, int):
data.outputs.ex_data = 'n must be a integer!'
return False
data.outputs.factorial_of_n = math.factorial(n)
return True
def inputs_format(self):
"""
组件所需的输入字段,每个字段都包含字段名、字段键、字段类型及是否必填的说明。
:return:必须返回一个 InputItem 的数组,返回的这些信息能够用于确认该组件需要获取什么样的输入数据。
"""
return [
Service.InputItem(name='integer n', key='n', type='int', required=True)
]
def outputs_format(self):
"""
组件执行成功时输出的字段,每个字段都包含字段名、字段键及字段类型的说明
:return: 必须返回一个 OutputItem 的数组, 便于在流程上下文或后续节点中进行引用
"""
return [
Service.OutputItem(name='factorial of n', key='factorial_of_n', type='int')
]
首先我们继承了 Service 基类,并实现了 execute() 和 outputs_format() 这两个方法,他们的作用如下:
execute:组件被调用时执行的逻辑。接收data和parent_data两个参数。
其中,data是当前节点的数据对象,这个数据对象存储了用户传递给当前节点的参数的值以及当前节点输出的值。parent_data则是该节点所属流程的数据对象,通常会将一些全局使用的常量存储在该对象中,如当前流程的执行者、流程的开始时间等。outputs_format:组件执行成功时输出的字段,每个字段都包含字段名、字段键及字段类型的说明。这个方法必须返回一个OutputItem的数组,返回的这些信息能够用于确认某个组件在执行成功时输出的数据,便于在流程上下文或后续节点中进行引用。inputs_format:组件所需的输入字段,每个字段都包含字段名、字段键、字段类型及是否必填的说明。这个方法必须返回一个InputItem的数组,返回的这些信息能够用于确认某个组件需要获取什么样的输入数据。
下面我们来看一下 execute() 方法内部执行的逻辑,首先我们尝试从当前节点数据对象的输出中获取输入参数 n,如果获取到的参数不是一个 int 实例,那么我们会将异常信息写入到当前节点输出的 ex_data 字段中,这个字段是引擎内部的保留字段,节点执行失败时产生的异常信息都应该写入到该字段中。随后我们返回 False 代表组件本次执行失败,随后节点会进入失败状态:
n = data.get_one_of_inputs('n')
if not isinstance(n, int):
data.outputs.ex_data = 'n must be a integer!'
return False
若获取到的 n 是一个正常的 int,我们就调用 math.factorial() 函数来计算 n 的阶乘,计算完成后,我们会将结果写入到输出的 factorial_of_n 字段中,以供流程中的其他节点使用:
data.outputs.factorial_of_n = math.factorial(n) return True
3.3 编写流程组件,绑定Service原子
完成 Service 的编写后,我们需要将其与一个 Component 绑定起来,才能够注册到组件库中,在 big_calculator\components\__init__.py 文件下添加如下的代码:
import logging
from pipeline.component_framework.component import Component
from big_calculator.components.collections.plugins import FactorialCalculateService
logger = logging.getLogger('celery')
class FactorialCalculateComponent(Component):
name = 'FactorialCalculateComponent'
code = 'fac_cal_comp'
bound_service = FactorialCalculateService我们定义了一个继承自基类 Component 的类 FactorialCalculateComponent,他拥有以下属性:
name:组件名。code:组件代码,这个代码必须是全局唯一的。bound_service:与该组件绑定的Service。
这样一来,我们就完成了一个流程原子的开发。
3.4 生成流程,测试刚编写的组件
在 big_calculator\test.py 写入以下内容,生成一个流程,测试刚刚编写的组件:
# Python 实用宝典
# 2021/06/20
import time
from bamboo_engine.builder import *
from big_calculator.components import FactorialCalculateComponent
from pipeline.eri.runtime import BambooDjangoRuntime
from bamboo_engine import api
from bamboo_engine import builder
def bamboo_playground():
"""
测试流程引擎
"""
# 使用 builder 构造出流程描述结构
start = EmptyStartEvent()
# 这里使用 我们刚创建好的n阶乘组件
act = ServiceActivity(component_code=FactorialCalculateComponent.code)
# 传入参数
act.component.inputs.n = Var(type=Var.PLAIN, value=4)
end = EmptyEndEvent()
start.extend(act).extend(end)
pipeline = builder.build_tree(start)
api.run_pipeline(runtime=BambooDjangoRuntime(), pipeline=pipeline)
# 等待 1s 后获取流程执行结果
time.sleep(1)
result = api.get_execution_data_outputs(BambooDjangoRuntime(), act.id).data
print(result)
随后,在命令行输入
python manage.py shell
打开 django console, 输入以下命令,执行此流程:
from big_calculator.test import bamboo_playground bamboo_playground()
流程运行完后,获取节点的执行结果,可以看到,该节点输出了 factorial_of_n,并且值为 24(4 * 3 * 2 *1),这正是我们需要的效果:
{'_loop': 0, '_result': True, 'factorial_of_n': 24}
恭喜你,你已经成功的创建了一个流程并把它运行起来了!在这期间你可能会遇到不少的坑,建议尝试先自行解决,如果实在无法解决,可以前往 标准运维 仓库提 issues,或者前往蓝鲸智云官网提问。
我们的文章到此就结束啦,如果你喜欢今天的 Python 教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 ( pythondict.com )
不只是一个宝典
欢迎关注公众号:Python实用宝典

