我们曾经研究过如何让Python和Go互相调度,当时发现,将Go语言写的模块打包成动态链接库,就能在Python中进行调度:
优劣互补! Python+Go结合开发的探讨
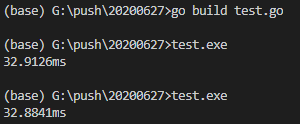
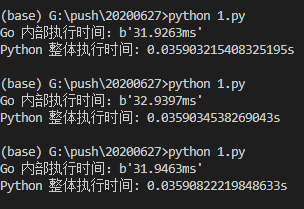
Go的优势很明显,从1亿减到1,在我的设备上测试,用Go运行只需要50ms,Python可能需要接近100倍的时间。
但是,这种写法也有缺点:实在太麻烦了,大大增加了整个项目的耦合性。
那Python中有没有办法不通过打包成动态链接库的方法,用Python调度Go的任务呢?答案是Go celery.
https://github.com/gocelery/gocelery
我们可以用Go写一个计算密集型任务的Worker,然后用Python的Celery beat来调度这个Worker,下面给大家演示一下:
1.编写Go Worker
最好是将计算密集型的任务改造成Go语言版的,这样收益才能最大化。
比如这里,我使用的是上回从1亿减到1的老梗。
// 文件名: main.go
// Python实用宝典
package main
import (
"fmt"
"time"
"github.com/gocelery/gocelery"
"github.com/gomodule/redigo/redis"
)
func minus() {
start := time.Now()
decrement(100000000)
fmt.Println(time.Since(start))
}
func decrement(n int) {
for n > 0 {
n -= 1
}
}
func main() {
// create redis connection pool
redisPool := &redis.Pool{
MaxIdle: 3, // maximum number of idle connections in the pool
MaxActive: 0, // maximum number of connections allocated by the pool at a given time
IdleTimeout: 240 * time.Second, // close connections after remaining idle for this duration
Dial: func() (redis.Conn, error) {
c, err := redis.DialURL("redis://")
if err != nil {
return nil, err
}
return c, err
},
TestOnBorrow: func(c redis.Conn, t time.Time) error {
_, err := c.Do("PING")
return err
},
}
// initialize celery client
cli, _ := gocelery.NewCeleryClient(
gocelery.NewRedisBroker(redisPool),
&gocelery.RedisCeleryBackend{Pool: redisPool},
5, // number of workers
)
// register task
cli.Register("go_tasks.minus", minus)
// start workers (non-blocking call)
cli.StartWorker()
// wait for client request
time.Sleep(1000 * time.Second)
// stop workers gracefully (blocking call)
cli.StopWorker()
}
输入命令:
即可运行该worker
2.编写Python客户端
# 文件名: go_tasks.py
# Python实用宝典
from celery import Celery
app = Celery('go_tasks',broker='redis://127.0.0.1:6379')
app.conf.update(
CELERY_TASK_SERIALIZER='json',
CELERY_ACCEPT_CONTENT=['json'], # Ignore other content
CELERY_RESULT_SERIALIZER='json',
CELERY_ENABLE_UTC=True,
CELERY_TASK_PROTOCOL=1,
)
@app.on_after_configure.connect
def setup_periodic_tasks(sender, **kwargs):
# 每5秒调度一次1亿减到1,不过不跑Python worker,
# 由于Go Worker在运行,这里的minus会被Go Worker消费。
sender.add_periodic_task(5.0, minus.s())
@app.task
def minus():
x = 100000000
while x > 1:
x = x-1
每5秒调度一次1亿减到1,不过不跑Python worker. 由于Go Worker在运行,这里的minus会被Go Worker消费。
另外请注意,这里的minus函数实际上只是为了能被识别到而编写的,其内容毫无意义,直接写个pass都没问题(因为实际上是Go Worker在消费)。
编写完后,针对go_tasks模块启动beat:
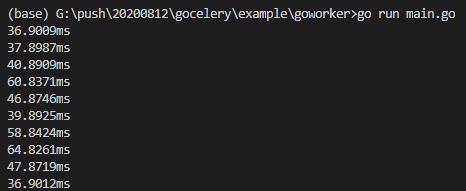
此时,调度器就会调度Go Worker执行任务:
可以看到,我们成功用Python的Celery Beat调度了Go写的Worker!可喜可贺。
接下来可以看看如果单纯用Python的Worker做这样的计算是有多耗时:
# 文件名: python_tasks
# Python实用宝典
from celery import Celery
app = Celery('python_tasks')
@app.on_after_configure.connect
def setup_periodic_tasks(sender, **kwargs):
sender.add_periodic_task(1.0, minus.s())
@app.task
def minus():
x = 100000000
while x > 1:
x = x-1
启动worker:
celery worker -A python_tasks -l info --pool=eventlet 启动beat调度器:
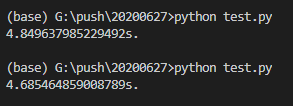
celery -A python_tasks beat 结果如下:
可以看到,Python从1亿减到1平均需要5.2秒左右的时间,和Go版相差了100倍左右。
如果我们将调度器的频率提高到每秒计算1次,Python版的Worker,其任务队列一定会堵塞,因为Worker消费能力不够强大。相比之下,Go版的Worker可就非常给力了。
因此,如果你的项目中有这种计算密集型的任务,可以尝试将其提取成Go版本试试,说不定有惊喜呢。
我们的文章到此就结束啦,如果你喜欢今天的Python 实战教程 ,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群 ,回答相应验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
Python实用宝典 (pythondict.com )