from datetime import datetime
from pydantic import BaseModel
class User(BaseModel):
id: int
name = 'John Doe'
signup_ts: datetime = None
m = User.parse_raw('{"id": 123, "name": "James"}')
print(m)
#> id=123 signup_ts=None name='James'
此外,它能直接将ORM的对象输入,转为Pydantic的对象,比如从Sqlalchemy ORM:
from typing import List
from sqlalchemy import Column, Integer, String
from sqlalchemy.dialects.postgresql import ARRAY
from sqlalchemy.ext.declarative import declarative_base
from pydantic import BaseModel, constr
Base = declarative_base()
class CompanyOrm(Base):
__tablename__ = 'companies'
id = Column(Integer, primary_key=True, nullable=False)
public_key = Column(String(20), index=True, nullable=False, unique=True)
name = Column(String(63), unique=True)
domains = Column(ARRAY(String(255)))
class CompanyModel(BaseModel):
id: int
public_key: constr(max_length=20)
name: constr(max_length=63)
domains: List[constr(max_length=255)]
class Config:
orm_mode = True
co_orm = CompanyOrm(
id=123,
public_key='foobar',
name='Testing',
domains=['example.com', 'foobar.com'],
)
print(co_orm)
#> <models_orm_mode.CompanyOrm object at 0x7f0bdac44850>
co_model = CompanyModel.from_orm(co_orm)
print(co_model)
#> id=123 public_key='foobar' name='Testing' domains=['example.com',
#> 'foobar.com']
从Json文件导入:
from datetime import datetime
from pathlib import Path
from pydantic import BaseModel
class User(BaseModel):
id: int
name = 'John Doe'
signup_ts: datetime = None
path = Path('data.json')
path.write_text('{"id": 123, "name": "James"}')
m = User.parse_file(path)
print(m)
from pydantic import BaseModel, ValidationError, validator
class UserModel(BaseModel):
name: str
username: str
password1: str
password2: str
@validator('name')
def name_must_contain_space(cls, v):
if ' ' not in v:
raise ValueError('must contain a space')
return v.title()
@validator('password2')
def passwords_match(cls, v, values, **kwargs):
if 'password1' in values and v != values['password1']:
raise ValueError('passwords do not match')
return v
@validator('username')
def username_alphanumeric(cls, v):
assert v.isalnum(), 'must be alphanumeric'
return v
上面,我们增加了三种自定义校验逻辑:
1.name 必须带有空格
2.password2 必须和 password1 相同
3.username 必须为字母
让我们试试这三个校验是否成功实现:
user = UserModel(
name='samuel colvin',
username='scolvin',
password1='zxcvbn',
password2='zxcvbn',
)
print(user)
#> name='Samuel Colvin' username='scolvin' password1='zxcvbn' password2='zxcvbn'
try:
UserModel(
name='samuel',
username='scolvin',
password1='zxcvbn',
password2='zxcvbn2',
)
except ValidationError as e:
print(e)
"""
2 validation errors for UserModel
name
must contain a space (type=value_error)
password2
passwords do not match (type=value_error)
"""
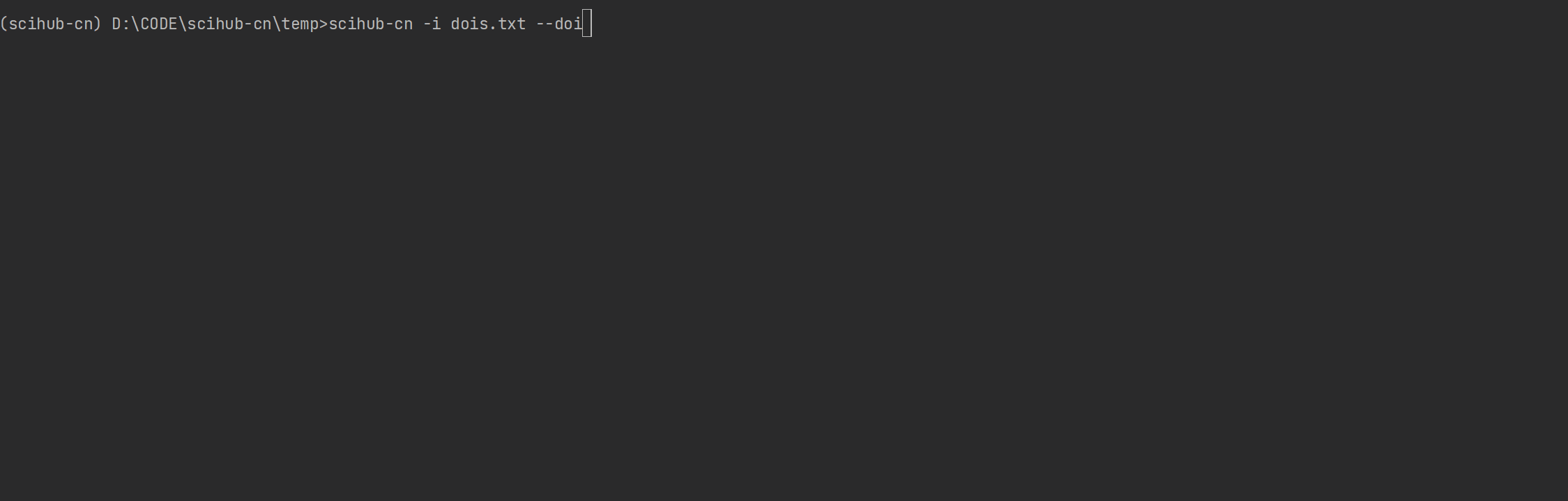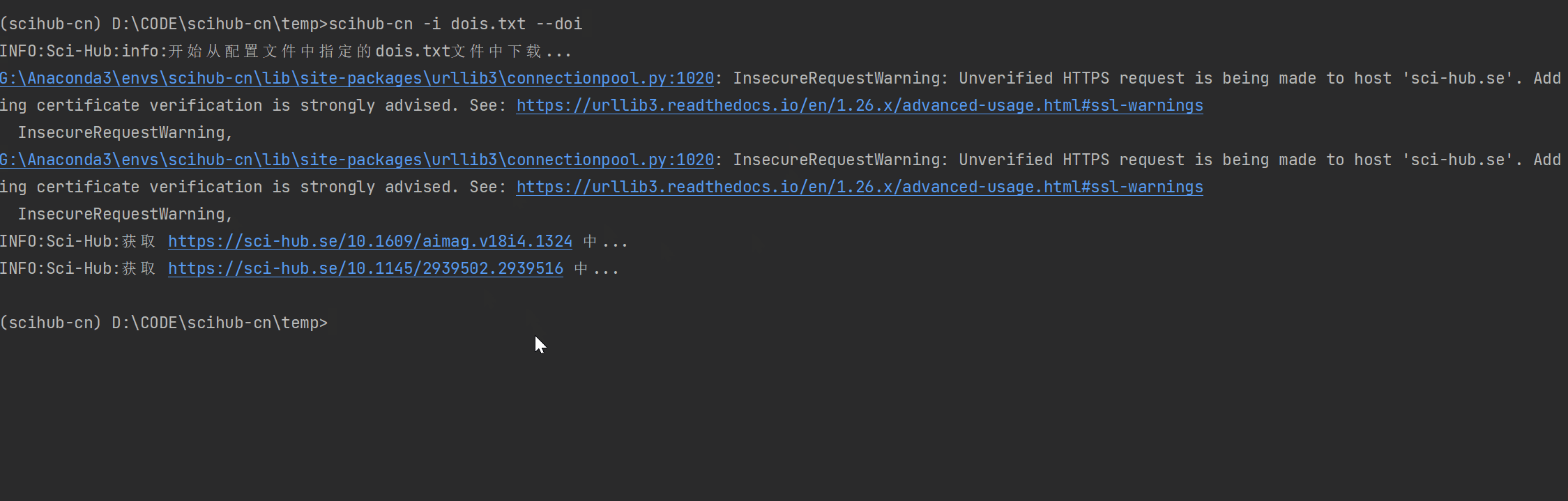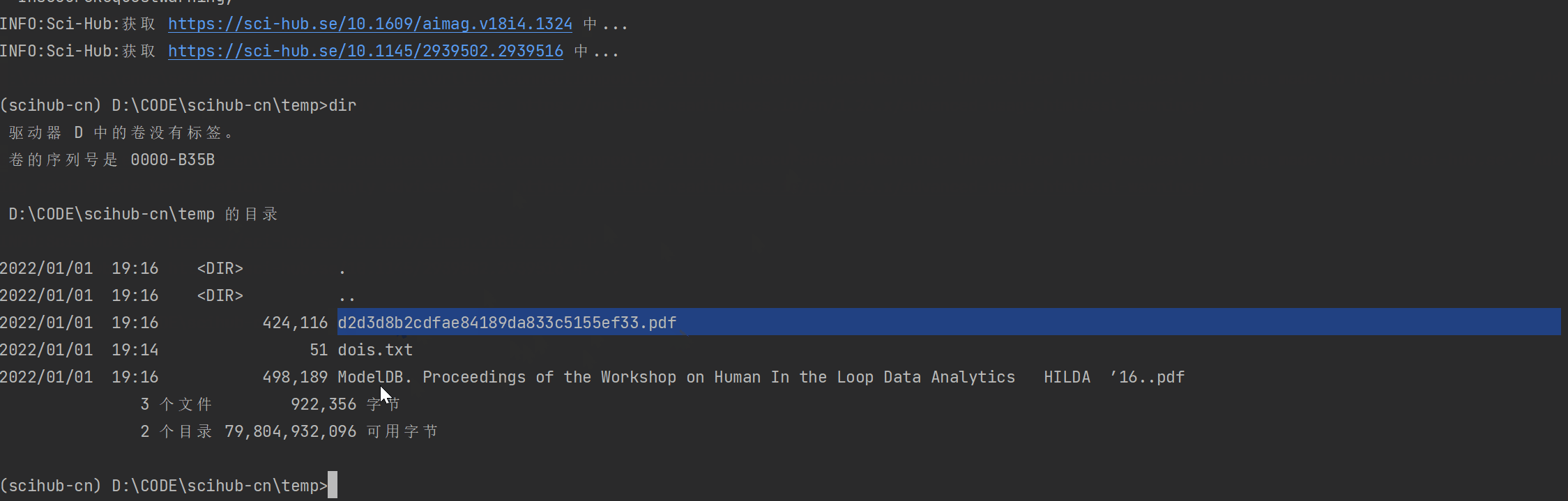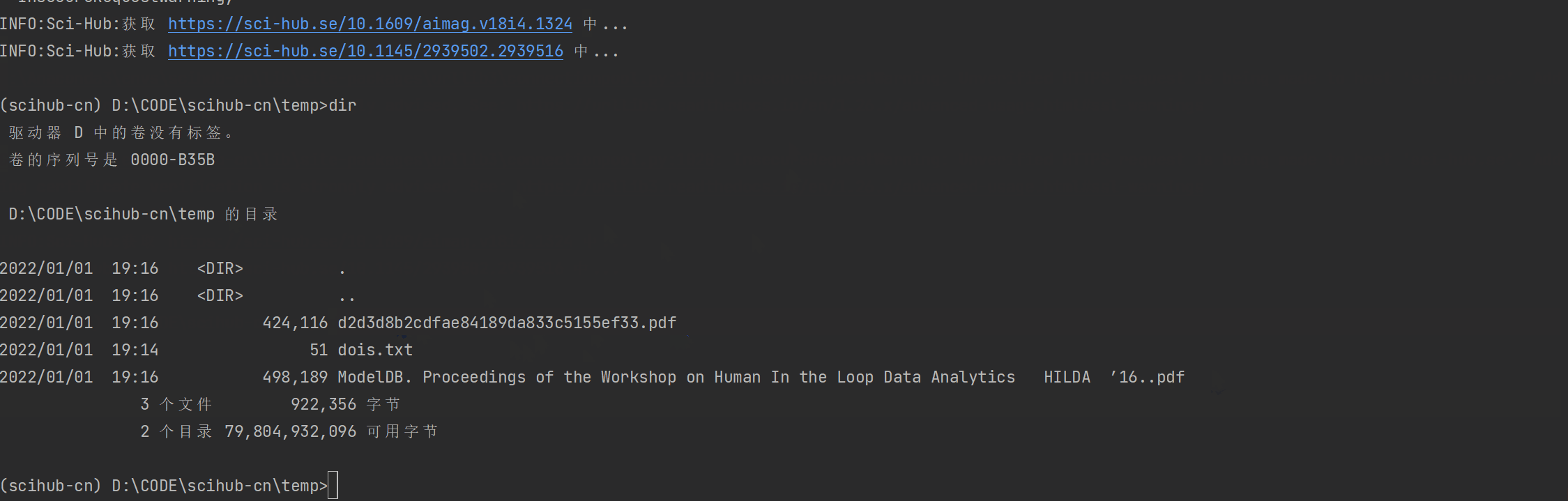
$scihub-cn --help
... ...
optional arguments:
-h, --help show this help message and exit
-u URL input the download url
-d DOI input the download doi
--input INPUTFILE, -i INPUTFILE
input download file
-w WORDS, --words WORDS
download from some key words,keywords are linked by
_,like machine_learning.
--title download from paper titles file
-p PROXY, --proxy PROXY
use proxy to download papers
--output OUTPUT, -o OUTPUT
setting output path
--doi download paper from dois file
--bib download papers from bibtex file
--url download paper from url file
-e SEARCH_ENGINE, --engine SEARCH_ENGINE
set the search engine
-l LIMIT, --limit LIMIT
limit the number of search result