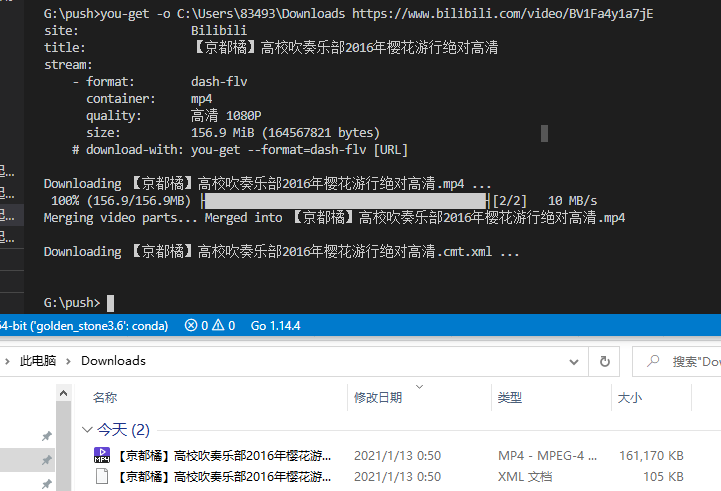
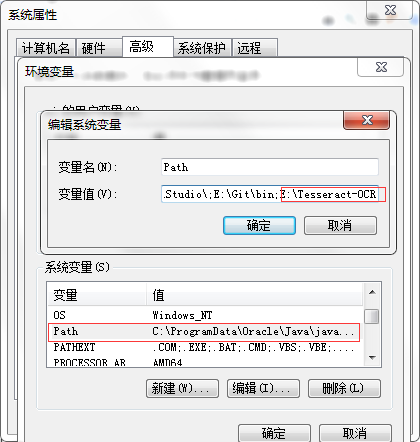
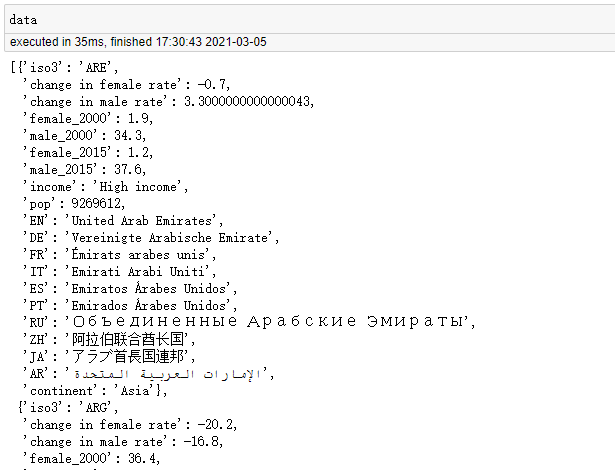
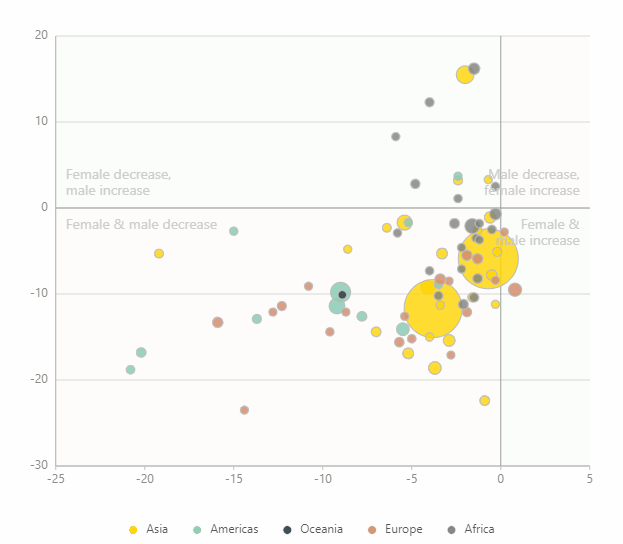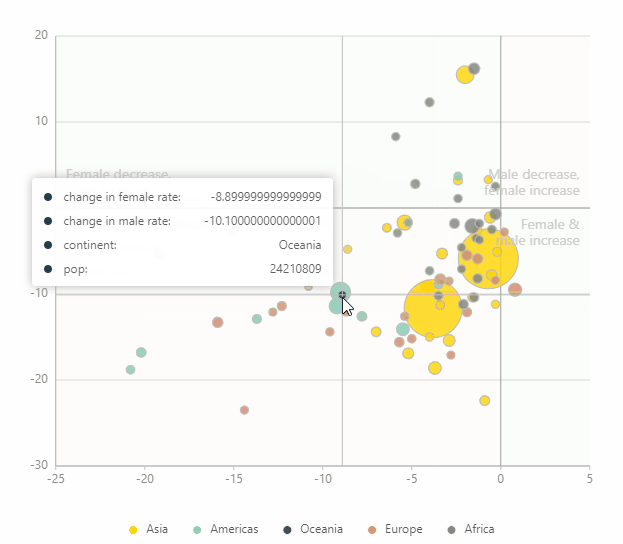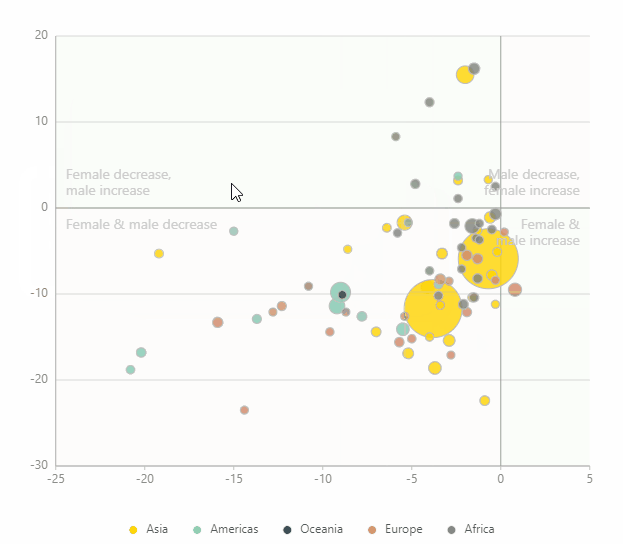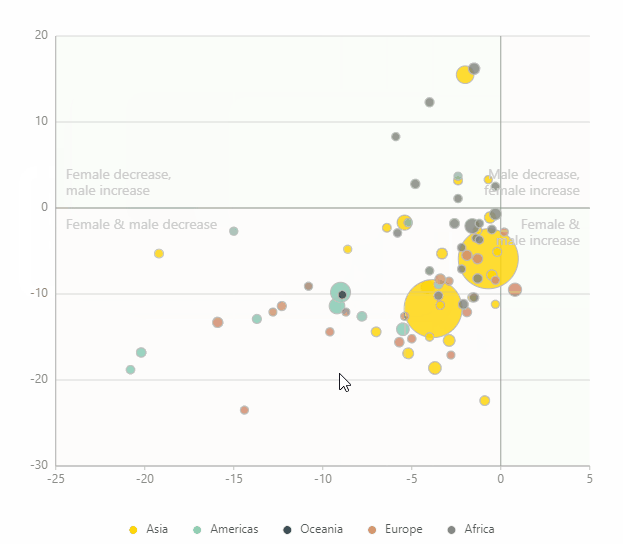
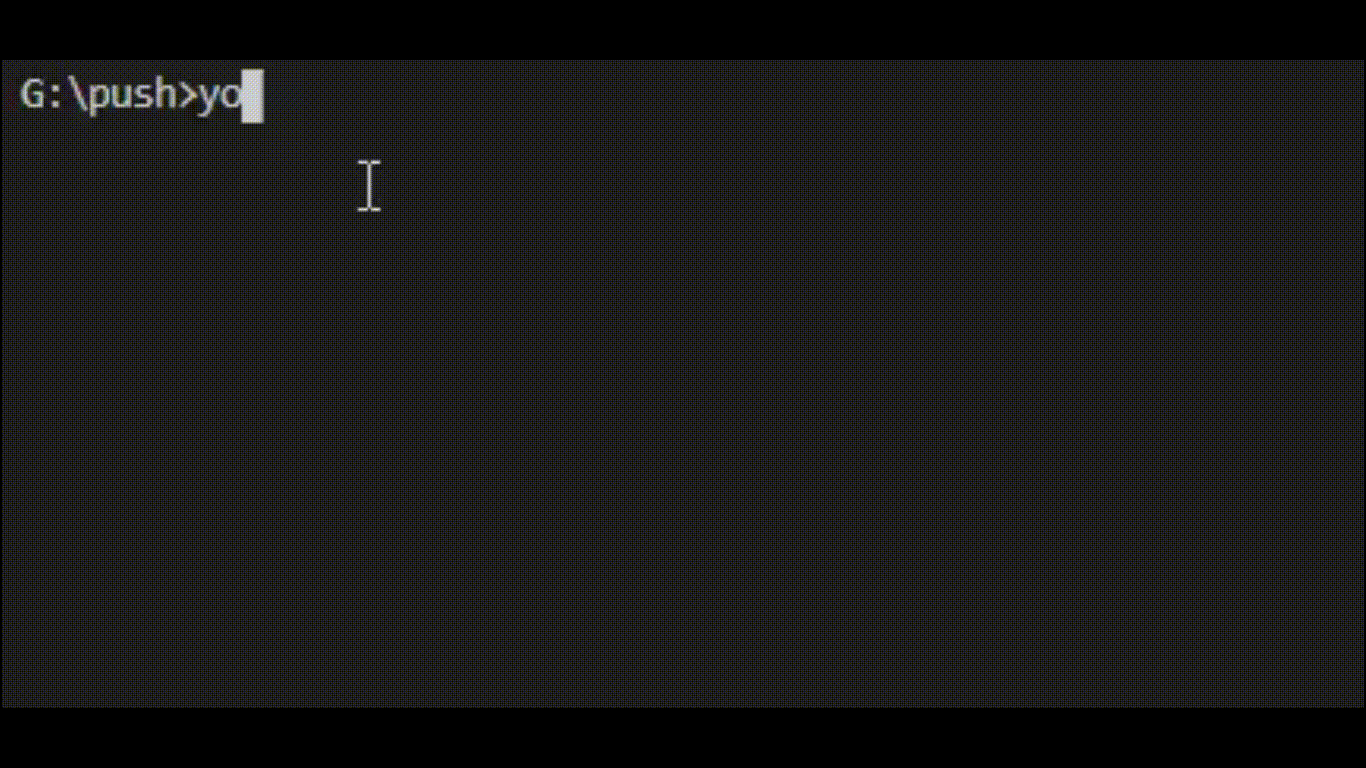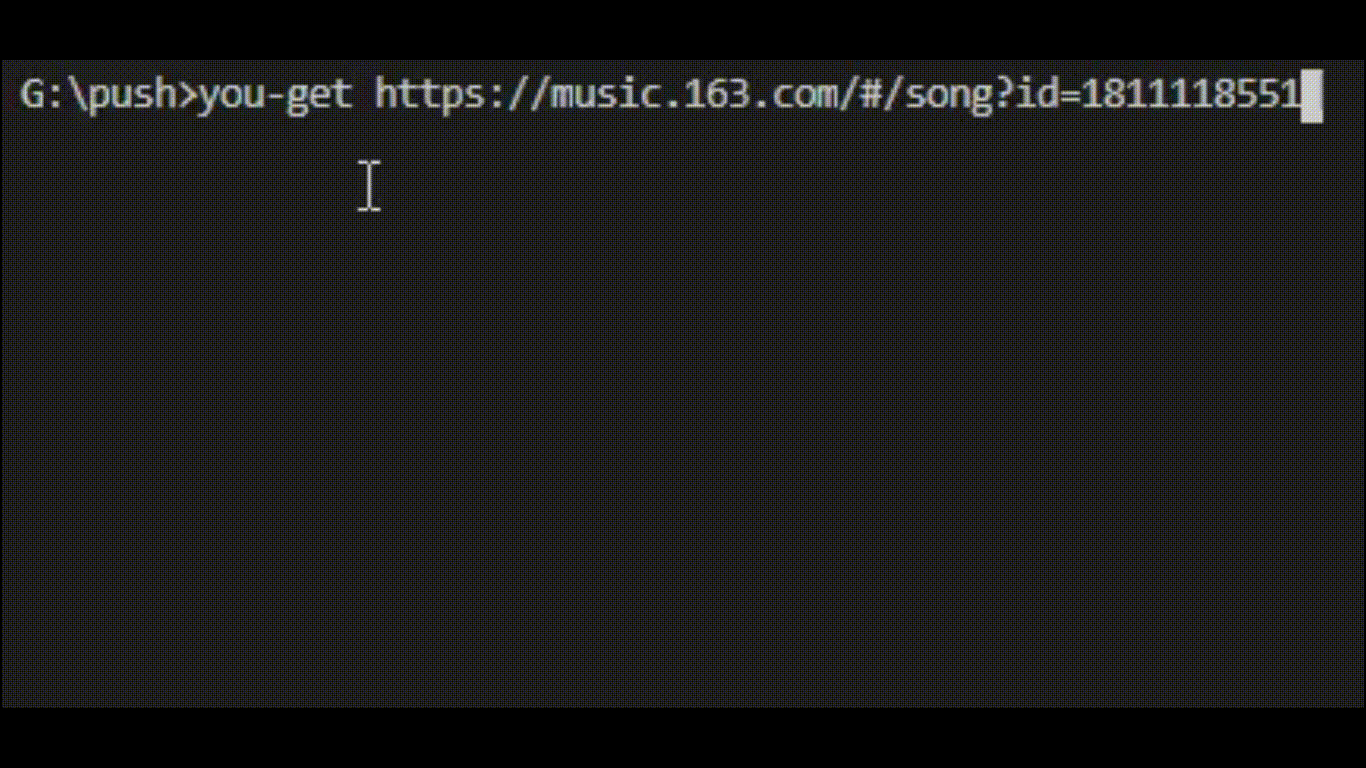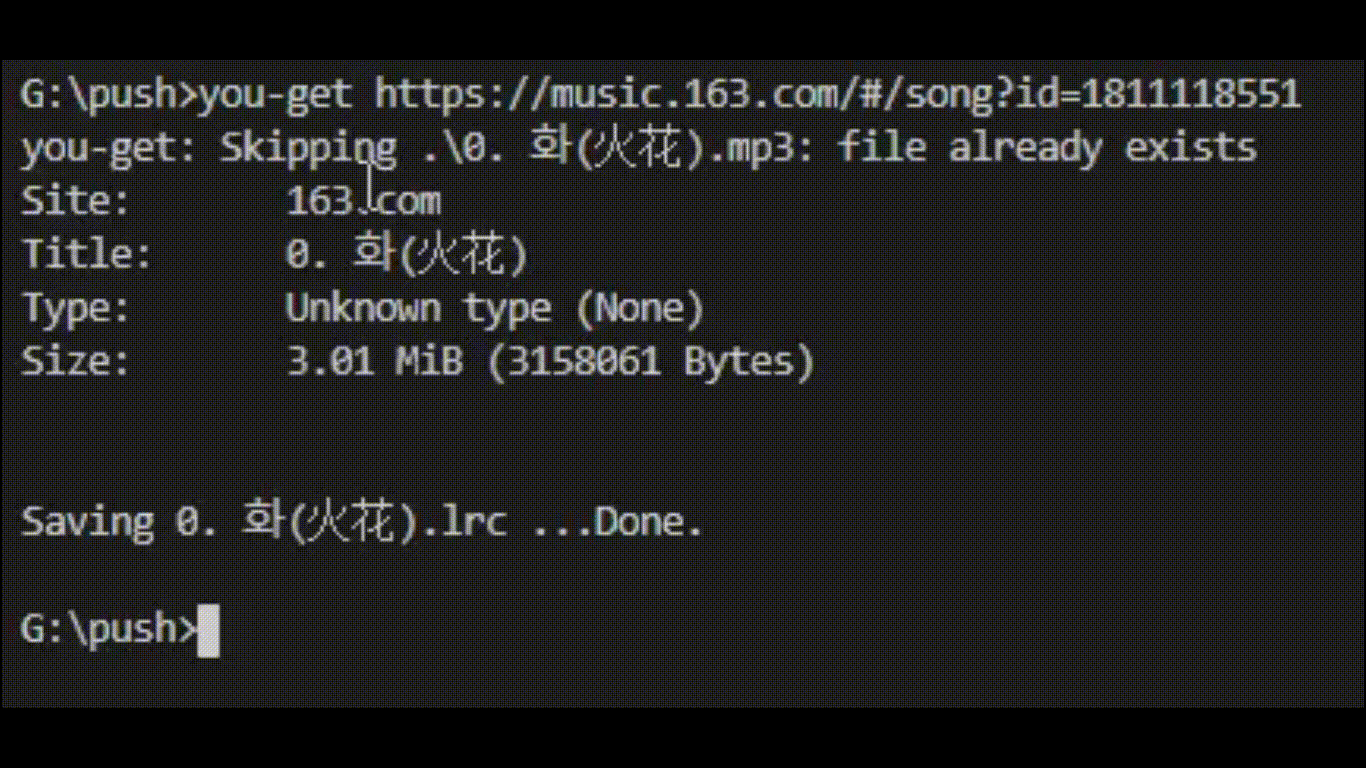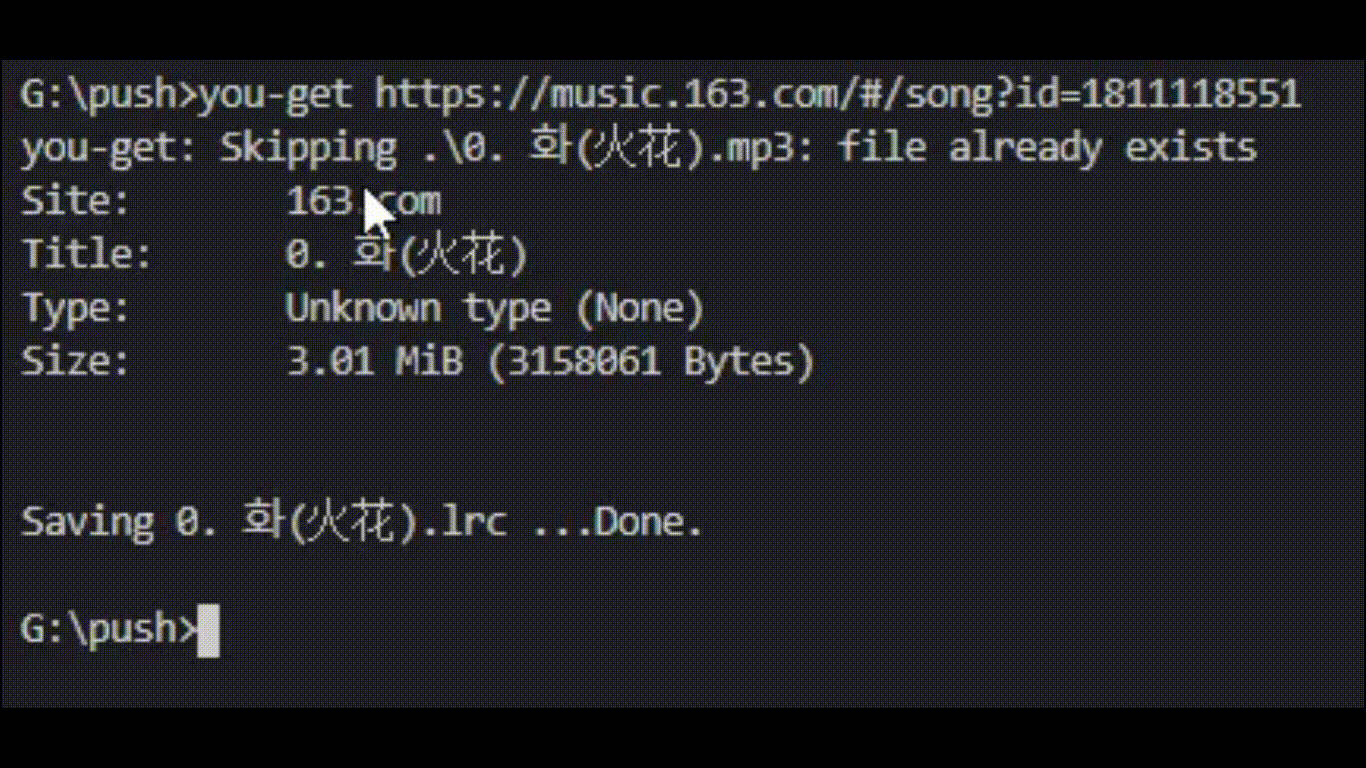通用安装方法(可在Windows,Mac OS X,Linux等上运行,并且始终提供最新版本)是使用pip:
# Make sure we have an up-to-date version of pip and setuptools:
$ python -m pip install --upgrade pip setuptools
$ python -m pip install --upgrade httpie
$ you-get 'https://www.youtube.com/watch?v=jNQXAC9IVRw'
site: YouTube
title: Me at the zoo
stream:
- itag: 43
container: webm
quality: medium
size: 0.5 MiB (564215 bytes)
# download-with: you-get --itag=43 [URL]
Downloading Me at the zoo.webm ...
100% ( 0.5/ 0.5MB) ├██████████████████████████████████┤[1/1] 6 MB/s
Saving Me at the zoo.en.srt ... Done.
$ you-get 'https://www.youtube.com/watch?v=jNQXAC9IVRw'
site: YouTube
title: Me at the zoo
stream:
- itag: 242
container: webm
quality: 320x240
size: 0.6 MiB (618358 bytes)
# download-with: you-get --itag=242 [URL]
Downloading Me at the zoo.webm ...
100% ( 0.6/ 0.6MB) ├██████████████████████████████████████████████████████████████████████████████┤[2/2] 2 MB/s
Merging video parts... Merged into Me at the zoo.webm
Saving Me at the zoo.en.srt ... Done.
>>> x = {"key1": "value1 from x", "key2": "value2 from x"}
>>> y = {"key2": "value2 from y", "key3": "value3 from y"}
>>> x | y
{'key1': 'value1 from x', 'key2': 'value2 from y', 'key3': 'value3 from y'}
>>> y | x
{'key2': 'value2 from x', 'key3': 'value3 from y', 'key1': 'value1 from x'}
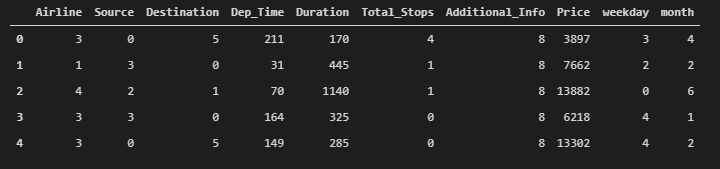
from sklearn.preprocessing import LabelEncoder
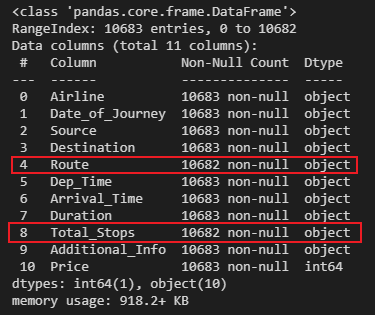
var_mod = ['Airline','Source','Destination','Additional_Info','Total_Stops','weekday','month','Dep_Time']
le = LabelEncoder()
for i in var_mod:
flights[i] = le.fit_transform(flights[i])
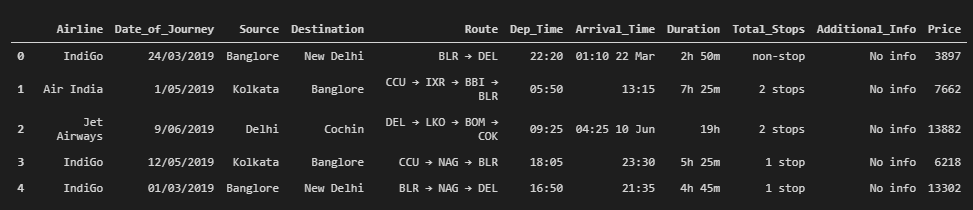
flights.head()
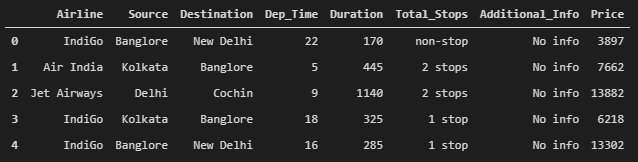
对每列数据进行特征缩放,提取自变量(x)和因变量(y):
flights.corr()
def outlier(df):
for i in df.describe().columns:
Q1=df.describe().at['25%',i]
Q3=df.describe().at['75%',i]
IQR= Q3-Q1
LE=Q1-1.5*IQR
UE=Q3+1.5*IQR
df[i]=df[i].mask(df[i]<LE,LE)
df[i]=df[i].mask(df[i]>UE,UE)
return df
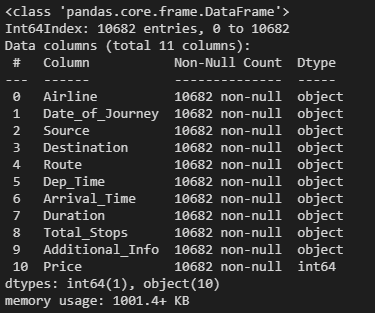
flights = outlier(flights)
x = flights.drop('Price',axis=1)
y = flights['Price']
划分测试集和训练集:
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=101)
4.2 模型训练及测试
使用随机森林进行模型训练:
from sklearn.ensemble import RandomForestRegressor
rfr=RandomForestRegressor(n_estimators=100)
rfr.fit(x_train,y_train)