from functools import reduce
data = [{"a": 1}, {"a": 1}, {"a": 3}, {"b": 4}]
result = []
def unduplicate(result, data):
if data not in result:
result = result + [data]
return result
for i in data:
result = unduplicate(result, i)
>>> result
>>> [{'a': 1}, {'a': 3}, {'b': 4}]
稍显复杂,如果使用reduce函数和lambda函数,代码能简化很多:
def delete_duplicate(data):
func = lambda x, y: x + [y] if y not in x else x
data = reduce(func, [[], ] + data)
return data
>>> delete_duplicate(data)
>>> [{'a': 1}, {'a': 3}, {'b': 4}]
当然, 我也能一行写完这个功能:
data = reduce(lambda x, y: x + [y] if y not in x else x, [[], ] + data)
只不过有可能会被打死在工位上,所以不建议这么干。
2.奇怪的技巧
就如文章开头提到的,字典之所以不能用set去重,是因为它是可变对象。
但是…如果我们把它变成不可变对象呢?
data = [{"a": 1}, {"a": 1}, {"a": 3}, {"b": 4}]
def delete_duplicate(data):
immutable_dict = set([str(item) for item in data])
data = [eval(i) for i in immutable_dict]
return data
>>> delete_duplicate(data)
>>> [{'a': 1}, {'a': 3}, {'b': 4}]
没错,这能成。
1.遍历字典,将每个子项变成字符串存放到数组中,再通过set函数去重。
2.通过eval函数,将去重后的数组里的每个子项重新转化回字典。
如此Python,怎能不好玩?
3.高效的方式
上面讲了两种骚操作,其实都不太建议在实际工作中使用。
一个原因是真的太骚了,怕被打趴在工位上。
另一个原因是,它们在应对较大数据量的时候,性能不太行。
下面是最正统的方式:
data = [dict(t) for t in set([tuple(d.items()) for d in data])]
>>>data
>>>[{'a': 1}, {'b': 2}]
data2 = [{"a": {"b": "c"}}, {"a": {"b": "c"}}]
def delete_duplicate_str(data):
immutable_dict = set([str(item) for item in data])
data = [eval(i) for i in immutable_dict]
return data
print(delete_duplicate_str(data2))
>>> [{'a': {'b': 'c'}}]
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
# 显示等待打开主页面
wait = WebDriverWait(driver, 10, 0.5)
# 切换到对应的iframe,否则无法操作内部元素
wait.until(
EC.frame_to_be_available_and_switch_to_it(driver.find_element_by_xpath('//iframe[contains(@id,"x-URS-iframe")]')))
# 找一个登录成功的页面元素
# 通过元素属性+元素值来唯一定位元素
result = True
try:
element_recy_email = wait.until(EC.element_to_be_clickable((By.XPATH, '//span[@class="oz0" and contains(text(),"收 信")]')))
if element_recy_email:
result = True
else:
result = False
except Exception as e:
result = False
print("邮箱登陆成功" if result else "邮箱登录失败")
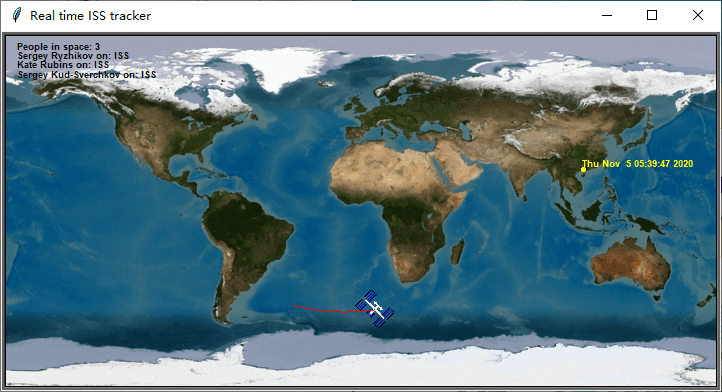
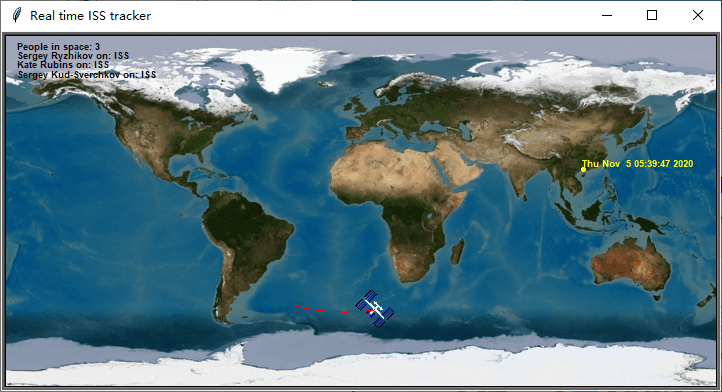
while True:
location = ISS_Info.iss_current_loc()
lat = location['iss_position']['latitude']
lon = location['iss_position']['longitude']
print("Position: \n latitude: {}, longitude: {}".format(lat,lon))
pos = iss.pos()
posx = iss.xcor()
if iss.xcor() >= (179.1): ### Stop drawing at the right edge of
iss.penup() ### the screen to avoid a
iss.goto(float(lon),float(lat)) ### horizontal wrap round line
time.sleep(5)
else:
iss.goto(float(lon),float(lat))
iss.pendown()
time.sleep(5)
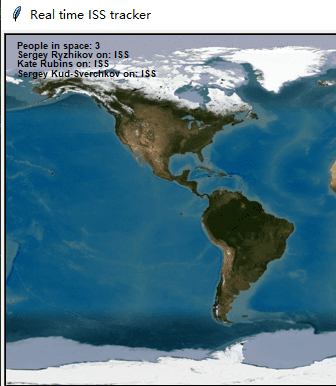
我们还可以标出自己目前所处的位置,以查看和国际空间站的距离及空间站经过你上空的时间点(UTC)。
# 深圳
lat = 112.5118928
lon = 23.8534489
prediction = turtle.Turtle()
prediction.penup()
prediction.color('yellow')
prediction.goto(lat, lon)
prediction.dot(5)
prediction.hideturtle()
url = 'http://api.open-notify.org/iss-pass.json?lat=' +str(lat-90) + '&lon=' + str(lon)
response = urllib.request.urlopen(url)
result = json.loads(response.read())
over = result ['response'][1]['risetime']
prediction.write(time.ctime(over), font=style)
因此http协议创始人警告我们这些凡人们正在错误的使用http协议,除了警告,他还发表了一篇博客,大概意思就是教大家如何正确使用http协议,如何正确定义url,这就是REST(Representational State Transfer),不需要管这几个英文单词代表什么意思,只需要记住下面一句话:
用url唯一定位资源,用Http请求方式(GET, POST, DELETE, PUT)描述用户行为
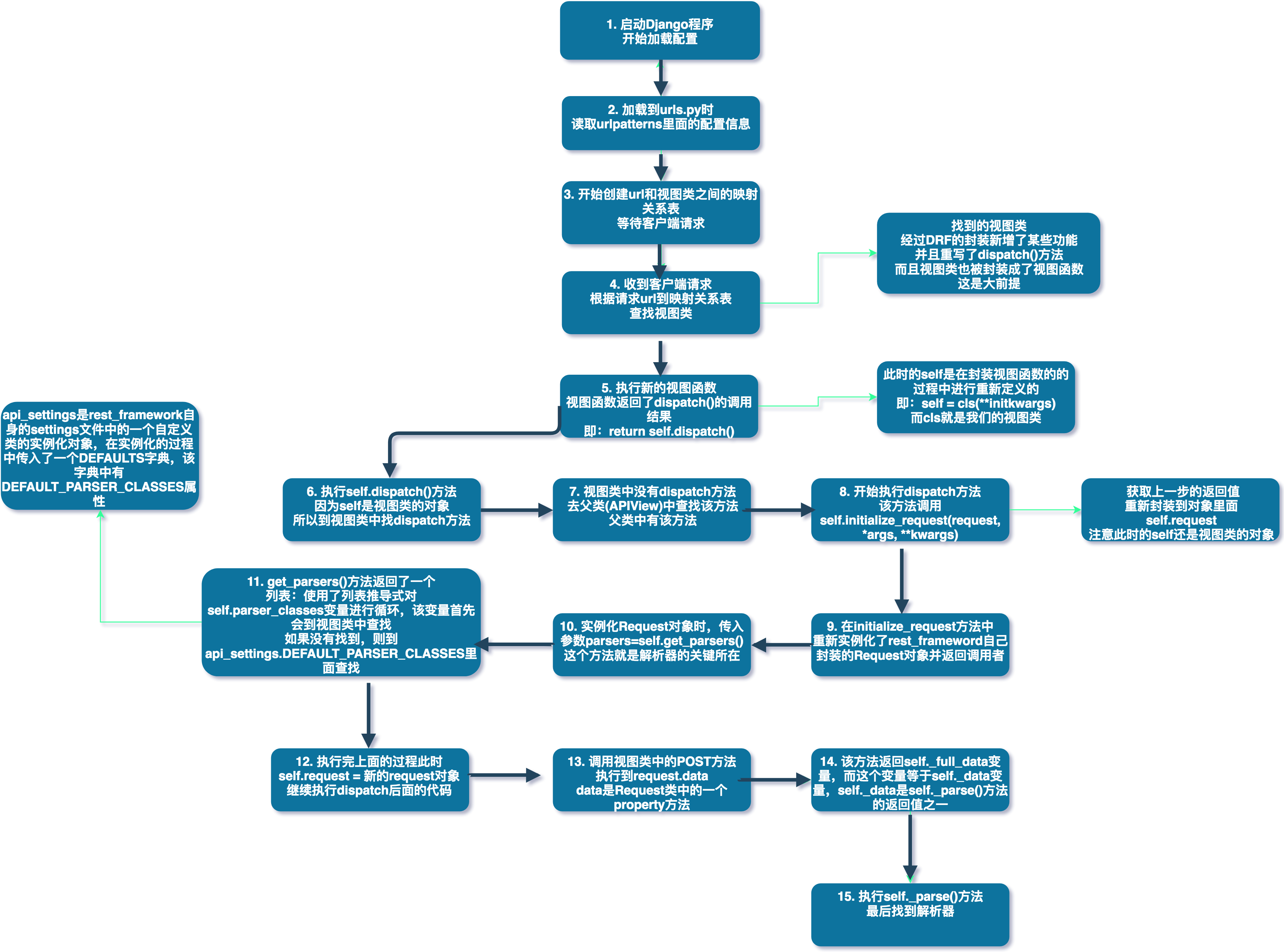
按照之前的方式,我们使用request.POST, 如果打印该值,会发现是一个空对象:request post <QueryDict: {}>,该现象证明Django并不能处理请求协议为application/json编码协议的数据,我们可以去看看request源码,可以看到下面这一段:
if self.content_type == 'multipart/form-data':
if hasattr(self, '_body'):
# Use already read data
data = BytesIO(self._body)
else:
data = self
try:
self._post, self._files = self.parse_file_upload(self.META, data)
except MultiPartParserError:
# An error occurred while parsing POST data. Since when
# formatting the error the request handler might access
# self.POST, set self._post and self._file to prevent
# attempts to parse POST data again.
# Mark that an error occurred. This allows self.__repr__ to
# be explicit about it instead of simply representing an
# empty POST
self._mark_post_parse_error()
raise
elif self.content_type == 'application/x-www-form-urlencoded':
self._post, self._files = QueryDict(self.body, encoding=self._encoding), MultiValueDict()
else:
self._post, self._files = QueryDict(encoding=self._encoding), MultiValueDict()
@classonlymethod
def as_view(cls, **initkwargs):
"""Main entry point for a request-response process."""
for key in initkwargs:
if key in cls.http_method_names:
raise TypeError("You tried to pass in the %s method name as a "
"keyword argument to %s(). Don't do that."
% (key, cls.__name__))
if not hasattr(cls, key):
raise TypeError("%s() received an invalid keyword %r. as_view "
"only accepts arguments that are already "
"attributes of the class." % (cls.__name__, key))
def view(request, *args, **kwargs):
self = cls(**initkwargs)
if hasattr(self, 'get') and not hasattr(self, 'head'):
self.head = self.get
self.request = request
self.args = args
self.kwargs = kwargs
return self.dispatch(request, *args, **kwargs)
view.view_class = cls
view.view_initkwargs = initkwargs
# take name and docstring from class
update_wrapper(view, cls, updated=())
# and possible attributes set by decorators
# like csrf_exempt from dispatch
update_wrapper(view, cls.dispatch, assigned=())
return view
@classonlymethod
def as_view(cls, **initkwargs):
"""Main entry point for a request-response process."""
for key in initkwargs:
if key in cls.http_method_names:
raise TypeError("You tried to pass in the %s method name as a "
"keyword argument to %s(). Don't do that."
% (key, cls.__name__))
if not hasattr(cls, key):
raise TypeError("%s() received an invalid keyword %r. as_view "
"only accepts arguments that are already "
"attributes of the class." % (cls.__name__, key))
def view(request, *args, **kwargs):
if request.content_type == "application/json":
import json
return HttpResponse(json.dumps({"error": "Unsupport content type!"}))
self = cls(**initkwargs)
if hasattr(self, 'get') and not hasattr(self, 'head'):
self.head = self.get
self.request = request
self.args = args
self.kwargs = kwargs
return self.dispatch(request, *args, **kwargs)
view.view_class = cls
view.view_initkwargs = initkwargs
# take name and docstring from class
update_wrapper(view, cls, updated=())
# and possible attributes set by decorators
# like csrf_exempt from dispatch
update_wrapper(view, cls.dispatch, assigned=())
return view
from __future__ import absolute_import, unicode_literals
from NBAsite.celery import app
from celery import shared_task
import time
@shared_task
def waste_time():
time.sleep(3)
return "Run function 'waste_time' finished."