翻译:Chinese 中文|Vietnamese Tiếng Việt|Spanish Español|Add translation
其他模式:Interactive|CLI
Python是一种设计精美的高级和基于解释器的编程语言,它为程序员提供了许多舒适的特性。但有时,Python代码片段的结果乍一看可能并不明显
下面是一个有趣的项目,它试图解释Python中一些违反直觉的代码片段和鲜为人知的功能背后到底发生了什么
虽然您在下面看到的一些示例可能不是真正意义上的WTF,但它们将揭示您可能不知道的Python的一些有趣部分。我发现这是学习编程语言内部的一个很好的方法,我相信您也会发现它很有趣!
如果您是一名经验丰富的Python程序员,那么您可以将其视为一次尝试就能正确完成大部分操作的挑战。你以前可能已经经历过其中的一些,我也许能唤起你甜蜜的旧回忆!😅
PS:如果你是回头客,你可以了解到新的修改here(标有星号的例子为最新一次主要修订中增加的例子)
所以,我们开始吧
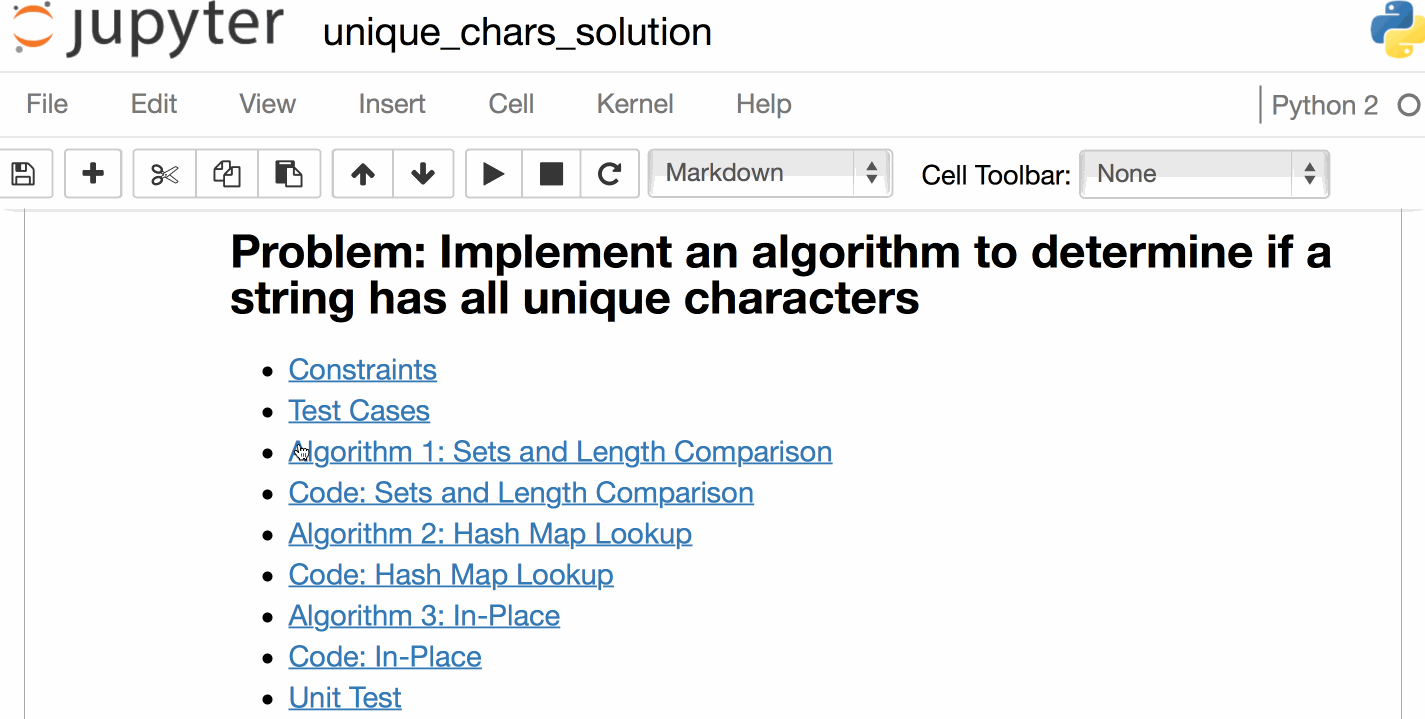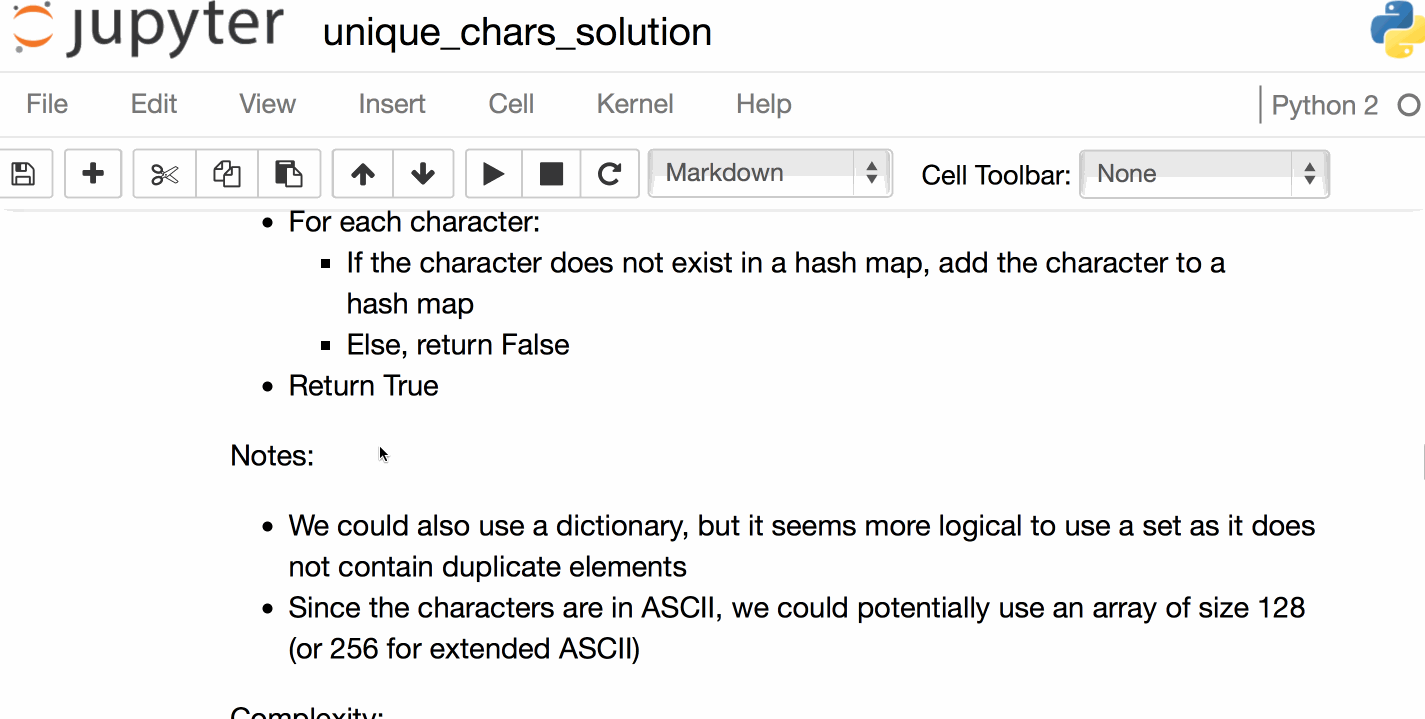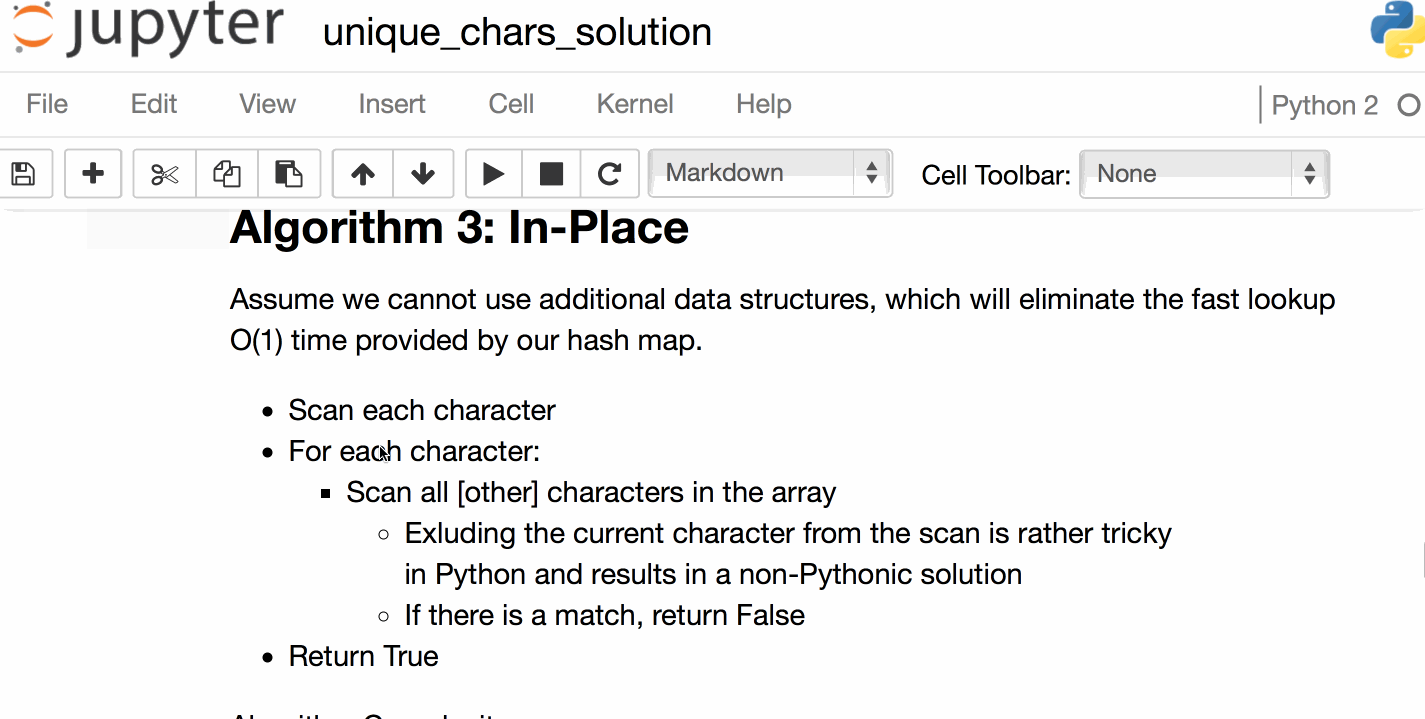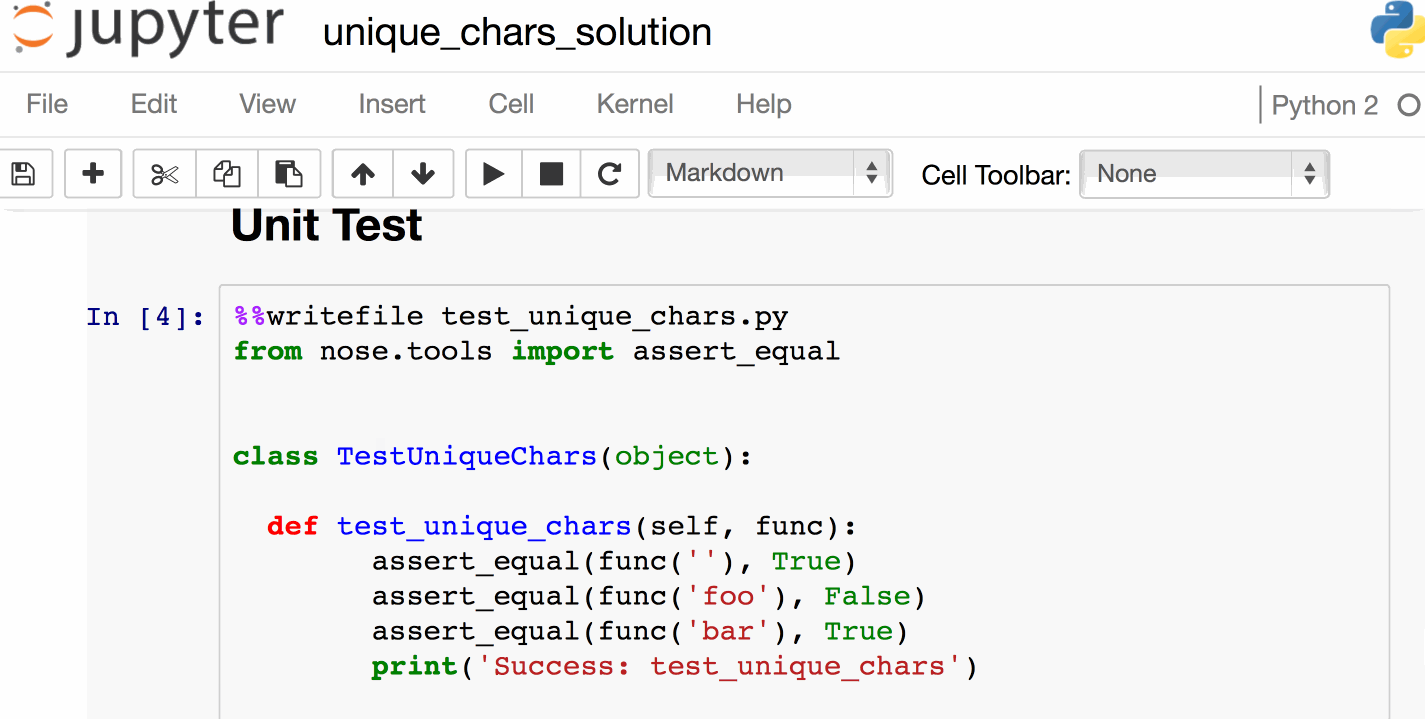
目录
示例的结构
所有示例的结构如下:
▶一些花哨的标题
# Set up the code.
# Preparation for the magic...
输出(Python版本):
>>> triggering_statement
Some unexpected output
(可选):一行描述意外输出
💡说明:
# Set up code
# More examples for further clarification (if necessary)
输出(Python版本):
>>> trigger # some example that makes it easy to unveil the magic
# some justified output
注:所有示例都在Python 3.5.2交互式解释器上进行了测试,除非在输出之前明确指定,否则它们应该适用于所有Python版本
用法
在我看来,最大限度地利用这些例子的一个很好的方法是按时间顺序阅读它们,并针对每个例子:
- 仔细阅读设置示例的初始代码。如果您是一名经验丰富的Python程序员,您将在大多数情况下成功预测接下来会发生什么
- 阅读输出片段,
- 检查输出是否与您预期的相同
- 如果您知道输出背后的确切原因,请确保它是这样的
- 如果答案是否定的(这完全没问题),深呼吸,然后阅读解释(如果你仍然不明白,就大声喊出来!)然后制造一个问题here)
- 如果是,轻轻拍一下你的背,你就可以跳到下一个例子了
PS:您也可以在命令行中使用pypi package,
$ pip install wtfpython -U
$ wtfpython
👀示例
部分:开动脑筋!
▶当务之急!*
由于某些原因,Python3.8的“Walrus”运算符(:=)已经变得相当流行了。我们去看看吧,
1个
# Python version 3.8+
>>> a = "wtf_walrus"
>>> a
'wtf_walrus'
>>> a := "wtf_walrus"
File "<stdin>", line 1
a := "wtf_walrus"
^
SyntaxError: invalid syntax
>>> (a := "wtf_walrus") # This works though
'wtf_walrus'
>>> a
'wtf_walrus'
2个
# Python version 3.8+
>>> a = 6, 9
>>> a
(6, 9)
>>> (a := 6, 9)
(6, 9)
>>> a
6
>>> a, b = 6, 9 # Typical unpacking
>>> a, b
(6, 9)
>>> (a, b = 16, 19) # Oops
File "<stdin>", line 1
(a, b = 16, 19)
^
SyntaxError: invalid syntax
>>> (a, b := 16, 19) # This prints out a weird 3-tuple
(6, 16, 19)
>>> a # a is still unchanged?
6
>>> b
16
💡解释
海象操作员快速刷新器
海象操作员(:=)是在Python3.8中引入的,因此在需要为表达式中的变量赋值的情况下会很有用
def some_func():
# Assume some expensive computation here
# time.sleep(1000)
return 5
# So instead of,
if some_func():
print(some_func()) # Which is bad practice since computation is happening twice
# or
a = some_func()
if a:
print(a)
# Now you can concisely write
if a := some_func():
print(a)
输出(>3.8):
这节省了一行代码,并且隐式地阻止了调用some_func两次
- 不带括号的“赋值表达式”(使用walrus运算符)在顶层受到限制,因此
SyntaxError在a := "wtf_walrus"第一个代码段的语句。加上括号后,它按预期工作并分配给a
- 与往常一样,包含以下内容的表达式的括号
=不允许使用操作员。因此,中的语法错误(a, b = 6, 9)
- Walrus运算符的语法为
NAME:= expr,在哪里NAME是有效的标识符,并且expr是有效的表达式。因此,不支持迭代打包和解包,这意味着,
(a := 6, 9)相当于((a := 6), 9)最终(a, 9) (其中a的值为6‘)
>>> (a := 6, 9) == ((a := 6), 9)
True
>>> x = (a := 696, 9)
>>> x
(696, 9)
>>> x[0] is a # Both reference same memory location
True
- 同样,
(a, b := 16, 19)相当于(a, (b := 16), 19)它只不过是一个3元组
▶字符串有时可能很棘手
1个
>>> a = "some_string"
>>> id(a)
140420665652016
>>> id("some" + "_" + "string") # Notice that both the ids are same.
140420665652016
2个
>>> a = "wtf"
>>> b = "wtf"
>>> a is b
True
>>> a = "wtf!"
>>> b = "wtf!"
>>> a is b
False
3个
>>> a, b = "wtf!", "wtf!"
>>> a is b # All versions except 3.7.x
True
>>> a = "wtf!"; b = "wtf!"
>>> a is b # This will print True or False depending on where you're invoking it (python shell / ipython / as a script)
False
# This time in file some_file.py
a = "wtf!"
b = "wtf!"
print(a is b)
# prints True when the module is invoked!
4.
输出(<Python3.7)
>>> 'a' * 20 is 'aaaaaaaaaaaaaaaaaaaa'
True
>>> 'a' * 21 is 'aaaaaaaaaaaaaaaaaaaaa'
False
很有道理,对吧?
💡说明:
- 第一个和第二个代码段中的行为是由于CPython优化(称为字符串插入),在某些情况下会尝试使用现有的不可变对象,而不是每次都创建新对象
- 在“内嵌”之后,许多变量可能会在内存中引用相同的字符串对象(从而节省内存)
- 在上面的代码片断中,字符串是隐式驻留的。何时隐式内嵌字符串的决定取决于实现。有一些规则可用于猜测字符串是否会被扣留:
- 所有长度为0和长度1的字符串都会被插入
- 字符串在编译时驻留(
'wtf'会被拘留,但是''.join(['w', 't', 'f'])不会被拘留)
- 不包含由ASCII字母、数字或下划线组成的字符串。这就解释了为什么
'wtf!'没有被拘留是因为!可以找到此规则的CPython实现here

- 什么时候
a和b设置为"wtf!"在同一行中,Python解释器创建一个新对象,然后同时引用第二个变量。如果您在单独的行上执行,它不会“知道”已经有"wtf!"作为对象(因为"wtf!"根据上述事实,未被默示拘留)。它是编译时优化。此优化不适用于CPython的3.7.x版本(选中此选项issue有关更多讨论,请参见)
- 在像IPython这样的交互式环境中,编译单元由单个语句组成,而如果是模块,则由整个模块组成。
a, b = "wtf!", "wtf!"是单个语句,而a = "wtf!"; b = "wtf!"是一行中的两个语句。这就解释了为什么a = "wtf!"; b = "wtf!",并解释为什么它们在中调用时是相同的some_file.py
- 第四个代码段的输出突然更改是由于peephole optimization一种称为恒定折叠的技术。这意味着表达式
'a'*20被替换为'aaaaaaaaaaaaaaaaaaaa'以在运行时节省几个时钟周期。常量折叠仅发生在长度小于21的字符串中。(为什么?想象一下……的大小.pyc作为表达式的结果生成的文件'a'*10**10)。Here’s相同的实现源
- 注意:在Python3.7中,常量折叠从窥视优化器移到了新的AST优化器,但在逻辑上也做了一些更改,因此第四个代码片段不适用于Python3.7。您可以阅读有关更改的更多信息here
▶注意链式操作
>>> (False == False) in [False] # makes sense
False
>>> False == (False in [False]) # makes sense
False
>>> False == False in [False] # now what?
True
>>> True is False == False
False
>>> False is False is False
True
>>> 1 > 0 < 1
True
>>> (1 > 0) < 1
False
>>> 1 > (0 < 1)
False
💡说明:
按规定https://docs.python.org/3/reference/expressions.html#membership-test-operations
形式上,如果a、b、c、…、y、z是表达式,并且op1、op2、…、opn是比较运算符,则a op1b、op2c。y opn z等同于a op1b和b op2c。y opn z,只是每个表达式最多求值一次
虽然在上面的示例中,这样的行为在您看来可能很愚蠢,但对于像这样的东西来说,它是非常棒的a == b == c和0 <= x <= 100
False is False is False相当于(False is False) and (False is False)True is False == False相当于True is False and False == False由于声明的第一部分(True is False)的计算结果为False,则整个表达式的计算结果为False1 > 0 < 1相当于1 > 0 and 0 < 1,它的计算结果为True- 表达式
(1 > 0) < 1相当于True < 1和
>>> int(True)
1
>>> True + 1 #not relevant for this example, but just for fun
2
所以,1 < 1计算结果为False
▶如何不使用is操作员
下面是一个在互联网上流传的非常著名的例子。
1个
>>> a = 256
>>> b = 256
>>> a is b
True
>>> a = 257
>>> b = 257
>>> a is b
False
2个
>>> a = []
>>> b = []
>>> a is b
False
>>> a = tuple()
>>> b = tuple()
>>> a is b
True
3个输出
>>> a, b = 257, 257
>>> a is b
True
输出(特别是Python 3.7.x)
>>> a, b = 257, 257
>> a is b
False
💡说明:
两者之间的区别is和==
is运算符检查两个操作数是否引用同一对象(即,它检查操作数的标识是否匹配)==运算符比较两个操作数的值并检查它们是否相同- 所以
is是为了引用相等和==是为了价值平等。这是一个澄清问题的例子,
>>> class A: pass
>>> A() is A() # These are two empty objects at two different memory locations.
False
256是现有对象,但257不是吗
当您启动python时,来自-5至256将会被分配。这些数字用得很多,所以只要准备好就行了
报价自https://docs.python.org/3/c-api/long.html
当前的实现为-5到256之间的所有整数保留了一个整数对象数组,当您在该范围内创建一个int时,您只会得到对现有对象的引用。所以应该可以更改1的值。我怀疑Python的行为(在本例中)是未定义的。:-)
>>> id(256)
10922528
>>> a = 256
>>> b = 256
>>> id(a)
10922528
>>> id(b)
10922528
>>> id(257)
140084850247312
>>> x = 257
>>> y = 257
>>> id(x)
140084850247440
>>> id(y)
140084850247344
在这里,解释器在执行时不够聪明y = 257要认识到我们已经创建了一个值的整数257,因此,它继续在内存中创建另一个对象
类似的优化也适用于其他不可变的对象也喜欢空元组。由于列表是可变的,这就是为什么[] is []会回来的False和() is ()会回来的True这解释了我们的第二个片段。让我们继续第三个问题,
两者都有a和b在同一行中使用相同的值初始化时引用相同的对象
输出
>>> a, b = 257, 257
>>> id(a)
140640774013296
>>> id(b)
140640774013296
>>> a = 257
>>> b = 257
>>> id(a)
140640774013392
>>> id(b)
140640774013488
- 当a和b设置为
257在同一行中,Python解释器创建一个新对象,然后同时引用第二个变量。如果您在单独的行上执行,它不会“知道”已经有257作为一个对象
- 它是一种编译器优化,特别适用于交互式环境。当您在实时解释器中输入两行时,它们被单独编译,因此分别进行了优化。如果您要在
.py文件时,您将不会看到相同的行为,因为该文件是一次性编译的。这种优化并不局限于整数,它也适用于其他不可变的数据类型,如字符串(请查看“字符串是棘手的示例”)和浮点数。
>>> a, b = 257.0, 257.0
>>> a is b
True
- 为什么这不适用于Python3.7?抽象原因是因为这样的编译器优化是特定于实现的(即可能随版本、OS等而改变)。我还在找出是什么具体的实现更改导致了这个问题,您可以查看以下内容issue用于更新
▶哈希布朗尼
1个
some_dict = {}
some_dict[5.5] = "JavaScript"
some_dict[5.0] = "Ruby"
some_dict[5] = "Python"
输出:
>>> some_dict[5.5]
"JavaScript"
>>> some_dict[5.0] # "Python" destroyed the existence of "Ruby"?
"Python"
>>> some_dict[5]
"Python"
>>> complex_five = 5 + 0j
>>> type(complex_five)
complex
>>> some_dict[complex_five]
"Python"
那么,为什么到处都是Python呢?
💡解释
▶在内心深处,我们都是一样的
输出:
>>> WTF() == WTF() # two different instances can't be equal
False
>>> WTF() is WTF() # identities are also different
False
>>> hash(WTF()) == hash(WTF()) # hashes _should_ be different as well
True
>>> id(WTF()) == id(WTF())
True
💡说明:
▶秩序中的混乱*
from collections import OrderedDict
dictionary = dict()
dictionary[1] = 'a'; dictionary[2] = 'b';
ordered_dict = OrderedDict()
ordered_dict[1] = 'a'; ordered_dict[2] = 'b';
another_ordered_dict = OrderedDict()
another_ordered_dict[2] = 'b'; another_ordered_dict[1] = 'a';
class DictWithHash(dict):
"""
A dict that also implements __hash__ magic.
"""
__hash__ = lambda self: 0
class OrderedDictWithHash(OrderedDict):
"""
An OrderedDict that also implements __hash__ magic.
"""
__hash__ = lambda self: 0
输出
>>> dictionary == ordered_dict # If a == b
True
>>> dictionary == another_ordered_dict # and b == c
True
>>> ordered_dict == another_ordered_dict # then why isn't c == a ??
False
# We all know that a set consists of only unique elements,
# let's try making a set of these dictionaries and see what happens...
>>> len({dictionary, ordered_dict, another_ordered_dict})
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'dict'
# Makes sense since dict don't have __hash__ implemented, let's use
# our wrapper classes.
>>> dictionary = DictWithHash()
>>> dictionary[1] = 'a'; dictionary[2] = 'b';
>>> ordered_dict = OrderedDictWithHash()
>>> ordered_dict[1] = 'a'; ordered_dict[2] = 'b';
>>> another_ordered_dict = OrderedDictWithHash()
>>> another_ordered_dict[2] = 'b'; another_ordered_dict[1] = 'a';
>>> len({dictionary, ordered_dict, another_ordered_dict})
1
>>> len({ordered_dict, another_ordered_dict, dictionary}) # changing the order
2
这里发生什么事情?
💡说明:
▶继续努力。*
def some_func():
try:
return 'from_try'
finally:
return 'from_finally'
def another_func():
for _ in range(3):
try:
continue
finally:
print("Finally!")
def one_more_func(): # A gotcha!
try:
for i in range(3):
try:
1 / i
except ZeroDivisionError:
# Let's throw it here and handle it outside for loop
raise ZeroDivisionError("A trivial divide by zero error")
finally:
print("Iteration", i)
break
except ZeroDivisionError as e:
print("Zero division error occurred", e)
输出:
>>> some_func()
'from_finally'
>>> another_func()
Finally!
Finally!
Finally!
>>> 1 / 0
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ZeroDivisionError: division by zero
>>> one_more_func()
Iteration 0
💡说明:
- 当一个
return,break或continue语句在try一套“Try…Finally”语句,finally子句也在退出时执行。
- 函数的返回值由最后一个
return语句已执行。由于finally子句始终执行,则会引发return中执行的语句finally子句将始终是最后执行的子句。
- 这里需要注意的是,如果Finally子句执行
return或break语句,则会丢弃临时保存的异常。
▶为了什么?
some_string = "wtf"
some_dict = {}
for i, some_dict[i] in enumerate(some_string):
i = 10
输出:
>>> some_dict # An indexed dict appears.
{0: 'w', 1: 't', 2: 'f'}
💡说明:
▶评估时间差异
1个
array = [1, 8, 15]
# A typical generator expression
gen = (x for x in array if array.count(x) > 0)
array = [2, 8, 22]
输出:
>>> print(list(gen)) # Where did the other values go?
[8]
2个
array_1 = [1,2,3,4]
gen_1 = (x for x in array_1)
array_1 = [1,2,3,4,5]
array_2 = [1,2,3,4]
gen_2 = (x for x in array_2)
array_2[:] = [1,2,3,4,5]
输出:
>>> print(list(gen_1))
[1, 2, 3, 4]
>>> print(list(gen_2))
[1, 2, 3, 4, 5]
3个
array_3 = [1, 2, 3]
array_4 = [10, 20, 30]
gen = (i + j for i in array_3 for j in array_4)
array_3 = [4, 5, 6]
array_4 = [400, 500, 600]
输出:
>>> print(list(gen))
[401, 501, 601, 402, 502, 602, 403, 503, 603]
💡解释
- 在一个generator表达式,则
in子句在声明时求值,但条件子句在运行时求值
- 所以在运行之前,
array被重新分配到列表中[2, 8, 22],并且由于不在1,8和15,只有8大于0,发电机只会产生8
- 其产量的不同之处在于
g1和g2第二部分是因应方式变量array_1和array_2是重新赋值的
- 在第一种情况下,
array_1绑定到新对象[1,2,3,4,5]而且由于in子句在声明时求值,它仍然引用旧对象。[1,2,3,4](未销毁)
- 在第二种情况下,将切片分配给
array_2更新相同的旧对象[1,2,3,4]至[1,2,3,4,5]因此,这两个g2和array_2仍然有对同一对象的引用(该对象现在已更新为[1,2,3,4,5])
- 好的,按照到目前为止讨论的逻辑,不应该是
list(gen)在第三个片段中[11, 21, 31, 12, 22, 32, 13, 23, 33]?(因为array_3和array_4会表现得就像array_1)。原因(仅限)array_4有关更新的值的说明,请参阅PEP-289
仅立即计算最外层的for-expression,其他表达式将推迟到生成器运行
▶is not ...不是is (not ...)
>>> 'something' is not None
True
>>> 'something' is (not None)
False
💡解释
is not是单个二元运算符,其行为与使用is和not分开的is not计算结果为False如果运算符两侧的变量指向同一对象,并且True否则- 在该示例中,
(not None)计算结果为True因为它的价值None是False在布尔上下文中,因此表达式变为'something' is True
▶一个X在第一次尝试中就赢了的井字棋(tic-tac-toe)!
# Let's initialize a row
row = [""] * 3 #row i['', '', '']
# Let's make a board
board = [row] * 3
输出:
>>> board
[['', '', ''], ['', '', ''], ['', '', '']]
>>> board[0]
['', '', '']
>>> board[0][0]
''
>>> board[0][0] = "X"
>>> board
[['X', '', ''], ['X', '', ''], ['X', '', '']]
我们没有分配三个"X"S,我们有吗?
💡说明:
当我们初始化时row变量,这种可视化解释了内存中发生的事情

而当board通过将row,这就是内存中发生的事情(每个元素board[0],board[1]和board[2]是对由引用的同一列表的引用row)

我们可以在这里避免这种情况,方法是不使用row要生成的变量board(被问及this问题)
>>> board = [['']*3 for _ in range(3)]
>>> board[0][0] = "X"
>>> board
[['X', '', ''], ['', '', ''], ['', '', '']]
▶薛定谔变量*
funcs = []
results = []
for x in range(7):
def some_func():
return x
funcs.append(some_func)
results.append(some_func()) # note the function call here
funcs_results = [func() for func in funcs]
输出(Python版本):
>>> results
[0, 1, 2, 3, 4, 5, 6]
>>> funcs_results
[6, 6, 6, 6, 6, 6, 6]
的价值x在追加之前的每个迭代中都是不同的some_func至funcs,但是在循环完成后对所有函数求值时,所有函数都返回6
>>> powers_of_x = [lambda x: x**i for i in range(10)]
>>> [f(2) for f in powers_of_x]
[512, 512, 512, 512, 512, 512, 512, 512, 512, 512]
💡说明:
- 在循环内定义在其主体中使用循环变量的函数时,循环函数的闭包将绑定到变量,而不是ITS价值该函数查找
x在周围的上下文中,而不是使用x在创建函数时。因此,所有函数都使用分配给变量的最新值进行计算。我们可以看到它正在使用x从周围的上下文(即不局部变量),具有:
>>> import inspect
>>> inspect.getclosurevars(funcs[0])
ClosureVars(nonlocals={}, globals={'x': 6}, builtins={}, unbound=set())
因为x是全局值,我们可以更改funcs将通过更新查找并返回x:
>>> x = 42
>>> [func() for func in funcs]
[42, 42, 42, 42, 42, 42, 42]
- 要获得所需的行为,可以将循环变量作为命名变量传递给函数。为什么这个管用呢?因为这将定义变量内部函数的作用域。它将不再转到周围的(全局)作用域来查找变量值,而是创建一个局部变量来存储
x在那个时间点上
funcs = []
for x in range(7):
def some_func(x=x):
return x
funcs.append(some_func)
输出:
>>> funcs_results = [func() for func in funcs]
>>> funcs_results
[0, 1, 2, 3, 4, 5, 6]
它不再使用x在全局范围内:
>>> inspect.getclosurevars(funcs[0])
ClosureVars(nonlocals={}, globals={}, builtins={}, unbound=set())
▶先有鸡还是先有蛋的问题**
1个
>>> isinstance(3, int)
True
>>> isinstance(type, object)
True
>>> isinstance(object, type)
True
那么,哪个是“终极”基类呢?顺便说一下,念力还有更多内容,
2个
>>> class A: pass
>>> isinstance(A, A)
False
>>> isinstance(type, type)
True
>>> isinstance(object, object)
True
3个
>>> issubclass(int, object)
True
>>> issubclass(type, object)
True
>>> issubclass(object, type)
False
💡解释
type是一种metaclass在Python中- 所有的一切是一种
object在Python中,包括类及其对象(实例)
- 班级
type是类的元类object,以及每个班级(包括type)直接或间接继承自object
- 中没有真正的基类。
object和type上述片段中的念力之所以出现,是因为我们正在考虑这些关系(issubclass和isinstance)在Python类方面。两国之间的关系object和type不能用纯python复制。更准确地说,以下关系不能在纯Python中重现,
- 类A是类B的实例,类B是类A的实例
- A类是其自身的一个实例
- 这些关系之间的关系
object和type(两者既是彼此的实例,也是自己的实例)存在于Python中,因为在实现级别上存在“欺骗”
▶子类关系
输出:
>>> from collections import Hashable
>>> issubclass(list, object)
True
>>> issubclass(object, Hashable)
True
>>> issubclass(list, Hashable)
False
子类关系应该是可传递的,对吗?(即,如果A是的子类B,以及B是的子类C,即A应该的子类C)
💡说明:
- 在Python中,子类关系不一定是可传递的。任何人都可以定义他们自己的,武断的
__subclasscheck__在元类中
- 什么时候
issubclass(cls, Hashable)被调用,它只是简单地查找非Falsey“__hash__“中的方法cls或它继承的任何东西
- 因为
object是可以哈希的,但是list是不可散列的,它打破了传递性关系
- 可以找到更详细的解释here
▶方法的等价性和同一性
class SomeClass:
def method(self):
pass
@classmethod
def classm(cls):
pass
@staticmethod
def staticm():
pass
输出:
>>> print(SomeClass.method is SomeClass.method)
True
>>> print(SomeClass.classm is SomeClass.classm)
False
>>> print(SomeClass.classm == SomeClass.classm)
True
>>> print(SomeClass.staticm is SomeClass.staticm)
True
访问classm两次,我们得到一个相等的对象,但不是相同的一?让我们看看如何处理以下实例SomeClass:
o1 = SomeClass()
o2 = SomeClass()
输出:
>>> print(o1.method == o2.method)
False
>>> print(o1.method == o1.method)
True
>>> print(o1.method is o1.method)
False
>>> print(o1.classm is o1.classm)
False
>>> print(o1.classm == o1.classm == o2.classm == SomeClass.classm)
True
>>> print(o1.staticm is o1.staticm is o2.staticm is SomeClass.staticm)
True
访问 classm或method两次,创建相等但不相等相同的对象的同一实例的SomeClass
💡解释
- 函数有descriptors无论何时将函数作为属性访问,都会调用描述符,从而创建一个方法对象,该对象将函数与拥有该属性的对象“绑定”在一起。如果被调用,该方法调用函数,将绑定对象作为第一个参数隐式传递(这就是我们如何获取
self作为第一个参数,尽管没有显式传递)
>>> o1.method
<bound method SomeClass.method of <__main__.SomeClass object at ...>>
- 多次访问该属性每次都会创建一个方法对象!因此,
o1.method is o1.method从来都不是真实的。但是,将函数作为类属性访问(与实例相反)并不会创建方法;因此SomeClass.method is SomeClass.method是真实的吗?
>>> SomeClass.method
<function SomeClass.method at ...>
classmethod将函数转换为类方法。类方法是描述符,当访问这些描述符时,会创建一个方法对象,该对象将班级对象的(类型),而不是对象本身
>>> o1.classm
<bound method SomeClass.classm of <class '__main__.SomeClass'>>
- 与函数不同,
classmethod在作为类属性访问时,也将创建一个方法(在这种情况下,它们绑定类,而不是绑定到类的类型)。所以SomeClass.classm is SomeClass.classm是假的
>>> SomeClass.classm
<bound method SomeClass.classm of <class '__main__.SomeClass'>>
- 当两个函数相等且绑定对象相同时,方法对象会比较相等。所以
o1.method == o1.method是真实的,尽管在内存中不是同一对象
staticmethod将函数转换为“no-op”描述符,该描述符按原样返回函数。不会创建任何方法对象,因此与is是真实的吗?
>>> o1.staticm
<function SomeClass.staticm at ...>
>>> SomeClass.staticm
<function SomeClass.staticm at ...>
- 每次Python调用实例方法时都必须创建新的“方法”对象,并且每次都必须修改参数才能插入
self严重影响了性能。CPython3.7solved it通过引入新的操作码来处理调用方法,而无需创建临时方法对象。这仅在实际调用所访问的函数时使用,因此此处的代码段不受影响,并且仍会生成方法:)
▶全真*
>>> all([True, True, True])
True
>>> all([True, True, False])
False
>>> all([])
True
>>> all([[]])
False
>>> all([[[]]])
True
为什么会有这种真假的改变呢?
💡说明:
- 该计划的实施
all函数等效于
-
def all(iterable):
for element in iterable:
if not element:
return False
return True
all([])退货True由于迭代器为空all([[]])退货False因为传递的数组有一个元素,[],在python中,空列表是虚假的。all([[[]]])更高的递归变体总是True这是因为传递的数组的单个元素([[...]])不再为空,带有值的列表为真
▶令人惊讶的逗号
输出(<3.6):
>>> def f(x, y,):
... print(x, y)
...
>>> def g(x=4, y=5,):
... print(x, y)
...
>>> def h(x, **kwargs,):
File "<stdin>", line 1
def h(x, **kwargs,):
^
SyntaxError: invalid syntax
>>> def h(*args,):
File "<stdin>", line 1
def h(*args,):
^
SyntaxError: invalid syntax
💡说明:
- 在Python函数的形参列表中,尾随逗号并不总是合法的
- 在Python中,参数列表部分使用前导逗号定义,部分使用尾随逗号定义。此冲突会导致逗号被困在中间的情况,并且没有规则接受它
- 注:后面的逗号问题是fixed in Python 3.6中的评论this简要讨论Python中尾随逗号的不同用法
▶字符串和反斜杠
输出:
>>> print("\"")
"
>>> print(r"\"")
\"
>>> print(r"\")
File "<stdin>", line 1
print(r"\")
^
SyntaxError: EOL while scanning string literal
>>> r'\'' == "\\'"
True
💡解释
- 在通常的python字符串中,反斜杠用于转义可能具有特殊含义的字符(如单引号、双引号和反斜杠本身)。
- 在原始字符串文字中(由前缀指示
r),则反斜杠会按原样传递自身,同时转义以下字符的行为
>>> r'wt\"f' == 'wt\\"f'
True
>>> print(repr(r'wt\"f')
'wt\\"f'
>>> print("\n")
>>> print(r"\\n")
'\\n'
- 这意味着当解析器在原始字符串中遇到反斜杠时,它会期待后面跟着另一个字符。在我们的情况下(
print(r"\")),则反斜杠转义尾部引号,使解析器没有终止引号(因此SyntaxError)。这就是原始字符串末尾不能使用反斜杠的原因
▶不是结!
输出:
>>> not x == y
True
>>> x == not y
File "<input>", line 1
x == not y
^
SyntaxError: invalid syntax
💡说明:
- 运算符优先级影响表达式的求值方式,并且
==运算符的优先级高于notPython中的运算符
- 所以
not x == y相当于not (x == y)这相当于not (True == False)最终评估为True
- 但
x == not y引发一个SyntaxError因为它可以被认为等同于(x == not) y而不是x == (not y)这可能是你第一眼看到的
- 解析器期望
not令牌作为not in运算符(因为两者==和not in运算符具有相同的优先级),但在无法找到in标记后跟在not令牌,则会引发SyntaxError
▶半个三引号字符串
输出:
>>> print('wtfpython''')
wtfpython
>>> print("wtfpython""")
wtfpython
>>> # The following statements raise `SyntaxError`
>>> # print('''wtfpython')
>>> # print("""wtfpython")
File "<input>", line 3
print("""wtfpython")
^
SyntaxError: EOF while scanning triple-quoted string literal
💡说明:
- Python支持隐式string literal concatenation,例如,
>>> print("wtf" "python")
wtfpython
>>> print("wtf" "") # or "wtf"""
wtf
'''和"""也是Python中的字符串分隔符,这会导致语法错误,因为Python解释器在扫描当前遇到的三重引号字符串文字时期望使用终止的三重引号作为分隔符
▶布尔人有什么问题吗?
1个
# A simple example to count the number of booleans and
# integers in an iterable of mixed data types.
mixed_list = [False, 1.0, "some_string", 3, True, [], False]
integers_found_so_far = 0
booleans_found_so_far = 0
for item in mixed_list:
if isinstance(item, int):
integers_found_so_far += 1
elif isinstance(item, bool):
booleans_found_so_far += 1
输出:
>>> integers_found_so_far
4
>>> booleans_found_so_far
0
2个
>>> some_bool = True
>>> "wtf" * some_bool
'wtf'
>>> some_bool = False
>>> "wtf" * some_bool
''
3个
def tell_truth():
True = False
if True == False:
print("I have lost faith in truth!")
输出(<3.x):
>>> tell_truth()
I have lost faith in truth!
💡说明:
bool是的子类int在Python中
>>> issubclass(bool, int)
True
>>> issubclass(int, bool)
False
- 因此,
True和False是以下对象的实例int
>>> isinstance(True, int)
True
>>> isinstance(False, int)
True
- 的整数值
True是1那就是False是0
>>> int(True)
1
>>> int(False)
0
- 查看此StackOverflowanswer以了解其背后的理论基础
- 最初,Python过去没有
bool类型(人们使用0表示FALSE,使用非零值1表示TRUE)。True,False,和一个bool类型是在2.x版本中添加的,但是为了向后兼容,True和False不能成为常量。它们只是内置变量,可以重新赋值
- Python3向后不兼容,该问题最终被修复,因此最后一个代码片段不能与Python3.x一起工作!
▶类属性和实例属性
1个
class A:
x = 1
class B(A):
pass
class C(A):
pass
输出:
>>> A.x, B.x, C.x
(1, 1, 1)
>>> B.x = 2
>>> A.x, B.x, C.x
(1, 2, 1)
>>> A.x = 3
>>> A.x, B.x, C.x # C.x changed, but B.x didn't
(3, 2, 3)
>>> a = A()
>>> a.x, A.x
(3, 3)
>>> a.x += 1
>>> a.x, A.x
(4, 3)
2个
class SomeClass:
some_var = 15
some_list = [5]
another_list = [5]
def __init__(self, x):
self.some_var = x + 1
self.some_list = self.some_list + [x]
self.another_list += [x]
输出:
>>> some_obj = SomeClass(420)
>>> some_obj.some_list
[5, 420]
>>> some_obj.another_list
[5, 420]
>>> another_obj = SomeClass(111)
>>> another_obj.some_list
[5, 111]
>>> another_obj.another_list
[5, 420, 111]
>>> another_obj.another_list is SomeClass.another_list
True
>>> another_obj.another_list is some_obj.another_list
True
💡说明:
- 类变量和类实例中的变量作为类对象的字典在内部处理。如果在当前类的字典中找不到变量名,则会在父类中搜索该变量名
- 这个
+=运算符就地修改可变对象,而不创建新对象。因此,更改一个实例的属性会影响其他实例和类属性
▶一无所获
some_iterable = ('a', 'b')
def some_func(val):
return "something"
输出(<=3.7.x):
>>> [x for x in some_iterable]
['a', 'b']
>>> [(yield x) for x in some_iterable]
<generator object <listcomp> at 0x7f70b0a4ad58>
>>> list([(yield x) for x in some_iterable])
['a', 'b']
>>> list((yield x) for x in some_iterable)
['a', None, 'b', None]
>>> list(some_func((yield x)) for x in some_iterable)
['a', 'something', 'b', 'something']
💡说明:
▶屈服于。回来!*
1个
def some_func(x):
if x == 3:
return ["wtf"]
else:
yield from range(x)
输出(>3.3):
>>> list(some_func(3))
[]
那辆车在哪里呢?"wtf"去?是不是因为有一些特殊的效果yield from?我们来验证一下,
2个
def some_func(x):
if x == 3:
return ["wtf"]
else:
for i in range(x):
yield i
输出:
>>> list(some_func(3))
[]
同样的结果,这也不管用
💡说明:
“。”return expr在发电机中引起StopIteration(expr)在离开发电机时提升。“
- 在以下情况下
some_func(3),StopIteration是在一开始就提出的,因为return声明。这个StopIteration异常会自动捕获到list(...)包装器和for循环。因此,上述两个代码段将产生一个空列表
- 为了得到
["wtf"]从发电机some_func我们需要赶上StopIteration例外,
try:
next(some_func(3))
except StopIteration as e:
some_string = e.value
▶NaN-自反性*
1个
a = float('inf')
b = float('nan')
c = float('-iNf') # These strings are case-insensitive
d = float('nan')
输出:
>>> a
inf
>>> b
nan
>>> c
-inf
>>> float('some_other_string')
ValueError: could not convert string to float: some_other_string
>>> a == -c # inf==inf
True
>>> None == None # None == None
True
>>> b == d # but nan!=nan
False
>>> 50 / a
0.0
>>> a / a
nan
>>> 23 + b
nan
2个
>>> x = float('nan')
>>> y = x / x
>>> y is y # identity holds
True
>>> y == y # equality fails of y
False
>>> [y] == [y] # but the equality succeeds for the list containing y
True
💡说明:
▶变异不变的东西!
如果您知道引用在Python中的工作方式,这可能看起来微不足道
some_tuple = ("A", "tuple", "with", "values")
another_tuple = ([1, 2], [3, 4], [5, 6])
输出:
>>> some_tuple[2] = "change this"
TypeError: 'tuple' object does not support item assignment
>>> another_tuple[2].append(1000) #This throws no error
>>> another_tuple
([1, 2], [3, 4], [5, 6, 1000])
>>> another_tuple[2] += [99, 999]
TypeError: 'tuple' object does not support item assignment
>>> another_tuple
([1, 2], [3, 4], [5, 6, 1000, 99, 999])
但是我认为元组是不变的
💡说明:
▶外部作用域中正在消失的变量
e = 7
try:
raise Exception()
except Exception as e:
pass
输出(Python 2.x):
>>> print(e)
# prints nothing
输出(Python 3.x):
>>> print(e)
NameError: name 'e' is not defined
💡说明:
▶神秘的钥匙类型转换
class SomeClass(str):
pass
some_dict = {'s': 42}
输出:
>>> type(list(some_dict.keys())[0])
str
>>> s = SomeClass('s')
>>> some_dict[s] = 40
>>> some_dict # expected: Two different keys-value pairs
{'s': 40}
>>> type(list(some_dict.keys())[0])
str
💡说明:
- 这两个对象
s和那根弦"s"散列为相同的值,因为SomeClass继承__hash__一种方法str班级
SomeClass("s") == "s"计算结果为True因为SomeClass还继承了__eq__方法来自str班级- 由于这两个对象散列为相同的值并且相等,因此它们在字典中由相同的键表示
- 对于所需的行为,我们可以重新定义
__eq__中的方法SomeClass
class SomeClass(str):
def __eq__(self, other):
return (
type(self) is SomeClass
and type(other) is SomeClass
and super().__eq__(other)
)
# When we define a custom __eq__, Python stops automatically inheriting the
# __hash__ method, so we need to define it as well
__hash__ = str.__hash__
some_dict = {'s':42}
输出:
>>> s = SomeClass('s')
>>> some_dict[s] = 40
>>> some_dict
{'s': 40, 's': 42}
>>> keys = list(some_dict.keys())
>>> type(keys[0]), type(keys[1])
(__main__.SomeClass, str)
▶让我们看看你能不能猜到这个?
输出:
💡说明:
赋值语句计算表达式列表(请记住,这可以是单个表达式或逗号分隔的列表,后者生成一个元组),并将单个结果对象从左到右分配给每个目标列表
剖面:湿滑斜坡
▶在迭代字典时修改字典
x = {0: None}
for i in x:
del x[i]
x[i+1] = None
print(i)
输出(Python 2.7-Python 3.5):
是的,它的运行时间正好是八时间和停靠站
💡说明:
- 不支持对同时编辑的字典进行迭代
- 它运行8次,因为这是字典调整大小以容纳更多键的时间点(我们有8个删除条目,因此需要调整大小)。这实际上是一个实现细节
- 对于不同的Python实现,处理已删除键的方式和调整大小的时间可能会有所不同
- 因此,对于除Python2.7-Python3.5之外的Python版本,计数可能不同于8(但无论计数是多少,每次运行它都是一样的)。你可以找到一些关于这方面的讨论here或在this堆栈溢出线程
- 从Python 3.7.6开始,您将看到
RuntimeError: dictionary keys changed during iteration如果您尝试执行此操作,则会出现异常
▶固执的del运营
class SomeClass:
def __del__(self):
print("Deleted!")
输出:1个
>>> x = SomeClass()
>>> y = x
>>> del x # this should print "Deleted!"
>>> del y
Deleted!
哎呀,终于删掉了。你可能已经猜到是什么救了你__del__在我们第一次尝试删除时被调用x让我们在这个示例中添加更多的曲折
2个
>>> x = SomeClass()
>>> y = x
>>> del x
>>> y # check if y exists
<__main__.SomeClass instance at 0x7f98a1a67fc8>
>>> del y # Like previously, this should print "Deleted!"
>>> globals() # oh, it didn't. Let's check all our global variables and confirm
Deleted!
{'__builtins__': <module '__builtin__' (built-in)>, 'SomeClass': <class __main__.SomeClass at 0x7f98a1a5f668>, '__package__': None, '__name__': '__main__', '__doc__': None}
好的,现在它被删除了😕
💡说明:
del x不会直接调用x.__del__()- 什么时候
del x时,Python将删除该名称x从当前作用域开始,并将对象的引用计数减1x已引用。__del__()仅当对象的引用计数达到零时才调用
- 在第二个输出片段中,
__del__()未调用,因为前面的语句(>>> y)创建了对同一对象的另一个引用(具体地说,_魔术变量,它引用最后一个非None表达式),从而防止在以下情况下引用计数达到零del y遇到了
- 呼叫
globals(或者实际上,执行任何将具有非None结果)导致_若要引用新结果,请删除现有引用。现在引用计数达到0,我们可以看到“已删除!”正在打印中(终于!)
▶超出作用域的变量
1个
a = 1
def some_func():
return a
def another_func():
a += 1
return a
2个
def some_closure_func():
a = 1
def some_inner_func():
return a
return some_inner_func()
def another_closure_func():
a = 1
def another_inner_func():
a += 1
return a
return another_inner_func()
输出:
>>> some_func()
1
>>> another_func()
UnboundLocalError: local variable 'a' referenced before assignment
>>> some_closure_func()
1
>>> another_closure_func()
UnboundLocalError: local variable 'a' referenced before assignment
💡说明:
- 当您为作用域中的变量赋值时,它将变为该作用域的局部变量。所以
a成为本地化的作用域another_func,但是它以前没有在相同的作用域中初始化,这会引发错误
- 修改外部作用域变量
a在……里面another_func,我们必须使用global关键字
def another_func()
global a
a += 1
return a
输出:
- 在……里面
another_closure_func,a成为本地化的作用域another_inner_func,但是它以前没有在相同的作用域中初始化,这就是它抛出错误的原因。
- 修改外部作用域变量
a在……里面another_inner_func,请使用nonlocal关键字。非本地语句用于引用在最近的外部(不包括全局)作用域中定义的变量
def another_func():
a = 1
def another_inner_func():
nonlocal a
a += 1
return a
return another_inner_func()
输出:
- 关键字
global和nonlocal告诉python解释器不要声明新变量,并在相应的外部作用域中查找它们。
- 朗读this这是一本简短但令人敬畏的指南,可帮助您详细了解Python中的名称空间和作用域解析是如何工作的
▶迭代时删除列表项
list_1 = [1, 2, 3, 4]
list_2 = [1, 2, 3, 4]
list_3 = [1, 2, 3, 4]
list_4 = [1, 2, 3, 4]
for idx, item in enumerate(list_1):
del item
for idx, item in enumerate(list_2):
list_2.remove(item)
for idx, item in enumerate(list_3[:]):
list_3.remove(item)
for idx, item in enumerate(list_4):
list_4.pop(idx)
输出:
>>> list_1
[1, 2, 3, 4]
>>> list_2
[2, 4]
>>> list_3
[]
>>> list_4
[2, 4]
你能猜出为什么输出是[2, 4]?
💡说明:
- 更改正在迭代的对象从来都不是一个好主意。这样做的正确方法是迭代对象的副本,并且
list_3[:]就是这么做的吗?
>>> some_list = [1, 2, 3, 4]
>>> id(some_list)
139798789457608
>>> id(some_list[:]) # Notice that python creates new object for sliced list.
139798779601192
两者之间的差异del,remove,以及pop:
del var_name只是移除了var_name从本地或全局命名空间(这就是为什么list_1不受影响)remove移除第一个匹配值,而不是特定索引,将引发ValueError如果找不到该值pop移除特定索引处的元素并将其返回,引发IndexError如果指定的索引无效
为什么输出是[2, 4]?
- 列表迭代是逐个索引完成的,当我们删除
1从…list_2或list_4,列表的内容现在是[2, 3, 4]剩余的元素被下移,即,2位于索引0,并且3由于下一次迭代将查看索引1(它是3)、2完全跳过了。列表序列中的每个备用元素都会发生类似的情况
- 请参阅此StackOverflowthread解释示例
- 另请参见这个不错的StackOverflowthread查看与Python中的字典相关的类似示例
▶迭代程序的有损压缩*
>>> numbers = list(range(7))
>>> numbers
[0, 1, 2, 3, 4, 5, 6]
>>> first_three, remaining = numbers[:3], numbers[3:]
>>> first_three, remaining
([0, 1, 2], [3, 4, 5, 6])
>>> numbers_iter = iter(numbers)
>>> list(zip(numbers_iter, first_three))
[(0, 0), (1, 1), (2, 2)]
# so far so good, let's zip the remaining
>>> list(zip(numbers_iter, remaining))
[(4, 3), (5, 4), (6, 5)]
DID元素位于何处3从numbers名单?
💡说明:
- 来自Pythondocs,这里是zip函数的大致实现,
def zip(*iterables):
sentinel = object()
iterators = [iter(it) for it in iterables]
while iterators:
result = []
for it in iterators:
elem = next(it, sentinel)
if elem is sentinel: return
result.append(elem)
yield tuple(result)
- 因此,该函数接受任意数量的可迭代对象,并将它们的每个项添加到
result列表,方法是调用next函数,并在任何迭代量耗尽时停止
- 这里需要注意的是,当耗尽任何可迭代时,
result列表将被丢弃。这就是发生在3在numbers_iter
- 执行上述操作的正确方法是使用
zip会是,
>>> numbers = list(range(7))
>>> numbers_iter = iter(numbers)
>>> list(zip(first_three, numbers_iter))
[(0, 0), (1, 1), (2, 2)]
>>> list(zip(remaining, numbers_iter))
[(3, 3), (4, 4), (5, 5), (6, 6)]
zip的第一个参数应该是元素最少的那个
▶循环变量泄漏!
1个
for x in range(7):
if x == 6:
print(x, ': for x inside loop')
print(x, ': x in global')
输出:
6 : for x inside loop
6 : x in global
但x从未在for循环的作用域之外定义
2个
# This time let's initialize x first
x = -1
for x in range(7):
if x == 6:
print(x, ': for x inside loop')
print(x, ': x in global')
输出:
6 : for x inside loop
6 : x in global
3个
输出(Python 2.x):
>>> x = 1
>>> print([x for x in range(5)])
[0, 1, 2, 3, 4]
>>> print(x)
4
输出(Python 3.x):
>>> x = 1
>>> print([x for x in range(5)])
[0, 1, 2, 3, 4]
>>> print(x)
1
💡说明:
- 在Python中,for循环使用它们所在的作用域,并将其定义的循环变量留在后面。如果我们之前在全局名称空间中显式定义了for-loop变量,这也适用。在这种情况下,它将重新绑定现有变量
- 列表理解示例的Python 2.x和Python 3.x解释器的输出差异可通过中记录的以下更改进行解释What’s New In Python 3.0更改日志:
“列表理解不再支持语法形式[... for var in item1, item2, ...]使用[... for var in (item1, item2, ...)]取而代之的是。还要注意,列表理解具有不同的语义:它们更接近于list()构造函数,特别是循环控制变量不再泄漏到周围的作用域。“
▶注意默认的可变参数!
def some_func(default_arg=[]):
default_arg.append("some_string")
return default_arg
输出:
>>> some_func()
['some_string']
>>> some_func()
['some_string', 'some_string']
>>> some_func([])
['some_string']
>>> some_func()
['some_string', 'some_string', 'some_string']
💡说明:
- Python中函数的默认可变参数并不是在您每次调用函数时都真正初始化的。取而代之的是,使用最近分配给它们的值作为默认值。当我们显式地传递
[]至some_func作为参数,default_arg未使用变量,因此函数按预期返回
def some_func(default_arg=[]):
default_arg.append("some_string")
return default_arg
输出:
>>> some_func.__defaults__ #This will show the default argument values for the function
([],)
>>> some_func()
>>> some_func.__defaults__
(['some_string'],)
>>> some_func()
>>> some_func.__defaults__
(['some_string', 'some_string'],)
>>> some_func([])
>>> some_func.__defaults__
(['some_string', 'some_string'],)
- 避免由于可变参数导致的错误的常见做法是将
None作为默认值,稍后检查是否有任何值传递给与该参数对应的函数。示例:
def some_func(default_arg=None):
if default_arg is None:
default_arg = []
default_arg.append("some_string")
return default_arg
▶捕捉异常
some_list = [1, 2, 3]
try:
# This should raise an ``IndexError``
print(some_list[4])
except IndexError, ValueError:
print("Caught!")
try:
# This should raise a ``ValueError``
some_list.remove(4)
except IndexError, ValueError:
print("Caught again!")
输出(Python 2.x):
Caught!
ValueError: list.remove(x): x not in list
输出(Python 3.x):
File "<input>", line 3
except IndexError, ValueError:
^
SyntaxError: invalid syntax
💡解释
- 要向EXCEPT子句添加多个异常,需要将它们作为带括号的元组作为第一个参数传递。第二个参数是一个可选名称,当提供该名称时,它将绑定已引发的异常实例。例如,
some_list = [1, 2, 3]
try:
# This should raise a ``ValueError``
some_list.remove(4)
except (IndexError, ValueError), e:
print("Caught again!")
print(e)
输出(Python 2.x):
Caught again!
list.remove(x): x not in list
输出(Python 3.x):
File "<input>", line 4
except (IndexError, ValueError), e:
^
IndentationError: unindent does not match any outer indentation level
- 不建议使用逗号将异常与变量分开,这在Python3中不起作用;正确的方法是使用
as例如,
some_list = [1, 2, 3]
try:
some_list.remove(4)
except (IndexError, ValueError) as e:
print("Caught again!")
print(e)
输出:
Caught again!
list.remove(x): x not in list
▶同样的操作数,不同的故事!
1个
a = [1, 2, 3, 4]
b = a
a = a + [5, 6, 7, 8]
输出:
>>> a
[1, 2, 3, 4, 5, 6, 7, 8]
>>> b
[1, 2, 3, 4]
2个
a = [1, 2, 3, 4]
b = a
a += [5, 6, 7, 8]
输出:
>>> a
[1, 2, 3, 4, 5, 6, 7, 8]
>>> b
[1, 2, 3, 4, 5, 6, 7, 8]
💡说明:
a += b并不总是以相同的方式表现为a = a + b班级可能实施op=运算符不同,列表就是这样做的- 表达式
a = a + [5,6,7,8]生成新列表并设置a对新列表的引用,离开b不变
- 表达式
a += [5,6,7,8]实际上映射到在列表上操作的“扩展”函数,以便a和b仍然指向已就地修改的同一列表
▶忽略类作用域的名称解析
1个
x = 5
class SomeClass:
x = 17
y = (x for i in range(10))
输出:
>>> list(SomeClass.y)[0]
5
2个
x = 5
class SomeClass:
x = 17
y = [x for i in range(10)]
输出(Python 2.x):
输出(Python 3.x):
💡解释
- 嵌套在类定义内的作用域忽略类级别绑定的名称
- 生成器表达式有其自己的作用域
- 从Python3.x开始,列表理解也有自己的作用域
▶像银行家一样圆滑*
让我们实现一个朴素的函数来获取列表的中间元素:
def get_middle(some_list):
mid_index = round(len(some_list) / 2)
return some_list[mid_index - 1]
Python 3.x:
>>> get_middle([1]) # looks good
1
>>> get_middle([1,2,3]) # looks good
2
>>> get_middle([1,2,3,4,5]) # huh?
2
>>> len([1,2,3,4,5]) / 2 # good
2.5
>>> round(len([1,2,3,4,5]) / 2) # why?
2
看起来Python似乎将2.5舍入为2
💡说明:
>>> round(0.5)
0
>>> round(1.5)
2
>>> round(2.5)
2
>>> import numpy # numpy does the same
>>> numpy.round(0.5)
0.0
>>> numpy.round(1.5)
2.0
>>> numpy.round(2.5)
2.0
- 这是对0.5小数进行舍入的推荐方式,如中所述IEEE 754然而,另一种方式(从零开始四舍五入)大部分时间都是在学校教授的,所以银行家的舍入可能不是那么出名。此外,一些最流行的编程语言(例如:JavaScript、Java、C/C++、Ruby、Rust)也不使用银行家取整。因此,这对于Python语言来说仍然非常特殊,并且在对分数进行舍入时可能会导致念力
- 请参阅round() docs或this stackoverflow thread了解更多信息
- 请注意,
get_middle([1])仅返回1,因为索引为round(0.5) - 1 = 0 - 1 = -1,返回列表中的最后一个元素
▶干草堆里的针*
到目前为止,我还没有遇到过一位体验过Pythonist的人,他没有遇到过以下一个或多个场景,
1个
x, y = (0, 1) if True else None, None
输出:
>>> x, y # expected (0, 1)
((0, 1), None)
2个
t = ('one', 'two')
for i in t:
print(i)
t = ('one')
for i in t:
print(i)
t = ()
print(t)
输出:
3个
ten_words_list = [
"some",
"very",
"big",
"list",
"that"
"consists",
"of",
"exactly",
"ten",
"words"
]
输出
>>> len(ten_words_list)
9
4.主张不够有力
a = "python"
b = "javascript"
输出:
# An assert statement with an assertion failure message.
>>> assert(a == b, "Both languages are different")
# No AssertionError is raised
5个
some_list = [1, 2, 3]
some_dict = {
"key_1": 1,
"key_2": 2,
"key_3": 3
}
some_list = some_list.append(4)
some_dict = some_dict.update({"key_4": 4})
输出:
>>> print(some_list)
None
>>> print(some_dict)
None
6个
def some_recursive_func(a):
if a[0] == 0:
return
a[0] -= 1
some_recursive_func(a)
return a
def similar_recursive_func(a):
if a == 0:
return a
a -= 1
similar_recursive_func(a)
return a
输出:
>>> some_recursive_func([5, 0])
[0, 0]
>>> similar_recursive_func(5)
4
💡说明:
- 对于%1,预期行为的正确语句为
x, y = (0, 1) if True else (None, None)
- 对于2,预期行为的正确语句为
t = ('one',)或t = 'one',(缺少逗号)否则口译员会认为t成为一名str并逐个字符对其进行迭代
()是一个特殊标记,表示为空tuple- 在3中,正如您可能已经知道的那样,第5个元素后面缺少逗号(
"that")。因此,通过隐式字符串文字连接,
>>> ten_words_list
['some', 'very', 'big', 'list', 'thatconsists', 'of', 'exactly', 'ten', 'words']
- 不是的
AssertionError在第四个代码段中引发,因为不是断言单个表达式a == b,我们断言整个元组。下面的代码片断将澄清问题,
>>> a = "python"
>>> b = "javascript"
>>> assert a == b
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AssertionError
>>> assert (a == b, "Values are not equal")
<stdin>:1: SyntaxWarning: assertion is always true, perhaps remove parentheses?
>>> assert a == b, "Values are not equal"
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AssertionError: Values are not equal
- 对于第五个代码段,大多数修改序列/映射对象项的方法,如
list.append,dict.update,list.sort等,就地修改对象并返回None这背后的基本原理是,如果操作可以就地完成,则可以通过避免复制对象来提高性能(请参阅here)
- 最后一个应该是相当明显的可变对象(如
list)可以在函数中更改,并且重新分配不可变的(a -= 1)不是对价值的更改
- 从长远来看,意识到这些吹毛求疵可以为您节省数小时的调试工作
▶分裂*
>>> 'a'.split()
['a']
# is same as
>>> 'a'.split(' ')
['a']
# but
>>> len(''.split())
0
# isn't the same as
>>> len(''.split(' '))
1
💡说明:
- 最初可能显示分割的默认分隔符是单个空格
' ',但根据docs
如果未指定SEP或None,则应用不同的拆分算法:连续的空格串被视为单个分隔符,如果字符串具有前导空格或尾随空格,则结果的开头或结尾处将不包含空字符串。因此,拆分空字符串或仅由空格组成的字符串(使用NONE分隔符)将返回[]如果给定了SEP,则连续的分隔符不会组合在一起,并被视为分隔空字符串(例如,'1,,2'.split(',')退货['1', '', '2'])。使用指定的分隔符拆分空字符串将返回['']
- 注意以下代码片段中前导空格和尾随空格的处理方式会让事情变得清晰起来,
>>> ' a '.split(' ')
['', 'a', '']
>>> ' a '.split()
['a']
>>> ''.split(' ')
['']
▶野生进口**
# File: module.py
def some_weird_name_func_():
print("works!")
def _another_weird_name_func():
print("works!")
输出
>>> from module import *
>>> some_weird_name_func_()
"works!"
>>> _another_weird_name_func()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name '_another_weird_name_func' is not defined
💡说明:
- 通常建议不要使用通配符导入。第一个显而易见的原因是,在通配符导入中,不会导入带有前导下划线的名称。这可能会导致运行时出错
- 如果我们用了
from ... import a, b, c语法,以上NameError就不会发生
>>> from module import some_weird_name_func_, _another_weird_name_func
>>> _another_weird_name_func()
works!
- 如果您真的想使用通配符导入,那么您必须定义列表
__all__在您的模块中,它将包含在执行通配符导入时可用的公共对象列表
__all__ = ['_another_weird_name_func']
def some_weird_name_func_():
print("works!")
def _another_weird_name_func():
print("works!")
输出
>>> _another_weird_name_func()
"works!"
>>> some_weird_name_func_()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'some_weird_name_func_' is not defined
▶都整理好了吗*
>>> x = 7, 8, 9
>>> sorted(x) == x
False
>>> sorted(x) == sorted(x)
True
>>> y = reversed(x)
>>> sorted(y) == sorted(y)
False
💡说明:
- 这个
sorted方法始终返回列表,比较列表和元组始终返回False在Python中
-
>>> [] == tuple()
False
>>> x = 7, 8, 9
>>> type(x), type(sorted(x))
(tuple, list)
- 不像
sorted,即reversed方法返回迭代器。为什么?因为排序需要就地修改迭代器或使用额外的容器(列表),而反转只需从最后一个索引迭代到第一个索引即可
- 所以在比较的时候
sorted(y) == sorted(y),第一次调用sorted()将使用迭代器y,下一次调用将只返回一个空列表
>>> x = 7, 8, 9
>>> y = reversed(x)
>>> sorted(y), sorted(y)
([7, 8, 9], [])
▶午夜时间不存在吗?
from datetime import datetime
midnight = datetime(2018, 1, 1, 0, 0)
midnight_time = midnight.time()
noon = datetime(2018, 1, 1, 12, 0)
noon_time = noon.time()
if midnight_time:
print("Time at midnight is", midnight_time)
if noon_time:
print("Time at noon is", noon_time)
输出(<3.5):
('Time at noon is', datetime.time(12, 0))
未打印午夜时间
💡说明:
在Python 3.5之前的版本中,datetime.time对象被认为是False如果它代表协调世界时的午夜。在使用if obj:语法,以检查是否obj为NULL或与“Empty”等价物。
部分:隐藏的宝藏!
这一节包含一些像我这样的初学者不知道的关于Python的鲜为人知和有趣的事情(好吧,现在不知道了)
▶好的,python,能给我做飞翔吗?
好的,给你
输出:嘘。这是个超级秘密
💡说明:
▶goto但是为什么呢?
from goto import goto, label
for i in range(9):
for j in range(9):
for k in range(9):
print("I am trapped, please rescue!")
if k == 2:
goto .breakout # breaking out from a deeply nested loop
label .breakout
print("Freedom!")
输出(Python 2.3):
I am trapped, please rescue!
I am trapped, please rescue!
Freedom!
💡说明:
- 的工作版本
goto在Python中是announced作为2004年4月1日的愚人节笑话
- 当前版本的Python没有此模块
- 虽然有效,但请不要使用。这是reason为什么
goto在Python中不存在
▶振作起来!
如果您不喜欢在Python中使用空格来表示作用域,您可以使用C样式{},方法是导入
from __future__ import braces
输出:
File "some_file.py", line 1
from __future__ import braces
SyntaxError: not a chance
牙套?不行!如果您认为这令人失望,可以使用Java。好的,另一件令人惊讶的事,你能找到SyntaxError成长于__future__模块code?
💡说明:
- 这个
__future__模块通常用于提供未来版本的Python的功能。然而,在这一特定背景下的“未来”是具有讽刺意味的。
- 这是一个复活节彩蛋,关注社区在这个问题上的感受
- 代码实际上是存在的here在……里面
future.c文件
- 当CPython编译器遇到future statement,它首先在
future.c在将其视为普通导入语句之前
▶让我们来见见友好的终生语言大叔
输出(Python 3.x)
>>> from __future__ import barry_as_FLUFL
>>> "Ruby" != "Python" # there's no doubt about it
File "some_file.py", line 1
"Ruby" != "Python"
^
SyntaxError: invalid syntax
>>> "Ruby" <> "Python"
True
好了,我们走吧
💡说明:
- 这与以下内容相关PEP-4012009年4月1日上映(现在你知道这意味着什么了)
- 引用PEP-401
认识到Python3.0中的!=不等式运算符是一个可怕的、会导致手指疼痛的错误,FLUFL恢复了<>菱形运算符作为唯一拼写
- 巴里叔叔在PEP中有更多的东西要分享;你可以阅读它们here
- 它在交互环境中工作得很好,但它会引发
SyntaxError当您通过python文件运行时(请参阅此issue)。但是,您可以将语句包装在eval或compile为了让它运转起来,
from __future__ import barry_as_FLUFL
print(eval('"Ruby" <> "Python"'))
▶即使是python也明白爱情是复杂的
等等,这是什么这?this就是爱❤️
输出:
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
这是巨蟒的禅宗!
>>> love = this
>>> this is love
True
>>> love is True
False
>>> love is False
False
>>> love is not True or False
True
>>> love is not True or False; love is love # Love is complicated
True
💡说明:
thisPython中的模块是Python禅宗的复活节彩蛋(PEP 20)- 如果您认为这已经足够有趣,请查看this.py有趣的是,禅宗的密码违背了它自己(这可能是唯一发生这种情况的地方)
- 关于这份声明
love is not True or False; love is love,具有讽刺意味,但这是不言而喻的(如果不是,请参阅与以下内容相关的示例is和is not操作员)
▶是的,它确实存在!
这个elseFOR循环子句一个典型的示例可能是:
def does_exists_num(l, to_find):
for num in l:
if num == to_find:
print("Exists!")
break
else:
print("Does not exist")
输出:
>>> some_list = [1, 2, 3, 4, 5]
>>> does_exists_num(some_list, 4)
Exists!
>>> does_exists_num(some_list, -1)
Does not exist
这个else异常处理中的子句举个例子,
try:
pass
except:
print("Exception occurred!!!")
else:
print("Try block executed successfully...")
输出:
Try block executed successfully...
💡说明:
- 这个
else循环后的子句仅在没有显式break在所有的迭代之后。你可以把它看作是“不中断”条款。
else挡路试水后条款又称“补全条款”,即到达else子句中的子句try语句表示试用挡路实际已成功完成
▶省略号*
def some_func():
Ellipsis
输出
>>> some_func()
# No output, No Error
>>> SomeRandomString
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'SomeRandomString' is not defined
>>> Ellipsis
Ellipsis
💡解释
- 在Python中,
Ellipsis是全局可用的内置对象,它等效于...
- 省略可以用于几个目的,
- 作为尚未编写的代码的占位符(就像
pass声明)
- 在切片语法中表示剩余方向上的完整切片
>>> import numpy as np
>>> three_dimensional_array = np.arange(8).reshape(2, 2, 2)
array([
[
[0, 1],
[2, 3]
],
[
[4, 5],
[6, 7]
]
])
所以我们的three_dimensional_array是由数组数组组成的数组。假设我们要打印第二个元素(index1)在所有最里面的数组中,我们可以使用省略号绕过前面的所有维度
>>> three_dimensional_array[:,:,1]
array([[1, 3],
[5, 7]])
>>> three_dimensional_array[..., 1] # using Ellipsis.
array([[1, 3],
[5, 7]])
注意:这适用于任何数量的维度。您甚至可以选择第一个和最后一个维度中的切片,而忽略中间维度(n_dimensional_array[firs_dim_slice, ..., last_dim_slice])
- 在……里面type hinting仅表示该类型的一部分(如
(Callable[..., int]或Tuple[str, ...]))
- 您还可以使用省略号作为默认函数参数(在需要区分“没有传递参数”和“没有传递值”的情况下)
▶纯洁
这个拼写是有意的。请不要为此提交补丁
输出(Python 3.x):
>>> infinity = float('infinity')
>>> hash(infinity)
314159
>>> hash(float('-inf'))
-314159
💡说明:
- 无穷大的散列是10⁵xπ
- 有趣的是,
float('-inf')在Python3中为“-10⁵xπ”,而在Python2中为“-10⁵x e
▶让我们毁了它吧
1个
class Yo(object):
def __init__(self):
self.__honey = True
self.bro = True
输出:
>>> Yo().bro
True
>>> Yo().__honey
AttributeError: 'Yo' object has no attribute '__honey'
>>> Yo()._Yo__honey
True
2个
class Yo(object):
def __init__(self):
# Let's try something symmetrical this time
self.__honey__ = True
self.bro = True
输出:
>>> Yo().bro
True
>>> Yo()._Yo__honey__
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'Yo' object has no attribute '_Yo__honey__'
为什么要Yo()._Yo__honey工作?
3个
_A__variable = "Some value"
class A(object):
def some_func(self):
return __variable # not initialized anywhere yet
输出:
>>> A().__variable
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'A' object has no attribute '__variable'
>>> A().some_func()
'Some value'
💡说明:
- Name Mangling用于避免不同命名空间之间的命名冲突。
- 在Python中,解释器修改(损坏)以开头的类成员名称
__(双下划线,也称为“下划线”),并且不能以多个尾部下划线结尾,方法是添加_NameOfTheClass在前面
- 因此,要访问
__honey属性,我们必须在第一个代码段中追加_Yo添加到前面,这样可以防止与任何其他类中定义的相同名称属性发生冲突
- 但是为什么它在第二个片段中不起作用呢?因为名称损坏会排除以双下划线结尾的名称
- 第三个代码片段也是名称损坏的结果。名字
__variable在声明中return __variable被弄得残缺不全_A__variable,恰好也是我们在外部作用域中声明的变量的名称
- 此外,如果损坏的名称超过255个字符,则会发生截断
部分:外表是有欺骗性的!
▶跳过台词?
输出:
>>> value = 11
>>> valuе = 32
>>> value
11
无精打采的?
注:要再现这一点,最简单的方法是简单地从上面的代码片段复制语句,并将它们粘贴到文件/shell中
💡解释
有些非西方字符看起来与英语字母表中的字母相同,但口译员认为它们是不同的
>>> ord('е') # cyrillic 'e' (Ye)
1077
>>> ord('e') # latin 'e', as used in English and typed using standard keyboard
101
>>> 'е' == 'e'
False
>>> value = 42 # latin e
>>> valuе = 23 # cyrillic 'e', Python 2.x interpreter would raise a `SyntaxError` here
>>> value
42
内置的ord()函数返回字符的Unicodecode point,并且西里尔文‘e’和拉丁文‘e’的不同代码位置证明了上述示例的行为
▶隐形传态
# `pip install numpy` first.
import numpy as np
def energy_send(x):
# Initializing a numpy array
np.array([float(x)])
def energy_receive():
# Return an empty numpy array
return np.empty((), dtype=np.float).tolist()
输出:
>>> energy_send(123.456)
>>> energy_receive()
123.456
诺贝尔奖在哪里?
💡说明:
- 请注意,在
energy_send函数不返回,因此内存空间可以自由重新分配。
numpy.empty()返回下一个可用内存插槽,而不重新初始化它。这个内存点恰好与刚刚释放的内存点相同(通常,但不总是)
▶嗯,有些事很可疑
def square(x):
"""
A simple function to calculate the square of a number by addition.
"""
sum_so_far = 0
for counter in range(x):
sum_so_far = sum_so_far + x
return sum_so_far
输出(Python 2.x):
不是应该是100吗?
注:如果无法重现此文件,请尝试运行该文件mixed_tabs_and_spaces.py通过外壳
💡解释
- 不要将制表符和空格混为一谈!紧接在回车之前的字符是“制表符”,并且在示例中的其他地方,代码以“4个空格”的倍数缩进
- 以下是Python处理选项卡的方式:
首先,制表符被替换(从左到右)1到8个空格,这样替换之前(包括替换)的字符总数是8的倍数<.>
- 所以最后一行的“制表符”
square函数被替换为8个空格,并进入循环
- Python3非常友好,可以在这种情况下自动抛出错误
输出(Python 3.x):
TabError: inconsistent use of tabs and spaces in indentation
部分:其他
▶+=速度更快
# using "+", three strings:
>>> timeit.timeit("s1 = s1 + s2 + s3", setup="s1 = ' ' * 100000; s2 = ' ' * 100000; s3 = ' ' * 100000", number=100)
0.25748300552368164
# using "+=", three strings:
>>> timeit.timeit("s1 += s2 + s3", setup="s1 = ' ' * 100000; s2 = ' ' * 100000; s3 = ' ' * 100000", number=100)
0.012188911437988281
💡说明:
+=比我们的速度要快得多+用于连接两个以上的字符串,因为第一个字符串(例如,s1为s1 += s2 + s3)在计算完整字符串时不会被销毁
▶让我们做一根巨大的绳子吧!
def add_string_with_plus(iters):
s = ""
for i in range(iters):
s += "xyz"
assert len(s) == 3*iters
def add_bytes_with_plus(iters):
s = b""
for i in range(iters):
s += b"xyz"
assert len(s) == 3*iters
def add_string_with_format(iters):
fs = "{}"*iters
s = fs.format(*(["xyz"]*iters))
assert len(s) == 3*iters
def add_string_with_join(iters):
l = []
for i in range(iters):
l.append("xyz")
s = "".join(l)
assert len(s) == 3*iters
def convert_list_to_string(l, iters):
s = "".join(l)
assert len(s) == 3*iters
输出:
# Executed in ipython shell using %timeit for better readability of results.
# You can also use the timeit module in normal python shell/scriptm=, example usage below
# timeit.timeit('add_string_with_plus(10000)', number=1000, globals=globals())
>>> NUM_ITERS = 1000
>>> %timeit -n1000 add_string_with_plus(NUM_ITERS)
124 µs ± 4.73 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
>>> %timeit -n1000 add_bytes_with_plus(NUM_ITERS)
211 µs ± 10.5 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
>>> %timeit -n1000 add_string_with_format(NUM_ITERS)
61 µs ± 2.18 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
>>> %timeit -n1000 add_string_with_join(NUM_ITERS)
117 µs ± 3.21 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
>>> l = ["xyz"]*NUM_ITERS
>>> %timeit -n1000 convert_list_to_string(l, NUM_ITERS)
10.1 µs ± 1.06 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
让我们将迭代次数增加10倍
>>> NUM_ITERS = 10000
>>> %timeit -n1000 add_string_with_plus(NUM_ITERS) # Linear increase in execution time
1.26 ms ± 76.8 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
>>> %timeit -n1000 add_bytes_with_plus(NUM_ITERS) # Quadratic increase
6.82 ms ± 134 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
>>> %timeit -n1000 add_string_with_format(NUM_ITERS) # Linear increase
645 µs ± 24.5 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
>>> %timeit -n1000 add_string_with_join(NUM_ITERS) # Linear increase
1.17 ms ± 7.25 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
>>> l = ["xyz"]*NUM_ITERS
>>> %timeit -n1000 convert_list_to_string(l, NUM_ITERS) # Linear increase
86.3 µs ± 2 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
💡解释
- 您可以阅读更多关于timeit或%timeit在这些链接上。它们用于度量代码片段的执行时间
- 不要使用
+为了生成长字符串-在Python中,str是不可变的,因此对于每对串联,必须将左字符串和右字符串复制到新字符串中。如果连接四个长度为10的字符串,您将复制(10+10)+((10+10)+10)+(10+10)+10)+10)=90个字符,而不仅仅是40个字符。随着字符串的数量和大小的增加,情况会变得平方恶化(这与add_bytes_with_plus功能)
- 因此,建议您使用
.format.或%语法(但是,它们比+对于非常短的字符串)
- 或者更好的是,如果您已经有了可迭代对象形式的内容,那么使用
''.join(iterable_object)它的速度要快得多
- 不像
add_bytes_with_plus因为+=上一个示例中讨论的优化,add_string_with_plus没有表现出执行时间的二次增长。如果这份声明是s = s + "x" + "y" + "z"而不是s += "xyz",那么增长将是平方的。
def add_string_with_plus(iters):
s = ""
for i in range(iters):
s = s + "x" + "y" + "z"
assert len(s) == 3*iters
>>> %timeit -n100 add_string_with_plus(1000)
388 µs ± 22.4 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
>>> %timeit -n100 add_string_with_plus(10000) # Quadratic increase in execution time
9 ms ± 298 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
- 因此,格式化和创建巨型字符串的许多方法与Zen of Python,根据它的说法,
应该有1个,最好只有一个–显而易见的方法
▶减速dict查找*
some_dict = {str(i): 1 for i in range(1_000_000)}
another_dict = {str(i): 1 for i in range(1_000_000)}
输出:
>>> %timeit some_dict['5']
28.6 ns ± 0.115 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each)
>>> some_dict[1] = 1
>>> %timeit some_dict['5']
37.2 ns ± 0.265 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each)
>>> %timeit another_dict['5']
28.5 ns ± 0.142 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each)
>>> another_dict[1] # Trying to access a key that doesn't exist
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 1
>>> %timeit another_dict['5']
38.5 ns ± 0.0913 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each)
为什么相同的查找速度变慢了?
💡说明:
- CPython有一个通用字典查找函数,可以处理所有类型的键(
str,int,任何对象。),还有一个专门的,用于由以下内容组成的字典的常见情况str-仅密钥
- 专用函数(名为
lookdict_unicode在CPython的source)知道所有现有键(包括查找的键)都是字符串,并使用更快、更简单的字符串比较来比较键,而不是调用__eq__方法
- 第一次
dict实例使用非str键,则会对其进行修改,以便将来的查找使用泛型函数
- 此过程对于特定情况是不可逆的
dict实例,并且该键甚至不必存在于字典中。这就是为什么尝试失败的查找会产生同样的效果
▶膨胀的实例dict%s*
import sys
class SomeClass:
def __init__(self):
self.some_attr1 = 1
self.some_attr2 = 2
self.some_attr3 = 3
self.some_attr4 = 4
def dict_size(o):
return sys.getsizeof(o.__dict__)
输出:(Python 3.8,其他Python 3版本可能会稍有不同)
>>> o1 = SomeClass()
>>> o2 = SomeClass()
>>> dict_size(o1)
104
>>> dict_size(o2)
104
>>> del o1.some_attr1
>>> o3 = SomeClass()
>>> dict_size(o3)
232
>>> dict_size(o1)
232
我们再试一次。在新的口译器中:
>>> o1 = SomeClass()
>>> o2 = SomeClass()
>>> dict_size(o1)
104 # as expected
>>> o1.some_attr5 = 5
>>> o1.some_attr6 = 6
>>> dict_size(o1)
360
>>> dict_size(o2)
272
>>> o3 = SomeClass()
>>> dict_size(o3)
232
是什么让那些字典变得臃肿呢?为什么新创建的物体也会膨胀呢?
💡说明:
- CPython能够在多个字典中重用相同的“键”对象。这是在PEP 412有减少内存使用的动机,特别是在实例字典中-其中键(实例属性)往往对所有实例都是通用的
- 这种优化对于例如字典来说是完全无缝的,但是如果某些假设被打破,它将被禁用
- 密钥共享字典不支持删除;如果实例属性被删除,则字典是“非共享”的,并且对同一类的所有未来实例禁用密钥共享
- 此外,如果字典键已调整大小(因为插入了新键),则它们将保持共享仅限如果它们正好由单个字典使用(这允许在
__init__第一个创建的实例的属性,而不会导致“取消共享”)。如果在调整大小时存在多个实例,则对同一类的所有未来实例禁用密钥共享:CPython无法知道您的实例是否再使用相同的属性集,因此决定放弃尝试共享它们的密钥
- 如果您的目标是降低程序的内存占用量,那么给您一个小提示:不要删除实例属性,并确保初始化
__init__好了!
▶次要的*
join()是字符串操作,而不是列表操作。(第一次使用时有点违反直觉)
💡说明:如果join()是字符串上的方法,那么它可以操作任何可迭代的(列表、元组、迭代器)。如果它是列表上的方法,则必须由每种类型单独实现。此外,将特定于字符串的方法放在泛型list对象API
- 一些看起来奇怪但语义正确的陈述:
[] = ()是语义上正确的语句(解包一个空的tuple变得空荡荡的list)'a'[0][0][0][0][0]与字符串一样,也是语义上正确的语句sequencesPython中的(支持使用整数索引访问元素的迭代数)3 --0-- 5 == 8和--5 == 5都是语义上正确的语句,并且求值为True
- 考虑到这一点
a是一个数字,++a和--a都是有效的Python语句,但行为方式与C、C++或Java等语言中的类似语句不同
>>> a = 5
>>> a
5
>>> ++a
5
>>> --a
5
💡说明:
- 没有
++Python语法中的运算符。实际上是两个+操作员
++a解析为+(+a)这意味着a同样,语句的输出--a可以证明是合理的- 此堆栈溢出thread讨论Python中没有递增和递减运算符的原因
- 您一定知道Python中的Walrus操作符。但是你有没有听说过太空入侵者操作员?
>>> a = 42
>>> a -=- 1
>>> a
43
它与另一个递增运算符一起用作另一个递增运算符
💡说明:这个恶作剧来自于Raymond Hettinger’s tweet空间入侵者操作符实际上只是一个格式错误的a -= (-1)这相当于a = a - (- 1)类似于a += (+ 1)案例
- Python有一个未记录的converse implication操作员
>>> False ** False == True
True
>>> False ** True == False
True
>>> True ** False == True
True
>>> True ** True == True
True
💡说明:如果你替换掉False和True用0和1相乘并做数学运算,真值表等价于一个逆蕴涵运算符。(Source)
- 既然我们说的是运营商,还有
@矩阵乘法运算符(别担心,这次是实数)
>>> import numpy as np
>>> np.array([2, 2, 2]) @ np.array([7, 8, 8])
46
💡说明:这个@Python3.5中添加了运算符,将科学界考虑在内。任何对象都可以重载__matmul__定义此运算符行为的神奇方法
- 从Python3.8开始,您可以使用典型的f-string语法,如下所示
f'{some_var=}用于快速调试。例如,
>>> some_string = "wtfpython"
>>> f'{some_string=}'
"some_string='wtfpython'"
- Python使用2个字节存储函数中的局部变量。理论上,这意味着一个函数中只能定义65536个变量。但是,Python内置了一个方便的解决方案,可用于存储超过2^16个变量名。下面的代码演示了当定义了超过65536个局部变量时堆栈中会发生什么(警告:此代码打印大约2^18行文本,因此请做好准备!)
import dis
exec("""
def f():
""" + """
""".join(["X" + str(x) + "=" + str(x) for x in range(65539)]))
f()
print(dis.dis(f))
- 多个Python线程不会运行您的Python代码同时(是的,你没听错!)产生多个线程并让它们并发执行Python代码似乎很直观,但是由于Global Interpreter Lock在Python中,您所要做的就是让您的线程轮流在同一内核上执行。Python线程适用于IO受限的任务,但要在Python中实现CPU受限任务的实际并行化,您可能需要使用Pythonmultiprocessing模块
- 有时候,
print方法可能不会立即打印值。例如,
# File some_file.py
import time
print("wtfpython", end="_")
time.sleep(3)
这将打印wtfpython3秒后,由于end参数,因为输出缓冲区在遇到\n或者当程序完成执行时。我们可以通过传递以下参数来强制刷新缓冲区flush=True论据
- 索引超出界限的列表切片不会引发错误
>>> some_list = [1, 2, 3, 4, 5]
>>> some_list[111:]
[]
- 对迭代数进行切片并不总是会创建一个新对象。例如,
>>> some_str = "wtfpython"
>>> some_list = ['w', 't', 'f', 'p', 'y', 't', 'h', 'o', 'n']
>>> some_list is some_list[:] # False expected because a new object is created.
False
>>> some_str is some_str[:] # True because strings are immutable, so making a new object is of not much use.
True
int('١٢٣٤٥٦٧٨٩')退货123456789在Python 3中。在Python中,十进制字符包括数字字符和所有可用于构成小数基数的字符,例如U+0660,阿拉伯数字0。这是一张interesting story与Python的此行为相关- 从Python3开始,可以使用下划线分隔数字文字(以提高可读性
>>> six_million = 6_000_000
>>> six_million
6000000
>>> hex_address = 0xF00D_CAFE
>>> hex_address
4027435774
'abc'.count('') == 4以下是以下内容的大致实现count方法,这将使事情变得更清楚。
def count(s, sub):
result = 0
for i in range(len(s) + 1 - len(sub)):
result += (s[i:i + len(sub)] == sub)
return result
该行为是由于匹配空的子字符串(''),并在原始字符串中包含长度为0的片段
贡献
您可以通过几种方式为wtfpython做贡献,
请看CONTRIBUTING.md了解更多详细信息。您可以随意创建新的issue讨论事情
PS:请不要联系反向链接请求,不会添加任何链接,除非它们与项目高度相关
确认
这个系列的想法和设计最初的灵感来自Denys Dovhan令人惊叹的项目wtfjsPythonistas的压倒性支持给了它现在的样子
一些不错的链接!
🎓许可证

©Satwik Kansal
让你的朋友也大吃一惊吧!
如果您喜欢wtfpython,您可以使用这些快速链接与您的朋友分享它,
Twitter|Linkedin|Facebook
需要pdf版本吗?
我收到了一些关于wtfpython的pdf(和epub)版本的请求。您可以添加您的详细信息here一做完就拿到
这就是所有的人!对于即将发布的此类内容,您可以添加您的电子邮件here










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}