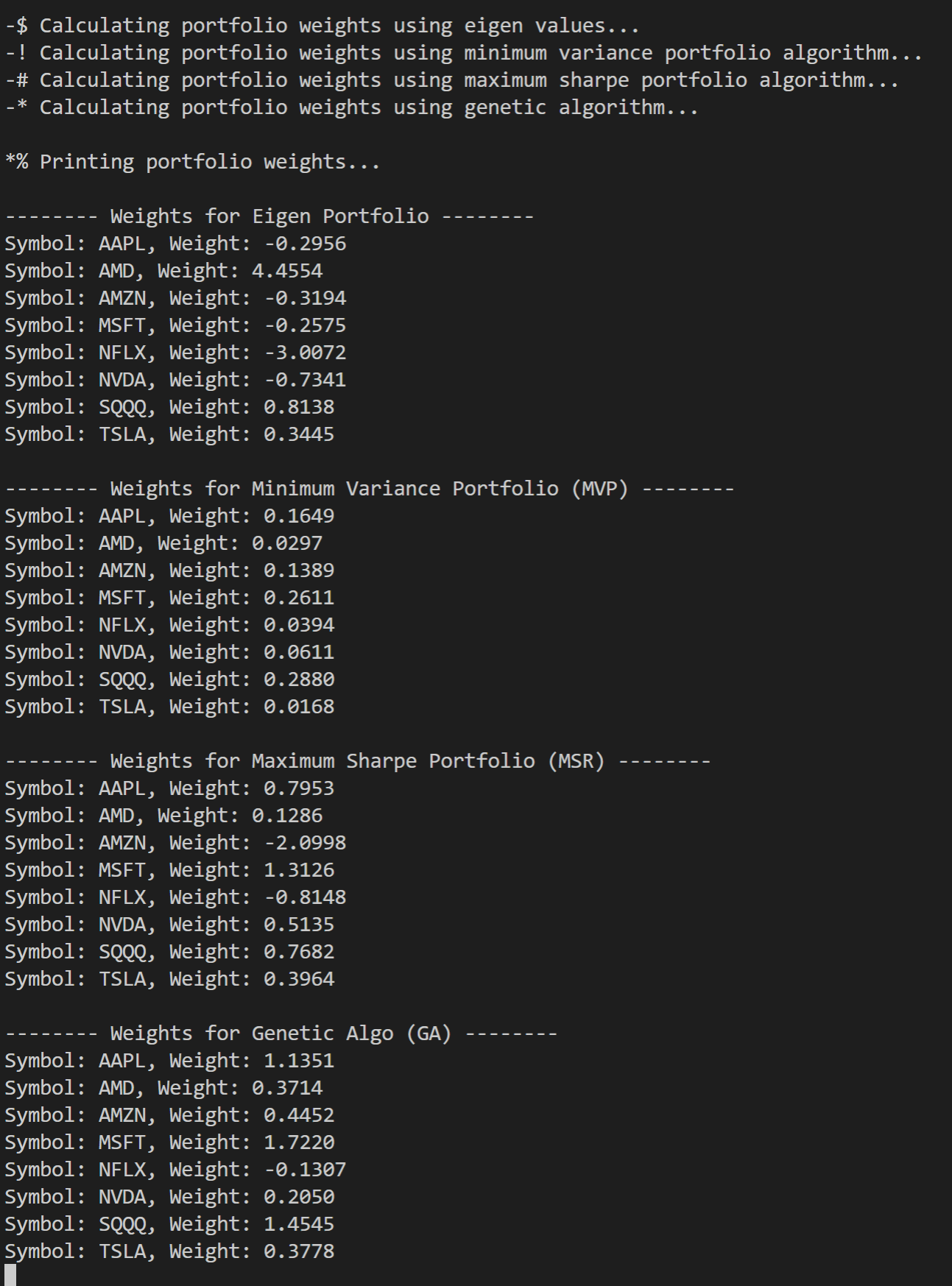
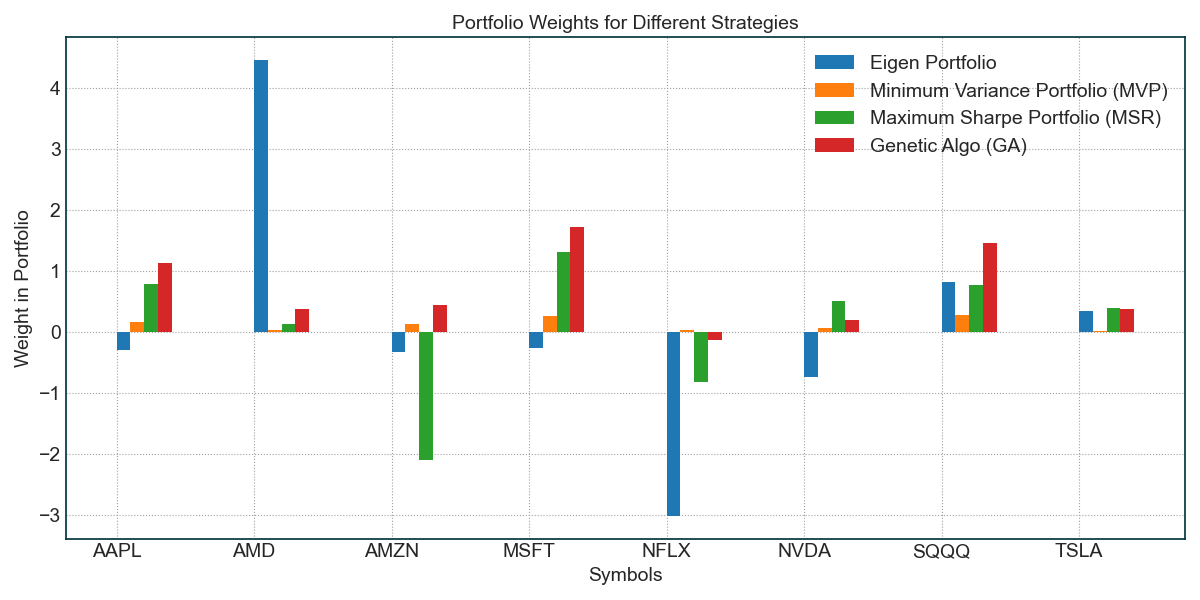
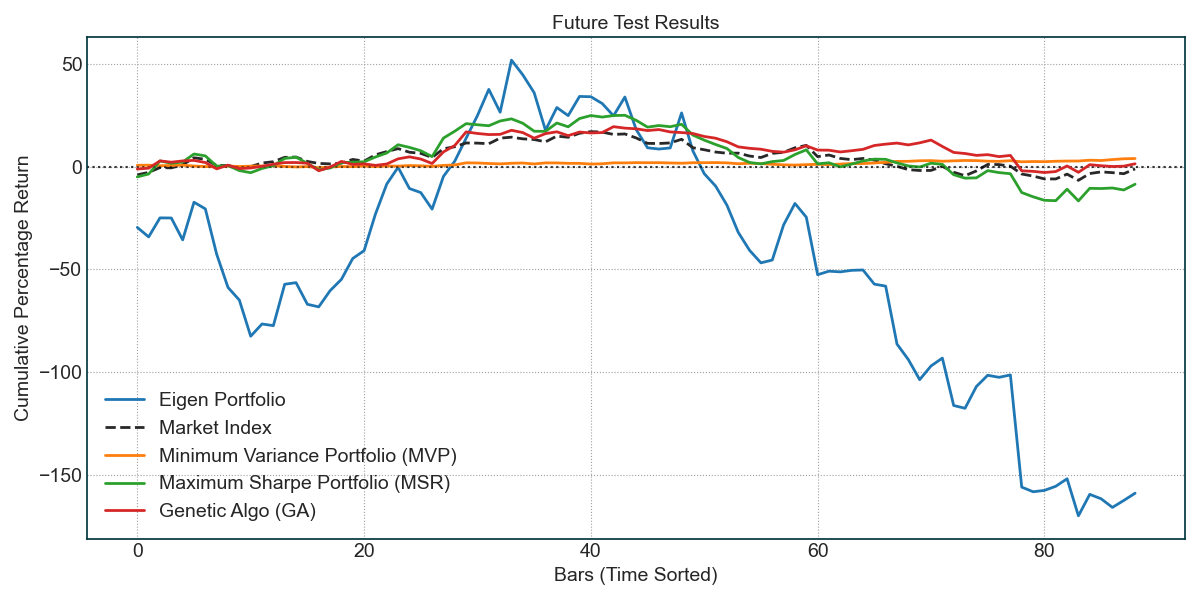
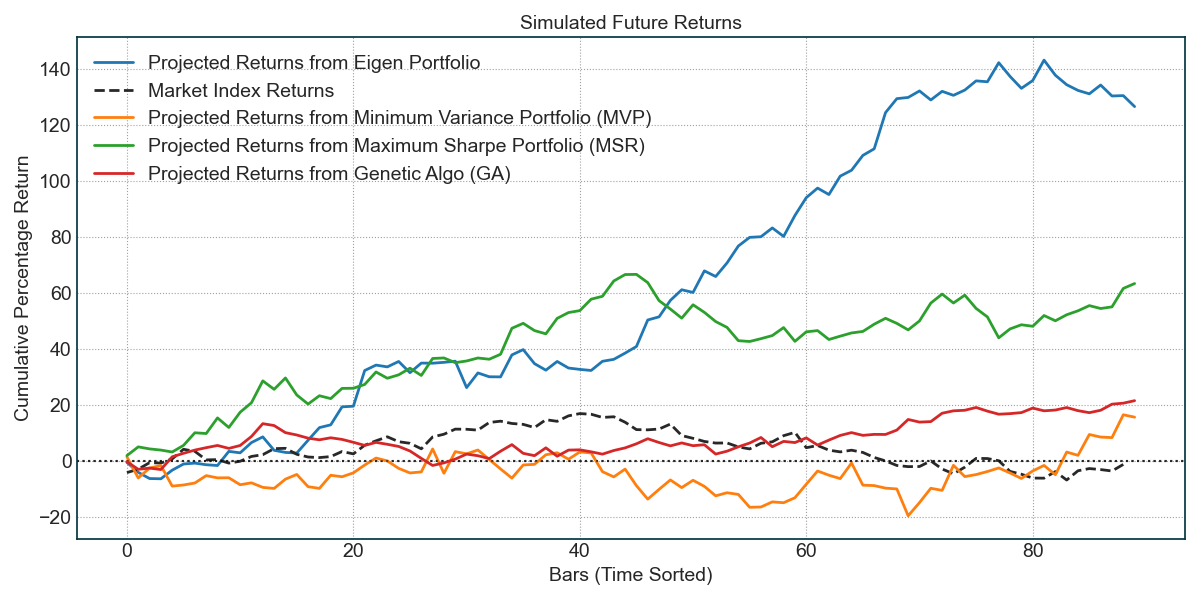
Earnings season in the US stock market is arguably one of the most thrilling investment games.
After earnings releases, stock price volatility can be extreme – 5% movements are normal, 10% swings are common, and some even exceed 20%.
This leads many to try ‘betting on earnings.’ However, this approach requires correctly predicting market direction after earnings, which is notoriously difficult to systematize.
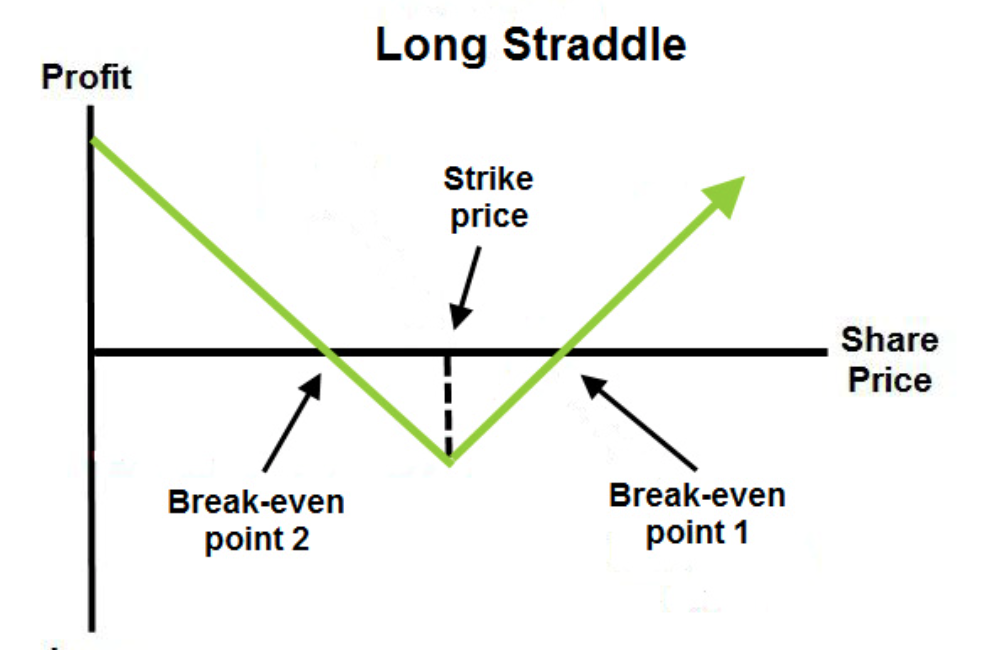
Today, I’ll introduce a strategy that doesn’t require directional prediction but instead profits from volatility – the Straddle strategy.
The principle of a Straddle is simple: simultaneously buying both call and put options with the same strike price and expiration date.
However, timing the purchase and selecting the right expiration date for the Straddle requires careful consideration.
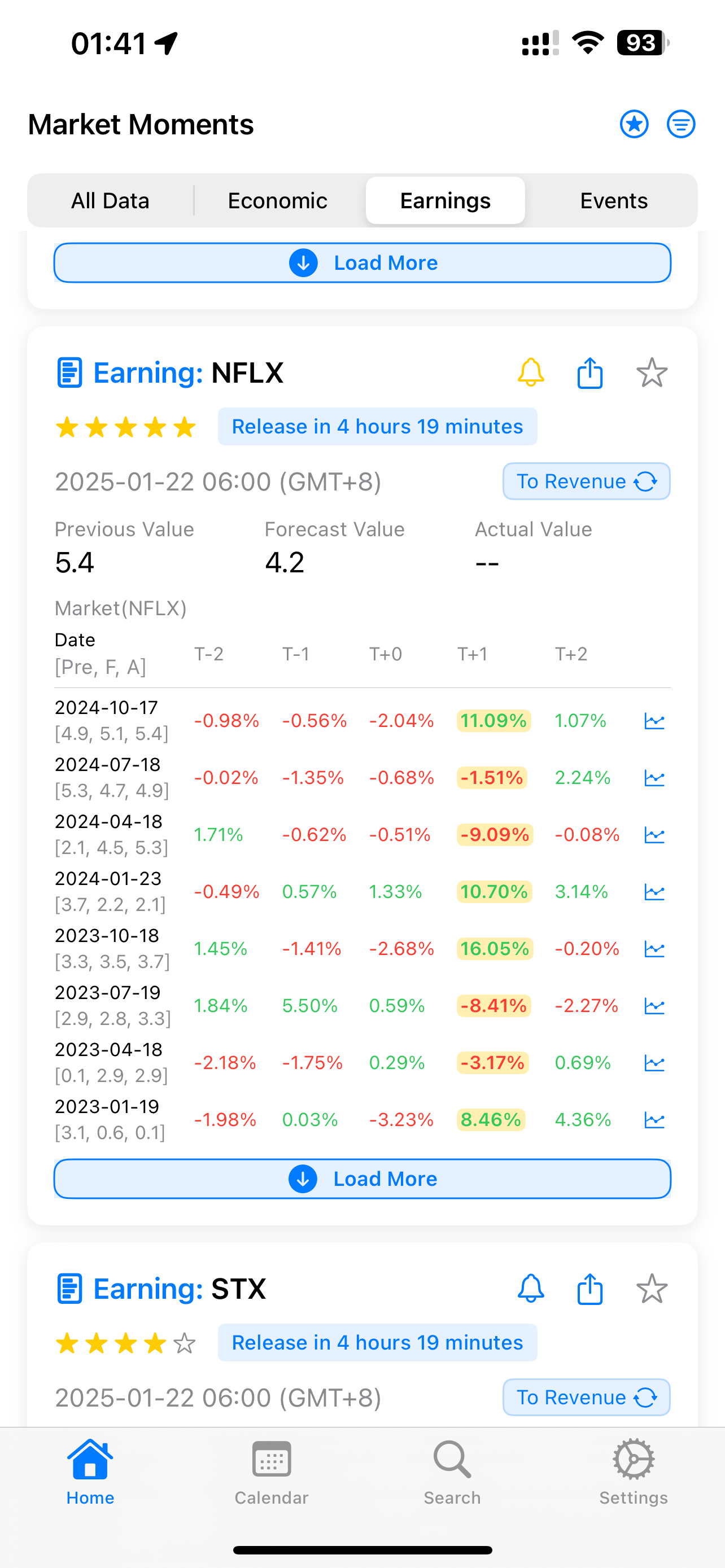
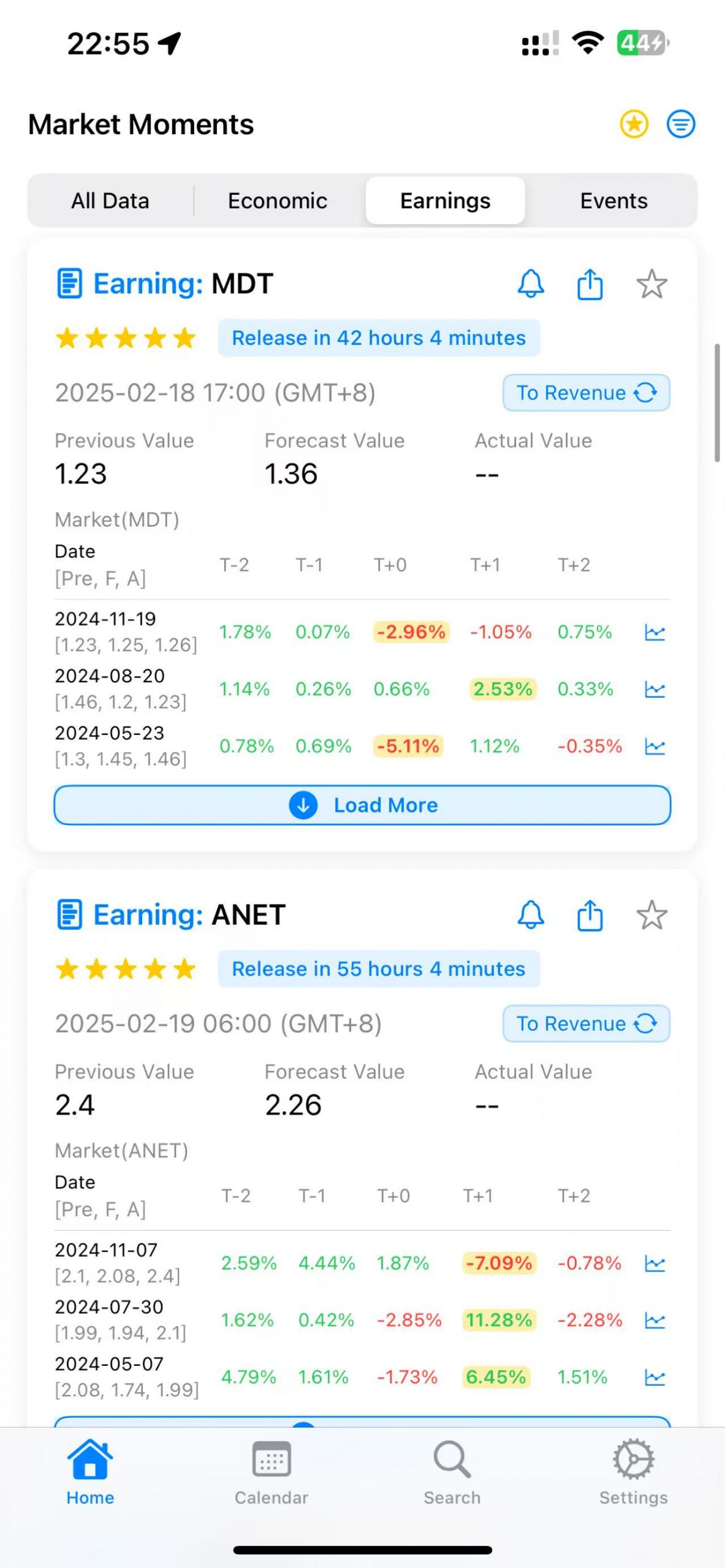
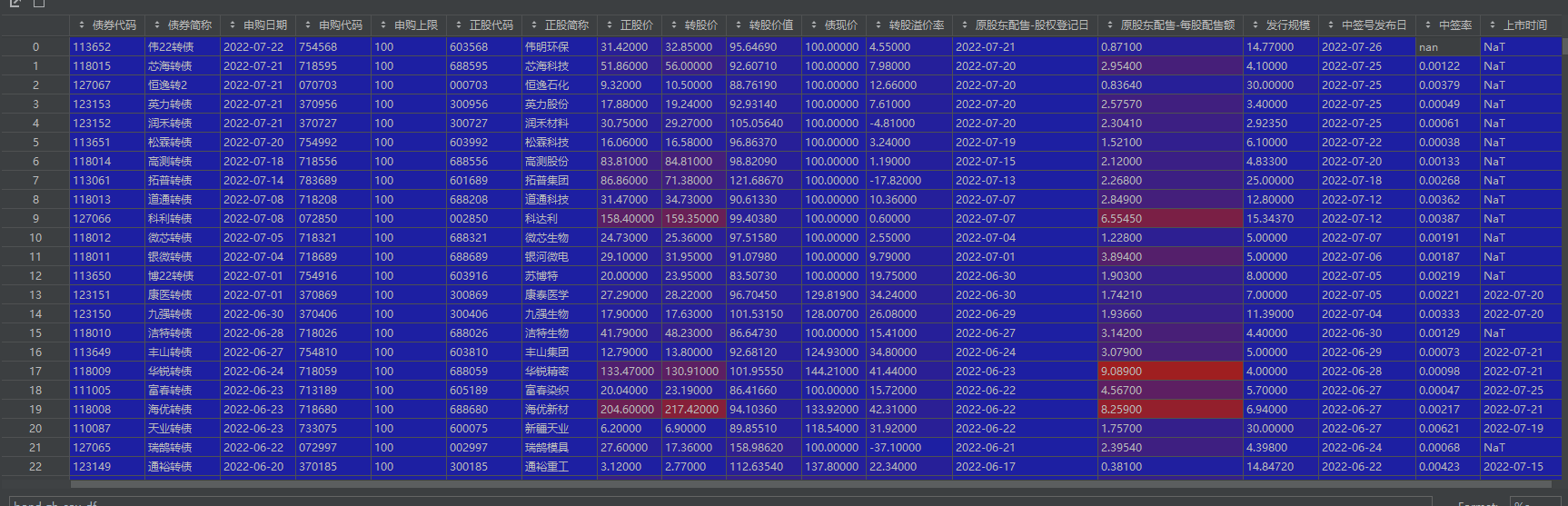
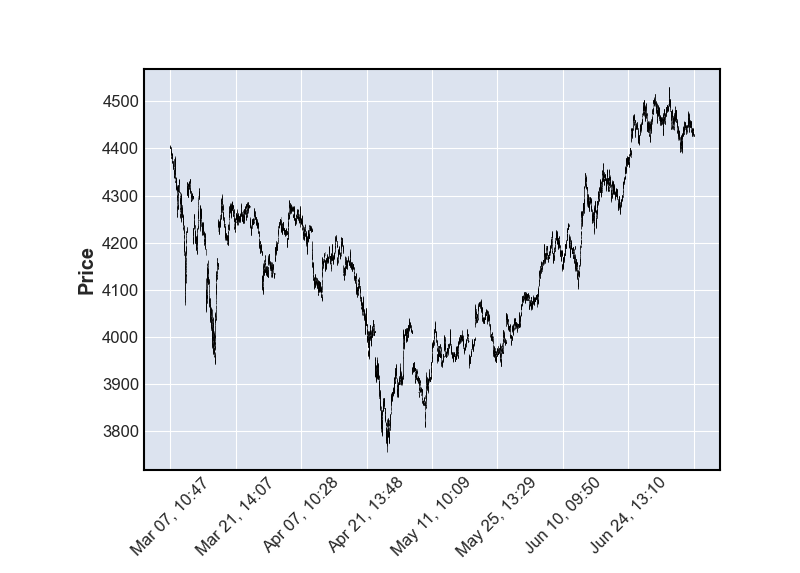
Let’s take a simple example from NFLX’s earnings on January 21st. According to the APP: Market Moments data, NFLX’s historical average post-earnings movement is around 8%:
At that time, purchasing one Straddle required a minimum movement of 7.x% to be profitable. Based on historical data, this had a high probability of success. My purchase cost was approximately $6,478.
Eventually, NFLX exceeded earnings expectations and opened up over 12%. If you sold within the first hour of trading, you could profit over $3,000, representing about a 47% return.
However, if NFLX hadn’t exceeded expectations and opened with less than a 7% move, you would have suffered losses due to the sharp decline in implied volatility. With only a 5% move at open, you would have lost around $1,200.
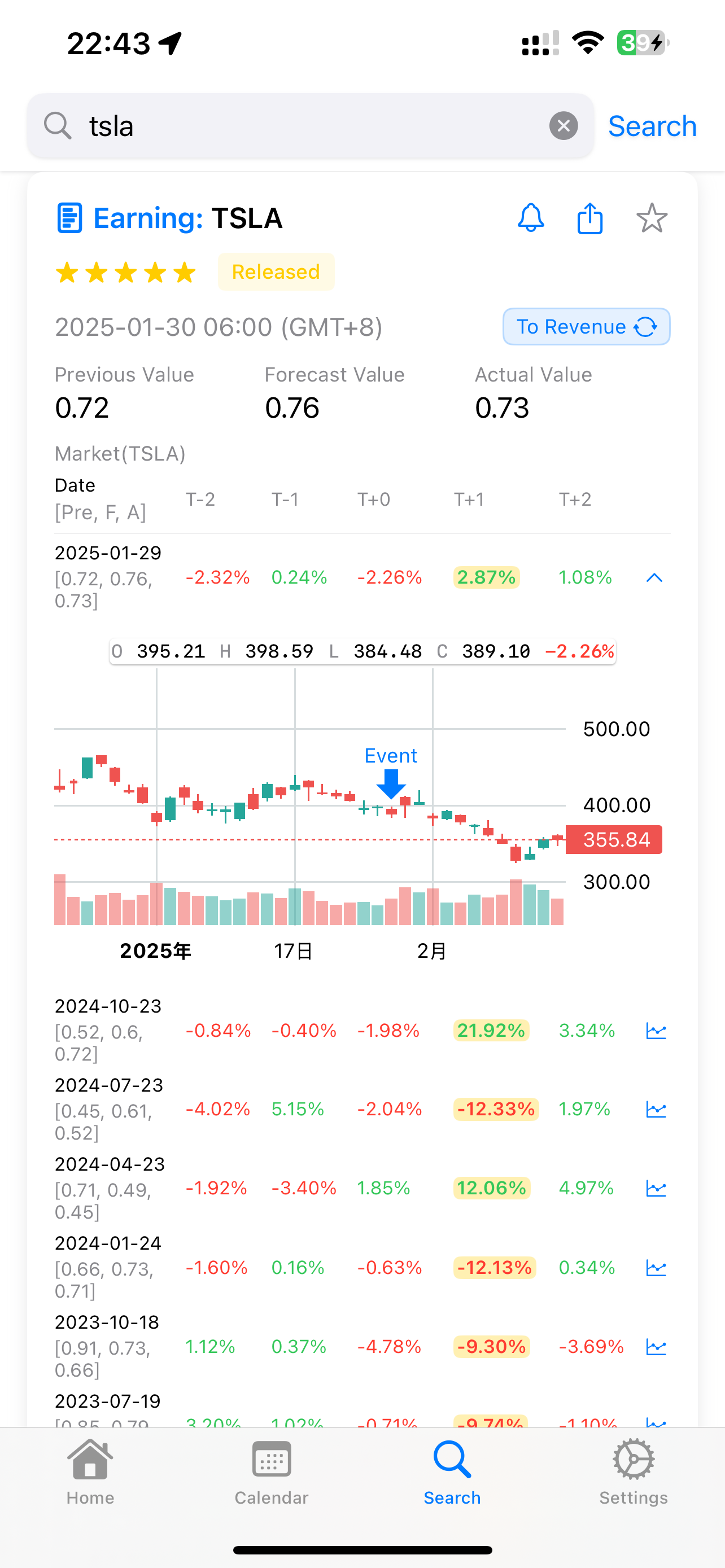
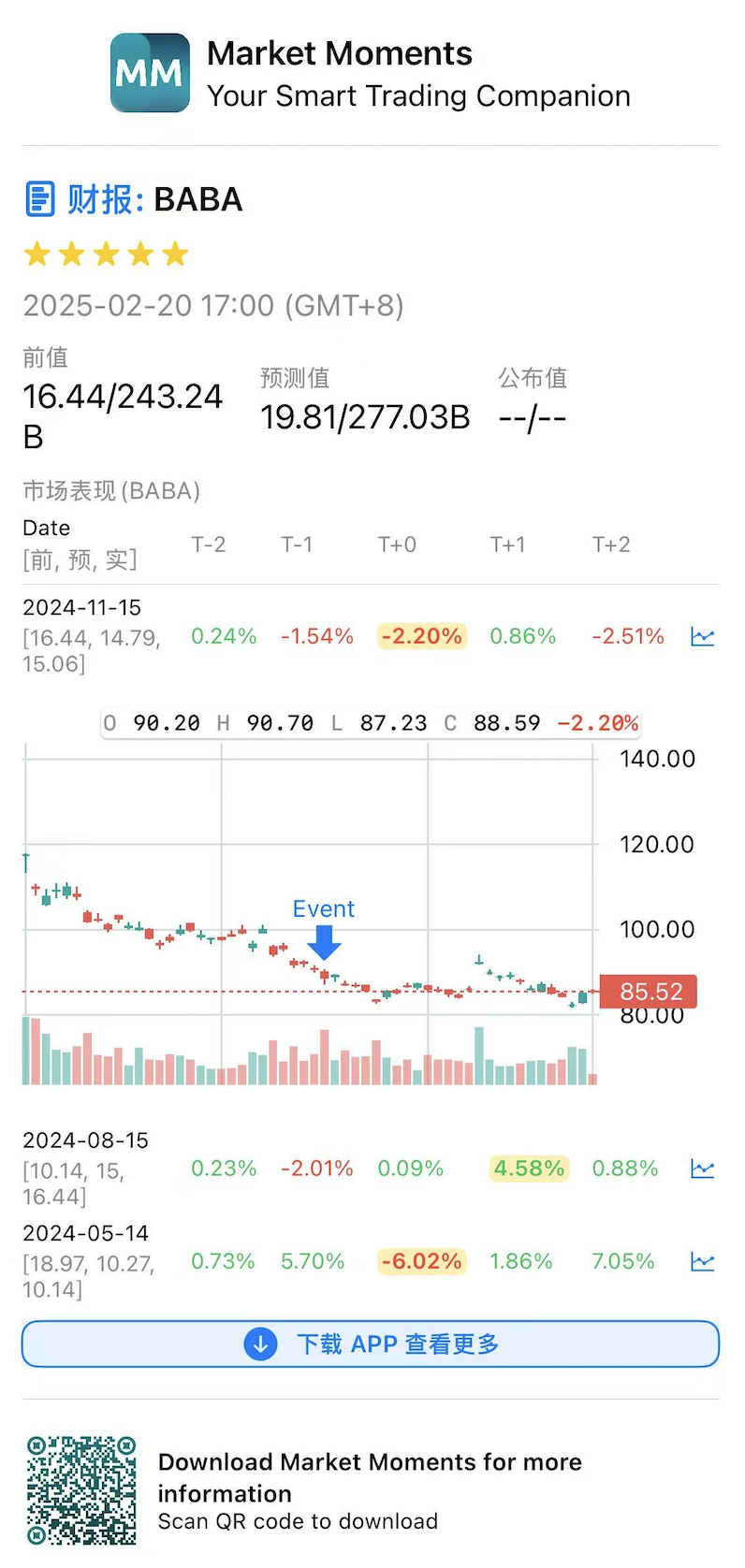
Therefore, analyzing historical volatility is crucial. However, buying Straddles with longer expiration dates provides more margin for error. Take Tesla’s recent earnings as an example:
According to APP: Market Moments search results, Tesla’s most recent earnings volatility was unusually low at just 2.x%. If you had bought a same-week expiring Straddle, with a cost basis of 10.x%, you would have suffered significant losses due to implied volatility collapse.
However, if you had chosen a late February expiring Straddle, given Tesla’s subsequent market performance dropping to $325, assuming your Straddle strike price was $389, the decline of 325/389-1 = 16.45% would have still resulted in a profit.
Two key factors for buying Straddles are:
Purchase Straddles with sufficiently distant expiration dates to provide a longer buffer period.
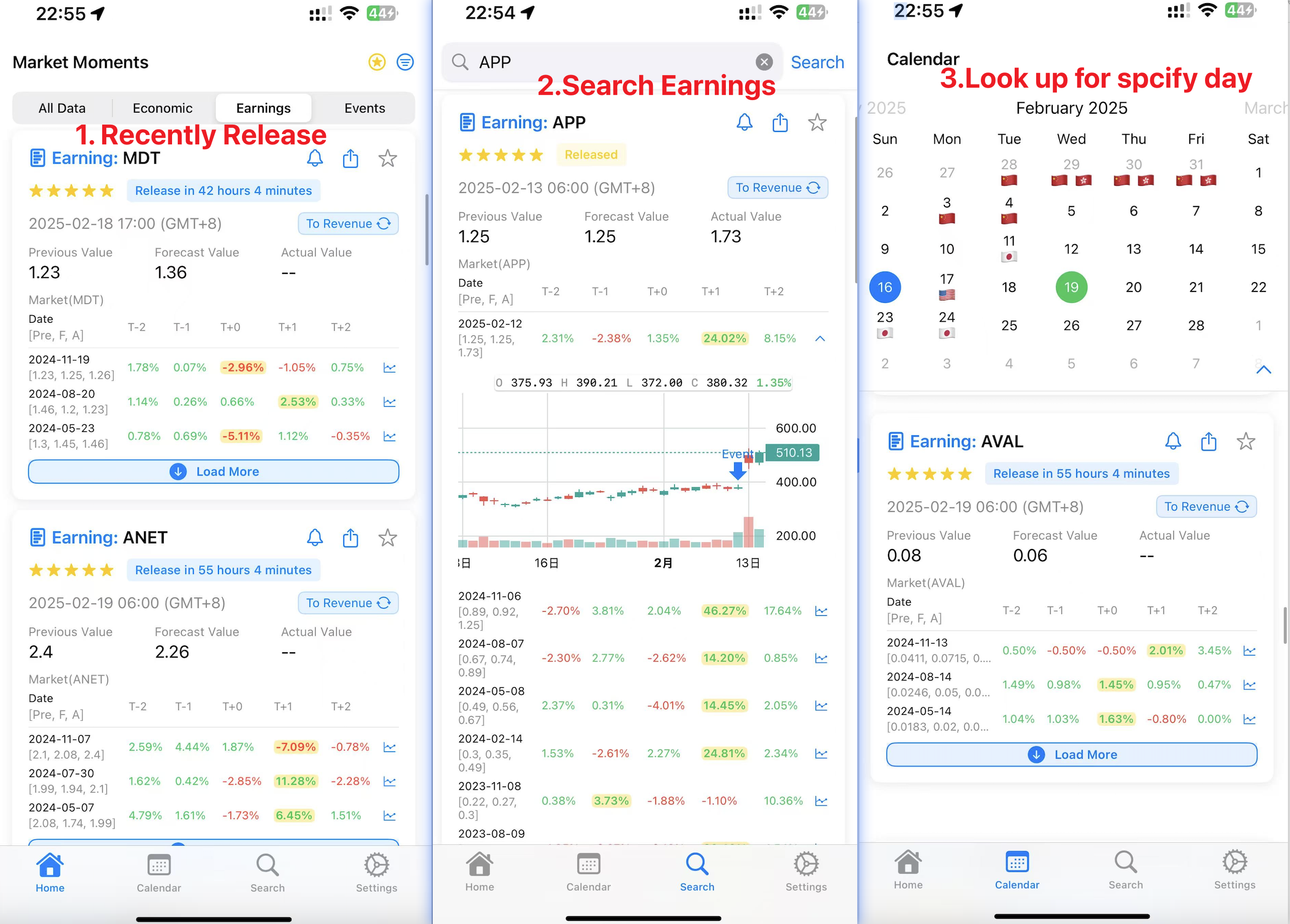
Historical earnings volatility should be high enough to exceed the minimum movement needed for the current Straddle to be profitable. You can view upcoming earnings releases or search historical earnings volatility for all US stocks in the APP: Market Moments:
As of November 1st, 2021 Yahooâs suite of services will no longer be accessi ble from mainland China. Yahoo products and services remain unaffected in all other global locations. We thank you for your support and readership,